En la primera parte de este blog, mencionamos algunos conceptos importantes relacionados con un buen entorno de replicación de PostgreSQL. Ahora, veamos cómo combinar todas estas cosas de una manera fácil usando ClusterControl. Para esto, asumiremos que tiene instalado ClusterControl, pero si no, puede ir al sitio oficial o consultar la documentación oficial para instalarlo.
Implementación de la replicación de secuencias de PostgreSQL
Para realizar un deployment de un Cluster PostgreSQL desde ClusterControl, seleccione la opción Deploy y siga las instrucciones que aparecen.
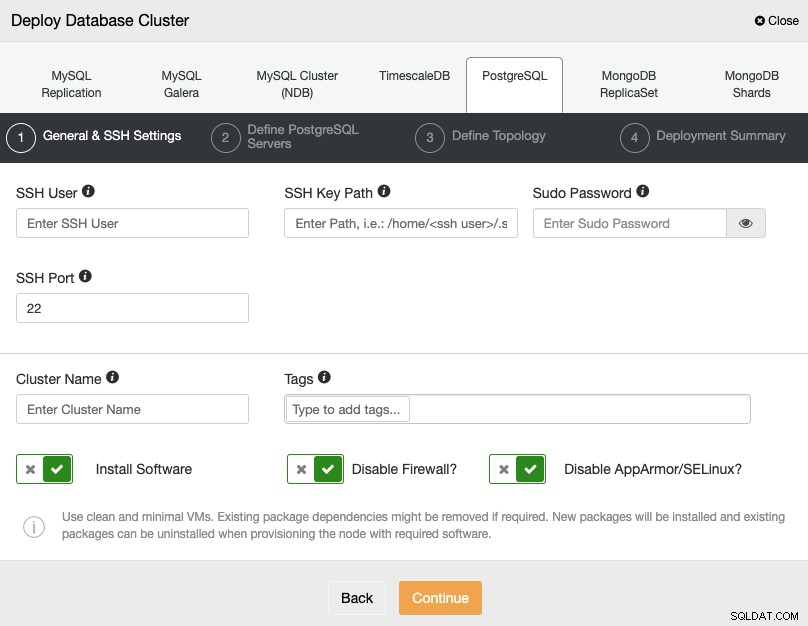
Al seleccionar PostgreSQL, debe especificar el Usuario, Clave o Contraseña, y Puerto para conectarse por SSH a sus servidores. También puede agregar un nombre para su nuevo clúster y especificar si desea que ClusterControl instale el software y las configuraciones correspondientes por usted.
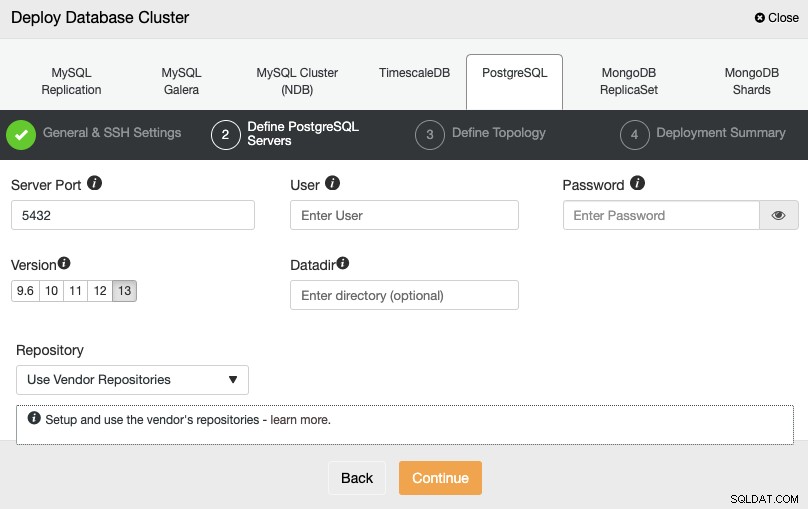
Después de configurar la información de acceso SSH, debe definir las credenciales de la base de datos , versión y datadir (opcional). También puede especificar qué repositorio usar.
