Como cualquier lenguaje de programación, T-SQL tiene su parte de errores y trampas comunes, algunos de los cuales causan resultados incorrectos y otros causan problemas de rendimiento. En muchos de esos casos, existen mejores prácticas que pueden ayudarlo a evitar meterse en problemas. Encuesté a otros MVP de la plataforma de datos de Microsoft y les pregunté sobre los errores y las trampas que ven a menudo o que simplemente encuentran particularmente interesantes, y las mejores prácticas que emplean para evitarlos. Tengo muchos casos interesantes.
¡Muchas gracias a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser y Chan Ming Man por compartir su conocimiento y experiencia!
Este artículo es el primero de una serie sobre el tema. Cada artículo se centra en un tema determinado. Este mes me centro en los errores, las trampas y las mejores prácticas relacionadas con el determinismo. Un cálculo determinista es aquel que está garantizado para producir resultados repetibles dadas las mismas entradas. Hay muchos errores y trampas que resultan del uso de cálculos no deterministas. En este artículo cubro las implicaciones del uso de orden no determinista, funciones no deterministas, referencias múltiples a expresiones de tablas con cálculos no deterministas y el uso de expresiones CASE y la función NULLIF con cálculos no deterministas.
Uso la base de datos de muestra TSQLV5 en muchos de los ejemplos de esta serie.
Orden no determinista
Una fuente común de errores en T-SQL es el uso de un orden no determinista. Es decir, cuando su pedido por lista no identifica de forma única una fila. Podría ser el pedido de presentación, el pedido TOP/OFFSET-FETCH o el pedido de ventana.
Tomemos, por ejemplo, un escenario de paginación clásico usando el filtro OFFSET-FETCH. Debe consultar la tabla Sales.Orders que devuelve una página de 10 filas a la vez, ordenadas por fecha de pedido, de forma descendente (la más reciente primero). Usaré constantes para los elementos de desplazamiento y recuperación por simplicidad, pero generalmente son expresiones que se basan en parámetros de entrada.
La siguiente consulta (llámela Consulta 1) devuelve la primera página de los 10 pedidos más recientes:
USAR TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH SOLO LAS SIGUIENTES 10 FILAS;
El plan para la Consulta 1 se muestra en la Figura 1.
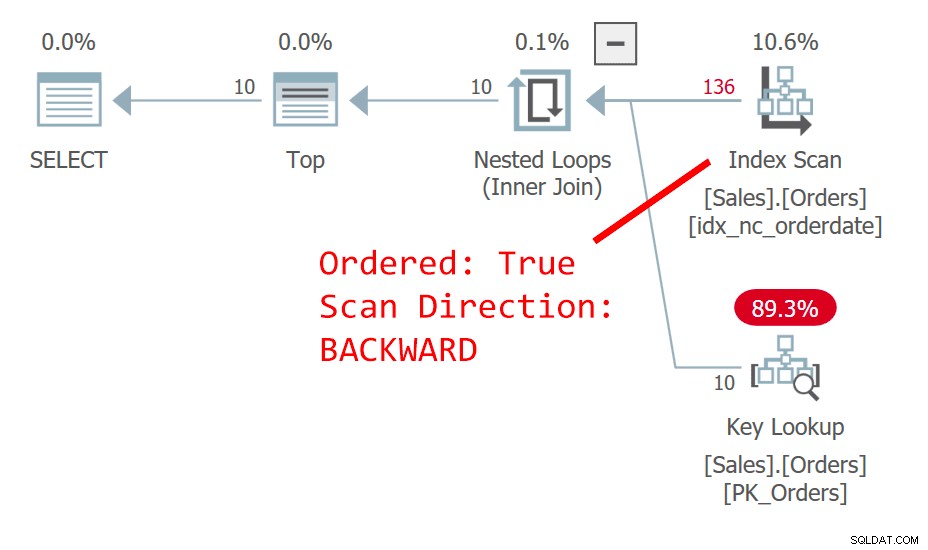 Figura 1:Plan para la consulta 1
Figura 1:Plan para la consulta 1
La consulta ordena las filas por fecha de pedido, de forma descendente. La columna de fecha de pedido no identifica de forma única una fila. Este orden no determinista significa que, conceptualmente, no hay preferencia entre las filas con la misma fecha. En caso de empates, lo que determina qué fila preferirá SQL Server son cosas como las opciones de planes y el diseño de datos físicos, no algo en lo que pueda confiar como repetible. El plan de la Figura 1 escanea el índice en la fecha de pedido ordenado hacia atrás. Sucede que esta tabla tiene un índice