Esta publicación tiene “condiciones adjuntas:por una buena razón. Vamos a explorar en profundidad SQL VARCHAR, el tipo de datos que trata con cadenas.
Además, esto es "solo para tus ojos" porque sin ataduras, no habrá publicaciones de blog, páginas web, instrucciones de juegos, recetas marcadas y mucho más para que nuestros ojos lean y disfruten. Nos ocupamos de un montón de cuerdas todos los días. Entonces, como desarrolladores, usted y yo somos responsables de hacer que este tipo de datos sea eficiente para almacenar y acceder.
Con esto en mente, cubriremos lo que es más importante para el almacenamiento y el rendimiento. Ingrese lo que se debe y no se debe hacer para este tipo de datos.
Pero antes de eso, VARCHAR es solo uno de los tipos de cadena en SQL. ¿Qué lo hace diferente?
¿Qué es VARCHAR en SQL? (Con ejemplos)
VARCHAR es un tipo de datos de cadena o carácter de tamaño variable. Puede almacenar letras, números y símbolos con él. A partir de SQL Server 2019, puede usar la gama completa de caracteres Unicode al usar una intercalación compatible con UTF-8.
Puede declarar columnas o variables VARCHAR usando VARCHAR[(n)], donde n representa el tamaño de la cadena en bytes. El rango de valores para n es de 1 a 8000. Son muchos datos de caracteres. Pero aún más, puede declararlo usando VARCHAR (MAX) si necesita una cadena gigantesca de hasta 2 GB. ¡Eso es lo suficientemente grande para tu lista de secretos y cosas privadas en tu diario! Sin embargo, tenga en cuenta que también puede declararlo sin el tamaño y el valor predeterminado es 1 si lo hace.
Pongamos un ejemplo.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
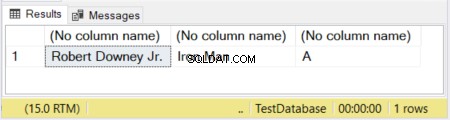
En la Figura 1, las primeras 2 columnas tienen sus tamaños definidos. La tercera columna se queda sin tamaño. Por lo tanto, la palabra "Vengadores" se trunca porque un VARCHAR sin un tamaño declarado tiene un valor predeterminado de 1 carácter.
Ahora, probemos algo enorme. Pero tenga en cuenta que esta consulta tardará un poco en ejecutarse:23 segundos en mi computadora portátil.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
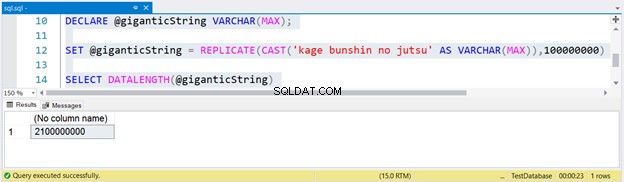
Para generar una cadena enorme, replicamos kage bunshin no jutsu 100 millones de veces. Tenga en cuenta el CAST dentro de REPLICATE. Si no convierte la expresión de cadena en VARCHAR(MAX), el resultado se truncará hasta un máximo de 8000 caracteres.
Pero, ¿cómo se compara SQL VARCHAR con otros tipos de datos de cadena?
Diferencia entre CHAR y VARCHAR en SQL
En comparación con VARCHAR, CHAR es un tipo de datos de caracteres de longitud fija. No importa cuán pequeño o grande sea el valor que le asignas a una variable CHAR, el tamaño final es el tamaño de la variable. Consulte las comparaciones a continuación.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
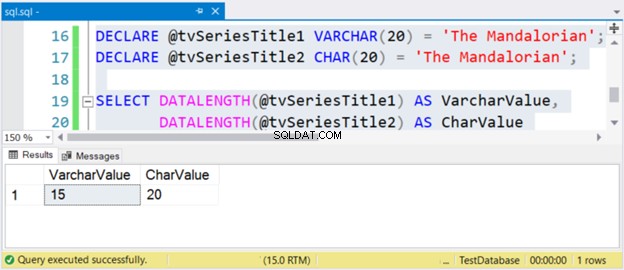
El tamaño de la cadena “The Mandalorian” es de 15 caracteres. Entonces, el VarcharValue la columna lo refleja correctamente. Sin embargo, CharValue conserva el tamaño de 20 – se rellena con 5 espacios a la derecha.
SQL VARCHAR vs NVARCHAR
Dos cosas básicas vienen a la mente al comparar estos tipos de datos.
Primero, es el tamaño en bytes. Cada carácter en NVARCHAR tiene el doble del tamaño de VARCHAR. NVARCHAR(n) es de 1 a 4000 solamente.
