Esta es la cuarta parte de una serie de cinco que profundiza en la forma en que comienzan a ejecutarse los planes paralelos en modo fila de SQL Server. La parte 1 inicializó el contexto de ejecución cero para la tarea principal y la parte 2 creó el árbol de exploración de consultas. La parte 3 inició el análisis de consultas, realizó algunas fases iniciales procesamiento e inició las primeras tareas paralelas adicionales en la rama C.
Detalles de ejecución de la rama C
Este es el segundo paso de la secuencia de ejecución:
- Rama A (tarea principal).
- Sucursal C (tareas paralelas adicionales).
- Sucursal D (tareas paralelas adicionales).
- Sucursal B (tareas paralelas adicionales).
Un recordatorio de las sucursales en nuestro plan paralelo (haga clic para ampliar)
Poco tiempo después de las nuevas tareas para la rama C están en cola, SQL Server adjunta un trabajador a cada tarea y coloca al trabajador en un programador listo para la ejecución. Cada nueva tarea se ejecuta dentro de un nuevo contexto de ejecución. En DOP 2, hay dos tareas nuevas, dos subprocesos de trabajo y dos contextos de ejecución para la rama C. Cada tarea ejecuta su propia copia de los iteradores en la rama C en su propio subproceso de trabajo:

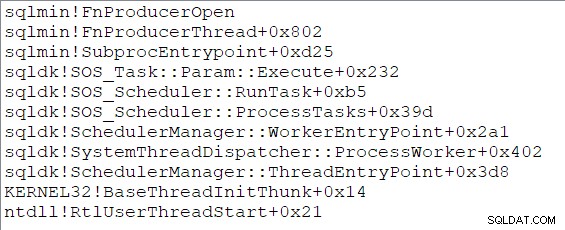
Las dos nuevas tareas paralelas comienzan a ejecutarse en un subprocedimiento punto de entrada, que inicialmente conduce a un Open llamada en el lado del productor del intercambio (CQScanXProducerNew::Open ). Ambas tareas tienen pilas de llamadas idénticas al comienzo de sus vidas:
Sincronización de Exchange
Mientras tanto, la tarea principal (ejecutándose en su propio subproceso de trabajo) registra los nuevos subprocesos con el administrador de subprocesos, luego espera en el lado del consumidor del intercambio de flujos de partición en el nodo 5. La tarea principal espera en CXPACKET * hasta todas de las tareas paralelas de la rama C completan su Open llamadas y volver al lado del productor del intercambio. Las tareas paralelas abrirán cada iterador en su subárbol (es decir, hasta la búsqueda de índice en el nodo 9 y viceversa) antes de volver al intercambio de flujos de partición en el nodo 5. La tarea principal esperará en CXPACKET mientras esto sucede. Recuerde que la tarea principal es ejecutar llamadas de fases tempranas.
Podemos ver esta espera en las tareas de espera DMV:

El contexto de ejecución cero (la tarea principal) está bloqueado por los dos nuevos contextos de ejecución. Estos contextos de ejecución son los primeros adicionales que se crean después del contexto cero, por lo que se les asignan los números uno y dos. Para enfatizar:ambos contextos de ejecución nuevos deben abrir sus subárboles y volver al intercambio para el CXPACKET de la tarea principal esperar a que termine.
Es posible que hayas esperado ver CXCONSUMER espera aquí, pero esa espera está reservada para esperar en datos de fila llegar. La espera actual no es para filas — corresponde al lado del productor abrir , por lo que obtenemos un CXPACKET genérico * espera.
* Azure SQL Database e Instancia administrada usan el nuevo CXSYNC_PORT esperar en lugar de CXPACKET aquí, pero esa mejora aún no ha llegado a SQL Server (a partir de 2019 CU9).
