El uso de la replicación para sus bases de datos PostgreSQL podría ser útil no solo para tener un entorno tolerante a fallas y de alta disponibilidad, sino también para mejorar el rendimiento de su sistema al equilibrar el tráfico entre los nodos en espera. En esta primera parte del blog de dos partes, vamos a ver algunos conceptos relacionados con la replicación de PostgreSQL.
Métodos de replicación en PostgreSQL
Existen diferentes métodos para replicar datos en PostgreSQL, pero aquí nos centraremos en los dos métodos principales:Streaming Replication y Logical Replication.
Replicación de transmisión
PostgreSQL Streaming Replication, la replicación de PostgreSQL más común, es una replicación física que replica los cambios a nivel de byte por byte, creando una copia idéntica de la base de datos en otro servidor. Se basa en el método de envío de registros. Los registros WAL se mueven directamente de un servidor de base de datos a otro para ser aplicados. Podemos decir que es una especie de PITR continuo.
Esta transferencia WAL se realiza de dos maneras diferentes, transfiriendo registros WAL de un archivo (segmento WAL) a la vez (trasvase de registros basado en archivos) y transfiriendo registros WAL (un archivo WAL se compone de registros WAL) sobre la marcha (envío de registros basado en registros), entre un servidor principal y uno o más servidores en espera, sin esperar a que se llene el archivo WAL.
En la práctica, un proceso denominado receptor WAL, que se ejecuta en el servidor de reserva, se conectará al servidor principal mediante una conexión TCP/IP. En el servidor primario existe otro proceso, llamado WAL sender, y se encarga de enviar los registros WAL al servidor standby a medida que ocurren.
Una replicación de transmisión básica se puede representar de la siguiente manera:
