Uno de los casos de uso del índice filtrado mencionado en Books Online se refiere a una columna que contiene principalmente NULLs valores. La idea es crear un índice filtrado que excluya los NULLs , lo que da como resultado un índice no agrupado más pequeño que requiere menos mantenimiento que el índice equivalente sin filtrar. Otro uso popular de los índices filtrados es filtrar NULLs de un UNIQUE index, brindando el comportamiento que los usuarios de otros motores de base de datos podrían esperar de un UNIQUE predeterminado índice o restricción:la unicidad se aplica solo para el no NULLs valores.
Desafortunadamente, el optimizador de consultas tiene limitaciones en lo que respecta a los índices filtrados. Esta publicación analiza un par de ejemplos menos conocidos.
Tablas de muestra
Usaremos dos tablas (A y B) que tienen la misma estructura:una clave principal agrupada sustituta, una mayormente NULLs columna que es única (sin tener en cuenta NULLs ) y una columna de relleno que representa las otras columnas que podrían estar en una tabla real.
La columna de interés es mayormente NULLs uno, que he declarado como SPARSE . La opción escasa no es obligatoria, solo la incluyo porque no tengo muchas posibilidades de usarla. En cualquier caso, SPARSE probablemente tenga sentido en muchos escenarios donde se espera que los datos de la columna sean en su mayoría NULLs . Si lo desea, puede eliminar el atributo disperso de los ejemplos.
CREATE TABLE dbo.TableA
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
CREATE TABLE dbo.TableB
(
pk integer IDENTITY PRIMARY KEY,
data bigint SPARSE NULL,
padding binary(250) NOT NULL DEFAULT 0x
);
Cada tabla contiene los números del 1 al 2000 en la columna de datos con 40 000 filas adicionales donde la columna de datos es NULLs :
-- Numbers 1 - 2,000
INSERT
dbo.TableA WITH (TABLOCKX)
(data)
SELECT TOP (2000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2
ORDER BY
ROW_NUMBER() OVER (ORDER BY (SELECT NULL));
-- NULLs
INSERT TOP (40000)
dbo.TableA WITH (TABLOCKX)
(data)
SELECT
CONVERT(bigint, NULL)
FROM sys.columns AS c
CROSS JOIN sys.columns AS c2;
-- Copy into TableB
INSERT dbo.TableB WITH (TABLOCKX)
(data)
SELECT
ta.data
FROM dbo.TableA AS ta;
Ambas tablas obtienen un UNIQUE índice filtrado para los 2000 no NULLs valores de datos:
CREATE UNIQUE NONCLUSTERED INDEX uqA ON dbo.TableA (data) WHERE data IS NOT NULL; CREATE UNIQUE NONCLUSTERED INDEX uqB ON dbo.TableB (data) WHERE data IS NOT NULL;
La salida de DBCC SHOW_STATISTICS resume la situación:
DBCC SHOW_STATISTICS (TableA, uqA) WITH STAT_HEADER; DBCC SHOW_STATISTICS (TableB, uqB) WITH STAT_HEADER;

Consulta de muestra
La consulta a continuación realiza una unión simple de las dos tablas:imagine que las tablas están en algún tipo de relación padre-hijo y muchas de las claves externas son NULL. Algo por el estilo de todos modos.
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data; Plan de ejecución predeterminado
Con SQL Server en su configuración predeterminada, el optimizador elige un plan de ejecución con una combinación de bucles anidados paralelos:
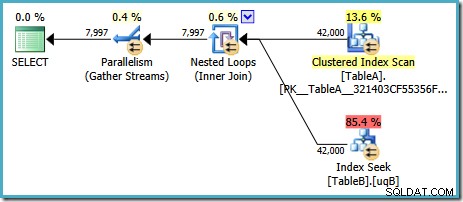
Este plan tiene un costo estimado de 7.7768 unidades magic Optimizer™.
Sin embargo, hay algunas cosas extrañas en este plan. Index Seek usa nuestro índice filtrado en la tabla B, pero la consulta está impulsada por un escaneo de índice agrupado de la tabla A. El predicado de unión es una prueba de igualdad en las columnas de datos, que rechazará NULLs (independientemente del ANSI_NULLS entorno). Podríamos haber esperado que el optimizador realizara algún razonamiento avanzado basado en esa observación, pero no. Este plan lee cada fila de la tabla A (incluidos los 40 000 NULLs ), realiza una búsqueda en el índice filtrado en la tabla B para cada uno, basándose en el hecho de que NULLs no coincidirá con NULLs en esa busqueda. Esta es una tremenda pérdida de esfuerzo.
Lo extraño es que el optimizador debe haberse dado cuenta de que la combinación rechaza NULLs para elegir el índice filtrado para la tabla B busque, pero no pensó en filtrar NULLs de la tabla A primero, o mejor aún, simplemente escanear el NULLs -índice filtrado libre en la tabla A. Quizás se pregunte si esta es una decisión basada en costos, ¿quizás las estadísticas no son muy buenas? ¿Quizás deberíamos forzar el uso del índice filtrado con una pista? Indicar el índice filtrado en la tabla A solo da como resultado el mismo plan con los roles invertidos:escanear la tabla B y buscar en la tabla A. Forzar el índice filtrado para ambas tablas produce error 8622 :el procesador de consultas no pudo producir un plan de consulta.