agrupado en orderid, y en una tabla agrupada, la clave del índice agrupado se usa como localizador de filas en índices no agrupados. En realidad, se coloca implícitamente como el último elemento clave en todos los índices no agrupados aunque, en teoría, SQL Server podría haberlo colocado en el índice como una columna incluida. Entonces, implícitamente, el índice no agrupado en la fecha del pedido se define realmente en (fecha del pedido, id del pedido). En consecuencia, en nuestro análisis hacia atrás ordenado del índice, entre filas vinculadas en función de la fecha de pedido, se accede a una fila con un valor de ID de pedido más alto antes que a una fila con un valor de ID de pedido más bajo. Esta consulta genera el siguiente resultado:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-05 10106-94 2 10106-94 80 *** 11068 2019-05-04 62
A continuación, use la siguiente consulta (llámela Consulta 2) para obtener la segunda página de 10 filas:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 FILAS SOLAMENTE;
El plan para Query se muestra en la Figura 2.
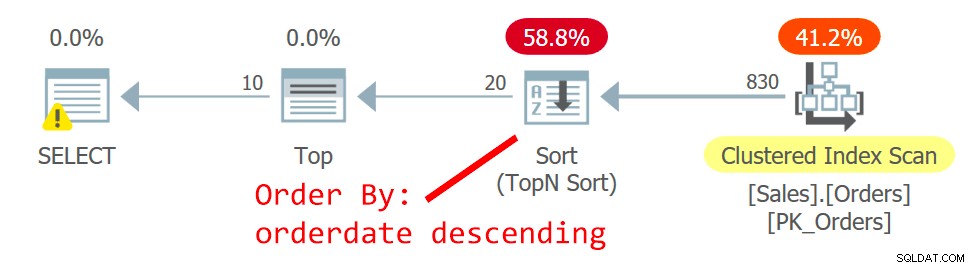
Figura 2:Plan para la consulta 2
El optimizador elige un plan diferente, uno que escanea el índice agrupado de forma desordenada y usa una clasificación TopN para admitir la solicitud del operador Top para manejar el filtro de recuperación de compensación. El motivo del cambio es que el plan de la Figura 1 usa un índice sin cobertura no agrupado, y cuanto más lejos esté la página que busca, más búsquedas se requieren. Con la solicitud de la segunda página, cruzó el punto de inflexión que justifica el uso del índice sin cobertura.
Aunque el escaneo del índice agrupado, que se define con orderid como clave, no está ordenado, el motor de almacenamiento emplea un escaneo de orden de índice internamente. Esto tiene que ver con el tamaño del índice. Hasta 64 páginas, el motor de almacenamiento generalmente prefiere escaneos de orden de índice a escaneos de orden de asignación. Incluso si el índice fuera más grande, bajo el nivel de aislamiento de lectura confirmada y los datos que no están marcados como de solo lectura, el motor de almacenamiento utiliza un escaneo de orden de índice para evitar la lectura doble y la omisión de filas como resultado de las divisiones de página que ocurren durante el proceso. escanear. Bajo las condiciones dadas, en la práctica, entre filas con la misma fecha, este plan accede a una fila con un ID de pedido más bajo antes que una con un ID de pedido más alto.
Esta consulta genera el siguiente resultado:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 7 010 37 11063 29-04 53 11058 29-04-2019 6
Observe que a pesar de que los datos subyacentes no cambiaron, terminó con el mismo pedido (con ID de pedido 11069) devuelto tanto en la primera como en la segunda página.
Con suerte, la mejor práctica aquí es clara. Agregue un desempate a su orden por lista para obtener una orden determinista. Por ejemplo, order by orderdate descendente, orderid descendente.
