No importa en qué lado de la ecuación se encuentre, a veces es difícil encontrar una persona calificada para un trabajo específico. En esta publicación, observamos un modelo de datos para ayudar a los departamentos de recursos humanos y reclutadores a mantenerse organizados durante el proceso de contratación.
La mayoría de nosotros hemos estado involucrados en el proceso de contratación, la mayoría de las veces como solicitantes de empleo. Sin embargo, también podemos encontrarnos involucrados en el lado de la contratación, tal vez probando los conocimientos técnicos del solicitante. El proceso de selección lleva una cierta cantidad de tiempo y el grupo de solicitantes se hace cada vez más pequeño a medida que nos acercamos a la decisión final. El resultado debe ser la selección de la mejor persona para el trabajo.
El reclutamiento en sí mismo es bastante complicado, por lo que discutiremos un modelo de datos bastante completo para cubrir todos los aspectos del proceso. ¡Siéntate en tu silla y disfruta del artículo de hoy!
Cómo funciona el proceso de contratación
La mayoría de las partes del proceso de contratación son de conocimiento común, pero discutiremos exactamente cómo funciona antes de pasar al modelo de datos.
-
Detectar una necesidad
Esta es una necesidad absoluta en el proceso de contratación; no habrá proceso si la gerencia no es consciente de la necesidad de contratar a un nuevo empleado. Esa necesidad podría ser el resultado de iniciar una nueva empresa, el crecimiento de una empresa existente o la partida de un empleado actual.
A menos que una empresa tenga puestos estrictamente definidos (por ejemplo, bancos), no siempre es fácil determinar cuándo contratar a un nuevo empleado. Hablar con los empleados y ver muchas horas extras puede estimular una nueva contratación. Las regulaciones internas o externas también pueden exigir que ciertos puestos solo se otorguen a personas con un conjunto de habilidades específico y experiencia laboral relevante (por ejemplo, revisor interno).
-
Resumir el puesto y las habilidades requeridas
Para tener una idea de este paso, piense en una descripción de trabajo muy bien escrita. Contiene:
- Una lista de todas las tareas relacionadas con el trabajo
- Cualificaciones mínimas de educación y experiencia laboral
- Habilidades específicas esenciales para las funciones laborales
- Habilidades adicionales o preferidas
- Un resumen de lo que el empleador espera del solicitante y lo que el solicitante puede esperar de este trabajo
- Un rango de salario y tal vez un paquete de beneficios
Esta información es importante tanto para los reclutadores como para los solicitantes. No tiene sentido invitar a diez candidatos al proceso de selección si ninguno de ellos está satisfecho con la oferta económica. Y cuanto más detallada sea la descripción del trabajo, más fácil será atraer a candidatos calificados.
-
Definir quién gestionará el proceso y cuándo debe realizarse cada tarea
El siguiente paso es definir fechas específicas en las que ocurrirá cada parte del proceso. Además, las empresas pueden asignar empleados a cada paso. Si la empresa tiene un departamento de Recursos Humanos, probablemente gestione cada parte del proceso de selección, aunque otros empleados pueden aportar sus conocimientos específicos cuando sea necesario (por ejemplo, si estamos contratando a un especialista en TI, el gerente del departamento de TI debe evaluar a los candidatos ' habilidades técnicas).
Si no hay un departamento de recursos humanos, podemos esperar que el personal de gestión esté a cargo del proceso. En las pequeñas y medianas empresas, esto no solo se necesita, sino que se desea.
-
Publicar el trabajo
Ahora estamos listos para publicar una descripción del trabajo en nuestro sitio, en bolsas de trabajo o agregadores, o en un periódico. El puesto de trabajo debe contener las viñetas enumeradas en el Paso 2. Esto ayudará a los candidatos potenciales a decidir si desean postularse para el puesto. Es esencial que la descripción del trabajo sea precisa; todos hemos perdido el tiempo en entrevistas para un trabajo que no coincidía con su descripción o nuestras expectativas.
-
Selección, prueba y entrevista de candidatos
Una vez que finaliza el período de solicitud, los solicitantes con el conjunto de habilidades y la experiencia más relevantes serán invitados a una fase de evaluación inicial (generalmente una entrevista o prueba). A los demás postulantes se les informará que no han sido seleccionados para el puesto. Una gran empresa debe invitar a un número mínimo predefinido de candidatos a la evaluación inicial. Esto ahorra tiempo tanto para los solicitantes como para la empresa.