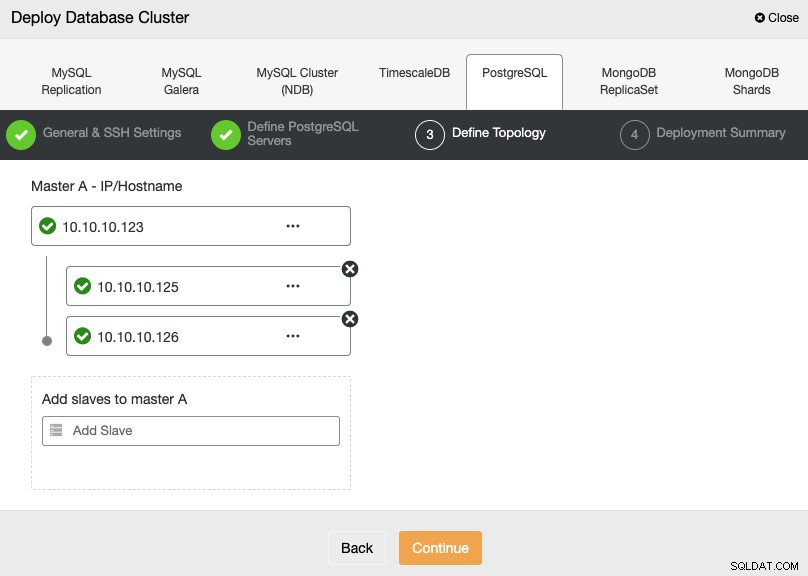
En el siguiente paso, debe agregar sus servidores al clúster que va a crear utilizando la dirección IP o el nombre de host.
En el último paso, puede elegir si su replicación será Síncrona o Asíncrono, y luego simplemente presione Implementar.
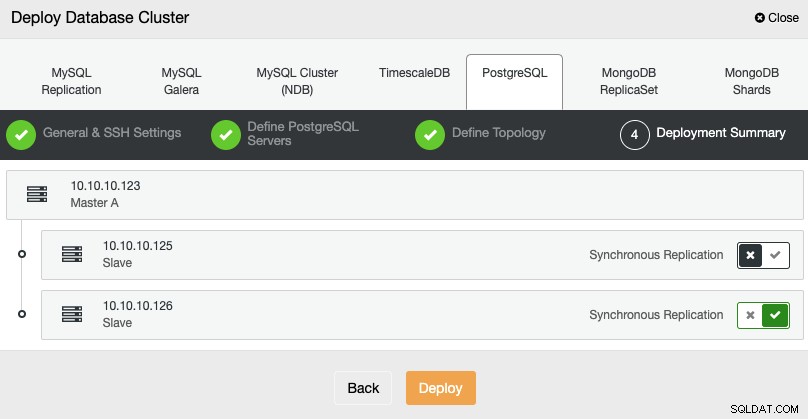
Una vez finalizada la tarea, puede ver su nuevo clúster de PostgreSQL en la pantalla principal de ClusterControl.

Ahora que ha creado su clúster, puede realizar varias tareas en él, como agregar un equilibrador de carga (HAProxy), un agrupador de conexiones (PgBouncer) o un nuevo esclavo de replicación síncrona o asíncrona.
Adición de esclavos de replicación sincrónicos y asincrónicos
Vaya a ClusterControl -> Acciones de clúster -> Agregar esclavo de replicación.
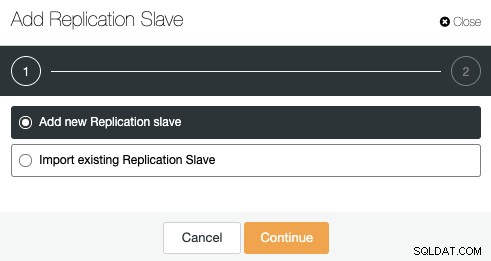
Puede agregar un nuevo esclavo de replicación o incluso importar uno existente. Elijamos la primera opción y continuemos.