Inspección de las nuevas tareas paralelas
Podemos ver las nuevas tareas en los perfiles de consulta DMV. La información de perfiles para las nuevas tareas aparece en el DMV porque sus contextos de ejecución se derivaron (clonaron y luego actualizaron) del padre (contexto de ejecución cero):
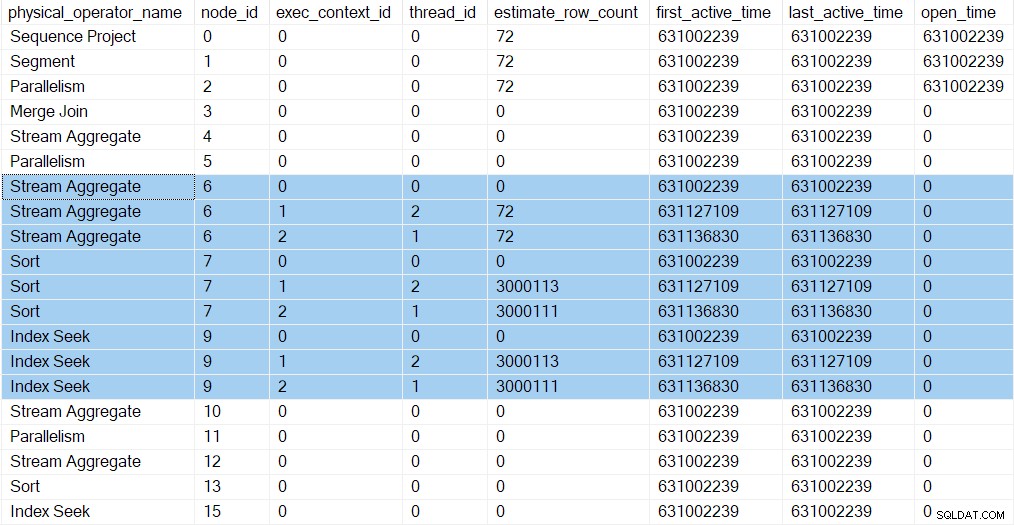
Ahora hay tres entradas para cada iterador en la Rama C (resaltado). Uno para la tarea principal (contexto de ejecución cero) y uno para cada nueva tarea paralela adicional (contextos 1 y 2). Observe que el recuento de filas estimado por subproceso (ver parte 1) han llegado ahora y se muestran solo para las tareas paralelas. Los primeros y últimos tiempos activos para las tareas paralelas representan el momento en que se crearon sus contextos de ejecución. Ninguna de las tareas nuevas se ha abierto cualquier iterador todavía.
Los flujos de reparto el intercambio en el nodo 5 aún tiene una sola entrada en la salida del DMV. Esto se debe a que el generador de perfiles invisible asociado supervisa al consumidor lado del intercambio. Las tareas paralelas adicionales están en el productor lado del intercambio. El lado del consumidor del nodo 5 eventualmente tenemos tareas paralelas, pero aún no hemos llegado a ese punto.
Punto de control
Este parece un buen punto para hacer una pausa y resumir dónde está todo en este momento. Habrá más de estos puntos de parada a medida que avancemos.
- La tarea principal está del lado del consumidor del intercambio de flujos de partición en el nodo 5 , esperando en
CXPACKET. Está en medio de la ejecución de llamadas de fases tempranas. Hizo una pausa para iniciar la rama C porque esa rama contiene una ordenación de bloqueo. La espera de la tarea principal continuará hasta que ambas tareas paralelas completen la apertura de sus subárboles. - Dos nuevas tareas paralelas en el lado del productor del intercambio del nodo 5 están listos para abrir los iteradores en la Rama C.
Nada fuera de la rama C de este plan de ejecución paralelo puede avanzar hasta que la tarea principal se libere de su CXPACKET Espere. Recuerde que hasta ahora solo hemos creado un conjunto de trabajadores paralelos adicionales para la Rama C. El único otro subproceso es la tarea principal y está bloqueada.
Ejecución paralela de rama C
Las dos tareas paralelas comienzan en el lado del productor del intercambio de flujos de partición en el nodo 5. Cada uno tiene un plan (en serie) separado con su propio agregado de flujo, ordenación y búsqueda de índice. El escalar de cómputo no aparece en el plan de tiempo de ejecución porque sus cálculos se difieren a la ordenación.