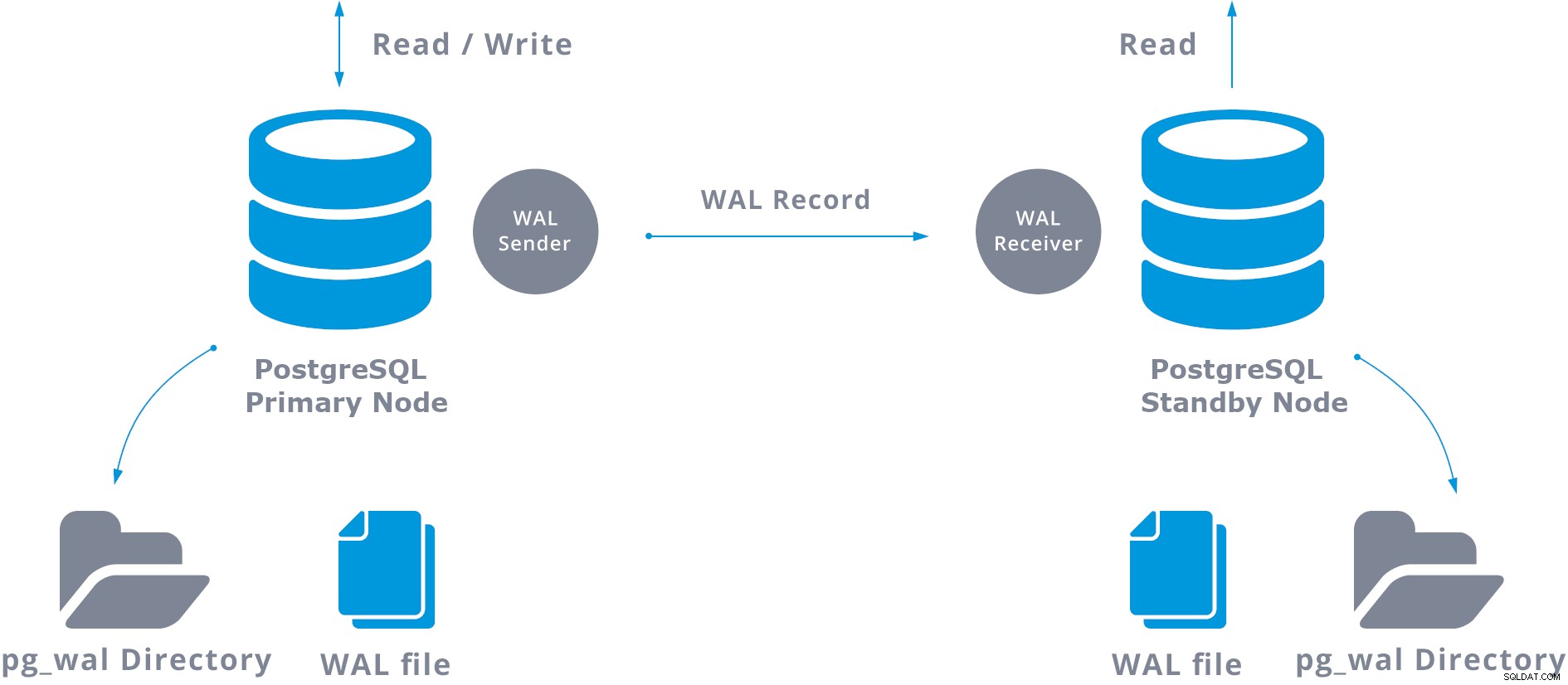
Al configurar la replicación de transmisión, tiene la opción de habilitar el archivo WAL. Esto no es obligatorio, pero es extremadamente importante para una configuración de replicación sólida, ya que es necesario evitar que el servidor principal recicle los archivos WAL antiguos que aún no se han aplicado al servidor en espera. Si esto ocurre, deberá volver a crear la réplica desde cero.
Replicación lógica
La replicación lógica de PostgreSQL es un método para replicar objetos de datos y sus cambios, en función de su identidad de replicación (generalmente una clave principal). Se basa en un modo de publicación y suscripción, donde uno o más suscriptores se suscriben a una o más publicaciones en un nodo de publicación.
Una publicación es un conjunto de cambios generados a partir de una tabla o un grupo de tablas. El nodo donde se define una publicación se denomina editor. Una suscripción es el lado descendente de la replicación lógica. El nodo donde se define una suscripción se denomina suscriptor y define la conexión a otra base de datos y conjunto de publicaciones (una o más) a las que desea suscribirse. Los suscriptores extraen datos de las publicaciones a las que se suscriben.
La replicación lógica se construye con una arquitectura similar a la replicación de transmisión física. Se implementa mediante los procesos "walsender" y "apply". El proceso de walsender inicia la decodificación lógica de WAL y carga el complemento de decodificación lógica estándar. El complemento transforma los cambios leídos de WAL al protocolo de replicación lógica y filtra los datos de acuerdo con la especificación de publicación. Luego, los datos se transfieren de forma continua utilizando el protocolo de replicación de transmisión al trabajador de aplicación, que asigna los datos a las tablas locales y aplica los cambios individuales a medida que se reciben, en un orden transaccional correcto.