Las pequeñas y medianas empresas podrían decidir continuar con el proceso hasta encontrar la mejor opción. En tales casos, el período de solicitud permanecerá abierto hasta que se encuentre el candidato adecuado y todas las demás fechas se definirán en el camino.
El proceso de entrevista y prueba variará según el tamaño y la organización de la empresa. En las grandes empresas con departamentos de recursos humanos, es probable que haya una serie de pruebas para verificar las habilidades laborales de los solicitantes. Otras pruebas pueden medir los rasgos psicológicos y de personalidad para determinar la coincidencia entre el solicitante y el trabajo, la coincidencia entre el solicitante y la empresa o incluso la cordura del solicitante. ☺
Estas pruebas generalmente se dividirán en varios pasos, y cada paso reducirá el número de solicitantes.
-
La entrevista final
Este paso probablemente será una entrevista de los mejores candidatos. Es el paso más importante del proceso porque los candidatos pueden hablar por sí mismos, demostrar su competencia y personalidad, y determinar si la empresa y el puesto serán adecuados para ellos. Después de este paso, el mejor solicitante recibirá una oferta. Si aceptan, el proceso de reclutamiento para ese puesto ha terminado. Si el solicitante rechaza la oferta de trabajo, la empresa hará una oferta a su próxima elección.
-
¿Existen diferencias en el proceso de contratación para pequeñas, medianas y grandes empresas? ¿Cómo los resolveremos en nuestro modelo?
Habrá ciertas diferencias en los procesos de selección de pequeñas, medianas y grandes empresas. Además, el proceso variará según los puestos que se contraten. Piense cuán diferentes son las habilidades y experiencias requeridas para un administrador de contenido, un ornitólogo y un capitán de crucero. Algunos trabajos tendrán más pruebas y entrevistas, otros pueden tener solo unas pocas. Pero al final, todo se reduce a obtener las respuestas correctas y clasificar a los solicitantes.
En este modelo, trataré todas las pruebas y entrevistas de la misma manera. Almacenaremos las respuestas de cada solicitante, las relacionaremos con la pregunta relevante y almacenaremos la puntuación del solicitante para cada paso del proceso.
-
¿Quién puede usar este modelo de datos?
Este modelo es muy específico y solo debe usarse para el proceso de reclutamiento. Pero no se limita a los departamentos de recursos humanos; también podría utilizar este modelo para ejecutar un servicio de contratación profesional.
-
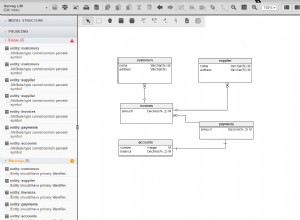
El modelo de datos
El modelo de datos consta de cinco áreas temáticas principales:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Describiré cada área temática por separado, en el mismo orden en que aparecen.
Sección 1:Trabajos
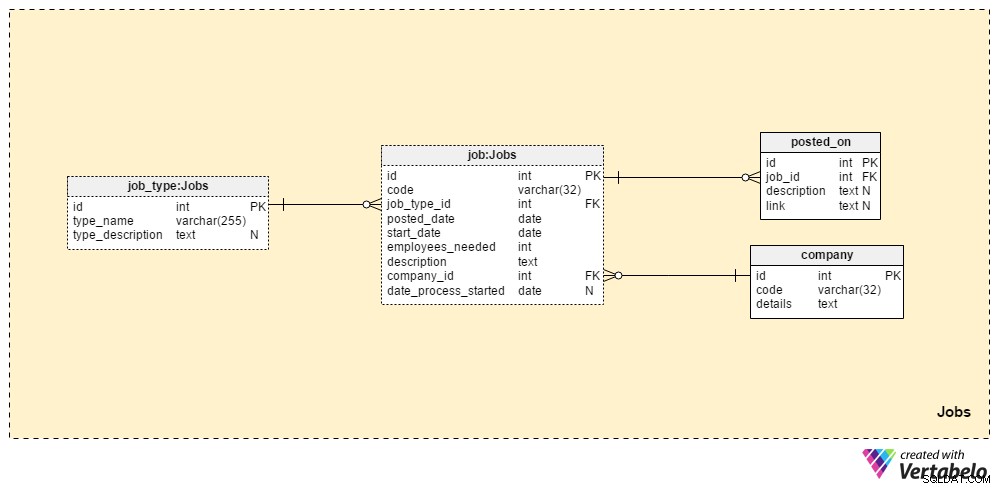
Los Jobs La sección almacenará todos los detalles de todas las posiciones que hemos publicado. Las dos tablas de diccionario, la company tabla y el job_type mesa, son parte de la configuración inicial. Las dos tablas restantes, job y posted_on , contienen datos “reales” relacionados con ofertas de trabajo.