Vuelva a intentar pedir la primera página, esta vez con un orden determinista:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 FILAS SOLAMENTE;
Obtiene el siguiente resultado, garantizado:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-05 10106-94 2 10106-94 80 11068 2019-05-04 62
Solicite la segunda página:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH SOLO LAS SIGUIENTES 10 FILAS;
Obtiene el siguiente resultado, garantizado:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-13109 27 4-0109 27 67 11058 2019-04-29 6
Mientras no haya cambios en los datos subyacentes, tiene la garantía de obtener páginas consecutivas sin repeticiones ni saltos de filas entre las páginas.
De manera similar, al usar funciones de ventana como ROW_NUMBER con un orden no determinista, puede obtener diferentes resultados para la misma consulta según la forma del plan y el orden de acceso real entre los lazos. Considere la siguiente consulta (llámela Consulta 3), implementando la solicitud de la primera página usando números de fila (forzando el uso del índice en la fecha de pedido con fines ilustrativos):
CON C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C DONDE n ENTRE 1 Y 10;
El plan para esta consulta se muestra en la Figura 3:
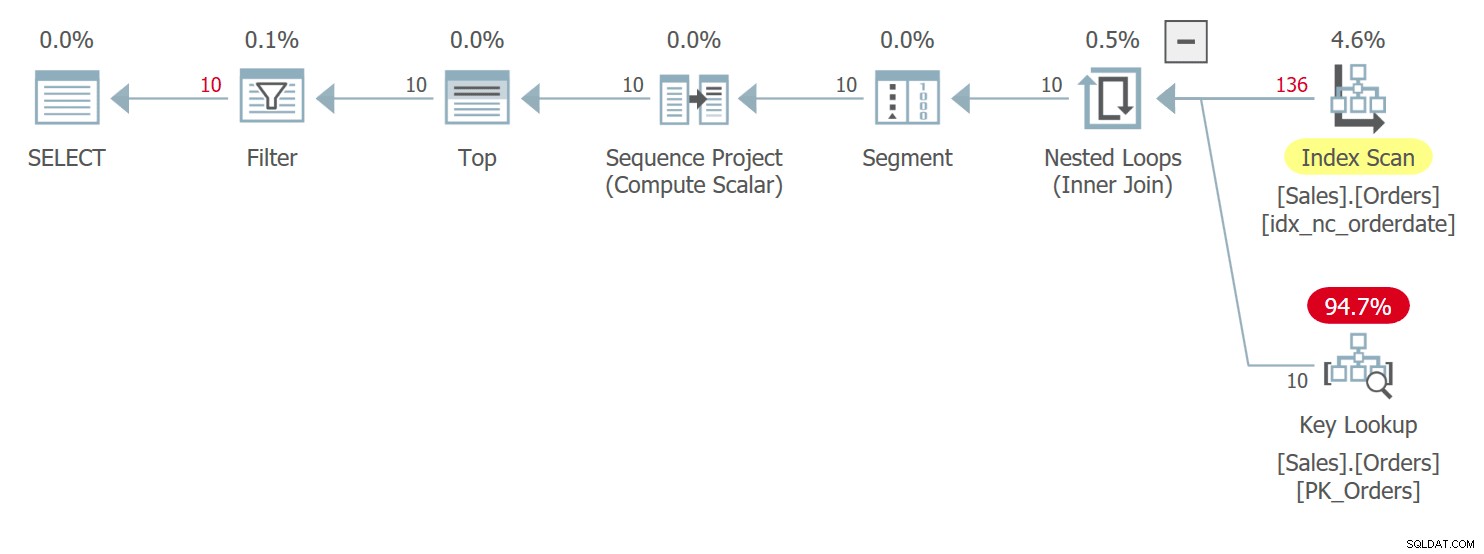
Figura 3:Plan para la consulta 3
Aquí tiene condiciones muy similares a las que describí anteriormente para la Consulta 1 con su plan que se mostró anteriormente en la Figura 1. Entre filas con vínculos en los valores de fecha de pedido, este plan accede a una fila con un valor de ID de pedido más alto antes que a uno con un valor más bajo. valor de ID de pedido. Esta consulta genera el siguiente resultado:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-05 10106-94 2 10106-94 80 *** 11068 2019-05-04 62
A continuación, vuelva a ejecutar la consulta (llámela Consulta 4), solicitando la primera página, solo que esta vez fuerce el uso del índice agrupado PK_Orders:
CON C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT orderid, orderdate, custid FROM C WHERE n ENTRE 1 Y 10;
El plan para esta consulta se muestra en la Figura 4.

