Me considero un poco explorador. En ciertas cosas eso es. Por lo general, siempre pido la misma comida en un restaurante conocido porque el miedo a la decepción supera mi aprensión a probar algo nuevo.
Y, por supuesto, un humano hambriento tiende a comer bien, ¿verdad?
Sin embargo, cuando se trata de tecnología, en particular SQL (PostgreSQL), tiendo a tropezar a toda velocidad (mi definición de exploración) a menudo en áreas desconocidas, con la esperanza de aprender. ¿Qué mejor manera de aprender que experimentando?
Entonces, ¿qué demonios tiene que ver esta divagación con la replicación lógica y de transmisión en PostgreSQL?
Soy un completo novato en estas áreas con cero conocimiento. Sí, tengo tanto conocimiento en esta área de Postgres como en astrofísica.
¿Mencioné que no tenía conocimiento?
Por lo tanto, en esta publicación de blog, intentaré digerir las diferencias en estos tipos de replicación. Sin experiencia práctica en el mundo real, no puedo prometerle el 'Be all end all ' manuscrito para replicación.
Probablemente, otras personas menos versadas en esta área en particular (como yo) se beneficiarían de esta publicación de blog.
Usuarios experimentados y desarrolladores a lo largo del viaje, espero verlos en los comentarios a continuación.
Un par de definiciones básicas
En el sentido amplio del término, ¿qué significa replicación?
La replicación, tal como se define en Wikcionario, dice lo siguiente:
"Proceso por el cual un objeto, persona, lugar o idea puede ser copiado, imitado o reproducido".
Sin embargo, el quinto elemento de la lista es más aplicable a esta publicación de blog y creo que también deberíamos analizarlo:
"(informática) El proceso de copia frecuente de datos electrónicos de una base de datos en una computadora o servidor a una base de datos en otra para que todos los usuarios compartan el mismo nivel de información. Se utiliza para mejorar la tolerancia a fallas del sistema".
Ahora hay algo en lo que podemos entrar. ¿La mención de copiar datos de un servidor o base de datos a otro? Estamos en territorio familiar ahora...
Entonces, agregando lo que sabemos de esa definición, ¿cuáles son las definiciones de Streaming Replication y Logical Replication?
Veamos lo que PostgreSQL Wiki tiene para ofrecer:
Streaming Replication:"brinda la capacidad de enviar y aplicar continuamente los registros WAL XLOG a una cierta cantidad de servidores en espera para mantenerlos actualizados.
Y la documentación de PostgreSQL tiene esta definición para la replicación lógica:
"La replicación lógica es un método para replicar objetos de datos y sus cambios, en función de su identidad de replicación (generalmente una clave principal). Usamos el término lógica en contraste con la replicación física, que usa direcciones de bloque exactas y replicación byte por byte. "
La replicación del Capítulo 19.6 de la documentación oficial también está repleta de ventajas, así que asegúrese de visitar esa fuente.
A continuación, intentaré transmitir las diferencias en términos sencillos. (Recuerde, si tropiezo, soy un novato). Esta es una descripción general extrema de 'alto nivel'.
Replicación lógica
Una base de datos "fuente" crea una PUBLICACIÓN mediante el comando CREAR PUBLICACIÓN. (Pienso en esto en términos simples como el 'remitente').
La documentación lo denomina editor.
Esta base de datos del editor tiene los datos que queremos replicar. Sin embargo, debemos tener algo para replicar y aquí es donde entran las contrapartes del editor. El 'suscriptor'. Tenga en cuenta que incluí una forma plural alternativa porque, por lo que he encontrado a través de búsquedas en línea, es una configuración práctica para tener múltiples suscriptores.
Un 'suscriptor' (también podría considerarse como la base de datos réplica) crea una SUSCRIPCIÓN a una base de datos "fuente" (editor) que define la información de conexión y cualquier publicación a la que se suscriba.
Es posible que un suscriptor sea también editor, creando su propia PUBLICACIÓN a la que pueden suscribirse otros suscriptores.
¿Qué pasa ahora?
Cualquier cambio de datos que ocurra en el publicador se envía al suscriptor. Lo cual, listo para usar, lo es todo, pero puede configurarse o limitarse a ciertas operaciones (es decir, INSERTAR, ACTUALIZAR o ELIMINAR).
Ejemplo de alto nivel:
Supongamos que actualizamos una fila o varias filas en una tabla particular en el publicador, esas actualizaciones y cambios se replican en la instancia del suscriptor o en varios suscriptores si se implementa ese tipo de configuración.
Aquí hay algunas cosas para recordar que me sentí digno de mencionar:
- La configuración wal_level de la base de datos del editor debe establecerse en lógica.
- La replicación lógica no tiene ningún comando DDL (lenguaje de definición de datos).
- De la página Conflictos en la documentación:"La replicación lógica se comporta de manera similar a las operaciones DML normales en el sentido de que los datos se actualizarán incluso si se cambiaron localmente en el nodo del suscriptor. Si los datos entrantes violan alguna restricción, la replicación se detendrá. Esto se conoce como un conflicto. Al replicar operaciones UPDATE o DELETE, los datos faltantes no producirán un conflicto y tales operaciones simplemente se omitirán".