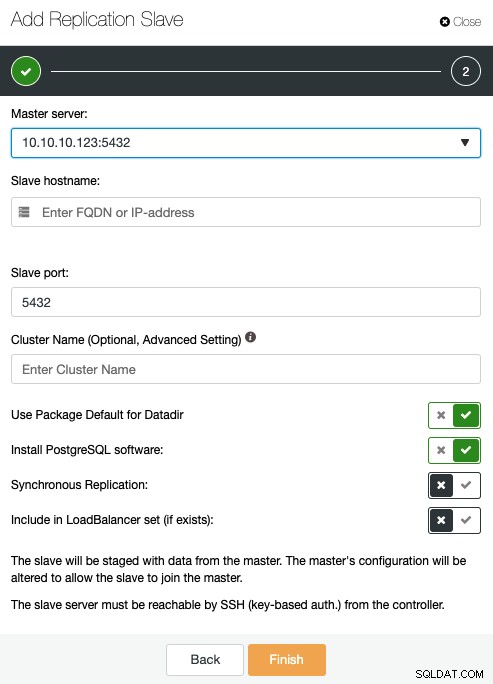
Aquí, debe especificar el servidor maestro, la dirección IP o el nombre de host de el nuevo esclavo de replicación, el puerto y, si desea que ClusterControl instale el software, o incluya este nodo en un balanceador de carga existente. También puede configurar la replicación para que sea síncrona o asíncrona.
Ahora que tiene su clúster de PostgreSQL en su lugar con las réplicas correspondientes, veamos cómo mejorar el rendimiento agregando un agrupador de conexiones.
Implementación de PgBouncer
Vaya a ClusterControl -> Seleccione Clúster de PostgreSQL -> Acciones de clúster -> Agregar equilibrador de carga -> PgBouncer. Aquí, puede implementar un nuevo nodo PgBouncer que se implementará en el nodo de base de datos seleccionado, o incluso importar un PgBouncer existente.
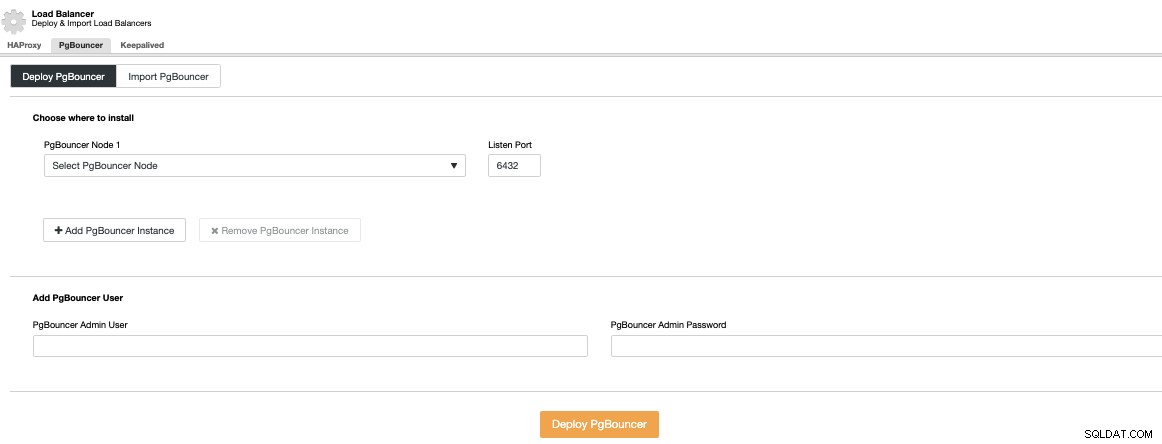
Deberá especificar una dirección IP o nombre de host, el puerto de escucha y Credenciales de PgBouncer. Cuando presiona Implementar PgBouncer, ClusterControl accederá al nodo, instalará y configurará todo sin ninguna intervención manual.
Puede monitorear el progreso en la Sección de Actividad de ClusterControl. Cuando termine, debe crear el nuevo grupo. Para ello, vaya a ClusterControl -> Seleccione el clúster de PostgreSQL -> Nodos -> nodo PgBouncer.