El job_type El diccionario contiene una lista de tipos de trabajo diferentes y ÚNICOS. Podemos esperar valores como “administrador principal de la base de datos” o “periodista de TI” para ser almacenado en el type_name atributo. El type_description El atributo puede almacenar una descripción más detallada del trabajo.
La company El diccionario contiene una lista de todas las empresas con las que trabajamos. Si contratamos empleados solo para nuestra empresa, este diccionario contendrá solo el nombre de nuestra empresa. Si somos una agencia de contratación, almacenará los nombres de todas las empresas que nos contrataron.
Una lista de cada puesto de trabajo que hemos publicado se almacena en la tabla de "trabajo". Los atributos de esta tabla son:
code– Nuestra ID ÚNICA interna utilizada para indicar un trabajo.job_type_id– Hace referencia al tipo de trabajo relacionado.posted_date– La fecha en que se publicó este puesto de trabajo.start_date– La fecha de inicio prevista (primer día hábil) para ese trabajo.employees_needed– El número de empleados que queremos contratar durante este proceso de selección. En su mayoría, esto tendrá un valor de "1", pero en algunos casos, p. al iniciar una nueva empresa o establecer un nuevo departamento, podemos esperar valores más grandes.description– Una descripción detallada de ese puesto. Este es el lugar donde enumeraremos todas las habilidades laborales requeridas, preferidas y deseadas.company_id– Hace referencia al DNI de la empresa que nos contrató. Si somos una agencia de contratación, esto se referirá a un nombre comercial almacenado en lacompanymesa. De lo contrario, será el ID de nuestra propia empresa.date_process_started– La fecha de inicio del proceso de contratación. Esto podría ser NULL si necesitamos definir pasos y acciones futuras con respecto a este trabajo.
La última tabla en esta área temática es la posted_on mesa. Para cada job_id , almacenaremos un link al puesto de trabajo y la description relacionada . Podríamos usar estos datos para saber dónde encuentran los candidatos nuestros puestos de trabajo.
Sección 2:Solicitantes, Reclutadores y Documentos
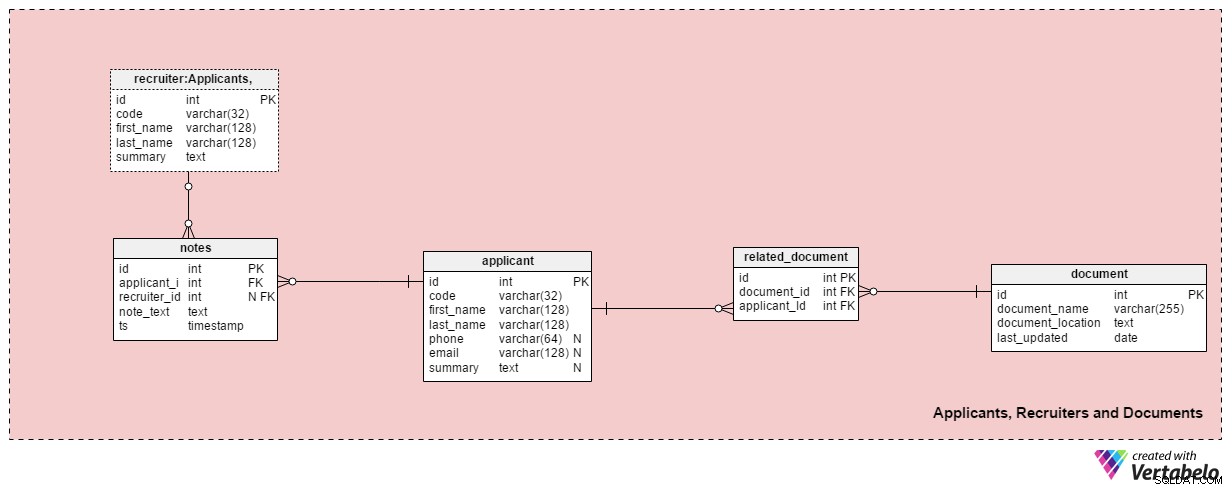
Esta área temática contiene todas las tablas necesarias para almacenar información sobre reclutadores, solicitantes y sus documentos relacionados.