Luego, los caracteres que puede almacenar. NVARCHAR puede almacenar caracteres multilingües como coreano, japonés, árabe, etc. Si planea almacenar letras de canciones de K-Pop coreano en su base de datos, este tipo de datos es una de sus opciones.
Tengamos un ejemplo. Vamos a usar el grupo de K-pop 세븐틴 o Seventeen en inglés.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
El código anterior generará el valor de la cadena, su tamaño en bytes y la cantidad de caracteres. Si se trata de caracteres que no son Unicode, el número de caracteres es igual al tamaño en bytes. Pero este no es el caso. Consulte la Figura 4 a continuación.
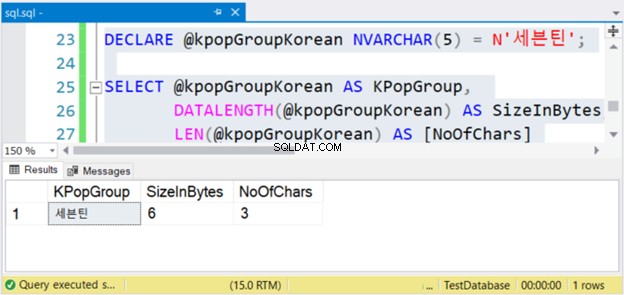
¿Ver? Si NVARCHAR tiene 3 caracteres, el tamaño en bytes es el doble. Pero no con VARCHAR. Lo mismo es cierto si usa caracteres ingleses.
Pero ¿qué hay de NCHAR? NCHAR es la contraparte de CHAR para caracteres Unicode.
SQL Server VARCHAR con compatibilidad con UTF-8
VARCHAR con compatibilidad con UTF-8 es posible en un nivel de servidor, nivel de base de datos o nivel de columna de tabla cambiando la información de intercalación. La intercalación a usar debe ser compatible con UTF-8.
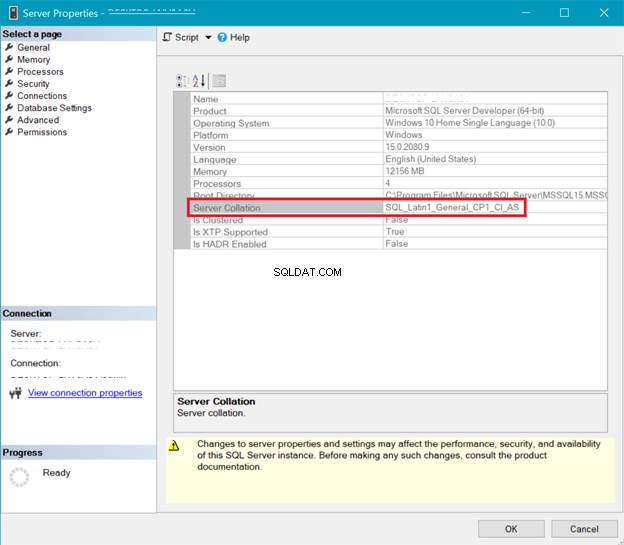
COLACIÓN DE SERVIDOR SQL
La Figura 5 presenta la ventana en SQL Server Management Studio que muestra la intercalación del servidor.
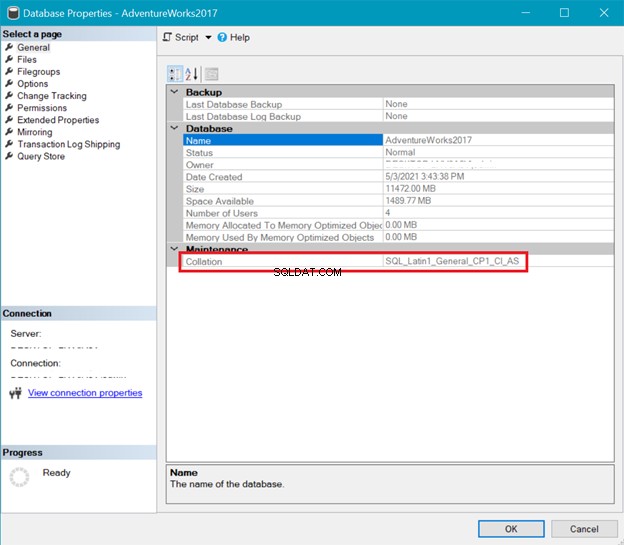
COLACIÓN DE BASES DE DATOS
Mientras tanto, la Figura 6 muestra la recopilación de AdventureWorks base de datos.
