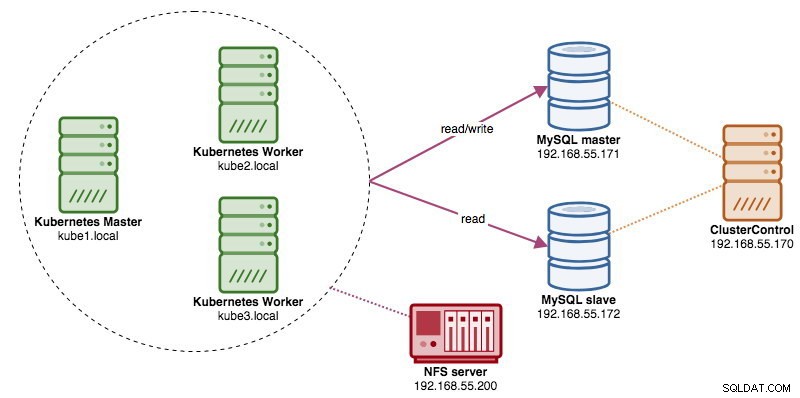
Cuando se ejecutan clústeres de bases de datos distribuidas, es bastante común enfrentarlos con balanceadores de carga. Las ventajas son claras:equilibrio de carga, conmutación por error de la conexión y desacoplamiento del nivel de la aplicación de las topologías de la base de datos subyacente. Para un equilibrio de carga más inteligente, un proxy compatible con bases de datos como ProxySQL o MaxScale sería el camino a seguir. En nuestro blog anterior, le mostramos cómo ejecutar ProxySQL como un contenedor auxiliar en Kubernetes. En esta publicación de blog, le mostraremos cómo implementar ProxySQL como un servicio de Kubernetes. Usaremos Wordpress como una aplicación de ejemplo y el backend de la base de datos se ejecuta en una replicación de MySQL de dos nodos implementada mediante ClusterControl. El siguiente diagrama ilustra nuestra infraestructura:
Dado que vamos a implementar una configuración similar a la de esta publicación de blog anterior, espere duplicación en algunas partes de la publicación de blog para que la publicación sea más legible.
ProxySQL en Kubernetes
Comencemos con un poco de resumen. El diseño de una arquitectura ProxySQL es un tema subjetivo y depende en gran medida de la ubicación de la aplicación, los contenedores de la base de datos y la función del propio ProxySQL. Idealmente, podemos configurar ProxySQL para que sea administrado por Kubernetes con dos configuraciones:
- ProxySQL como servicio de Kubernetes (implementación centralizada)
- ProxySQL como contenedor auxiliar en un pod (implementación distribuida)
Ambas implementaciones se pueden distinguir fácilmente observando el siguiente diagrama:
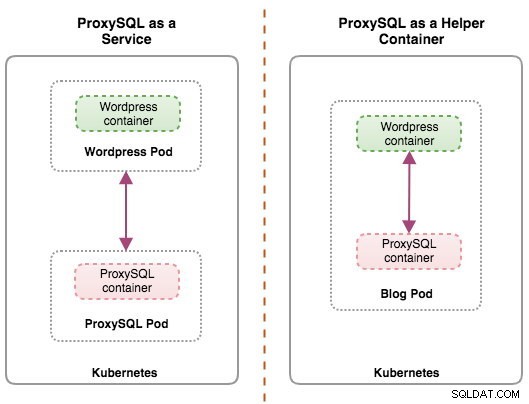
Esta publicación de blog cubrirá la primera configuración:ejecutar ProxySQL como un servicio de Kubernetes. La segunda configuración ya está cubierta aquí. En contraste con el enfoque del contenedor de ayuda, la ejecución como servicio hace que los pods de ProxySQL vivan independientemente de las aplicaciones y se pueden escalar y agrupar fácilmente con la ayuda de Kubernetes ConfigMap. Definitivamente, este es un enfoque de agrupación en clústeres diferente al soporte de agrupación en clústeres nativo de ProxySQL, que se basa en la suma de verificación de la configuración en las instancias de ProxySQL (también conocidas como servidores proxysql_servers). Consulte esta publicación de blog si desea obtener información sobre la agrupación en clústeres de ProxySQL de forma fácil con ClusterControl.