Figura 4:Plan para la consulta 4
Esta vez tiene condiciones muy similares a las que describí anteriormente para la Consulta 2 con su plan que se mostró anteriormente en la Figura 2. Entre filas con vínculos en los valores de fecha de pedido, este plan accede a una fila con un valor de ID de pedido más bajo antes que a una con un mayor valor orderid. Esta consulta genera el siguiente resultado:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05-05 2 10106-05 58 17 *** 11068 2019-05-04 62
Observe que las dos ejecuciones produjeron resultados diferentes aunque nada cambió en los datos subyacentes.
Nuevamente, la mejor práctica aquí es simple:use un orden determinista agregando un desempate, así:
CON C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C DONDE n ENTRE 1 Y 10;
Esta consulta genera el siguiente resultado:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-05 10106-94 2 10106-94 80 11068 2019-05-04 62
Se garantiza que el conjunto devuelto sea repetible independientemente de la forma del plan.
Probablemente valga la pena mencionar que, dado que esta consulta no tiene un orden de presentación por cláusula en la consulta externa, aquí no hay un orden de presentación garantizado. Si necesita dicha garantía, debe agregar una cláusula de orden por presentación, así:
CON C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C DONDE n ENTRE 1 Y 10 ORDEN POR n;
Funciones no deterministas
Una función no determinista es una función que, dadas las mismas entradas, puede devolver resultados diferentes en diferentes ejecuciones de la función. Los ejemplos clásicos son SYSDATETIME, NEWID y RAND (cuando se invoca sin una semilla de entrada). El comportamiento de las funciones no deterministas en T-SQL puede resultar sorprendente para algunos y, en algunos casos, podría generar errores y dificultades.
Mucha gente asume que cuando invoca una función no determinista como parte de una consulta, la función se evalúa por fila por separado. En la práctica, la mayoría de las funciones no deterministas se evalúan una vez por referencia en la consulta. Considere la siguiente consulta como ejemplo:
SELECCIONE orderid, SYSDATETIME() COMO dt, RAND() COMO rnd FROM Ventas.Pedidos;
Dado que solo hay una referencia a cada una de las funciones no deterministas SYSDATETIME y RAND en la consulta, cada una de estas funciones se evalúa solo una vez y su resultado se repite en todas las filas de resultados. Obtuve el siguiente resultado al ejecutar esta consulta:
orderid dt rnd ----------- --------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-03:17:03:07.9229177 0.962042872007464 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.92291777742220422042222222222222222222222222222222222222,9222222222222220O.Como ejemplo en el que no comprender este comportamiento puede generar un error, suponga que necesita escribir una consulta que devuelva tres pedidos aleatorios de la tabla Sales.Orders. Un intento inicial común es utilizar una consulta SUPERIOR con un orden basado en la función RAND, pensando que la función se evaluaría por separado por fila, así:
SELECT TOP (3) orderid FROM Ventas.Pedidos ORDEN POR ALEATORIO();En la práctica, la función se evalúa solo una vez para toda la consulta; por lo tanto, todas las filas obtienen el mismo resultado y el orden no se ve afectado en absoluto. De hecho, si comprueba el plan para esta consulta, no verá ningún operador Ordenar. Cuando ejecuté esta consulta varias veces, seguí obteniendo el mismo resultado:
ID de pedido ----------- 11008 11019 11039La consulta es en realidad equivalente a una sin una cláusula ORDER BY, donde no se garantiza el orden de presentación. Entonces, técnicamente, el orden no es determinista y, en teoría, diferentes ejecuciones podrían dar como resultado un orden diferente y, por lo tanto, una selección diferente de las 3 filas principales. Sin embargo, la probabilidad de que esto ocurra es baja y no puede pensar en esta solución como si produjera tres filas aleatorias en cada ejecución.