COLECCIÓN DE COLUMNAS DE TABLA
Tanto la intercalación anterior del servidor como de la base de datos muestra que UTF-8 no es compatible. La cadena de intercalación debe tener un _UTF8 para la compatibilidad con UTF-8. Pero aún puede usar la compatibilidad con UTF-8 en el nivel de columna de una tabla. Ver el ejemplo.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
El código anterior tiene Latin1_General_100_BIN2_UTF8 colación para KoreanName columna. Aunque VARCHAR y no NVARCHAR, esta columna aceptará caracteres del idioma coreano. Insertemos algunos registros y luego visualicémoslos.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Estamos usando nombres del grupo Seventeen K-pop usando contrapartes coreanas e inglesas. Para los caracteres coreanos, tenga en cuenta que aún debe prefijar el valor con N , tal como lo hace con los valores de NVARCHAR.
Luego, al usar SELECT con ORDER BY, también puede usar la intercalación. Puedes observar esto en el ejemplo anterior. Esto seguirá las reglas de clasificación para la colación especificada.
ALMACENAMIENTO DE VARCHAR CON SOPORTE UTF-8
Pero, ¿cómo es el almacenamiento de estos personajes? Si espera 2 bytes por carácter, se llevará una sorpresa. Mira la Figura 8.
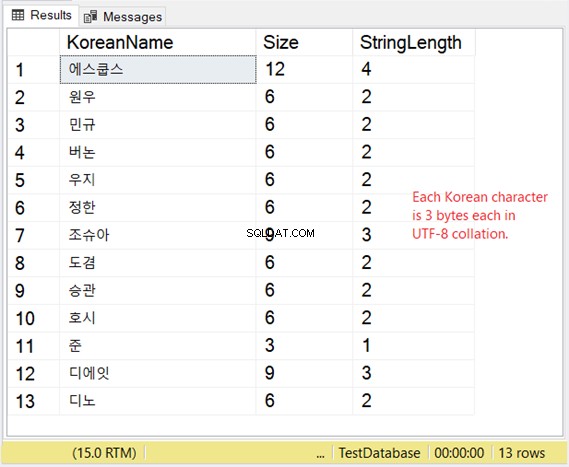
Entonces, si el almacenamiento es muy importante para usted, considere la siguiente tabla cuando use VARCHAR con soporte UTF-8.
| Personajes | Tamaño en bytes |
| Ascii 0 – 127 | 1 |
| La escritura basada en latín y griego, cirílico, copto, armenio, hebreo, árabe, siríaco, tana y n'ko | 2 |
| Escritura de Asia oriental, como chino, coreano y japonés | 3 |
| Caracteres en el rango 010000–10FFFF | 4 |
Nuestro ejemplo coreano es una secuencia de comandos de Asia oriental, por lo que tiene 3 bytes por carácter.
Ahora que hemos terminado de describir y comparar VARCHAR con otros tipos de cadenas, cubramos lo que se debe y lo que no se debe hacer
Qué hacer al usar VARCHAR en SQL Server
1. Especifique el Tamaño
¿Qué podría salir mal sin especificar el tamaño?
CORTE DE CADENA
Si te da pereza especificar el tamaño, se producirá el truncamiento de la cadena. Ya viste un ejemplo de esto antes.
IMPACTO EN EL ALMACENAMIENTO Y EL RENDIMIENTO
Otra consideración es el almacenamiento y el rendimiento. Solo necesita establecer el tamaño correcto para sus datos, no más. Pero, ¿cómo podrías saberlo? Para evitar el truncamiento en el futuro, puede establecerlo en el tamaño más grande. Eso es VARCHAR (8000) o incluso VARCHAR (MAX). Y 2 bytes se almacenarán tal cual. Lo mismo con 2GB. ¿Importa?
Responder eso nos llevará al concepto de cómo SQL Server almacena datos. Tengo otro artículo que explica esto en detalle con ejemplos e ilustraciones.
En resumen, los datos se almacenan en páginas de 8 KB. Cuando una fila de datos excede este tamaño, SQL Server la mueve a otra unidad de asignación de página llamada ROW_OVERFLOW_DATA.
Suponga que tiene datos VARCHAR de 2 bytes que pueden ajustarse a la unidad de asignación de página original. Cuando almacena una cadena de más de 8000 bytes, los datos se moverán a la página de desbordamiento de filas. Luego, redúzcalo nuevamente a un tamaño más bajo y se moverá de nuevo a la página original. El movimiento de ida y vuelta provoca una gran cantidad de E/S y un cuello de botella en el rendimiento. Recuperar esto de 2 páginas en lugar de 1 también necesita E/S adicional.