Agregar un predicado NOT NULL
Sospechar que la causa tiene algo que ver con el NULLs implícito -rechazo del predicado de unión, agregamos un NOT NULL explícito predicado al ON cláusula (o el WHERE cláusula si lo prefiere, se trata de lo mismo aquí):
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL;
Añadimos el NOT NULL verifique la columna de la tabla A porque el plan original escaneó el índice agrupado de esa tabla en lugar de usar nuestro índice filtrado (la búsqueda en la tabla B estuvo bien; sí usó el índice filtrado). La nueva consulta es semánticamente exactamente igual a la anterior, pero el plan de ejecución es diferente:
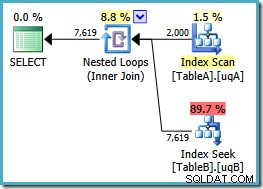
Ahora tenemos el escaneo esperado del índice filtrado en la tabla A, que produce 2,000 no NULLs filas para impulsar las búsquedas de bucle anidado en la tabla B. Ambas tablas están utilizando nuestros índices filtrados aparentemente de manera óptima ahora:el nuevo plan cuesta solo 0.362835 unidades (por debajo de 7.7768). Sin embargo, podemos hacerlo mejor.
Agregar dos predicados NOT NULL
El redundante NOT NULL el predicado de la tabla A hizo maravillas; ¿Qué sucede si también agregamos uno para la tabla B?
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL; Esta consulta sigue siendo lógicamente la misma que los dos esfuerzos anteriores, pero el plan de ejecución es diferente nuevamente:
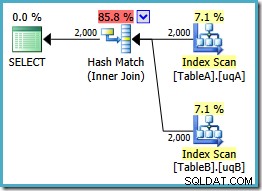
Este plan crea una tabla hash para las 2000 filas de la tabla A, luego busca coincidencias usando las 2000 filas de la tabla B. El número estimado de filas devueltas es mucho mejor que el plan anterior (¿observó la estimación de 7619 allí?) y el costo de ejecución estimado ha vuelto a caer, de 0,362835 a 0,0772056 .
Podría intentar forzar una unión hash utilizando una pista en el original o NOT NULL único consultas, pero no obtendrá el plan de bajo costo que se muestra arriba. El optimizador simplemente no tiene la capacidad de razonar completamente sobre el NULLs -rechazar el comportamiento de la combinación tal como se aplica a nuestros índices filtrados sin ambos predicados redundantes.
Puedes sorprenderte por esto, incluso si es solo la idea de que un predicado redundante no fue suficiente (seguramente si ta.data es NOT NULL y ta.data = tb.data , se deduce que tb.data es también NOT NULL , ¿verdad?)
Todavía no es perfecto
Es un poco sorprendente ver un hash unirse allí. Si está familiarizado con las principales diferencias entre los tres operadores de combinación física, probablemente sepa que la combinación hash es una de las principales candidatas donde:
- La entrada preordenada no está disponible
- La entrada de compilación hash es más pequeña que la entrada de la sonda
- La entrada de la sonda es bastante grande
Ninguna de estas cosas es cierta aquí. Nuestra expectativa sería que el mejor plan para esta consulta y conjunto de datos sería una combinación de combinación, explotando la entrada ordenada disponible de nuestros dos índices filtrados. Podemos intentar insinuar una combinación de fusión, conservando los dos ON adicionales predicados de la cláusula:
SELECT
ta.data,
tb.data
FROM dbo.TableA AS ta
JOIN dbo.TableB AS tb
ON ta.data = tb.data
AND ta.data IS NOT NULL
AND tb.data IS NOT NULL
OPTION (MERGE JOIN); La forma del plano es como esperábamos:
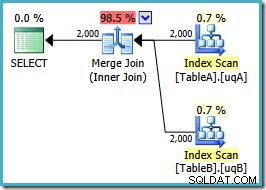
Un escaneo ordenado de ambos índices filtrados, excelentes estimaciones de cardinalidad, fantástico. Solo un pequeño problema:este plan de ejecución es mucho peor; el coste estimado ha saltado de 0,0772056 a 0,741527 . El motivo del salto en el costo estimado se revela al verificar las propiedades del operador de combinación de fusión:
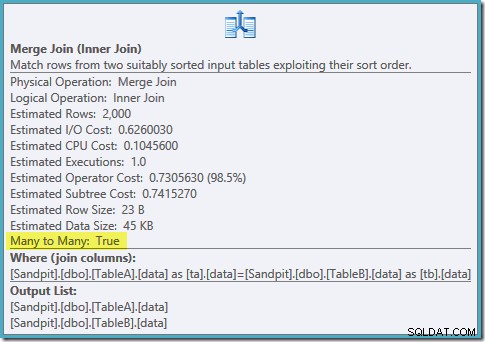
Esta es una combinación costosa de muchos a muchos, donde el motor de ejecución debe realizar un seguimiento de los duplicados de la entrada externa en una mesa de trabajo y rebobinar según sea necesario. ¿Duplicados? ¡Estamos escaneando un índice único! Resulta que el optimizador no sabe que un índice único filtrado produce valores únicos (conectar artículo aquí). De hecho, se trata de una unión uno a uno, pero el optimizador cuesta como si fuera muchos a muchos, lo que explica por qué prefiere el plan de unión hash.