Cada instancia de la búsqueda de índice es parallel-aware y opera en conjuntos disjuntos de filas. Estos conjuntos se generan bajo demanda a partir del conjunto de filas principal creado anteriormente por la tarea principal (cubierto en la parte 1). Cuando cualquiera de las instancias de la búsqueda necesita un nuevo subrango de filas, se sincroniza con los otros subprocesos de trabajo, de modo que solo uno asigna un nuevo subrango al mismo tiempo. El objeto de sincronización utilizado también fue creado anteriormente por la tarea principal. Cuando una tarea espera acceso exclusivo al conjunto de filas principal para adquirir un nuevo subrango, espera en CXROWSET_SYNC .
Tareas de rama C abiertas
La secuencia de Open llamadas para cada tarea en la Rama C es:
CQScanXProducerNew::Open. Tenga en cuenta que no hay un perfilador anterior en el lado del productor de un intercambio. Esto es desafortunado para los sintonizadores de consultas.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. El generador de perfiles sobre el nodo 6.CQScanStreamAggregateNew::Open(nodo 6)CQScanProfileNew::Open. El generador de perfiles sobre el nodo 7.CQScanSortNew::Open(nodo 7)
La ordenación es un operador de bloqueo completo. . Consume toda su entrada durante su Open llamar. Hay una gran cantidad de detalles internos interesantes para explorar aquí, pero el espacio es corto, por lo que solo cubriré los aspectos más destacados:
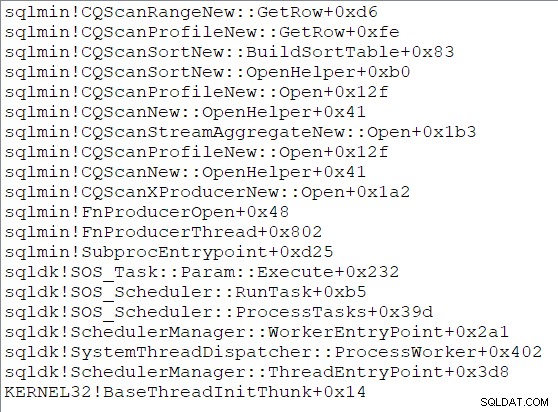
El ordenar construye su tabla de clasificación abriendo su subárbol y consumiendo todas las filas que sus hijos pueden proporcionar. Una vez que se completa la clasificación, la clasificación está lista para la transición al modo de salida y devuelve el control a su padre. La ordenación responderá más tarde a GetRow() llamadas, devolviendo la siguiente fila ordenada cada vez. Una pila de llamadas ilustrativa durante la ordenación de entrada es:
La ejecución continúa hasta que cada clasificación haya consumido todas las filas (intervalos separados de) disponibles de su búsqueda de índice secundaria. . Las clasificaciones luego llaman a Close en las búsquedas de índice y devolver el control a su agregado de flujo principal . Los agregados de flujo inicializan sus contadores y devuelven el control al productor lado del intercambio de partición en el nodo 5. La secuencia de Open ahora se completaron las llamadas en esta rama.
El DMV de perfiles en este punto muestra números de tiempo actualizados y tiempos de cierre para el índice paralelo busca:
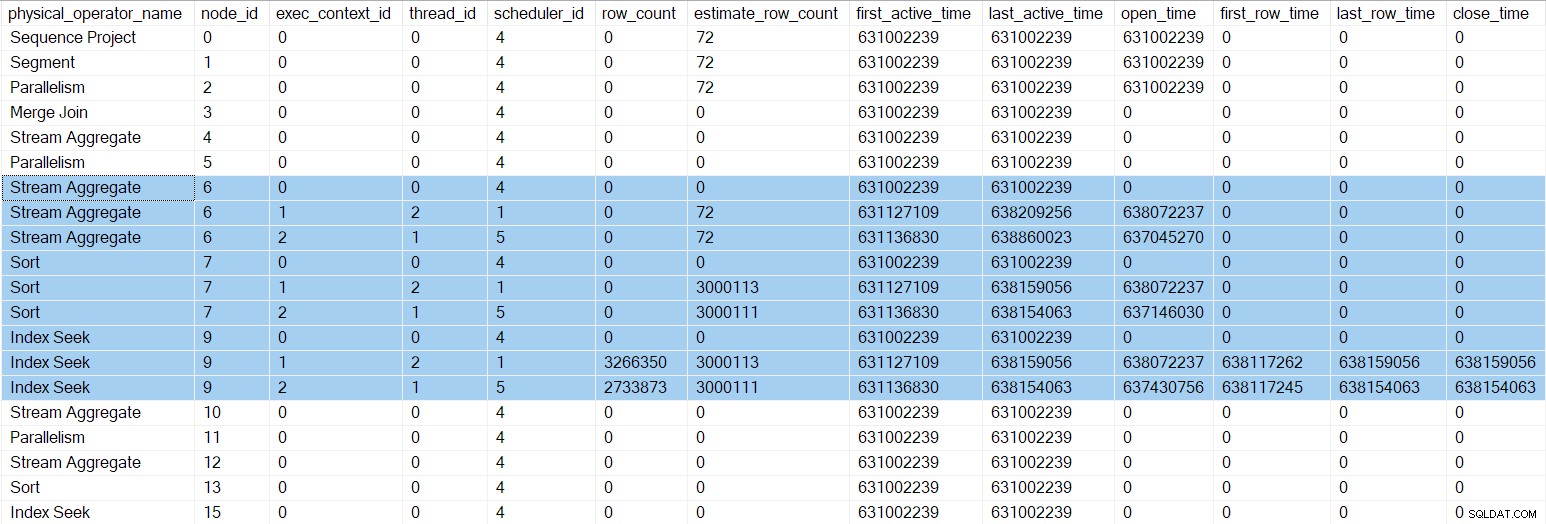
Más sincronización de intercambio