Otra razón es la indexación. VARCHAR(MAX) es un gran NO como clave de índice. Mientras tanto, VARCHAR(8000) superará el tamaño máximo de clave de índice. Eso es 1700 bytes para índices no agrupados y 900 bytes para índices agrupados.
IMPACTO DE LA CONVERSIÓN DE DATOS
Sin embargo, hay otra consideración:la conversión de datos. Pruébelo con un CAST sin el tamaño como el código a continuación.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Este código hará una conversión de una fecha/hora con información de zona horaria a VARCHAR.
Por lo tanto, si nos da pereza especificar el tamaño durante CAST o CONVERT, el resultado se limita a 30 caracteres únicamente.
¿Qué hay de convertir NVARCHAR a VARCHAR con soporte UTF-8? Hay una explicación detallada de esto más adelante, así que sigue leyendo.
2. Use VARCHAR si el tamaño de la cadena varía considerablemente
Nombres de AdventureWorks base de datos varían en tamaño. Uno de los nombres más cortos es Min Su, mientras que el nombre más largo es Osarumwense Uwaifiokun Agbonile. Eso es entre 6 y 31 caracteres, incluidos los espacios. Importemos estos nombres en 2 tablas y comparemos entre VARCHAR y CHAR.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Cual de los 2 son mejores? Verifiquemos las lecturas lógicas usando el siguiente código e inspeccionando la salida de STATISTICS IO.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
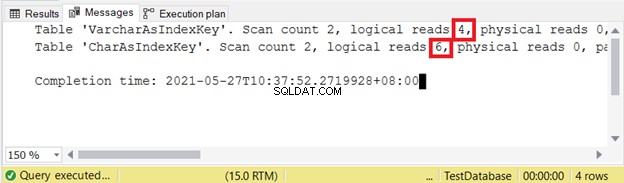
Lecturas lógicas:
Las lecturas menos lógicas, mejor. Aquí, la columna CHAR usó más del doble de la contraparte VARCHAR. Por lo tanto, VARCHAR gana en este ejemplo.
3. Use VARCHAR como clave de índice en lugar de CHAR cuando los valores varían en tamaño
¿Qué sucedió cuando se usaron como claves de índice? ¿A CHAR le irá mejor que a VARCHAR? Usemos los mismos datos de la sección anterior y respondamos esta pregunta.
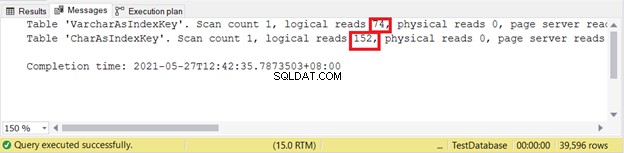
Consultaremos algunos datos y comprobaremos las lecturas lógicas. En este ejemplo, el filtro usa la clave de índice.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Lecturas lógicas:
Por lo tanto, las claves de índice VARCHAR son mejores que las claves de índice CHAR cuando la clave tiene diferentes tamaños. Pero, ¿qué tal INSERTAR y ACTUALIZAR que alterarán las entradas del índice?
CUANDO UTILICE INSERTAR Y ACTUALIZAR
Probemos 2 casos y luego verifiquemos las lecturas lógicas como lo hacemos habitualmente.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Lecturas lógicas:
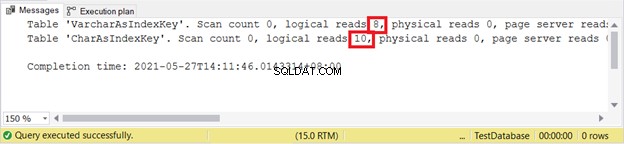
VARCHAR es aún mejor al insertar registros. ¿Qué tal ACTUALIZAR?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Lecturas lógicas:
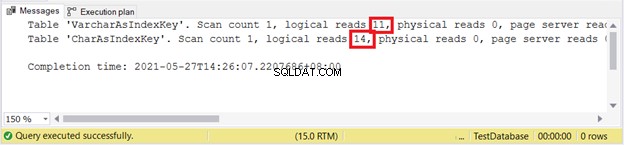
Parece que VARCHAR gana de nuevo.
Eventualmente, gana nuestra prueba, aunque podría ser pequeña. ¿Tienes un caso de prueba más grande que demuestre lo contrario?