En Kubernetes, el sistema de configuración multicapa de ProxySQL hace posible la agrupación en clústeres de pods con ConfigMap. Sin embargo, hay una serie de deficiencias y soluciones para que funcione sin problemas como lo hace la función de agrupación en clústeres nativa de ProxySQL. Por el momento, la señalización de un pod en la actualización de ConfigMap es una característica en desarrollo. Cubriremos este tema con mucho más detalle en una próxima publicación de blog.
Básicamente, necesitamos crear pods de ProxySQL y adjuntar un servicio de Kubernetes para que puedan acceder los otros pods dentro de la red de Kubernetes o externamente. Luego, las aplicaciones se conectarán al servicio ProxySQL a través de la red TCP/IP en los puertos configurados. El valor predeterminado es 6033 para conexiones con equilibrio de carga de MySQL y 6032 para la consola de administración de ProxySQL. Con más de una réplica, las conexiones al pod se equilibrarán automáticamente mediante el componente kube-proxy de Kubernetes que se ejecuta en cada nodo de Kubernetes.
ProxySQL como servicio de Kubernetes
En esta configuración, ejecutamos tanto ProxySQL como Wordpress como pods y servicios. El siguiente diagrama ilustra nuestra arquitectura de alto nivel:
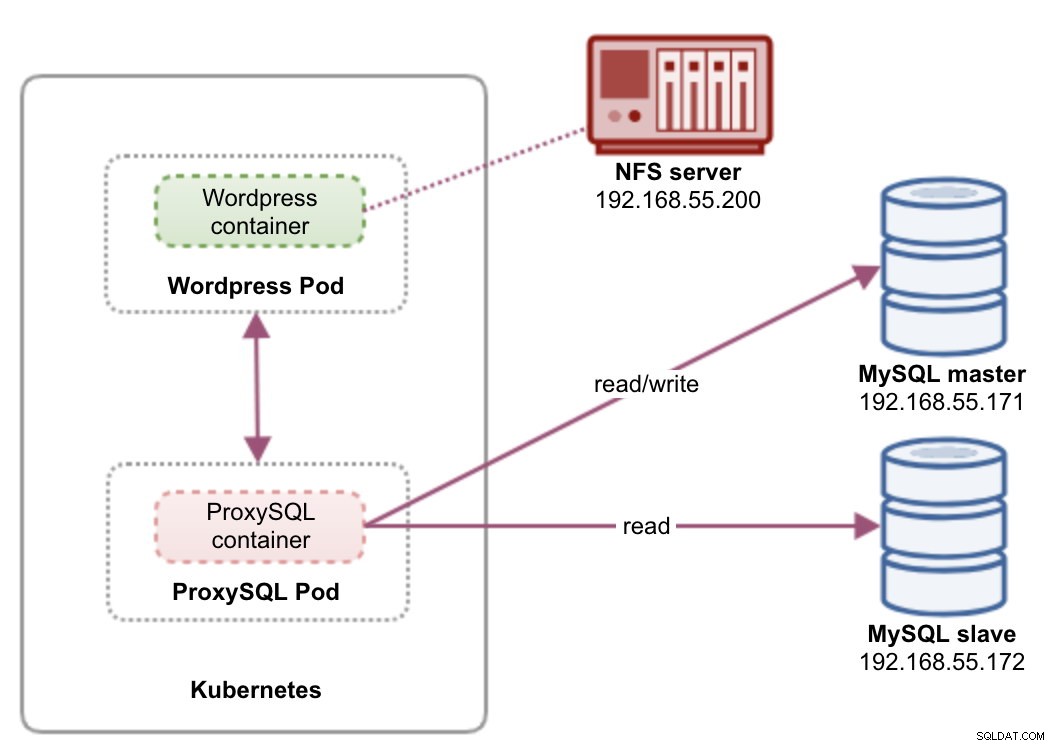
En esta configuración, implementaremos dos pods y servicios:"wordpress" y "proxysql". Fusionaremos la declaración de implementación y servicio en un archivo YAML por aplicación y los administraremos como una sola unidad. Para mantener el contenido de los contenedores de la aplicación persistente en varios nodos, tenemos que usar un sistema de archivos remoto o en clúster, que en este caso es NFS.