Una estrategia alternativa
Parece que seguimos enfrentándonos a las limitaciones del optimizador cuando usamos índices filtrados aquí (a pesar de que es un caso de uso destacado en Books Online). ¿Qué sucede si intentamos usar vistas en su lugar?
Uso de vistas
Las siguientes dos vistas solo filtran las tablas base para mostrar las filas donde la columna de datos es NOT NULL :
CREATE VIEW dbo.VA
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableA
WHERE data IS NOT NULL;
GO
CREATE VIEW dbo.VB
WITH SCHEMABINDING AS
SELECT
pk,
data,
padding
FROM dbo.TableB
WHERE data IS NOT NULL; Reescribir la consulta original para usar las vistas es trivial:
SELECT
v.data,
v2.data
FROM dbo.VA AS v
JOIN dbo.VB AS v2
ON v.data = v2.data; Recuerde que esta consulta produjo originalmente un plan de bucles anidados paralelos con un costo de 7,7768 unidades. Con las referencias de vista, obtenemos este plan de ejecución:
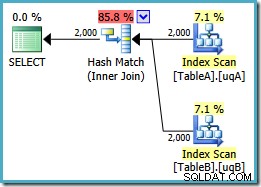
Este es exactamente el mismo plan de combinación hash que tuvimos que agregar NOT NULL redundante predicados para obtener con los índices filtrados (el costo es 0.0772056 unidades como antes). Esto se esperaba, porque todo lo que hemos hecho esencialmente aquí es empujar el extra NOT NULL predicados de la consulta a una vista.
Indización de las vistas
También podemos intentar materializar las vistas creando un índice agrupado único en la columna pk:
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VA (pk); CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.VB (pk);
Ahora podemos agregar índices no agrupados únicos en la columna de datos filtrados en la vista indexada:
CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VA (data); CREATE UNIQUE NONCLUSTERED INDEX ix ON dbo.VB (data);
Observe que el filtrado se realiza en la vista, estos índices no agrupados no se filtran.
El plan perfecto
Ahora estamos listos para ejecutar nuestra consulta en la vista, usando NOEXPAND sugerencia de tabla:
SELECT
v.data,
v2.data
FROM dbo.VA AS v WITH (NOEXPAND)
JOIN dbo.VB AS v2 WITH (NOEXPAND)
ON v.data = v2.data; El plan de ejecución es:
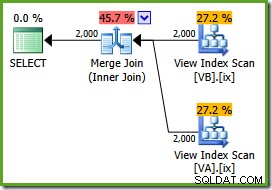
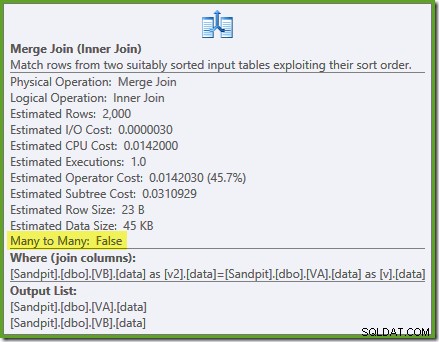
El optimizador puede ver el sin filtrar los índices de vista no agrupados son únicos, por lo que no se necesita una combinación de combinación de muchos a muchos. Este plan de ejecución final tiene un coste estimado de 0,0310929 unidades, incluso más bajo que el plan hash join (0.0772056 unidades). Esto valida nuestra expectativa de que una combinación de combinación debe tener el costo estimado más bajo para esta consulta y conjunto de datos de muestra.
El NOEXPAND se necesitan sugerencias incluso en Enterprise Edition para garantizar que el optimizador utilice la garantía de unicidad proporcionada por los índices de vista.
Resumen
Esta publicación destaca dos importantes limitaciones del optimizador con índices filtrados:
- Los predicados de combinación redundantes pueden ser necesarios para hacer coincidir los índices filtrados
- Los índices únicos filtrados no proporcionan información de unicidad al optimizador
En algunos casos, puede ser práctico simplemente agregar los predicados redundantes a cada consulta. La alternativa es encapsular los predicados implícitos deseados en una vista sin indexar. El plan de coincidencia de hash en esta publicación fue mucho mejor que el plan predeterminado, aunque el optimizador debería poder encontrar el plan de combinación de combinación ligeramente mejor. A veces, es posible que deba indexar la vista y usar NOEXPAND sugerencias (obligatorio de todos modos para las instancias de la Edición estándar). En otras circunstancias, ninguno de estos enfoques será adecuado. Lo siento :)