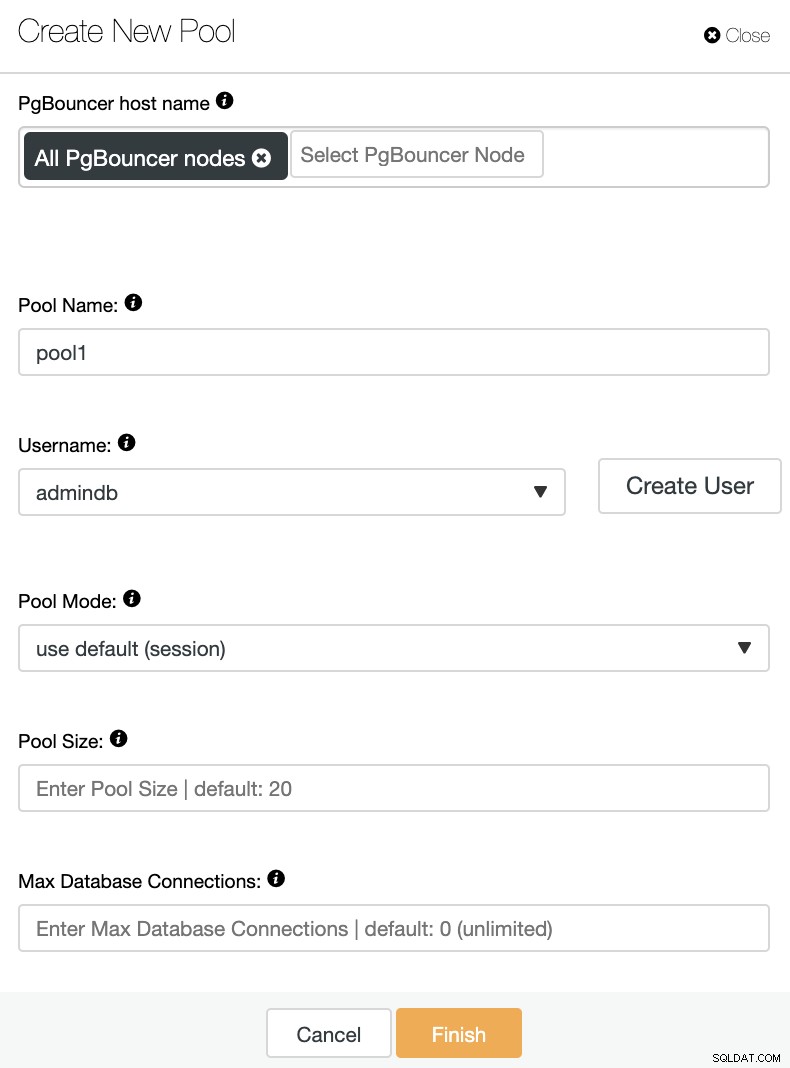
Deberá agregar la siguiente información:
-
Nombre de host de PgBouncer:seleccione los hosts del nodo para crear el grupo de conexiones.
-
Nombre del grupo:los nombres del grupo y de la base de datos deben ser iguales.
-
Nombre de usuario:seleccione un usuario del nodo principal de PostgreSQL o cree uno nuevo.
-
Modo de grupo:puede ser:sesión (predeterminado), transacción o agrupación de extractos.
-
Tamaño de la agrupación:tamaño máximo de las agrupaciones para esta base de datos. El valor predeterminado es 20.
-
Conexiones máximas de base de datos:configure un máximo para toda la base de datos. El valor predeterminado es 0, lo que significa ilimitado.
Ahora, debería poder ver el Grupo en la sección Nodo.
