Todos nos hemos echado a perder por la capacidad de los motores de búsqueda para "solucionar" cosas como errores de ortografía, diferencias de ortografía de nombres o cualquier otra situación en la que el término de búsqueda puede coincidir en páginas cuyos autores prefieren usar una ortografía diferente de una palabra. Agregar tales funciones a nuestras propias aplicaciones basadas en bases de datos puede enriquecer y mejorar nuestras aplicaciones de manera similar, y aunque las ofertas comerciales de sistemas de administración de bases de datos relacionales (RDBMS) brindan sus propias soluciones personalizadas completamente desarrolladas para este problema, los costos de licencia de estas herramientas pueden estar fuera de nuestro alcance. llegar a desarrolladores más pequeños o pequeñas empresas de desarrollo de software.
Se podría argumentar que esto podría hacerse usando un corrector ortográfico en su lugar. Sin embargo, un corrector ortográfico normalmente no sirve para hacer coincidir una ortografía correcta, pero alternativa, de un nombre u otra palabra. El emparejamiento por sonido llena este vacío funcional. Ese es el tema del tutorial de programación de hoy:cómo consultar sonidos con Python usando Metaphones.
¿Qué es Soundex?
Soundex se desarrolló a principios del siglo XX como un medio para que el Censo de EE. UU. buscara coincidencias de nombres en función de cómo suenan. Luego fue utilizado por varias compañías telefónicas para hacer coincidir los nombres de los clientes. Continúa usándose para la coincidencia de datos fonéticos hasta el día de hoy, a pesar de que se limita a la ortografía y pronunciación del inglés estadounidense. También se limita a las letras en inglés. La mayoría de los RDBMS, como SQL Server y Oracle, junto con MySQL y sus variantes, implementan una función Soundex y, a pesar de sus limitaciones, se sigue utilizando para hacer coincidir muchas palabras que no están en inglés.
¿Qué es un Metáfono Doble?
El metáfono El algoritmo fue desarrollado en 1990 y supera algunas de las limitaciones de Soundex. En 2000, una continuación mejorada, Double Metaphone , fue desarrollado. Double Metaphone devuelve un valor primario y secundario que corresponde a dos formas en que se puede pronunciar una sola palabra. Hasta el día de hoy, este algoritmo sigue siendo uno de los mejores algoritmos fonéticos de código abierto. Metaphone 3 se lanzó en 2009 como una mejora de Double Metaphone, pero se trata de un producto comercial.
Desafortunadamente, muchos de los RDBMS destacados mencionados anteriormente no implementan Double Metaphone, y la mayoría Los lenguajes de secuencias de comandos destacados no proporcionan una implementación compatible de Double Metaphone. Sin embargo, Python proporciona un módulo que implementa Double Metaphone.
Los ejemplos presentados en este tutorial de programación de Python utilizan MariaDB versión 10.5.12 y Python 3.9.2, ambos ejecutándose en Kali/Debian Linux.