La implementación de ProxySQL como un servicio trae un par de cosas buenas sobre el enfoque del contenedor auxiliar:
- Usando el enfoque de Kubernetes ConfigMap, ProxySQL se puede agrupar con una configuración inmutable.
- Kubernetes maneja la recuperación de ProxySQL y equilibra las conexiones a las instancias automáticamente.
- Punto final único con implementación de dirección IP virtual de Kubernetes llamada ClusterIP.
- Nivel de proxy inverso centralizado con arquitectura compartida.
- Se puede usar con aplicaciones externas fuera de Kubernetes.
Comenzaremos la implementación como dos réplicas para ProxySQL y tres para Wordpress para demostrar la ejecución a escala y las capacidades de equilibrio de carga que ofrece Kubernetes.
Preparación de la base de datos
Cree la base de datos de wordpress y el usuario en el maestro y asigne el privilegio correcto:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Además, cree el usuario de supervisión de ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Luego, vuelve a cargar la tabla de subvenciones:
mysql-master> FLUSH PRIVILEGES;Definición de servicio y pod de ProxySQL
El siguiente es preparar nuestra implementación de ProxySQL. Cree un archivo llamado proxysql-rs-svc.yml y agregue las siguientes líneas:
apiVersion: v1
kind: Deployment
metadata:
name: proxysql
labels:
app: proxysql
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: proxysql
tier: frontend
spec:
restartPolicy: Always
containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap
---
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendVeamos de qué se tratan esas definiciones. El YAML consta de dos recursos combinados en un archivo, separados por el delimitador "---". El primer recurso es el Deployment, que definimos con la siguiente especificación:
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdateLo anterior significa que nos gustaría implementar dos pods ProxySQL como un ReplicaSet que coincida con los contenedores etiquetados con "app=proxysql,tier=frontend". La estrategia de implementación especifica la estrategia utilizada para reemplazar los pods antiguos por otros nuevos. En esta implementación, elegimos RollingUpdate, lo que significa que los pods se actualizarán de forma continua, un pod a la vez.
La siguiente parte es la plantilla del contenedor:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmapEn spec.templates.spec.containers.* sección, le estamos diciendo a Kubernetes que implemente ProxySQL usando severalnines/proxysql imagen versión 1.4.12. También queremos que Kubernetes monte nuestro archivo de configuración personalizado y preconfigurado y lo asigne a /etc/proxysql.cnf dentro del contenedor. Los pods en ejecución publicarán dos puertos:6033 y 6032. También definimos la sección de "volúmenes", donde indicamos a Kubernetes que monte el ConfigMap como un volumen dentro de los pods de ProxySQL para ser montado por volumeMounts.
El segundo recurso es el servicio. Un servicio de Kubernetes es una capa de abstracción que define el conjunto lógico de pods y una política para acceder a ellos. En esta sección, definimos lo siguiente:
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendEn este caso, queremos que se acceda a nuestro ProxySQL desde la red externa, por lo que el tipo NodePort es el tipo elegido. Esto publicará el puerto de nodo en todos los nodos de Kubernetes en el clúster. El rango de puertos válidos para el recurso NodePort es 30000-32767. Elegimos el puerto 30033 para las conexiones de carga balanceada de MySQL, que está asignado al puerto 6033 de los pods de ProxySQL, y el puerto 30032 para el puerto de administración de ProxySQL asignado al 6032.
Por lo tanto, según nuestra definición YAML anterior, debemos preparar el siguiente recurso de Kubernetes antes de que podamos comenzar a implementar el pod "proxysql":
- ConfigMap:para almacenar el archivo de configuración de ProxySQL como un volumen para que pueda montarse en varios pods y volver a montarse si el pod se reprograma al otro nodo de Kubernetes.
Preparación de ConfigMap para ProxySQL
Al igual que en la publicación de blog anterior, vamos a utilizar el enfoque de ConfigMap para desacoplar el archivo de configuración del contenedor y también con fines de escalabilidad. Tenga en cuenta que en esta configuración, consideramos que nuestra configuración de ProxySQL es inmutable.