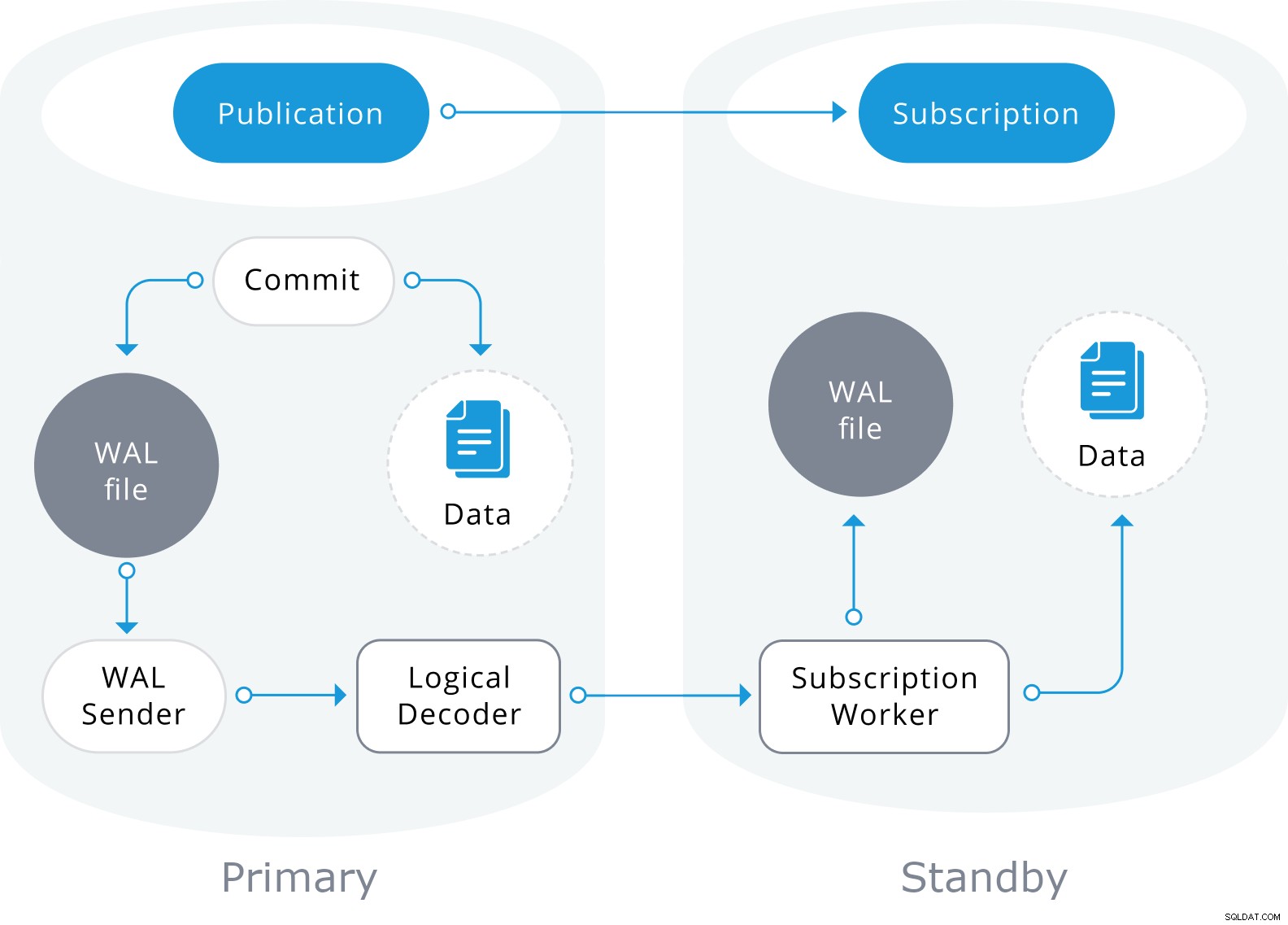
La replicación lógica comienza tomando una instantánea de los datos en la base de datos del editor y copiando eso al suscriptor. Los datos iniciales en las tablas suscritas existentes se capturan y se copian en una instancia paralela de un tipo especial de proceso de aplicación. Este proceso creará su propia ranura de replicación temporal y copiará los datos existentes. Una vez que se copian los datos existentes, el trabajador ingresa al modo de sincronización, lo que garantiza que la tabla se actualice a un estado sincronizado con el proceso de aplicación principal mediante la transmisión de cualquier cambio que haya ocurrido durante la copia de datos inicial mediante la replicación lógica estándar. Una vez que se realiza la sincronización, el control de la replicación de la tabla se devuelve al proceso de aplicación principal donde la replicación continúa con normalidad. Los cambios en el editor se envían al suscriptor a medida que ocurren en tiempo real.
Modos de replicación en PostgreSQL
La replicación en PostgreSQL puede ser síncrona o asíncrona.
Replicación asíncrona
Es el modo predeterminado. Aquí es posible que se confirmen algunas transacciones en el nodo principal que aún no se han replicado en el servidor de reserva. Esto significa que existe la posibilidad de alguna posible pérdida de datos. Se supone que este retraso en el proceso de confirmación es muy pequeño si el servidor en espera es lo suficientemente potente como para mantenerse al día con la carga. Si este pequeño riesgo de pérdida de datos no es aceptable en la empresa, puede utilizar la replicación síncrona en su lugar.