Cómo agregar doble metáfono a Python
Como cualquier módulo de Python, la herramienta pip se puede usar para instalar Double Metaphone. La sintaxis depende de su instalación de Python. Una instalación típica de Double Metaphone se parece al siguiente ejemplo:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Tenga en cuenta que la capitalización adicional es intencional. El siguiente código es un ejemplo de cómo usar Double Metaphone en Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
El script de Python anterior da el siguiente resultado cuando se ejecuta en su entorno de desarrollo integrado (IDE) o editor de código:
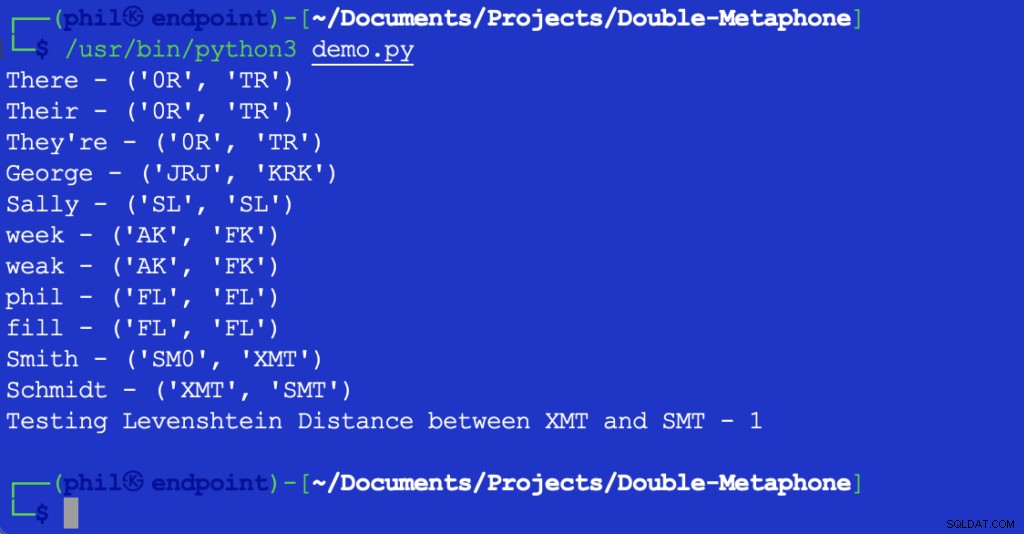
Figura 1:Salida del script de demostración
Como puede verse aquí, cada palabra tiene un valor fonético primario y secundario. Las palabras que coinciden con valores primarios o secundarios se denominan coincidencias fonéticas. Se dice que las palabras que comparten al menos un valor fonético, o que comparten los primeros dos caracteres en cualquier valor fonético, están fonéticamente cercanas entre sí.
La mayoría las letras mostradas corresponden a sus pronunciaciones en inglés. X puede corresponder a KS , SH o C . 0 corresponde al ésimo sonido en el o allí . Las vocales solo se emparejan al principio de una palabra. Debido a la cantidad incontable de diferencias en los acentos regionales, no es posible decir que las palabras pueden ser una coincidencia objetivamente exacta, incluso si tienen los mismos valores fonéticos.
Comparación de valores fonéticos con Python
Existen numerosos recursos en línea que pueden describir el funcionamiento completo del algoritmo Double Metáfono; sin embargo, esto no es necesario para usarlo porque estamos más interesados en comparar los valores calculados, más de lo que nos interesa calcular los valores. Como se indicó anteriormente, si hay al menos un valor en común entre dos palabras, se puede decir que estos valores son coincidencias fonéticas y valores fonéticos que son similares son fonéticamente cercanos .
Comparar valores absolutos es fácil, pero ¿cómo se puede determinar que las cadenas son similares? Si bien no existen limitaciones técnicas que le impidan comparar cadenas de varias palabras, estas comparaciones generalmente no son confiables. Limítate a comparar palabras sueltas.
¿Qué son las distancias de Levenshtein?
La Distancia de Levenshtein entre dos cadenas es el número de caracteres individuales que se deben cambiar en una cadena para que coincida con la segunda cadena. Un par de cuerdas que tienen una distancia de Levenshtein más baja son más similares entre sí que un par de cuerdas que tienen una distancia de Levenshtein más alta. La distancia de Levenshtein es similar a la distancia de Hamming , pero este último está limitado a cadenas de la misma longitud, ya que los valores fonéticos de Double Metaphone pueden variar en longitud, tiene más sentido compararlos utilizando la distancia de Levenshtein.
Biblioteca a distancia de Python Levenshtein
Python se puede ampliar para admitir cálculos de distancia de Levenshtein a través de un módulo de Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Tenga en cuenta que, al igual que con la instalación del DoubleMetaphone arriba, la sintaxis de la llamada a pip puede variar. El módulo python-Levenshtein proporciona mucha más funcionalidad que solo cálculos de la distancia de Levenshtein.
