Mi amigo Peter Larsson me envió un desafío de T-SQL que implicaba hacer coincidir la oferta con la demanda. En cuanto a los desafíos, es formidable. Es una necesidad bastante común en la vida real; es simple de describir y bastante fácil de resolver con un rendimiento razonable usando una solución basada en cursor. La parte difícil es resolverlo usando una solución eficiente basada en conjuntos.
Cuando Peter me envía un acertijo, generalmente respondo con una solución sugerida y, por lo general, se le ocurre una solución brillante y de mejor rendimiento. A veces sospecho que me envía acertijos para motivarse a encontrar una gran solución.
Dado que la tarea representa una necesidad común y es tan interesante, le pregunté a Peter si le importaría que la compartiera junto con sus soluciones con los lectores de sqlperformance.com, y estuvo feliz de dejarme.
Este mes, presentaré el desafío y la solución clásica basada en cursores. En artículos posteriores, presentaré soluciones basadas en conjuntos, incluidas aquellas en las que trabajamos Peter y yo.
El desafío
El desafío consiste en consultar una tabla llamada Subastas, que se crea con el siguiente código:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Esta tabla contiene entradas de oferta y demanda. Las entradas de demanda están marcadas con el código D y las entradas de oferta con S. Su tarea es hacer coincidir las cantidades de oferta y demanda según el pedido de identificación, escribiendo el resultado en una tabla temporal. Las entradas pueden representar órdenes de compra y venta de criptomonedas como BTC/USD, órdenes de compra y venta de acciones como MSFT/USD, o cualquier otro artículo o bien en el que necesite hacer coincidir la oferta con la demanda. Observe que a las entradas de Subastas les falta un atributo de precio. Como se mencionó, debe hacer coincidir las cantidades de oferta y demanda según el pedido de ID. Este orden podría haberse derivado del precio (ascendente para entradas de oferta y descendente para entradas de demanda) o cualquier otro criterio relevante. En este desafío, la idea era mantener las cosas simples y asumir que la identificación ya representa el orden relevante para la coincidencia.
Como ejemplo, use el siguiente código para llenar la tabla Subastas con un pequeño conjunto de datos de muestra:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Se supone que debes hacer coincidir las cantidades de oferta y demanda de la siguiente manera:
- Se iguala una cantidad de 5,0 para la Demanda 1 y la Oferta 1000, agotando la Demanda 1 y dejando 3,0 de la Oferta 1000
- Se iguala una cantidad de 3,0 para la Demanda 2 y la Oferta 1000, agotando tanto la Demanda 2 como la Oferta 1000
- Se iguala una cantidad de 6,0 para la Demanda 3 y la Oferta 2000, dejando 2,0 de la Demanda 3 y agotando la oferta 2000
- Se iguala una cantidad de 2,0 para la Demanda 3 y la Oferta 3000, agotando tanto la Demanda 3 como la Oferta 3000
- Se iguala una cantidad de 2,0 para la Demanda 5 y la Oferta 4000, agotando tanto la Demanda 5 como la Oferta 4000
- Se iguala una cantidad de 4,0 para Demanda 6 y Oferta 5000, dejando 4,0 de Demanda 6 y agotando Oferta 5000
- Se iguala una cantidad de 3,0 para Demanda 6 y Oferta 6000, dejando 1,0 de Demanda 6 y agotando Oferta 6000
- Se iguala una cantidad de 1,0 para Demanda 6 y Oferta 7000, agotando Demanda 6 y dejando 1,0 de Oferta 7000
- Se iguala una cantidad de 1,0 para Demanda 7 y Oferta 7000, dejando 3,0 de Demanda 7 y agotando Oferta 7000; La Demanda 8 no coincide con ninguna entrada de Suministro y, por lo tanto, queda con la cantidad total 2.0
Se supone que su solución debe escribir los siguientes datos en la tabla temporal resultante:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Gran conjunto de datos de muestra
Para probar el rendimiento de las soluciones, necesitará un conjunto más grande de datos de muestra. Para ayudar con esto, puede usar la función GetNums, que crea ejecutando el siguiente código:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Esta función devuelve una secuencia de enteros en el rango solicitado.
Con esta función implementada, puede usar el siguiente código proporcionado por Peter para completar la tabla Subastas con datos de muestra, personalizando las entradas según sea necesario:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Como puede ver, puede personalizar el número de compradores y vendedores, así como las cantidades mínimas y máximas de compradores y vendedores. El código anterior especifica 200 000 compradores y 200 000 vendedores, lo que da como resultado un total de 400 000 filas en la tabla Subastas. La última consulta le dice cuántas entradas de demanda (D) y suministro (S) se escribieron en la tabla. Devuelve el siguiente resultado para las entradas antes mencionadas:
Code Items ---- ----------- D 200000 S 200000
Voy a probar el rendimiento de varias soluciones utilizando el código anterior, estableciendo el número de compradores y vendedores de cada uno de los siguientes:50 000, 100 000, 150 000 y 200 000. Esto significa que obtendré los siguientes números totales de filas en la tabla:100 000, 200 000, 300 000 y 400 000. Por supuesto, puede personalizar las entradas como desee para probar el rendimiento de sus soluciones.
Solución basada en cursor
Peter proporcionó la solución basada en cursores. Es bastante básico, que es una de sus ventajas importantes. Se utilizará como punto de referencia.