Replicación síncrona
Cada confirmación de una transacción de escritura esperará hasta la confirmación de que la confirmación se ha escrito en el registro de escritura anticipada en el disco del servidor primario y en espera. Este método minimiza la posibilidad de pérdida de datos. Para que se produzca la pérdida de datos, necesitaría que tanto el principal como el de reserva fallaran al mismo tiempo.
La desventaja de este método es la misma para todos los métodos síncronos, ya que con este método aumenta el tiempo de respuesta para cada transacción de escritura. Esto se debe a la necesidad de esperar hasta todas las confirmaciones de que se comprometió la transacción. Afortunadamente, las transacciones de solo lectura no se verán afectadas por esto, pero; solo las transacciones de escritura.
Alta disponibilidad para la replicación de PostgreSQL
La alta disponibilidad es un requisito para muchos sistemas, independientemente de la tecnología que utilicemos, y existen diferentes enfoques para lograrlo utilizando diferentes herramientas.
Equilibrio de carga
Los balanceadores de carga son herramientas que se pueden usar para administrar el tráfico de su aplicación para aprovechar al máximo la arquitectura de su base de datos. No solo es útil para equilibrar la carga de nuestras bases de datos, sino que también ayuda a que las aplicaciones se redirijan a los nodos disponibles/en buen estado e incluso a especificar puertos con diferentes funciones.
HAProxy es un balanceador de carga que distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para esta tarea. Si alguno de los destinos deja de responder, se marca como fuera de línea y el tráfico se envía al resto de destinos disponibles. Tener solo un nodo de Load Balancer generará un punto único de falla, por lo que para evitar esto, debe implementar al menos dos nodos HAProxy y configurar Keepalived entre ellos.
Keepalived es un servicio que nos permite configurar una IP virtual dentro de un grupo de servidores activo/pasivo. Esta IP virtual está asignada a un servidor activo. Si este servidor falla, la IP se migra automáticamente al servidor pasivo “Secundario”, lo que le permite seguir trabajando con la misma IP de forma transparente para los sistemas.
Mejora del rendimiento en la replicación de PostgreSQL
El rendimiento siempre es importante en cualquier sistema. Deberá hacer un buen uso de los recursos disponibles para garantizar el mejor tiempo de respuesta posible y hay diferentes maneras de hacerlo. Cada conexión a una base de datos consume recursos, por lo que una de las formas de mejorar el rendimiento de su base de datos PostgreSQL es tener un buen agrupador de conexiones entre su aplicación y los servidores de la base de datos.
Agrupadores de conexiones
Una agrupación de conexiones es un método para crear un grupo de conexiones y reutilizarlas, evitando abrir nuevas conexiones a la base de datos todo el tiempo, lo que aumentará considerablemente el rendimiento de sus aplicaciones. PgBouncer es un agrupador de conexiones popular diseñado para PostgreSQL.
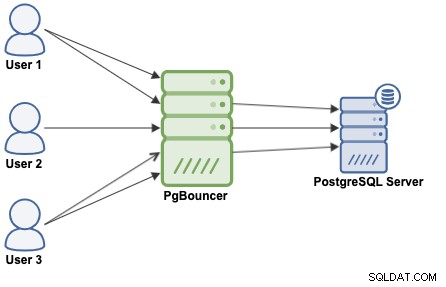
PgBouncer actúa como un servidor PostgreSQL, por lo que solo necesita acceder a su base de datos usando la información de PgBouncer (dirección IP/nombre de host y puerto), y PgBouncer creará una conexión con el servidor PostgreSQL, o reutilizará una si existe.
Cuando PgBouncer recibe una conexión, realiza la autenticación, que depende del método especificado en el archivo de configuración. PgBouncer admite todos los mecanismos de autenticación que admite el servidor PostgreSQL. Después de esto, PgBouncer busca una conexión en caché, con la misma combinación de nombre de usuario y base de datos. Si se encuentra una conexión en caché, devuelve la conexión al cliente, si no, crea una nueva conexión. Según la configuración de PgBouncer y la cantidad de conexiones activas, es posible que la nueva conexión se ponga en cola hasta que se pueda crear o incluso cancelar.
Con todos estos conceptos mencionados, en la segunda parte de este blog, veremos cómo puedes combinarlos para tener un buen entorno de replicación en PostgreSQL.