4. Considere VARCHAR con soporte UTF-8 para datos multilingües (SQL Server 2019+)
Si hay una combinación de caracteres Unicode y no Unicode en su tabla, puede considerar VARCHAR con compatibilidad con UTF-8 en lugar de NVARCHAR. Si la mayoría de los caracteres están dentro del rango de ASCII 0 a 127, puede ofrecer ahorros de espacio en comparación con NVARCHAR.
Para ver lo que quiero decir, hagamos una comparación.
NVARCHAR A VARCHAR CON SOPORTE UTF-8
¿Ya migraste tus bases de datos a SQL Server 2019? ¿Planea migrar sus datos de cadena a la intercalación UTF-8? Tendremos un ejemplo de un valor mixto de caracteres japoneses y no japoneses para darle una idea.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Ahora que los datos están configurados, inspeccionaremos el tamaño en bytes de los 2 valores:

¡Sorpresa! Con NVARCHAR, el tamaño es de 30 bytes. Eso es 15 veces más que 2 caracteres. Pero cuando se convierte a VARCHAR con soporte UTF-8, el tamaño es de solo 27 bytes. ¿Por qué 27? Compruebe cómo se calcula esto.

Así, 9 de los caracteres son de 1 byte cada uno. Eso es interesante porque, con NVARCHAR, las letras en inglés también son de 2 bytes. El resto de los caracteres japoneses son de 3 bytes cada uno.
Si estos han sido todos los caracteres japoneses, la cadena de 15 caracteres sería de 45 bytes y también consumiría el tamaño máximo de VarcharUTF8 columna. Tenga en cuenta que el tamaño de NVarcharValue la columna es menor que VarcharUTF8 .
Los tamaños no pueden ser iguales cuando se convierte desde NVARCHAR, o los datos pueden no encajar. Puede consultar la Tabla 1 anterior.
Considere el impacto en el tamaño al convertir NVARCHAR a VARCHAR con compatibilidad con UTF-8.
No hacer en el uso de VARCHAR en SQL Server
1. Cuando el tamaño de cadena es fijo y no anulable, use CHAR en su lugar.
La regla general cuando se requiere una cadena de tamaño fijo es usar CHAR. Sigo esto cuando tengo un requisito de datos que necesita espacios con relleno a la derecha. De lo contrario, usaré VARCHAR. Tuve algunos casos de uso cuando necesitaba volcar cadenas de longitud fija sin delimitadores en un archivo de texto para un cliente.
Además, uso columnas CHAR solo si las columnas no serán anulables. ¿Por qué? Porque el tamaño en bytes de las columnas CHAR cuando NULL es igual al tamaño definido de la columna. Sin embargo, VARCHAR cuando NULL tiene un tamaño de 1 sin importar cuánto sea el tamaño definido. Ejecute el código siguiente y compruébelo usted mismo.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. No use VARCHAR(n) si n Superará los 8000 bytes. Utilice VARCHAR(MAX) en su lugar.
¿Tiene una cadena que superará los 8000 bytes? Este es el momento de usar VARCHAR(MAX). Pero para las formas más comunes de datos como nombres y direcciones, VARCHAR(MAX) es excesivo y afectará el rendimiento. En mi experiencia personal, no recuerdo un requisito para usar VARCHAR(MAX).
3. Al usar caracteres multilingües con SQL Server 2017 y versiones anteriores. Utilice NVARCHAR en su lugar.
Esta es una opción obvia si todavía usa SQL Server 2017 y versiones anteriores.
El resultado final
El tipo de datos VARCHAR nos ha servido bien para muchos aspectos. Lo hizo para mí desde SQL Server 7. Sin embargo, a veces, aún tomamos malas decisiones. En esta publicación, SQL VARCHAR se define y se compara con otros tipos de datos de cadena con ejemplos. Y de nuevo, aquí están los pros y los contras para una base de datos más rápida:
Qué hacer:
- Especifique el tamaño n en VARCHAR[(n)] incluso si es opcional.
- Úselo cuando el tamaño de la cadena varíe considerablemente.
- Considere las columnas VARCHAR como claves de índice en lugar de CHAR.
- Y si ahora usa SQL Server 2019, considere VARCHAR para cadenas multilingües compatibles con UTF-8.
No hacer:
- No use VARCHAR cuando el tamaño de la cadena sea fijo y no anulable.
- No use VARCHAR(n) cuando el tamaño de la cadena supere los 8000 bytes.
- Y no use VARCHAR para datos multilingües cuando use SQL Server 2017 y versiones anteriores.
¿Tienes algo más que agregar? Infórmenos en la sección para comentarios. Si cree que esto ayudará a sus amigos desarrolladores, compártalo en sus plataformas de redes sociales favoritas.