En primer lugar, cree el archivo de configuración de ProxySQL, proxysql.cnf y agregue las siguientes líneas:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="proxysql-admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)Preste atención a las admin_variables.admin_credentials variable donde usamos un usuario no predeterminado que es "proxysql-admin". ProxySQL reserva el usuario "admin" predeterminado para la conexión local solo a través de localhost. Por lo tanto, tenemos que usar otros usuarios para acceder a la instancia de ProxySQL de forma remota. De lo contrario, obtendrías el siguiente error:
ERROR 1040 (42000): User 'admin' can only connect locallyNuestra configuración de ProxySQL se basa en nuestros dos servidores de base de datos que se ejecutan en MySQL Replication, como se resume en la siguiente captura de pantalla de topología tomada de ClusterControl:
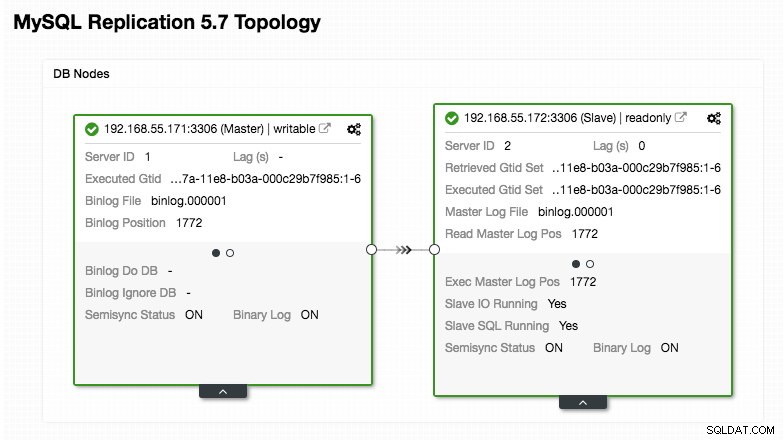
Todas las escrituras deben ir al nodo maestro mientras que las lecturas se reenvían al grupo de host 20, como se define en la sección "mysql_query_rules". Eso es lo básico de la división de lectura/escritura y queremos utilizarlos por completo.
Luego, importe el archivo de configuración a ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdVerifique si el ConfigMap está cargado en Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDefinición de servicio y pod de WordPress
Ahora, pegue las siguientes líneas en un archivo llamado wordpress-rs-svc.yml en el host donde está configurado kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033 # proxysql.default.svc.cluster.local:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_DATABASE
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendSimilar a nuestra definición de ProxySQL, el YAML consta de dos recursos, separados por el delimitador "---" combinados en un archivo. El primero es el recurso de implementación, que se implementará como un conjunto de réplicas, como se muestra en la sección "spec.*":
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdateEsta sección proporciona la especificación de implementación:3 pods para comenzar que coincidan con la etiqueta "app=wordpress,tier=backend". La estrategia de implementación es RollingUpdate, lo que significa que la forma en que Kubernetes reemplazará el pod es mediante el uso de actualizaciones continuas, al igual que nuestra implementación de ProxySQL.
La siguiente parte es la sección "spec.template.spec.*":
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
En esta sección, le decimos a Kubernetes que implemente Wordpress 4.9 usando el servidor web Apache y le dimos al contenedor el nombre "wordpress". El contenedor se reiniciará cada vez que esté inactivo, independientemente del estado. También queremos que Kubernetes pase una serie de variables de entorno:
- WORDPRESS_DB_HOST - El anfitrión de la base de datos MySQL. Como estamos usando ProxySQL como un servicio, el nombre del servicio será el valor de metadata.name que es "proxysql". ProxySQL escucha en el puerto 6033 para conexiones de carga equilibrada de MySQL, mientras que la consola de administración de ProxySQL está en 6032.
- WORDPRESS_DB_USER - Especifique el usuario de la base de datos de wordpress que se ha creado en la sección "Preparación de la base de datos".
- WORDPRESS_DB_PASSWORD - La contraseña para WORDPRESS_DB_USER . Como no queremos exponer la contraseña en este archivo, podemos ocultarla usando Kubernetes Secrets. Aquí le indicamos a Kubernetes que lea el recurso secreto "mysql-pass" en su lugar. Los secretos deben crearse por adelantado antes de la implementación del pod, como se explica más adelante.
