[ Parte 1 | Parte 2 | Parte 3 ]
En el espíritu de las diatribas recientes de Grant Fritchey, y los esfuerzos de Erin Stellato desde antes de que nos conociéramos, quiero subirme al tren para anunciar y promover la idea de deshacerse del rastro a favor de los eventos extendidos. Cuando alguien dice rastrear , la mayoría de la gente piensa inmediatamente en Perfilador . Si bien Profiler es su propia pesadilla especial, hoy quería hablar sobre el seguimiento predeterminado de SQL Server.
En nuestro entorno, está habilitado en los más de 200 servidores de producción y recolecta una gran cantidad de basura que nunca vamos a investigar. Tanta basura, de hecho, que los eventos importantes que podemos encontrar útiles para la resolución de problemas salen de los archivos de seguimiento antes de que tengamos la oportunidad. Así que comencé a considerar la posibilidad de apagarlo porque:
- no es gratis (la sobrecarga del observador de la propia actividad de rastreo, la E/S involucrada con la escritura en los archivos de rastreo y el espacio que consumen);
- en la mayoría de los servidores, nunca se mira; en otros, rara vez; y,
- es fácil de volver a encender para la solución de problemas específicos y aislados.
Un par de otras cosas afectan el valor de la traza predeterminada. No se puede configurar de ninguna manera:no puede cambiar qué eventos recopila, no puede agregar filtros y no puede controlar cuántos archivos guarda (5), qué tan grandes pueden llegar a ser (20 MB cada uno) , o dónde están almacenados (SERVERPROPERTY('ErrorLogFileName') ). Por lo tanto, estamos completamente a merced de la carga de trabajo:en