La solución utiliza dos cursores:uno para entradas de demanda ordenadas por ID y otro para entradas de oferta ordenadas por ID. Para evitar un escaneo completo y una ordenación por cursor, cree el siguiente índice:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Aquí está el código de la solución completa:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Como puede ver, el código comienza creando una tabla temporal. Luego declara los dos cursores y obtiene una fila de cada uno, escribiendo la cantidad de demanda actual en la variable @DemandQuantity y la cantidad de suministro actual en @SupplyQuantity. Luego procesa las entradas en un bucle siempre que la última búsqueda haya sido exitosa. El código aplica la siguiente lógica en el cuerpo del ciclo:
Si la cantidad de demanda actual es menor o igual que la cantidad de oferta actual, el código hace lo siguiente:
- Escribe una fila en la tabla temporal con el emparejamiento actual, con la cantidad de demanda (@DemandQuantity) como la cantidad coincidente
- Resta la cantidad de demanda actual de la cantidad de oferta actual (@SupplyQuantity)
- Obtiene la siguiente fila del cursor de demanda
De lo contrario, el código hace lo siguiente:
- Comprueba si la cantidad de suministro actual es mayor que cero y, de ser así, hace lo siguiente:
- Escribe una fila en la tabla temporal con el emparejamiento actual, con la cantidad de suministro como la cantidad coincidente
- Resta la cantidad de suministro actual de la cantidad de demanda actual
- Obtiene la siguiente fila del cursor de suministro
Una vez que se completa el ciclo, no hay más pares para hacer coincidir, por lo que el código simplemente limpia los recursos del cursor.
Desde el punto de vista del rendimiento, obtiene la sobrecarga típica de la búsqueda y el bucle del cursor. Por otra parte, esta solución realiza un solo paso ordenado sobre los datos de demanda y un solo paso ordenado sobre los datos de oferta, cada uno utilizando un escaneo de búsqueda y rango en el índice que creó anteriormente. Los planes para las consultas de cursor se muestran en la Figura 1.

Figura 1:Planes para consultas de cursor
Dado que el plan realiza un escaneo de rango ordenado y de búsqueda de cada una de las partes (demanda y suministro) sin clasificación involucrada, tiene una escala lineal. Esto fue confirmado por los números de rendimiento que obtuve al probarlo, como se muestra en la Figura 2.
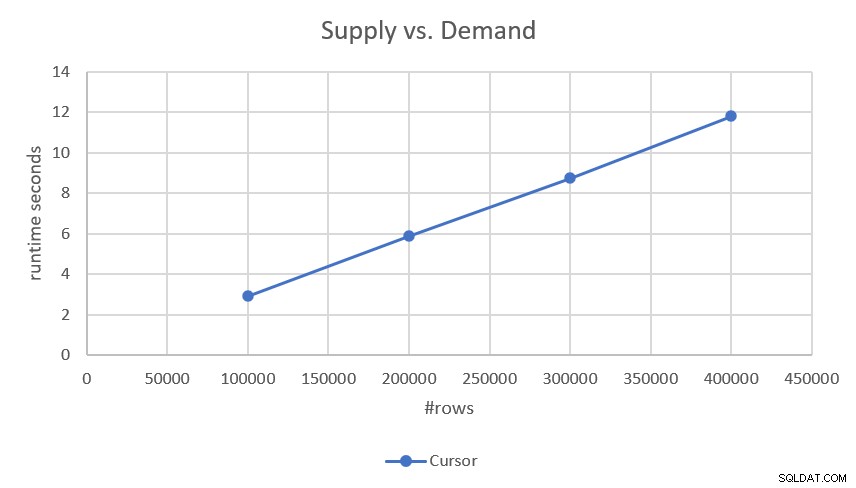
Figura 2:Rendimiento de la solución basada en cursores
Si está interesado en los tiempos de ejecución más precisos, aquí están:
- 100.000 filas (50.000 demandas y 50.000 suministros):2,93 segundos
- 200.000 filas:5,89 segundos
- 300.000 filas:8,75 segundos
- 400.000 filas:11,81 segundos
Dado que la solución tiene una escala lineal, puede predecir fácilmente el tiempo de ejecución con otras escalas. Por ejemplo, con un millón de filas (digamos, 500 000 demandas y 500 000 suministros), debería tardar unos 29,5 segundos en ejecutarse.
El desafío está en marcha
La solución basada en cursor tiene una escala lineal y, como tal, no está mal. Pero incurre en la sobrecarga típica de búsqueda y bucle del cursor. Obviamente, puede reducir esta sobrecarga implementando el mismo algoritmo utilizando una solución basada en CLR. La pregunta es, ¿puede encontrar una solución basada en conjuntos que funcione bien para esta tarea?
Como mencioné, exploraré soluciones basadas en conjuntos, tanto de bajo rendimiento como de buen rendimiento, a partir del próximo mes. Mientras tanto, si está preparado para el desafío, vea si puede encontrar sus propias soluciones basadas en conjuntos.
Para verificar la corrección de su solución, primero compare su resultado con el que se muestra aquí para el pequeño conjunto de datos de muestra. También puede verificar la validez del resultado de su solución con un gran conjunto de datos de muestra verificando que la diferencia simétrica entre el resultado de la solución del cursor y el suyo esté vacía. Suponiendo que el resultado del cursor se almacena en una tabla temporal llamada #PairingsCursor y el suyo en una tabla temporal llamada #MyPairings, puede usar el siguiente código para lograrlo:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
El resultado debe estar vacío.
¡Buena suerte!
[ Saltar a soluciones:Parte 1 | Parte 2 | Parte 3 ]