El applicant tabla enumera todos los solicitantes con los que hemos tenido contacto. Cada solicitante se define ÚNICAMENTE en nuestro sistema con un "código". Además de eso, almacenaremos el nombre y apellido de cada solicitante, phone número, email dirección y su summary . Esta tabla se puede ajustar para necesidades específicas, p. agregar números de teléfono, correos electrónicos o direcciones físicas adicionales.
Relacionaremos a los solicitantes con los documentos disponibles. En el document mesa. Para cada documento, almacenaremos su nombre en el sistema, su ubicación y la hora de la actualización más reciente.
Relacionaremos a los solicitantes con los documentos usando el related_document mesa. Contiene solo dos claves foráneas, que forman el document_id – applicant_id Par ÚNICO.
El recruiter La tabla enumera los empleados que podrían asignarse a una solicitud de empleo o que ingresan notas relacionadas con un solicitante. Cada reclutador se define ÚNICAMENTE por su code . Solo almacenaremos detalles básicos como first_name , last_name y el summary del reclutador .
La última tabla en esta área temática son las notes mesa. Aquí es donde almacenaremos todas las notas relacionadas con un solicitante. Podríamos almacenar notas como “El solicitante no asistió a la reunión” o “Al solicitante le fue muy bien en la primera entrevista” . Para cada nota, almacenaremos la ID del reclutador que hizo esa nota, la ID del solicitante relacionado, el note_text y la marca de tiempo cuando se creó la nota.
Sección 3:Detalles de la prueba
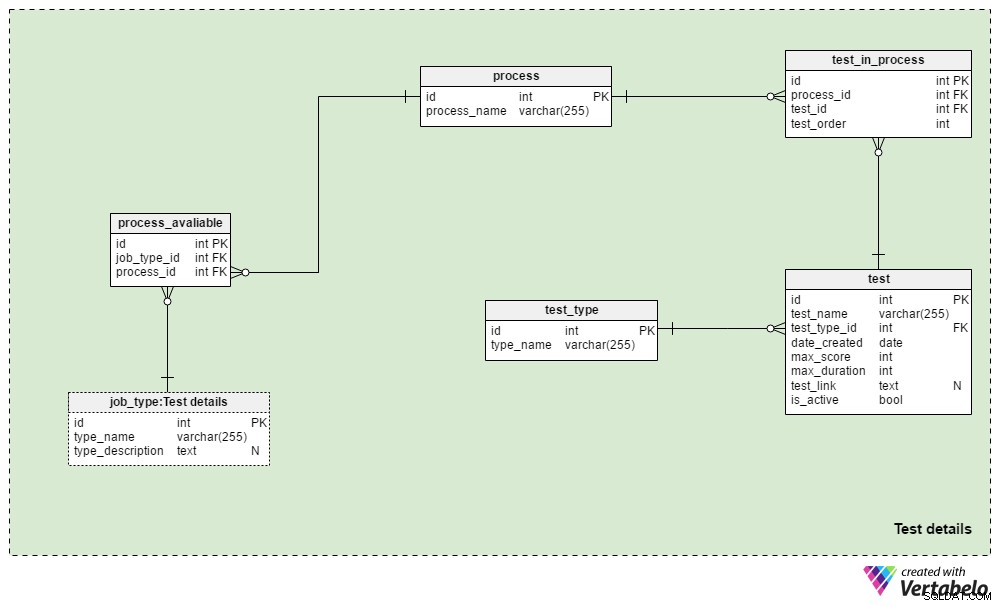
Los Test details El área temática contiene las tablas utilizadas para definir los procesos de contratación y las pruebas utilizadas durante estos procesos. Por lo general, siempre usaremos el mismo proceso de selección para el mismo tipo de trabajo:los cambios solo se realizan cuando lo requieren las circunstancias comerciales. Podríamos usar algunos procesos diferentes para cada tipo de trabajo y casi con seguridad usaremos el mismo proceso para diferentes tipos de trabajo.