cualquier servidor dado, no podemos predecir qué tan atrás podrían estar los datos (eventos con TextData más grandes valores, por ejemplo, pueden ocupar mucho más espacio y eliminar eventos más antiguos más rápidamente). A veces puede retroceder una semana, otras veces puede retroceder solo unos minutos.
Análisis del estado actual
Ejecuté el siguiente código en 224 instancias de producción, solo para comprender qué tipo de ruido llena el seguimiento predeterminado en nuestro entorno. Esto es probablemente más complicado de lo que debe ser, y ni siquiera es tan complejo como la consulta final que utilicé, pero es un buen punto de partida para analizar el desglose de los tipos de eventos de alto nivel que se están capturando actualmente:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (El predicado EventSubClass está ahí para evitar el conteo doble de eventos DDL.Para obtener un mapa de los valores de EventClass, los enumeré en esta respuesta en Stack Exchange).
Y los resultados no son bonitos (resultados típicos de un servidor aleatorio). Lo siguiente no representa el resultado exacto de esa consulta, pero pasé un tiempo agregando los resultados en un formato más digerible, para ver cuántos datos eran útiles y cuánto ruido (haga clic para ampliar):
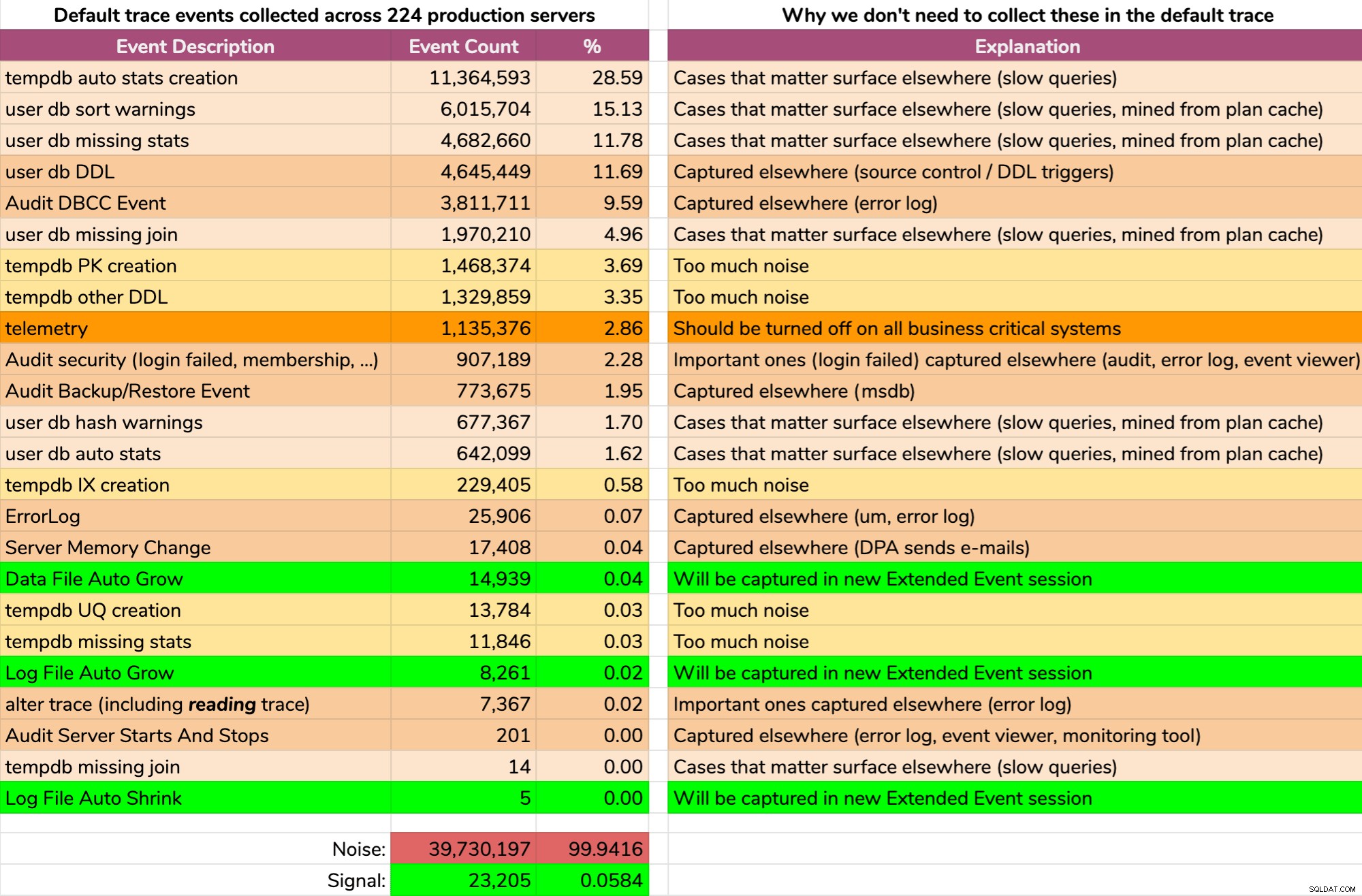
Casi todo el ruido (99,94%). Lo único útil que alguna vez necesitábamos del seguimiento predeterminado eran los eventos de crecimiento y reducción de archivos, ya que eran lo único que no capturábamos en ningún otro lugar de una forma u otra. Pero incluso en eso no siempre podemos confiar, porque los datos se pierden muy rápido.