Recuerde que la tarea principal está esperando al consumidor lado del nodo 5 para que todos los productores lo abran. Ahora ocurre un proceso de sincronización similar entre las tareas paralelas en el productor lado del mismo intercambio:
Cada tarea de productor se sincroniza con las demás a través de CXTransLocal::Synchronize . Los productores llaman a CXPort::Open , luego espere en CXPACKET para todos los del lado del consumidor tareas paralelas para abrir. Cuando la primera tarea paralela de la rama C regresa al lado del productor del intercambio y espera, las tareas en espera del DMV se ven así:

Todavía tenemos las esperas del lado del consumidor de la tarea principal. El nuevo CXPACKET destacada es nuestra primera tarea paralela del lado del productor en espera de todas las tareas paralelas del lado del consumidor para abrir el puerto de intercambio.
Las tareas paralelas del lado del consumidor (en la Rama B) ni siquiera existen todavía, por lo que la tarea del productor muestra NULL para el contexto de ejecución por el que está bloqueada. La tarea que actualmente espera en el lado del consumidor del intercambio de flujos de partición es la tarea principal (¡no una tarea paralela!) que ejecuta EarlyPhases código, por lo que no cuenta.
Termina la espera de la tarea principal CXPACKET
Cuando el segundo la tarea paralela en la Rama C regresa al lado del productor del intercambio desde su Open llamadas, todos los productores han abierto el puerto de intercambio, por lo que la tarea principal en el lado del consumidor del intercambio es liberado de su CXPACKET espera.
Los trabajadores del lado del productor continúan esperando que se creen las tareas paralelas del lado del consumidor y abran el puerto de intercambio:

Punto de control
En este momento:
- Hay un total de tres tareas:dos en la rama C, más la tarea principal.
- Ambos productores en el intercambio del nodo 5 se han abierto y están esperando en
CXPACKETpara que se abran las tareas paralelas del lado del consumidor. Gran parte de la maquinaria de intercambio (incluidos los amortiguadores de filas) es creada por el lado del consumidor, por lo que los productores aún no tienen dónde colocar filas. - Los tipos en la sucursal C han consumido todas sus entradas y están listas para proporcionar una salida ordenada.
- El índice busca en la sucursal C han completado su trabajo y cerrado.
- La tarea principal acaba de salir de la espera en
CXPACKETen el lado del consumidor del intercambio de flujos de partición del nodo 5. Es todavía ejecutandoEarlyPhasesanidadas llamadas.
Inicio de tareas paralelas de la rama D
Este es el tercer paso en la secuencia de ejecución:
- Rama A (tarea principal).
- Sucursal C (tareas paralelas adicionales).
- Sucursal D (tareas paralelas adicionales).