También queremos publicar el puerto 80 del pod para el usuario final. El contenido de Wordpress almacenado dentro de /var/www/html en el contenedor se montará en nuestro almacenamiento persistente que se ejecuta en NFS. Usaremos los recursos PersistentVolume y PersistentVolumeClaim para este fin, como se muestra en la sección "Preparación del almacenamiento persistente para Wordpress".
Después de la línea de corte "---", definimos otro recurso llamado Servicio:
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendEn esta configuración, nos gustaría que Kubernetes cree un servicio llamado "wordpress", escuche en el puerto 30088 en todos los nodos (también conocido como NodePort) a la red externa y lo reenvíe al puerto 80 en todos los pods etiquetados con "app=wordpress,tier=interfaz".
Por lo tanto, en función de nuestra definición de YAML anterior, tenemos que preparar una serie de recursos de Kubernetes antes de que podamos comenzar a implementar el pod y el servicio "wordpress":
- Volumen persistente y Reclamación de volumen persistente - Para almacenar los contenidos web de nuestra aplicación Wordpress, de modo que cuando el pod se reprograme a otro nodo trabajador, no perderemos los últimos cambios.
- Secretos - Para ocultar la contraseña de usuario de la base de datos de Wordpress dentro del archivo YAML.
Preparación de almacenamiento persistente para Wordpress
Todos los nodos de Kubernetes del clúster deberían poder acceder a un buen almacenamiento persistente para Kubernetes. Por el bien de esta publicación de blog, usamos NFS como el proveedor PersistentVolume (PV) porque es fácil y compatible de forma inmediata. El servidor NFS está ubicado en algún lugar fuera de nuestra red de Kubernetes (como se muestra en el primer diagrama de arquitectura) y lo hemos configurado para permitir todos los nodos de Kubernetes con la siguiente línea dentro de /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Tenga en cuenta que el paquete de cliente NFS debe estar instalado en todos los nodos de Kubernetes. De lo contrario, Kubernetes no podría montar el NFS correctamente. En todos los nodos:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSAdemás, asegúrese de que en el servidor NFS exista el directorio de destino:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressLuego, crea un archivo llamado wordpress-pv-pvc.yml y agregue las siguientes líneas:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: wordpress
tier: frontendEn la definición anterior, le decimos a Kubernetes que asigne 3 GB de espacio de volumen en el servidor NFS para nuestro contenedor de Wordpress. Tome nota del uso de producción, NFS debe configurarse con aprovisionador automático y clase de almacenamiento.
Cree los recursos PV y PVC:
$ kubectl create -f wordpress-pv-pvc.ymlVerifique si esos recursos están creados y el estado debe ser "Bound":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hPreparando Secretos para Wordpress
Cree un secreto para que lo use el contenedor de Wordpress para WORDPRESS_DB_PASSWORD Variable ambiental. La razón es simplemente porque no queremos exponer la contraseña en texto claro dentro del archivo YAML.
Cree un recurso secreto llamado mysql-pass y pase la contraseña correspondiente:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifica que nuestro secreto esté creado:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mImplementación de ProxySQL y Wordpress
Finalmente, podemos comenzar el despliegue. Implemente ProxySQL primero, seguido de Wordpress:
$ kubectl create -f proxysql-rs-svc.yml
$ kubectl create -f wordpress-rs-svc.ymlA continuación, podemos enumerar todos los pods y servicios que se han creado en el nivel "frontend":
$ kubectl get pods,services -l tier=frontend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
pod/proxysql-95b8d8446-qfbf2 1/1 Running 0 12m 10.36.0.2 kube2.local <none>
pod/proxysql-95b8d8446-vljlr 1/1 Running 0 12m 10.44.0.6 kube3.local <none>
pod/wordpress-59489d57b9-4dzvk 1/1 Running 0 37m 10.36.0.1 kube2.local <none>
pod/wordpress-59489d57b9-7d2jb 1/1 Running 0 30m 10.44.0.4 kube3.local <none>
pod/wordpress-59489d57b9-gw4p9 1/1 Running 0 30m 10.36.0.3 kube2.local <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/proxysql NodePort 10.108.195.54 <none> 6033:30033/TCP,6032:30032/TCP 10m app=proxysql,tier=frontend
service/wordpress NodePort 10.109.144.234 <none> 80:30088/TCP 37m app=wordpress,tier=frontend
kube2.local <none>El resultado anterior verifica nuestra arquitectura de implementación donde actualmente tenemos tres pods de Wordpress, expuestos públicamente en el puerto 30088, así como nuestra instancia de ProxySQL que está expuesta en los puertos 30033 y 30032 externamente más 6033 y 6032 internamente.