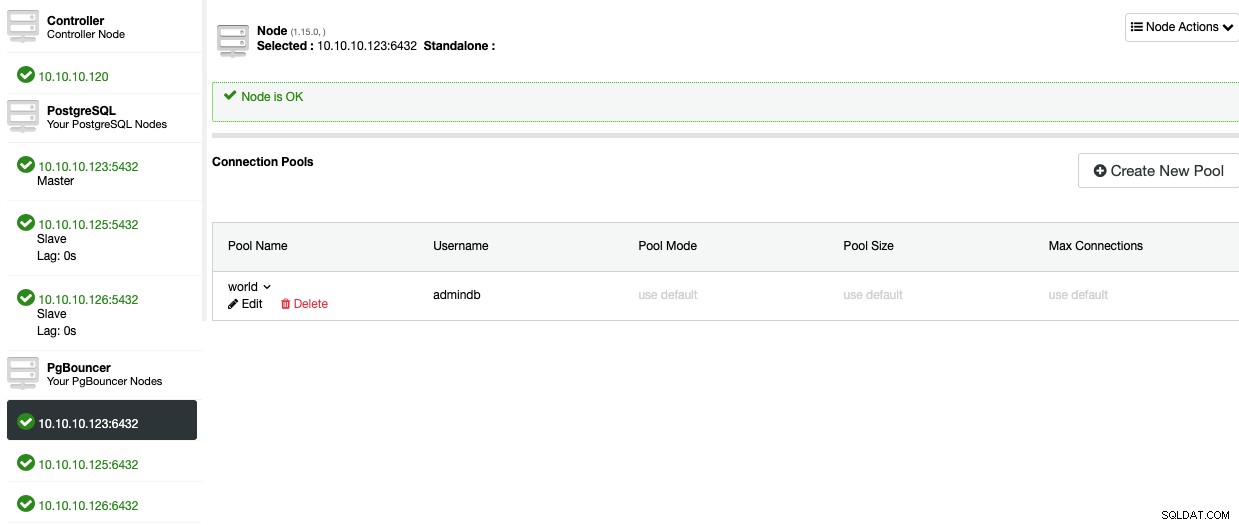
Para agregar alta disponibilidad a su base de datos PostgreSQL, veamos cómo implementar un equilibrador de carga.
Implementación del equilibrador de carga
Para realizar una implementación del balanceador de carga, seleccione la opción Agregar balanceador de carga en el menú Acciones del clúster y complete la información solicitada.
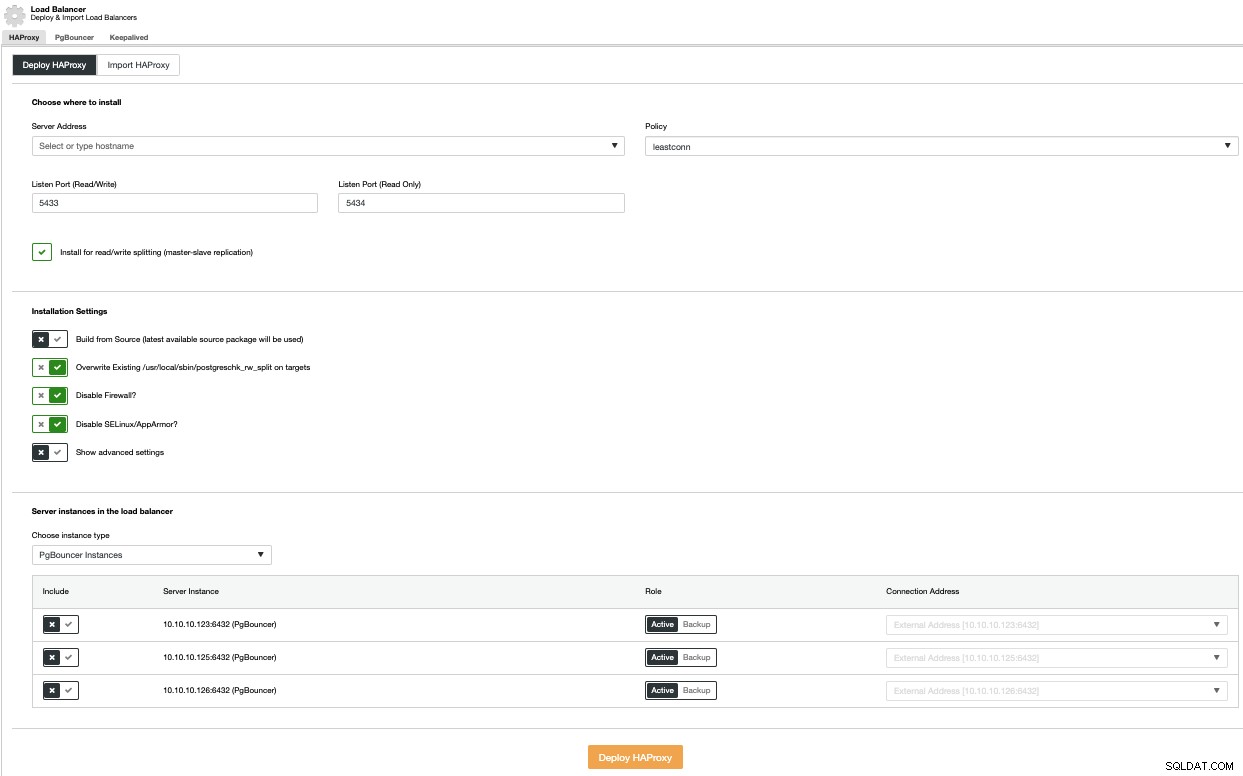
Debe agregar IP o nombre de host, puerto, política y los nodos vas a usar. Si está utilizando PgBouncer, puede elegirlo en el cuadro combinado de tipo de instancia.