Una excepción a la regla de que una función no determinista se invoca una vez por referencia en la consulta es la función NEWID, que devuelve un identificador único global (GUID). Cuando se usa en una consulta, esta función es invocado por separado por fila. La siguiente consulta demuestra esto:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;Esta consulta generó el siguiente resultado:
orderid mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...El valor de NEWID en sí es bastante aleatorio. Si aplica la función CHECKSUM encima, obtiene un resultado entero con una distribución aleatoria aún mejor. Entonces, una forma de obtener tres pedidos aleatorios es usar una consulta TOP con un pedido basado en CHECKSUM(NEWID()), así:
SELECCIONE TOP (3) orderid FROM Ventas.Pedidos ORDEN POR CHECKSUM(NEWID());Ejecute esta consulta repetidamente y observe que obtiene un conjunto diferente de tres pedidos aleatorios cada vez. Obtuve el siguiente resultado en una ejecución:
ID de pedido ----------- 11031 10330 10962Y el siguiente resultado en otra ejecución:
ID de pedido ----------- 10308 10885 10444Además de NEWID, ¿qué sucede si necesita usar una función no determinista como SYSDATETIME en una consulta y necesita que se evalúe por separado por fila? Una forma de lograr esto es usar una función definida por el usuario (UDF) que invoque la función no determinista, así:
CREAR O ALTERAR FUNCIÓN dbo.MySysDateTime() DEVUELVE DATETIME2 COMO BEGIN RETURN SYSDATETIME(); FIN; IRLuego invoque el UDF en la consulta así (llámelo Consulta 5):
SELECCIONE orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;El UDF se ejecuta por fila esta vez. Sin embargo, debe tener en cuenta que existe una penalización de rendimiento bastante aguda asociada con la ejecución por fila de la UDF. Además, invocar una UDF de T-SQL escalar es un inhibidor de paralelismo.
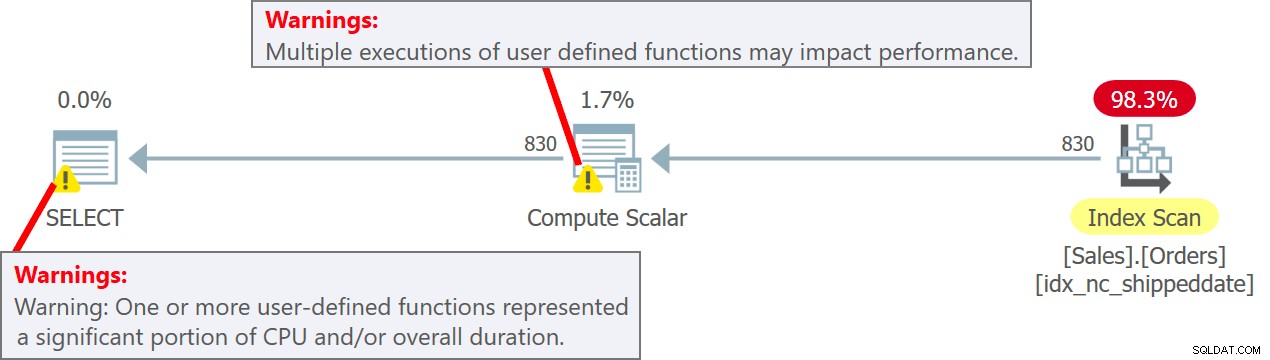
El plan para esta consulta se muestra en la Figura 5.
Figura 5:Plan para la consulta 5Observe en el plan que, de hecho, la UDF se invoca por fila de origen en el operador Compute Scalar. También tenga en cuenta que SentryOne Plan Explorer le advierte sobre la posible penalización de rendimiento asociada con el uso de UDF tanto en el operador Compute Scalar como en el nodo raíz del plan.