El process table es un diccionario simple que contiene solo un process_name ÚNICO atributo. Enumera todos los procesos de reclutamiento que hemos usado y estamos usando actualmente.
Relacionaremos procesos con diferentes tipos de trabajo. Guardaremos estas relaciones en el process_available mesa. Sus únicos atributos son el par ÚNICO job_type_id – process_id . Cuando hay múltiples procesos disponibles para un tipo de trabajo, esto le permite al reclutador elegir uno.
El test_in_process La tabla se utiliza para definir el orden de las pruebas durante ese proceso. Los atributos de esta tabla son:
process_idytest_id– Hace referencia al proceso y la prueba relacionados.test_order– El número ordinal de esa prueba o paso en el proceso. Junto conprocess_id, esto forma la clave ÚNICA de la tabla. Solo podemos tener un paso a la vez durante el proceso.
La test La tabla enumera todas las pruebas utilizadas actualmente y anteriormente en el proceso de reclutamiento. También trataremos las revisiones de CV y las entrevistas como pruebas. Aunque no necesitan preguntas y respuestas definidas, son parte de una evaluación. Para cada prueba, almacenaremos:
test_name– Una designación ÚNICA para cada prueba.test_type_id– Hace referencia altest_typediccionario.date_created– La fecha en que creamos esta prueba en nuestro sistema.max_score– La puntuación máxima alcanzable para esta prueba. Este valor es la suma de todas las respuestas correctas en esta prueba o la calificación más alta que los reclutadores podrían dar a un CV o una entrevista.max_duration– Cuánto tiempo (en minutos) tiene el solicitante para completar la prueba.test_link– Contiene un enlace a la ubicación de la prueba. Este valor podría ser NULL cuando no usamos una prueba en el proceso.is_active– Indica si actualmente usamos esta prueba.
Ya hemos mencionado el test_type diccionario. Contiene todos los nombres de prueba ÚNICOS por formato, p. "Revisión de CV" , “prueba de habilidad en línea” , "prueba de habilidad en papel" y “entrevista” .
Este modelo no incluye la estructura necesaria para almacenar las preguntas y respuestas de las pruebas. Más bien, almacena un enlace a las ubicaciones que contienen esta información. El mismo diseño se utilizará en las Applications área temática.
Sección 4:Aplicaciones
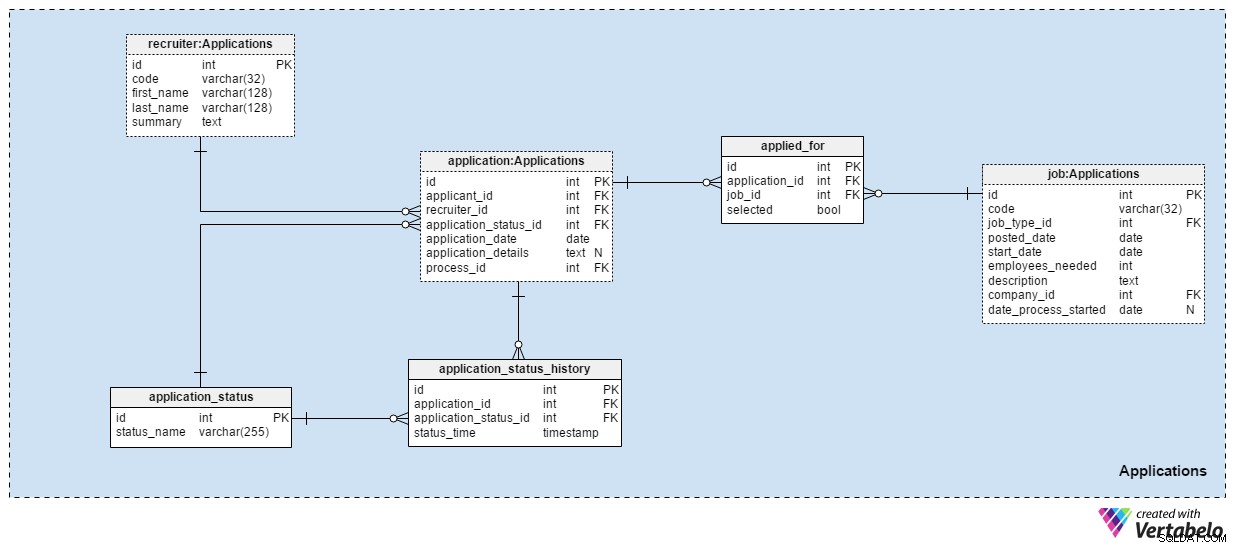
Las Applications El área temática es probablemente la más importante en este modelo de datos. Todas las demás áreas temáticas mencionadas hasta ahora describen aplicaciones. Este almacena las cosas reales.