- Sucursal B (tareas paralelas adicionales).
Liberado de su CXPACKET espere en el lado del consumidor del intercambio de flujos de partición en el nodo 5, la tarea principal asciende el árbol de exploración de consultas de la rama B. Regresa de EarlyPhases anidadas llama a los diversos iteradores y generadores de perfiles en la entrada externa (superior) de la combinación de fusión.
Como se mencionó, ascendente el árbol actualiza los tiempos transcurridos y de CPU registrados por los iteradores de creación de perfiles invisibles. Estamos ejecutando código utilizando la tarea principal, por lo que esos números se registran en el contexto de ejecución cero. Esta es la fuente definitiva de los números de tiempo del "subproceso 0" a los que se hace referencia en mi artículo anterior, Comprensión de los tiempos del operador del plan de ejecución.
Una vez de vuelta en la unión de fusión, la tarea principal llama a EarlyPhases para los iteradores y generadores de perfiles en la entrada interna (inferior) a la unión de fusión. Estos son nodos 10 a 15 (excluyendo 14, que es diferido):
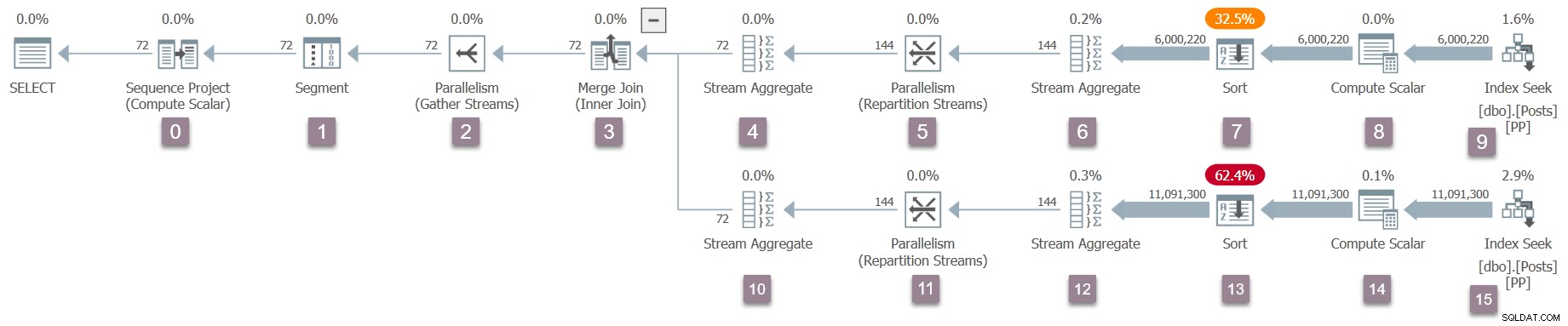
Una vez que las llamadas de las primeras fases de la tarea principal alcanzan la búsqueda de índice en el nodo 15, comienza a ascender en el árbol nuevamente (estableciendo tiempos de creación de perfiles) hasta que alcanza el intercambio de flujos de partición en el nodo 11.
Luego, tal como lo hizo en la entrada externa (superior) de la combinación de combinación, inicia el lado del productor del intercambio en nodo 11 , creando dos nuevas tareas paralelas .
Esto pone en marcha la Rama D (como se muestra a continuación). La rama D se ejecuta exactamente como ya se describió en detalle para la rama C.
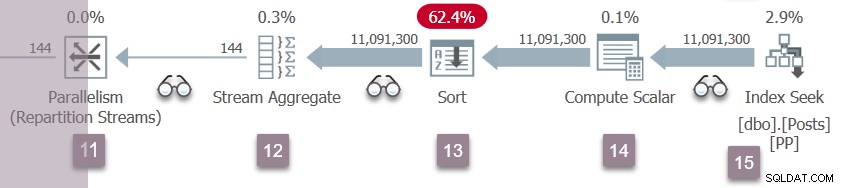
Inmediatamente después de iniciar las tareas para la sucursal D, la tarea principal espera en CXPACKET en el nodo 11 para que los nuevos productores abran el puerto de intercambio:

El nuevo CXPACKET las esperas están resaltadas. Tenga en cuenta que la identificación del nodo informado puede ser un poco engañosa. La tarea principal realmente está esperando en el lado del consumidor del nodo 11 (flujos de partición), no en el nodo 2 (flujos de recopilación). Esta es una peculiaridad del procesamiento de fase temprana.