Para evitar un único punto de falla, debe implementar al menos dos nodos HAProxy y usar Keepalived, que le permite usar una dirección IP virtual en su aplicación que está asignada al nodo HAProxy activo. Si este nodo falla, la dirección IP virtual se migrará al balanceador de carga secundario, por lo que su aplicación podrá seguir funcionando como de costumbre.
Implementación mantenida
Para realizar una implementación de Keepalived, seleccione la opción Add Load Balancer en el menú Acciones del clúster y luego vaya a la pestaña Keepalived.
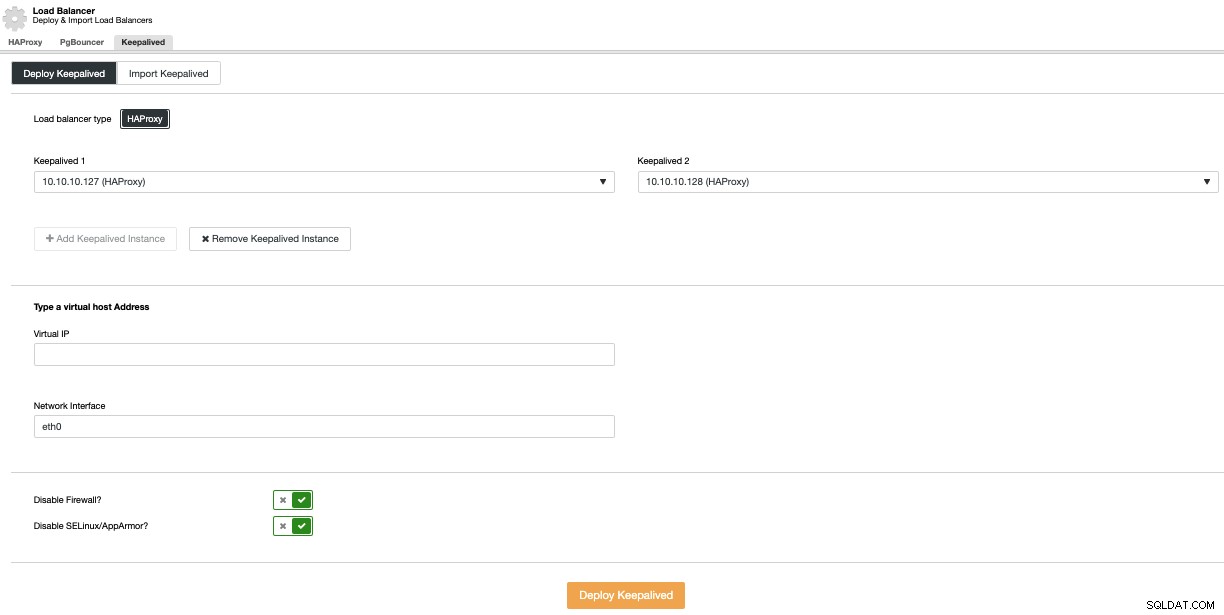
Aquí, seleccione los nodos HAProxy y especifique la dirección IP virtual que usarse para acceder a la base de datos (o al agrupador de conexiones).