El siguiente código muestra una prueba para el cálculo de la distancia de Levenshtein en Python:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Ejecutar este script da el siguiente resultado:
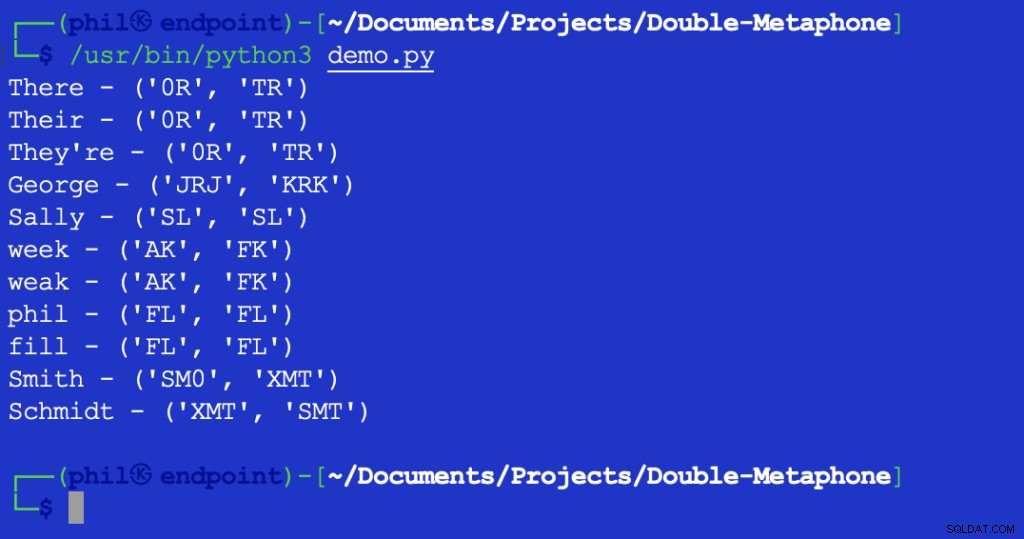
Figura 2:resultado de la prueba de distancia de Levenshtein
El valor devuelto de 1 indica que hay un carácter entre XMT y SMT eso es diferente. En este caso, es el primer carácter de ambas cadenas.
Comparación de metáfonos dobles en Python
Lo que sigue no es el principio y fin de todas las comparaciones fonéticas. Es simplemente una de las muchas maneras de realizar tal comparación. Para comparar efectivamente la proximidad fonética de dos cadenas dadas, cada valor fonético de Metaphone doble de una cadena debe compararse con el valor fonético de Metaphone doble correspondiente de otra cadena. Dado que ambos valores fonéticos de una cadena dada tienen el mismo peso, entonces el promedio de estos valores de comparación dará una aproximación razonablemente buena de la cercanía fonética:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
donde:
- DM1(1) :Primer valor doble de metáfono de la cadena 1,
- DM1(2) :Segundo valor doble de metáfono de la cadena 1
- DM2(1) :Primer valor doble de metáfono de la cadena 2
- DM2(2) :Segundo valor doble de metáfono de la cadena 2
- PN :Cercanía fonética, donde los valores más bajos están más cerca que los valores más altos. Un valor cero indica similitud fonética. El valor más alto para esto es el número de letras en la cadena más corta.
Esta fórmula falla en casos como Schmidt (XMT, SMT) y Smith (SM0, XMT) donde el primer valor fonético de la primera cadena coincide con el segundo valor fonético de la segunda cadena. En tales situaciones, tanto Schmidt y Smith pueden considerarse fonéticamente similares debido al valor compartido. El código para la función de proximidad debe aplicar la fórmula anterior solo cuando los cuatro valores fonéticos son diferentes. La fórmula también tiene debilidades cuando se comparan cadenas de diferentes longitudes.
Tenga en cuenta que no existe una forma singularmente eficaz de comparar cadenas de diferentes longitudes, aunque al calcular la distancia de Levenshtein entre dos cadenas se tienen en cuenta las diferencias en la longitud de la cadena. Una posible solución sería comparar ambas cadenas hasta la longitud de la más corta de las dos cadenas.