Cada solicitud que hemos recibido se registra en la application mesa. Para cada solicitud, almacenaremos la identificación de los solicitantes relacionados, la identificación de los reclutadores y una referencia al estado actual de esa solicitud. Actualizaremos este estado al mismo tiempo que hacemos una nueva entrada en el application_status_history mesa. La application_date El atributo se utiliza para almacenar la fecha relevante, mientras que todos los detalles adicionales se almacenan en formato de texto. El process_id El atributo almacena una referencia al proceso seleccionado para esa aplicación.
Las aplicaciones cambiarán de estado con el tiempo. Una lista de todos los estados de la aplicación se almacena en application_status diccionario. El único atributo es status_name y solo puede contener valores ÚNICOS. Los valores esperados incluyen:"aplicado" , "CV revisado" , "elegido para la prueba" , "rechazado después de revisar el CV" , "pasó la prueba" , "invitado a una entrevista" y "terminado por el solicitante" .
Guardaremos todos los estados de las solicitudes en el application_status_history mesa. Esta tabla contiene referencias a la application tabla y el application_status diccionario. También almacenaremos el status_time exacto cuando se asignó este estado a la aplicación. El application_id – status_time par forma la clave ÚNICA de esta tabla.
En la mayoría de los casos, un solicitante solicitará solo un puesto con una solicitud. Es posible que un candidato postule para más de un puesto y elegiremos el rol más adecuado para él durante el proceso de selección. En el applied_for tabla, almacenaremos el par ÚNICO application_id – job_id . También registraremos si el solicitante relacionado con esa solicitud fue selected para ese puesto. Podemos esperar que todos los selected los valores se establecerán en “Falso” al comienzo del proceso de selección y que actualizaremos solo uno por cada puesto de trabajo a "Verdadero" .
Sección 5:Pruebas de aplicación
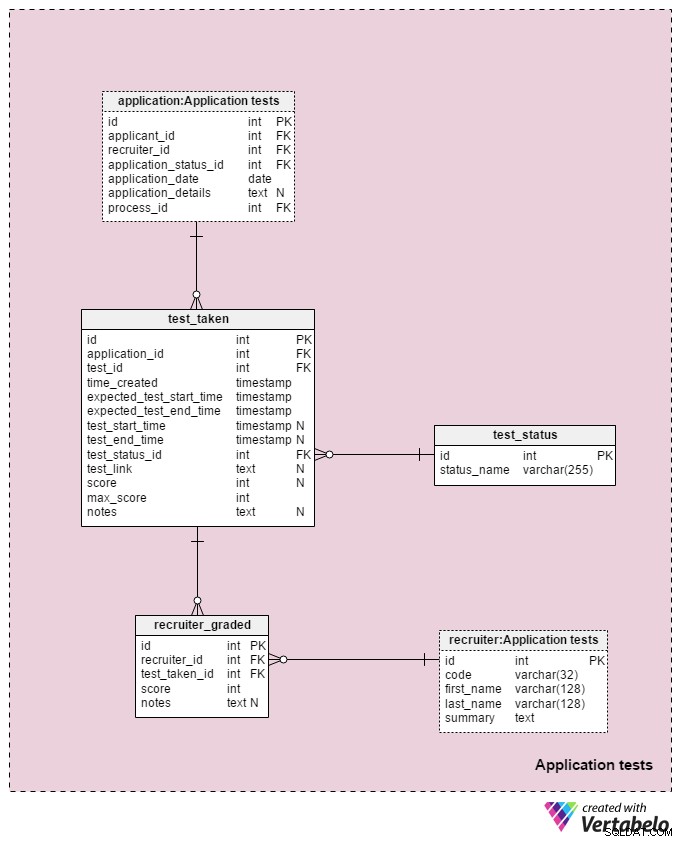
La última área temática de nuestro modelo se utilizará para almacenar los resultados de cada prueba realizada durante el proceso de selección. Dos tablas utilizadas en esta área temática son copias de otras áreas temáticas:application y recruiter . Se utilizan aquí para simplificar el modelo.