Mientras tanto, los subprocesos del productor en la Rama C continúan esperando en CXPACKET para que se abra el lado del consumidor del intercambio de flujos de partición del nodo 5.
Apertura sucursal D
Justo después de que la tarea principal inicie los productores de la rama D, el perfil de consulta DMV muestra los nuevos contextos de ejecución (3 y 4):
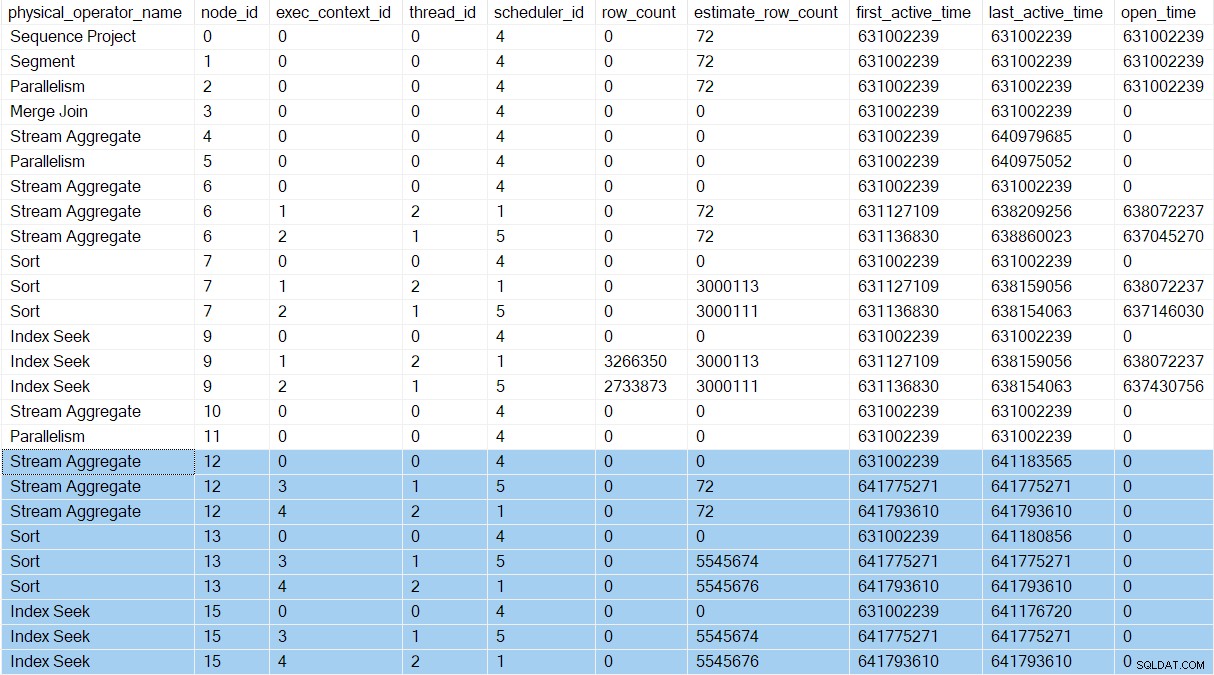
Las dos nuevas tareas paralelas en la Rama D proceda exactamente como lo hicieron los de la Rama C. Las clasificaciones consumen todos sus insumos y las tareas de la Sucursal D regresan al intercambio. Esto libera la tarea principal de su CXPACKET Espere. Los trabajadores de la sucursal D luego esperan en CXPACKET en el lado del productor del nodo 11 para que se abran las tareas paralelas del lado del consumidor. Esos trabajadores paralelos (en la Rama B) aún no existen.
Punto de control
Las tareas de espera en este punto se muestran a continuación:

Ambos conjuntos de tareas paralelas en las Ramas C y D están esperando en CXPACKET para que se abran sus consumidores de tareas paralelas, en los nodos de intercambio de flujos de partición 5 y 11 respectivamente. La única tarea ejecutable en toda la consulta en este momento está la tarea principal .