A continuación se muestra un fragmento de código de ejemplo que implementa el código anterior, junto con algunos ejemplos de prueba:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
El código Python de muestra da el siguiente resultado:
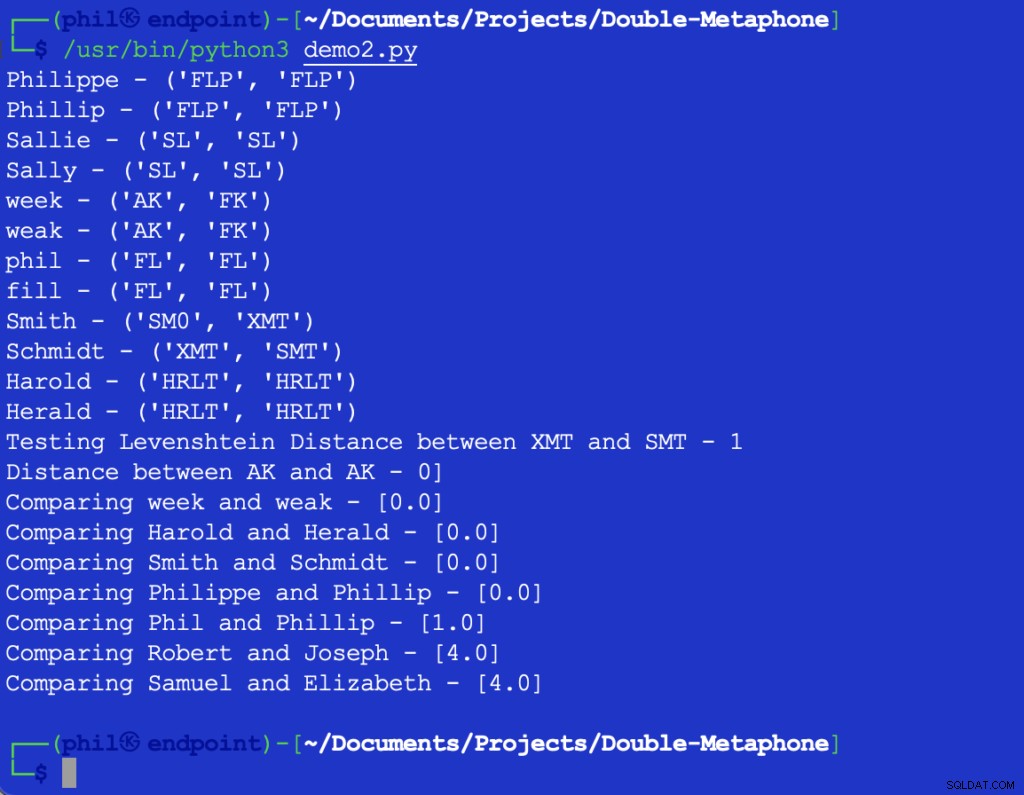
Figura 3:Salida del algoritmo de proximidad
El conjunto de muestras confirma la tendencia general de que cuanto mayores sean las diferencias en las palabras, mayor será el resultado de la Cercanía función.
Integración de base de datos en Python
El código anterior rompe la brecha funcional entre un RDBMS dado y una implementación de Double Metaphone. Además de esto, al implementar la Cercanía función en Python, se vuelve fácil de reemplazar si se prefiere un algoritmo de comparación diferente.