En este punto, nuestra arquitectura se parece a esto:
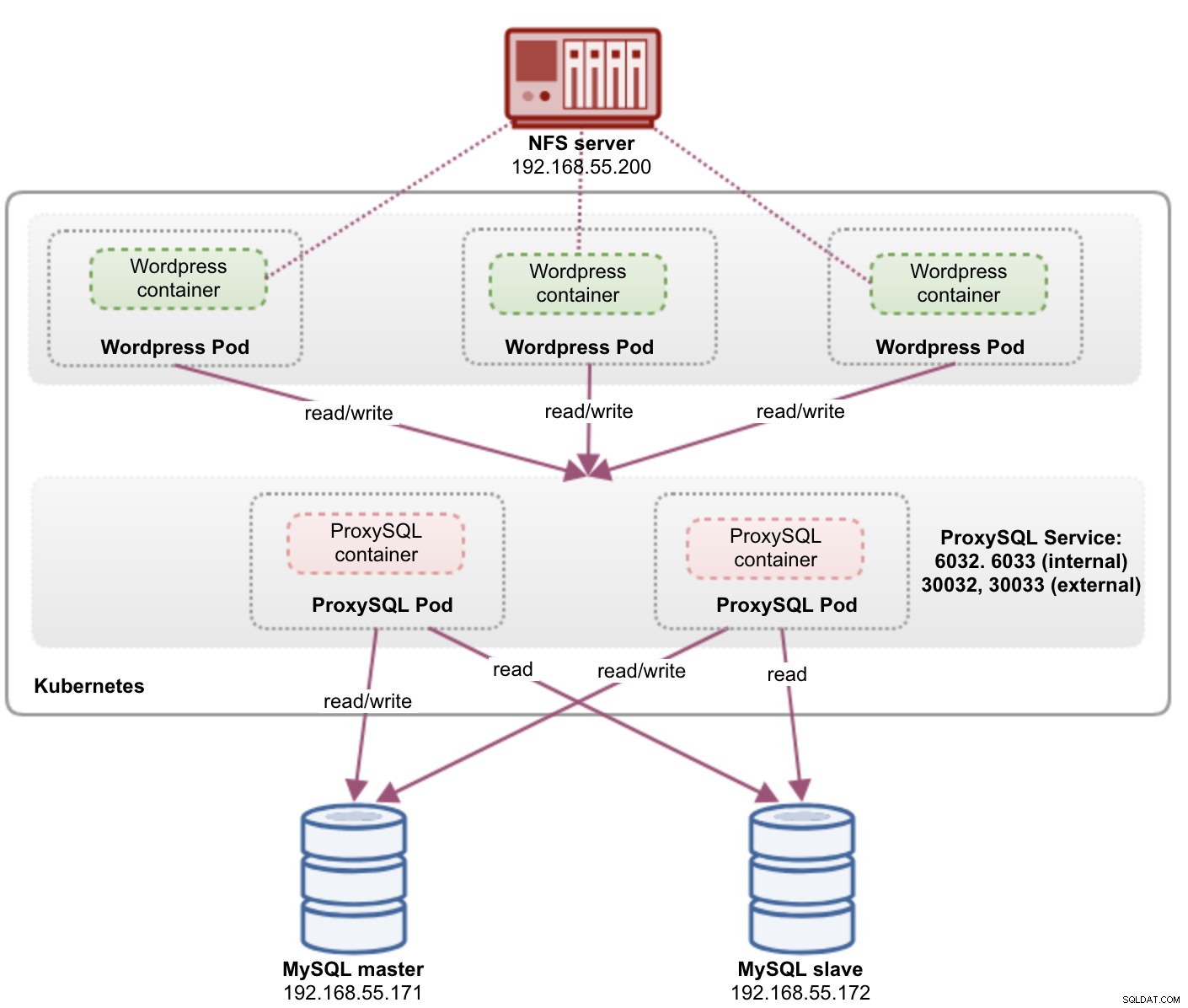
El puerto 80 publicado por los pods de Wordpress ahora está asignado al mundo exterior a través del puerto 30088. Podemos acceder a nuestra publicación de blog en https://{any_kubernetes_host}:30088/ y debe ser redirigido a la página de instalación de Wordpress. Si procedemos con la instalación, se saltaría la parte de conexión a la base de datos y mostraría directamente esta página:
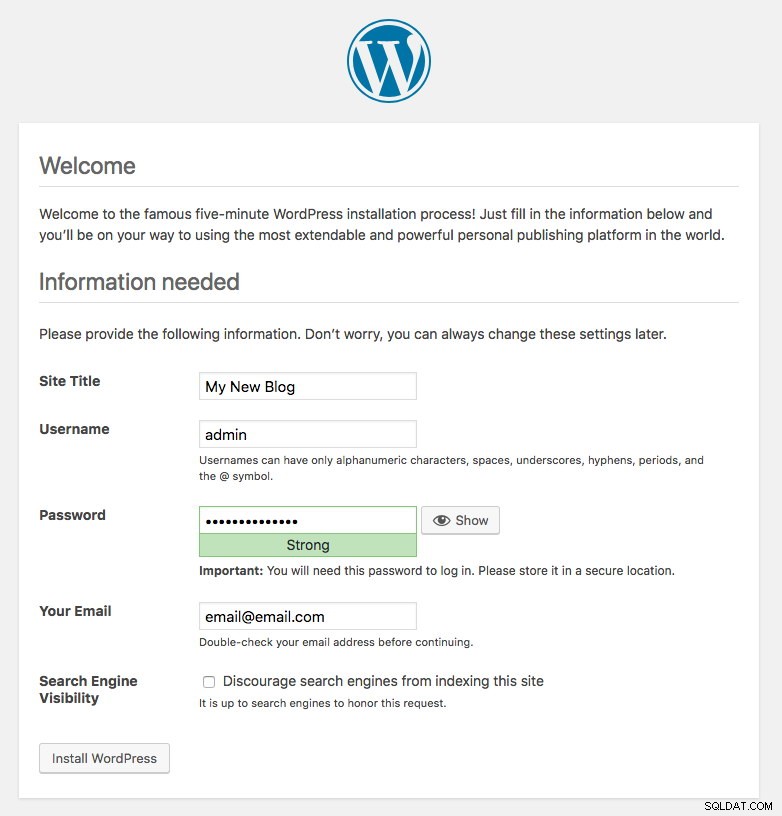
Indica que nuestra configuración de MySQL y ProxySQL está correctamente configurada dentro del archivo wp-config.php. De lo contrario, sería redirigido a la página de configuración de la base de datos.
Nuestro despliegue ahora está completo.
Gestión de servicios y pods de ProxySQL
Se espera que Kubernetes maneje automáticamente la conmutación por error y la recuperación. Por ejemplo, si un trabajador de Kubernetes deja de funcionar, el pod se volverá a crear en el siguiente nodo disponible después de --pod-eviction-timeout (predeterminado en 5 minutos). Si el contenedor falla o muere, Kubernetes lo reemplazará casi al instante.
Se espera que algunas tareas de administración comunes sean diferentes cuando se ejecutan dentro de Kubernetes, como se muestra en las siguientes secciones.
Conexión a ProxySQL
Si bien ProxySQL está expuesto externamente en el puerto 30033 (MySQL) y 30032 (Admin), también se puede acceder a él internamente a través de los puertos publicados, 6033 y 6032 respectivamente. Por lo tanto, para acceder a las instancias de ProxySQL dentro de la red de Kubernetes, use el CLUSTER-IP o el nombre de servicio "proxysql" como valor de host. Por ejemplo, dentro del pod de Wordpress, puede acceder a la consola de administración de ProxySQL usando el siguiente comando:
$ mysql -uproxysql-admin -p -hproxysql -P6032Si desea conectarse externamente, use el puerto definido en el valor nodePort del servicio YAML y seleccione cualquiera de los nodos de Kubernetes como valor de host:
$ mysql -uproxysql-admin -p -hkube3.local -P30032Lo mismo se aplica a la conexión de equilibrio de carga de MySQL en el puerto 30033 (externo) y 6033 (interno).