Obtuve el siguiente resultado de la ejecución de esta consulta:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 1014:02-72-05 2019-05 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 .. .Observe que las filas de salida tienen varios valores de fecha y hora diferentes en la columna mydt.
Es posible que haya escuchado que SQL Server 2019 soluciona el problema de rendimiento común causado por las UDF escalares de T-SQL al integrar dichas funciones. Sin embargo, la UDF tiene que cumplir con una lista de requisitos para ser inlineable. Uno de los requisitos es que la UDF no invoque ninguna función intrínseca no determinista como SYSDATETIME. El razonamiento de este requisito es que tal vez creó la UDF exactamente para obtener una ejecución por fila. Si el UDF se intercalara, la función no determinista subyacente se ejecutaría solo una vez para toda la consulta. De hecho, el plan de la Figura 5 se generó en SQL Server 2019 y puede ver claramente que la UDF no se incorporó. Eso se debe al uso de la función no determinista SYSDATETIME. Puede comprobar si un UDF se puede incorporar en línea en SQL Server 2019 consultando el atributo is_inlineable en la vista sys.sql_modules, así:
SELECCIONE is_inlineable DESDE sys.sql_modules DONDE object_id =OBJECT_ID(N'dbo.MySysDateTime');Este código genera el siguiente resultado que le indica que el UDF MySysDateTime no es inlineable:
es_inlineable ------------- 0Para demostrar una UDF que es inlineable, aquí está la definición de una UDF llamada EndOfyear que acepta una fecha de entrada y devuelve la fecha de fin de año respectiva:
CREAR O ALTERAR FUNCIÓN dbo.EndOfYear(@dt COMO FECHA) DEVUELVE FECHA COMO COMIENZO FECHA DE RETORNO ADD(año, DATEDIFF(año, '18991231', @dt), '18991231'); FIN; IRAquí no se utilizan funciones no deterministas, y el código también cumple con los otros requisitos para la inserción. Puede verificar que el UDF se puede incorporar mediante el siguiente código:
SELECCIONE is_inlineable DESDE sys.sql_modules DONDE object_id =OBJECT_ID(N'dbo.EndOfYear');Este código genera el siguiente resultado:
es_inlineable ------------- 1La siguiente consulta (llámela Consulta 6) utiliza la UDF EndOfYear para filtrar los pedidos que se realizaron en una fecha de fin de año:
SELECCIONE orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);El plan para esta consulta se muestra en la Figura 6.
Figura 6:Plan para la consulta 6El plan muestra claramente que el UDF se incorporó.
Expresiones de tabla, no determinismo y referencias múltiples
Como se mencionó, las funciones no deterministas como SYSDATETIME se invocan una vez por referencia en una consulta. Pero, ¿qué sucede si hace referencia a dicha función una vez en una consulta en una expresión de tabla como una CTE y luego tiene una consulta externa con múltiples referencias a la CTE? Mucha gente no se da cuenta de que cada referencia a la expresión de la tabla se expande por separado y el código en línea da como resultado múltiples referencias a la función no determinista subyacente. Con una función como SYSDATETIME, dependiendo del tiempo exacto de cada una de las ejecuciones, podría terminar obteniendo un resultado diferente para cada una. Algunas personas encuentran este comportamiento sorprendente.
Esto se puede ilustrar con el siguiente código:
DECLARAR @i COMO INT =1, @rc COMO INT =NULL; MIENTRAS 1 =1 EMPIEZA; CON C1 COMO (SELECCIONE SYSDATETIME() COMO dt), C2 COMO (SELECCIONE dt DE C1 UNION SELECCIONE dt DE C1) SELECCIONE @rc =COUNT(*) DE C2; SI @rc> 1 PAUSA; FIJAR @i +=1; FIN; SELECT @rc AS valores distintos, @i AS iteraciones;Si ambas referencias a C1 en la consulta en C2 representaran lo mismo, este código habría dado como resultado un bucle infinito. Sin embargo, dado que las dos referencias se expanden por separado, cuando el tiempo es tal que cada invocación tiene lugar en un intervalo diferente de 100 nanosegundos (la precisión del valor del resultado), la unión da como resultado dos filas y el código debe separarse del círculo. Ejecute este código y compruébelo usted mismo. De hecho, después de algunas iteraciones se rompe. Obtuve el siguiente resultado en una de las ejecuciones:
iteraciones de valores distintos -------------- ----------- 2 448La mejor práctica es evitar el uso de expresiones de tabla como CTE y vistas, cuando la consulta interna usa cálculos no deterministas y la consulta externa hace referencia a la expresión de tabla varias veces. Eso es, por supuesto, a menos que comprenda las implicaciones y esté de acuerdo con ellas. Las opciones alternativas podrían ser conservar el resultado de la consulta interna, digamos en una tabla temporal, y luego consultar la tabla temporal tantas veces como sea necesario.