Considere la siguiente tabla MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
En la mayoría de las aplicaciones basadas en bases de datos, el middleware compone declaraciones SQL para administrar los datos, incluida la inserción. El siguiente código insertará algunos nombres de muestra en esta tabla, pero en la práctica, cualquier código de una aplicación web o de escritorio que recopile dichos datos podría hacer lo mismo.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Ejecutar este código no imprime nada, pero llena la tabla de prueba en la base de datos para que la use la siguiente lista. Consultar la tabla directamente en el cliente MySQL puede verificar que el código anterior funcionó:
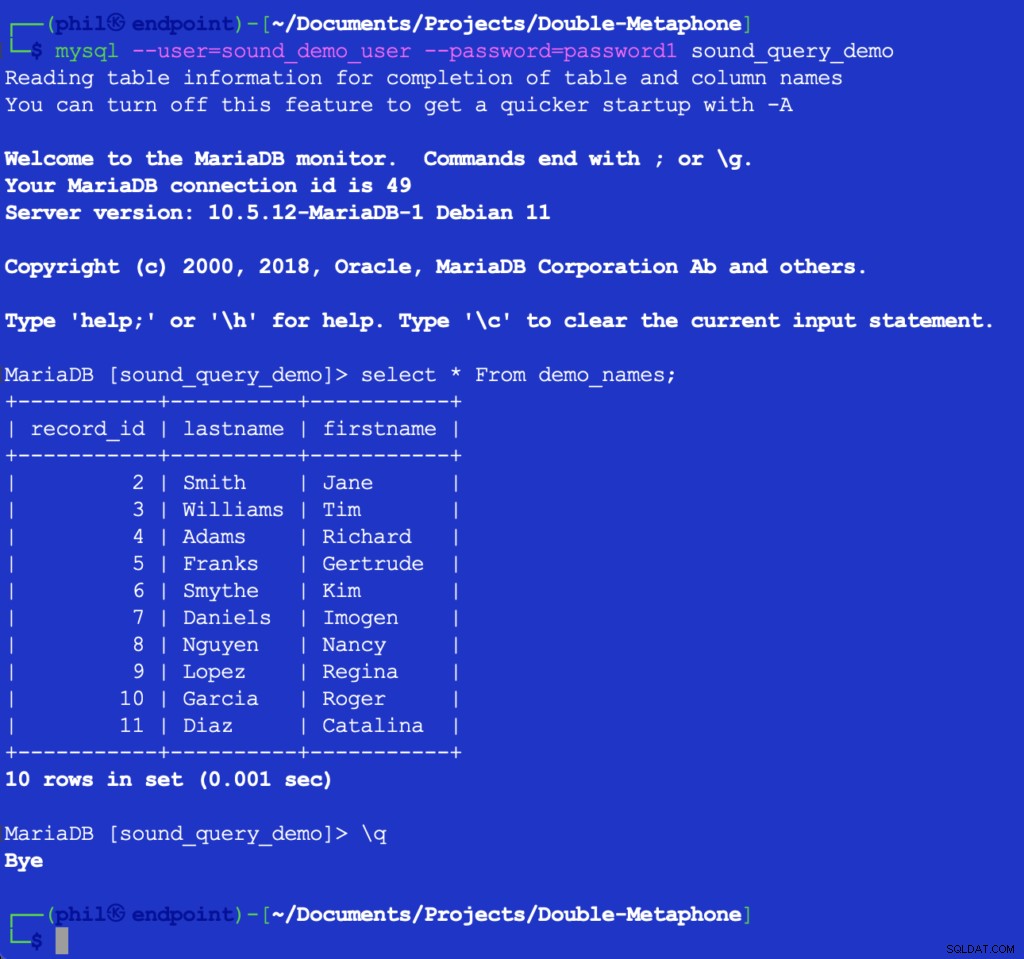
Figura 4:los datos de la tabla insertada
El siguiente código introducirá algunos datos de comparación en los datos de la tabla anterior y realizará una comparación de proximidad con ellos:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Ejecutar este código nos da el siguiente resultado:
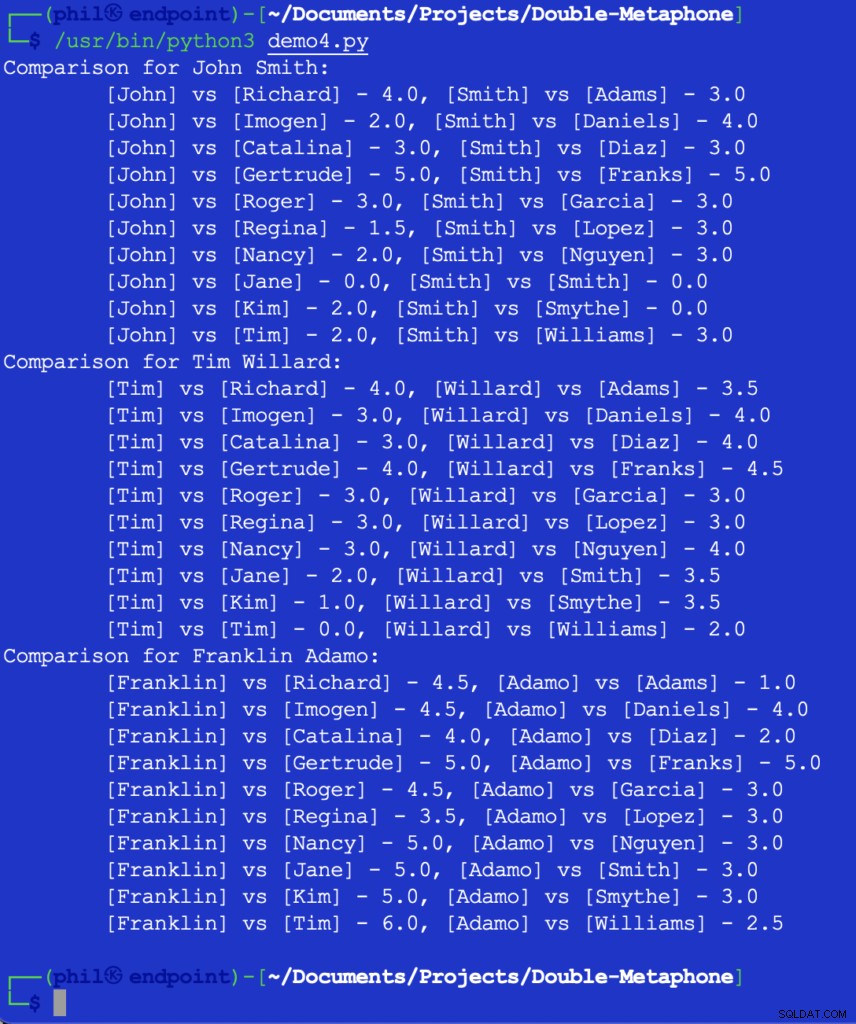
Figura 5:resultados de la comparación de proximidad
En este punto, dependería del desarrollador decidir cuál sería el umbral de lo que constituye una comparación útil. Algunos de los números anteriores pueden parecer inesperados o sorprendentes, pero una posible adición al código podría ser un SI declaración para filtrar cualquier valor de comparación que sea mayor que 2 .