En este momento, debería tener la siguiente topología:
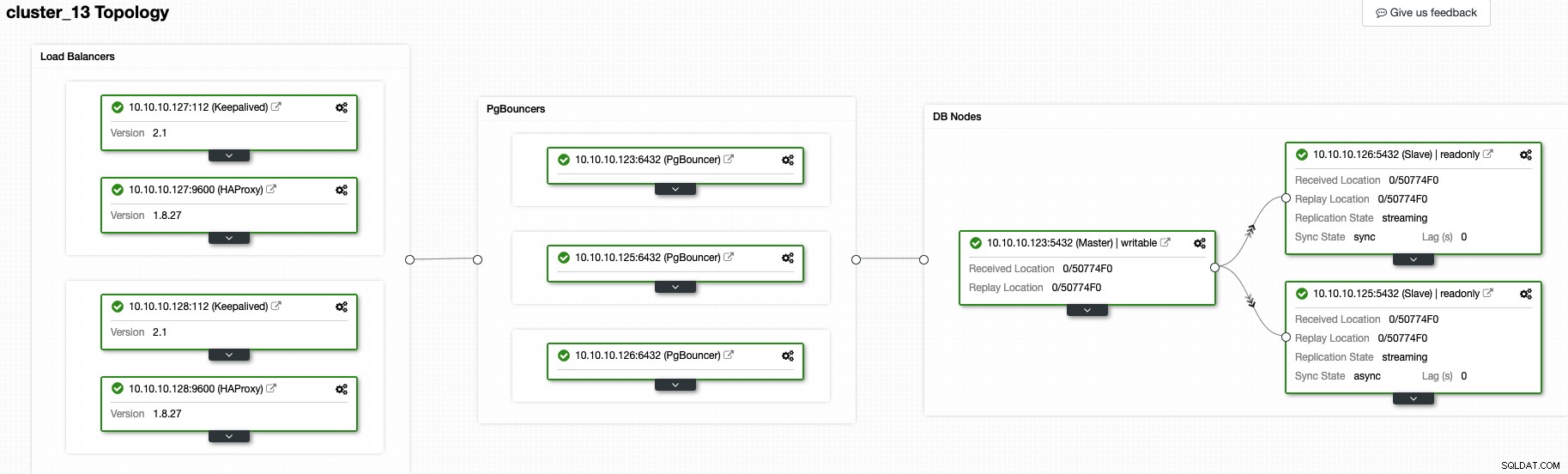
Y esto significa:HAProxy + Keepalived -> PgBouncer -> Nodos de base de datos PostgreSQL , esa es una buena topología para su clúster de PostgreSQL.
Función de recuperación automática de ClusterControl
En caso de falla, ClusterControl promoverá el nodo de reserva más avanzado a principal y le notificará el problema. También falla el resto del nodo en espera para replicar desde el nuevo servidor principal.
De forma predeterminada, HAProxy está configurado con dos puertos diferentes:lectura-escritura y solo lectura. En el puerto de lectura y escritura, tiene su nodo de base de datos principal (o PgBouncer) en línea y el resto de los nodos en línea, y en el puerto de solo lectura, tiene en línea tanto el nodo principal como el de reserva.
Cuando HAProxy detecta que uno de sus nodos no es accesible, lo marca automáticamente como fuera de línea y no lo tiene en cuenta para enviarle tráfico. La detección se realiza mediante secuencias de comandos de comprobación de estado configuradas por ClusterControl en el momento de la implementación. Estos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Cuando ClusterControl promueve un nodo en espera, HAProxy marca el principal anterior como fuera de línea para ambos puertos y pone el nodo promovido en línea en el puerto de lectura y escritura.
Si su HAProxy activo, al que se le asigna una dirección IP virtual a la que se conectan sus sistemas, falla, Keepalived migra esta dirección IP a su HAProxy pasivo automáticamente. Esto significa que sus sistemas podrán continuar funcionando normalmente.
Conclusión
Como puede ver, tener una buena topología de PostgreSQL es fácil si usa ClusterControl y sigue los conceptos básicos de mejores prácticas para la replicación de PostgreSQL. Por supuesto, el mejor entorno depende de la carga de trabajo, el hardware, la aplicación, etc., pero puede usarlo como ejemplo y mover las piezas según lo necesite.