Todos los detalles relacionados con cada prueba se almacenan en el test_taken mesa. Esta tabla también contiene todos los demás pasos del proceso que podrían calificarse, como una revisión de CV. Los atributos de esta tabla son:
application_id– Hace referencia a laapplicationmesa. Esto relaciona una prueba con el solicitante que tomó esa prueba.test_id– Hace referencia a latestcatalogar. También podríamos hacer referencia altest_in_processtabla aquí, que nos proporcionaría más información sobre la prueba realizada. Decidí no hacerlo porque esta estructura nos da más flexibilidad. (Por ejemplo, si queremos permitir que los solicitantes realicen un examen dos veces o fuera del horario habitual).time_created– La hora real en la que insertamos esta prueba en nuestro sistema.expected_test_start_timeyexpected_test_end_time– Las horas de inicio y finalización, según lo discutido con el solicitante. Podríamos cambiar estos valores en caso de que el solicitante o el reclutador necesite posponer la prueba.test_start_timeytest_end_time–Las horas reales de inicio y finalización de la prueba. Estos contendrán valores NULL cuando se cree la prueba; los valores se actualizarán cuando el solicitante comience y finalice esta prueba.test_status_id– Hace referencia altest_statusdiccionario.test_link– Enlaces a la prueba con las respuestas del aspirante. Se actualizará cuando el solicitante envíe la prueba.score– La puntuación del solicitante en esa prueba. Esto lo determina manualmente un reclutador (por ejemplo, para una revisión de CV) o automáticamente (la suma de todos los puntajes de los elementos de la prueba). También podría contener un valor NULL para las pruebas que no se puntúan o califican en alguna escala predefinida. Además, una prueba que está programada pero aún no se ha completado puede tener un valor NULL.max_score– La puntuación máxima alcanzable de la prueba. Este es el mismo que el valor almacenado en eltest.”max_scoreatributo. Quiero mantener ese valor porque el reclutador podría modificar la prueba mientras se está dando y, por lo tanto, cambiar el puntaje máximo que se podría lograr.notes– Cualquier nota o comentario adicional ingresado por los reclutadores con respecto a esa prueba específica.
La combinación de test_id – application_id – expected_test_start_time atributos forma la clave ÚNICA de esta tabla. Antes de agregar una nueva sesión de prueba, aún debemos verificar los intervalos de prueba superpuestos para el solicitante relacionado y todos los reclutadores relacionados.
El test_status el diccionario contiene una lista de cada status_name ÚNICO que podría ser asignado a una prueba. Algunos valores esperados incluyen:"no iniciado" , "en curso" , "completado con éxito" , "completado sin éxito" , "pospuesto" , "cancelado" y "solicitante cancelado" .
La última tabla de nuestro modelo es la recruiter_graded tabla, que almacena todas las calificaciones que dieron los reclutadores al calificar cada prueba. Por lo tanto, almacenaremos referencias al recruiter y test_taken mesas. También almacenaremos la score logrado así como cualquier notes . Esta información es muy importante, especialmente cuando estamos calificando pruebas manualmente (es decir, para revisiones de CV y entrevistas).
Hoy hemos discutido un modelo de datos que puede cubrir casi cualquier situación en el proceso de selección y reclutamiento, incluidas excepciones poco comunes.
La mayoría de nosotros tenemos alguna experiencia con este tema. Comparta su experiencia mientras desempeñaba el papel de reclutador o del otro lado del escritorio. ¿Este modelo cubre las situaciones que enfrentaste? Si no, ¿qué cambios propondría?