Para demostrar ejemplos en los que no seguir las mejores prácticas puede causarle problemas, suponga que necesita escribir una consulta que empareje empleados de la tabla HR.Employees al azar. Se le ocurre la siguiente consulta (llámela consulta 7) para manejar la tarea:
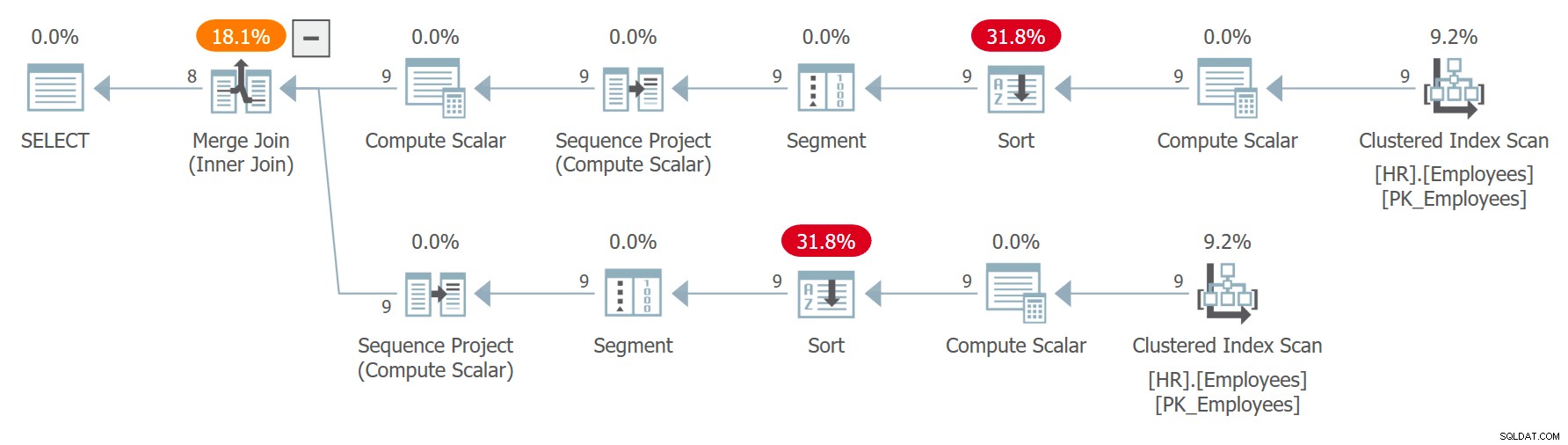
CON C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1;El plan para esta consulta se muestra en la Figura 7.
Figura 7:Plan para Consulta 7Observe que las dos referencias a C se expanden por separado y los números de fila se calculan de forma independiente para cada referencia ordenada por invocaciones independientes de la expresión CHECKSUM(NEWID()). Esto significa que no se garantiza que el mismo empleado obtenga el mismo número de fila en las dos referencias expandidas. Si un empleado obtiene el número de fila x en C1 y el número de fila x – 1 en C2, la consulta emparejará al empleado consigo mismo. Por ejemplo, obtuve el siguiente resultado en una de las ejecuciones:
empid1 nombre1 apellido1 empid2 nombre2 apellido2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Rey Russell ***Observe que aquí hay tres casos de autopares. Esto es más fácil de ver agregando un filtro a la consulta externa que busca específicamente autopares, así:
CON C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. lastname AS lastname1, C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2 FROM C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Es posible que deba ejecutar esta consulta varias veces para ver el problema. Aquí hay un ejemplo del resultado que obtuve en una de las ejecuciones:
empid1 nombre1 apellido1 empid2 nombre2 apellido2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkSiguiendo la mejor práctica, una forma de resolver este problema es conservar el resultado de la consulta interna en una tabla temporal y luego consultar varias instancias de la tabla temporal según sea necesario.