Ampliar y reducir
Ampliar es fácil con Kubernetes:
$ kubectl scale deployment proxysql --replicas=5
deployment.extensions/proxysql scaledVerifique el estado de implementación:
$ kubectl rollout status deployment proxysql
deployment "proxysql" successfully rolled outLa reducción también es similar. Aquí queremos volver de 5 a 2 réplicas:
$ kubectl scale deployment proxysql --replicas=2
deployment.extensions/proxysql scaledTambién podemos ver los eventos de implementación de ProxySQL para obtener una mejor idea de lo que sucedió en esta implementación usando la opción "describir":
$ kubectl describe deployment proxysql
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 0
Normal ScalingReplicaSet 7m10s deployment-controller Scaled up replica set proxysql-6c55f647cb to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled down replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set proxysql-6c55f647cb to 2
Normal ScalingReplicaSet 6m53s deployment-controller Scaled down replica set proxysql-769895fbf7 to 0
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set proxysql-6c55f647cb to 5
Normal ScalingReplicaSet 21s deployment-controller Scaled down replica set proxysql-6c55f647cb to 2Kubernetes equilibrará automáticamente la carga de las conexiones a los pods.
Cambios de configuración
Una forma de realizar cambios de configuración en nuestros pods de ProxySQL es versionar nuestra configuración con otro nombre de ConfigMap. En primer lugar, modifique nuestro archivo de configuración directamente a través de su editor de texto favorito:
$ vim /root/proxysql.cnfLuego, cárguelo en Kubernetes ConfigMap con un nombre diferente. En este ejemplo, agregamos "-v2" en el nombre del recurso:
$ kubectl create configmap proxysql-configmap-v2 --from-file=proxysql.cnfVerifique si el ConfigMap está cargado correctamente:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 3d15h
proxysql-configmap-v2 1 19mAbra el archivo de implementación de ProxySQL, proxysql-rs-svc.yml y cambie la siguiente línea en la sección configMap a la nueva versión:
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap-v2 #change this lineLuego, aplique los cambios a nuestra implementación de ProxySQL:
$ kubectl apply -f proxysql-rs-svc.yml
deployment.apps/proxysql configured
service/proxysql configuredVerifique el despliegue mirando el evento ReplicaSet usando el indicador "describir":
$ kubectl describe proxysql
...
Pod Template:
Labels: app=proxysql
tier=frontend
Containers:
proxysql:
Image: severalnines/proxysql:1.4.12
Ports: 6033/TCP, 6032/TCP
Host Ports: 0/TCP, 0/TCP
Environment: <none>
Mounts:
/etc/proxysql.cnf from proxysql-config (rw)
Volumes:
proxysql-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: proxysql-configmap-v2
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: proxysql-769895fbf7 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 53s deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 41s deployment-controller Scaled down replica set proxysql-95b8d8446 to 0Preste atención a la sección "Volúmenes" con el nuevo nombre de ConfigMap. También puede ver los eventos de implementación en la parte inferior de la salida. En este punto, nuestra nueva configuración se cargó en todos los pods de ProxySQL, donde Kubernetes redujo el ProxySQL ReplicaSet a 0 (obedeciendo la estrategia RollingUpdate) y los devolvió al estado deseado de 2 réplicas.
Reflexiones finales
Hasta este punto, hemos cubierto el posible enfoque de implementación de ProxySQL en Kubernetes. Ejecutar ProxySQL con la ayuda de Kubernetes ConfigMap abre una nueva posibilidad de agrupamiento de ProxySQL, donde es algo diferente en comparación con el soporte nativo de agrupamiento integrado dentro de ProxySQL.
En la próxima publicación del blog, exploraremos la agrupación en clústeres de ProxySQL con Kubernetes ConfigMap y cómo hacerlo de la manera correcta. ¡Estén atentos!