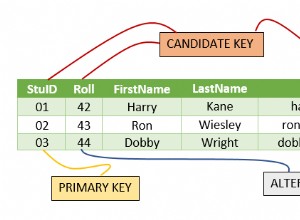
- Las tablas del publicador deben tener una forma de identificarse (llamada "identidad de réplica") para poder replicar correctamente las operaciones DML (ACTUALIZAR y ELIMINAR) en cualquier réplica de las filas afectadas. Si la tabla tiene una clave principal, esta es la opción predeterminada (me parece la mejor opción), pero en ausencia de una clave principal, hay otras opciones de configuración disponibles. La fila completa podría usarse si no existe otra clave candidata (denominada "completa"), aunque la documentación menciona que esta no suele ser una solución eficiente. (Consulte la sección IDENTIDAD DE LA RÉPLICA en los documentos para obtener una descripción de nivel inferior sobre cómo configurarla)
Restricciones
La documentación del apartado 31.4. Restricciones tiene algunos recordatorios clave sobre las restricciones que pasaré por alto. Asegúrese de revisar la página vinculada arriba para ver la verborrea exacta.
- El esquema de la base de datos y cualquier comando DDL no se admiten en la replicación. Se sugiere que tal vez pg_dump podría usarse inicialmente, pero aún así, usted mismo deberá actualizar cualquier cambio y avance en el esquema para todas las réplicas.
- Se replicarán los datos en las columnas de secuencia. Pero, la secuencia en sí solo reflejaría el valor inicial. Para lecturas, está bien. Pero si este es su destino para la conmutación por error, deberá ACTUALIZAR al valor actual usted mismo. Los documentos sugieren pg_dump aquí.
- Aún no se admite truncar.
- La replicación de objetos grandes no es compatible.
- Las vistas, las vistas materializadas, las tablas raíz de partición o las tablas externas no se admiten ni en el editor ni en el suscriptor.
Casos de uso común informados
- Solo le interesan ciertos datos y cambios en los datos que realmente replique en lugar de simplemente replicar toda la base de datos.
- Cuando necesite réplicas para operaciones de solo lectura, como un escenario de análisis.
- Permitir a los usuarios o diferentes subconjuntos de usuarios un acceso limitado o supervisado a los datos.
- Distribución de datos.
- Compatibilidad con otras versiones de PostgreSQL.
Replicación de transmisión
De la investigación, la lectura y el estudio de Streaming Replication, una cosa que deduje desde el principio es elegir configurar la replicación asíncrona (predeterminada) o síncrona.
Ah, más términos desconocidos, ¿eh?
Aquí está mi definición de "alto nivel" de ambos:
Con la replicación asíncrona, después de que se confirma una transacción en el principal, hay un ligero retraso cuando se confirma esa misma transacción y se escribe en la réplica. Existe la posibilidad de pérdida de datos con este tipo de configuración.
- Uno, supongamos que el maestro falla.
- Dos, la(s) réplica(s) está(n) tan atrasada(s) que la(s) maestra(s) ha descartado los datos e información necesarios para que la(s) réplica(s) esté(n) incluso 'actualizada(s)'.
Sin embargo, en la replicación síncrona, ninguna transacción se considera completa, hasta que sea confirmada por los servidores principal y de réplica. Lo cual habrá escrito un compromiso en el WAL de ambos servidores.
Según tengo entendido, esto significa que las escrituras en el maestro también se confirmaron y se escribieron en la réplica.
Aquí está la explicación oficial de la sección 26.2.8. Replicación síncrona en la documentación oficial:
“Al solicitar la replicación síncrona, cada compromiso de una transacción de escritura esperará hasta que se reciba la confirmación de que el compromiso se ha escrito en el registro de escritura anticipada en el disco del servidor principal y en espera. “
Otro pasaje de la documentación tiene un buen resumen de lo que tiene que ser (en mi opinión), un gran beneficio:"La única posibilidad de que se pierdan datos es si tanto el principal como el de reserva sufren fallas al mismo tiempo".
Si bien nada es imposible, sigue siendo una buena garantía de que no se quedará sin una copia de sus datos.
Bien, sabemos que tenemos que elegir una de estas configuraciones de configuración, pero ¿cuál es la esencia general?
En pocas palabras, Streaming Replication envía y aplica archivos WAL (Write Ahead Log) desde un servidor de base de datos (el maestro o principal) a una 'réplica' (base de datos receptora).
Pero hay una advertencia aquí a tener en cuenta. Potencialmente, los archivos WAL del maestro se pueden reciclar antes de que el standy los obtenga. Una forma de mitigar esto es aumentar la configuración de wal_keep_segments a un valor más alto.
Puntos en la replicación de transmisión
Recursos relacionados ClusterControl para PostgreSQL Replicación de transmisión de PostgreSQL:un análisis profundo Guía de expertos para la replicación de Slony para PostgreSQL- De forma predeterminada, la replicación de transmisión es asíncrona, lo que significa que hay un retraso (quizás pequeño) entre las transacciones confirmadas en el maestro y su visibilidad en la réplica.
- Las réplicas se conectan al maestro a través de una conexión de red.
- Tenga en cuenta la autenticación. Consulte aquí en la documentación:"Es muy importante que los privilegios de acceso para la replicación se configuren de modo que solo los usuarios de confianza puedan leer el flujo WAL porque es fácil extraer información privilegiada de él"
Cuándo usar la replicación de transmisión
- Un uso común (especialmente en análisis) proporciona una réplica de "solo lectura" para aliviar la carga del servidor principal.
- Necesita un entorno de alta disponibilidad.
- Configuración útil para la conmutación por error al servidor de espera en caliente en caso de que el principal se caiga.