Otro ejemplo ilustra los errores que pueden resultar del uso de un orden no determinista y varias referencias a una expresión de tabla. Suponga que necesita consultar la tabla Sales.Orders y, para realizar un análisis de tendencias, desea emparejar cada pedido con el siguiente en función del pedido de fecha de pedido. Su solución debe ser compatible con los sistemas anteriores a SQL Server 2012, lo que significa que no puede usar las funciones LAG/LEAD obvias. Decide utilizar un CTE que calcula los números de fila para colocar las filas en función del orden de la fecha del pedido y, a continuación, une dos instancias del CTE, emparejando los pedidos en función de un desplazamiento de 1 entre los números de fila, así (llame a esta Consulta 8):
CON C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DESDE C COMO C1 IZQUIERDA EXTERNA ÚNETE C AS C2 EN C1.n =C2.n + 1;El plan para esta consulta se muestra en la Figura 8.
Figura 8:Plan para Consulta 8
El orden del número de fila no es determinista ya que la fecha de pedido no es única. Obsérvese que las dos referencias al CTE se amplían por separado. Curiosamente, dado que la consulta busca un subconjunto diferente de columnas de cada una de las instancias, el optimizador decide usar un índice diferente en cada caso. En un caso, utiliza un escaneo hacia atrás ordenado del índice en orderdate, escaneando efectivamente filas con la misma fecha según el orden descendente orderid. En el otro caso, escanea el índice agrupado, ordena falso y luego ordena, pero efectivamente entre las filas con la misma fecha, accede a las filas en orden ascendente orderid. Eso se debe a un razonamiento similar que proporcioné anteriormente en la sección sobre el orden no determinista. Esto puede dar como resultado que la misma fila obtenga el número de fila x en una instancia y el número de fila x – 1 en la otra instancia. En tal caso, la unión terminará haciendo coincidir un pedido consigo mismo en lugar de con el siguiente como debería.
Obtuve el siguiente resultado al ejecutar esta consulta:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULO NULO 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-010 7-20 5 1 05 *** ...Observe las autocoincidencias en el resultado. Una vez más, el problema se puede identificar más fácilmente agregando un filtro que busque autocoincidencias, así:
CON C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DESDE C COMO C1 IZQUIERDA EXTERNA ÚNETE C AS C2 EN C1.n =C2.n + 1 DONDE C1.orderid =C2.orderid;Obtuve el siguiente resultado de esta consulta:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...La mejor práctica aquí es asegurarse de usar un orden único para garantizar el determinismo agregando un desempate como orderid a la cláusula de orden de la ventana. Entonces, aunque tenga varias referencias al mismo CTE, los números de fila serán los mismos en ambos. Si desea evitar la repetición de los cálculos, también podría considerar conservar el resultado de la consulta interna, pero luego debe considerar el costo adicional de dicho trabajo.
FUNCIONES CASE/NULLIF y no deterministas
Cuando tiene varias referencias a una función no determinista en una consulta, cada referencia se evalúa por separado. Lo que podría ser sorprendente e incluso generar errores es que a veces escribe una referencia, pero implícitamente se convierte en múltiples referencias. Tal es la situación con algunos usos de la expresión CASE y la función IIF.
Considere el siguiente ejemplo:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 CUANDO 0 ENTONCES 'Par' CUANDO 1 ENTONCES 'Impar' FIN;Aquí el resultado de la expresión probada es un valor entero no negativo, por lo que claramente tiene que ser par o impar. No puede ser ni par ni impar. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusión
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!