El generador de perfiles de consultas del DMV en este punto se muestra a continuación, con los operadores en las Sucursales C y D resaltados:
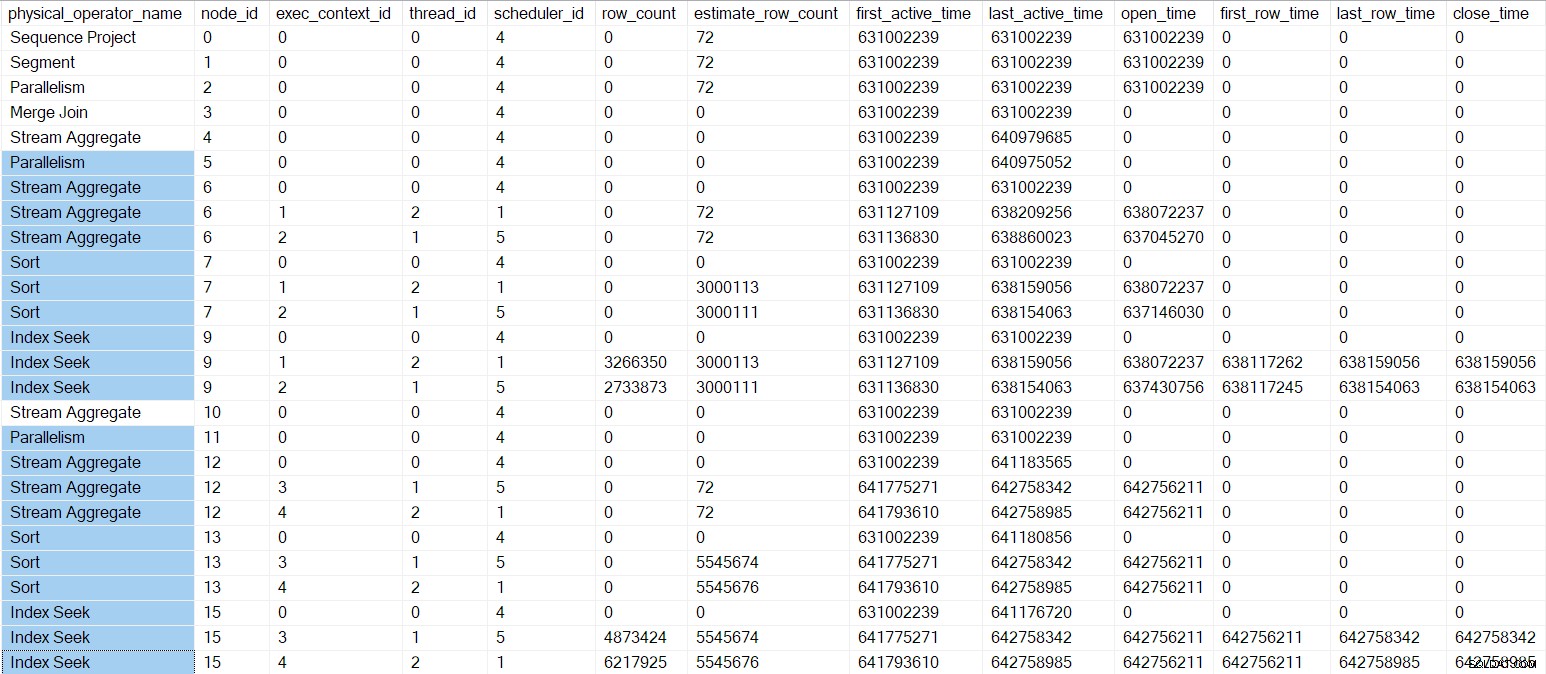
Las únicas tareas paralelas que aún no hemos comenzado están en la Sucursal B. Todo el trabajo en la Sucursal B hasta ahora ha sido fases iniciales. llamadas realizadas por la tarea principal .
Fin de la Parte 4
En la parte final de esta serie, describiré cómo se inicia el resto de este plan de ejecución paralelo en particular y cubriré brevemente cómo el plan arroja resultados. Concluiré con una descripción más general que se aplica a planes paralelos de complejidad arbitraria.