Puede valer la pena señalar que los valores fonéticos en sí mismos no se almacenan en la base de datos. Esto se debe a que se calculan como parte del código de Python y no existe una necesidad real de almacenarlos en ningún lugar, ya que se descartan cuando el programa sale; sin embargo, un desarrollador puede encontrar valor al almacenarlos en la base de datos y luego implementar la comparación. función dentro de la base de datos un procedimiento almacenado. Sin embargo, el principal inconveniente de esto es la pérdida de portabilidad del código.
Reflexiones finales sobre la consulta de datos por sonido con Python
La comparación de datos por sonido no parece obtener el "amor" o la atención que puede obtener la comparación de datos por análisis de imágenes, pero si una aplicación tiene que lidiar con múltiples variantes de palabras con sonidos similares en varios idiomas, puede ser una herramienta crucialmente útil. herramienta. Una característica útil de este tipo de análisis es que un desarrollador no necesita ser un experto en lingüística o fonética para hacer uso de estas herramientas. El desarrollador también tiene una gran flexibilidad para definir cómo se pueden comparar dichos datos; las comparaciones se pueden modificar en función de las necesidades de la aplicación o la lógica empresarial.
Con suerte, este campo de estudio recibirá más atención en el ámbito de la investigación y habrá herramientas de análisis más capaces y sólidas en el futuro.