Otra forma en que dividí los datos:evento más antiguo por instancia. ¡Algunas instancias tenían tanto ruido que no podían mantener los datos de seguimiento predeterminados durante más de unos minutos! Borré los nombres de los servidores, pero estos son datos reales (estos son los 20 servidores con el historial más corto; haga clic para ampliar):
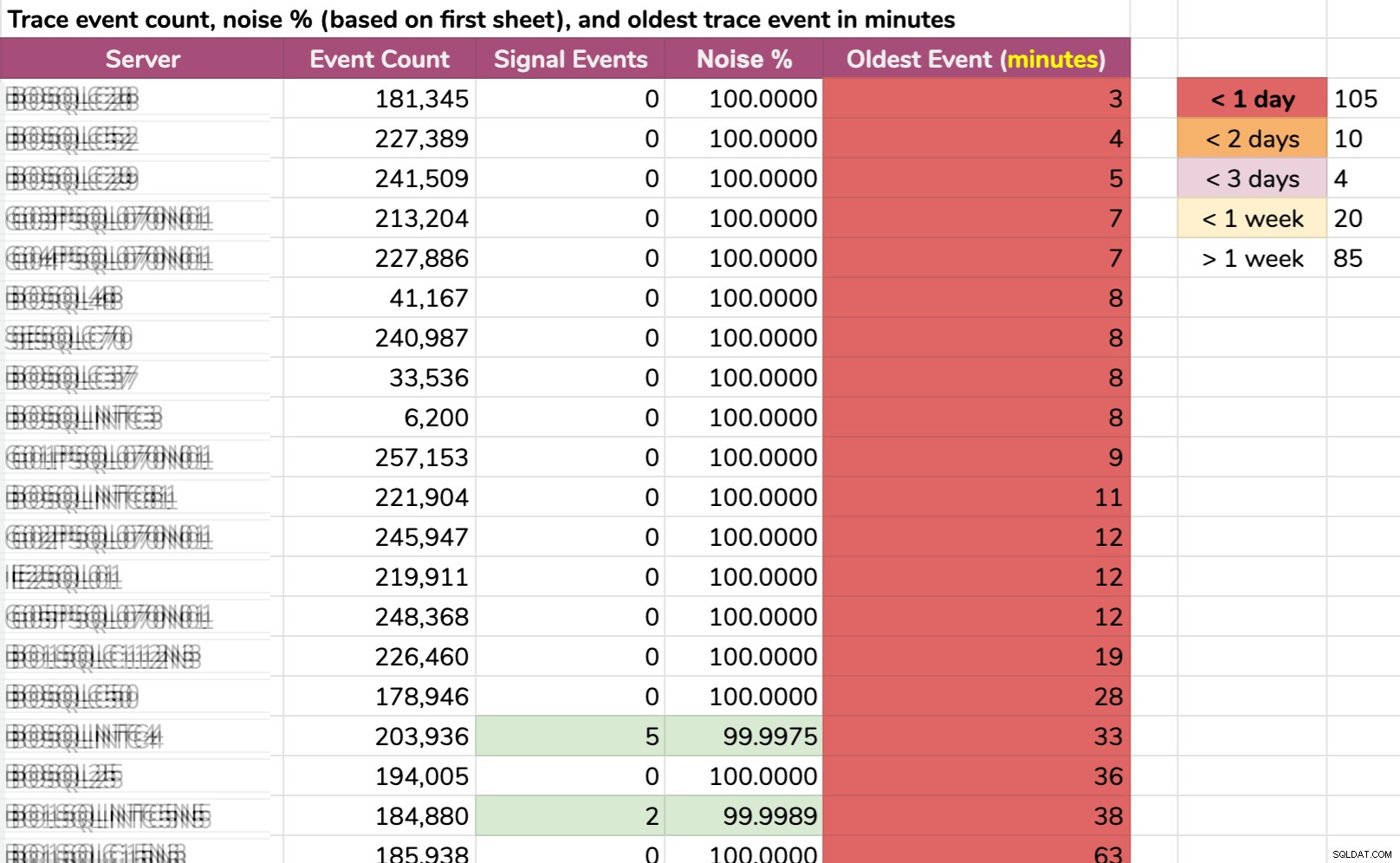
Incluso si el seguimiento recopilara solo información relevante, y sucedió algo interesante, tendríamos que actuar rápidamente para atraparlo, dependiendo del servidor. Si sucedió:
- Hace 20 minutos , entonces ya se habrá ido en 15 instancias .
- esta vez ayer , desaparecería en 105 instancias .
- hace dos días , desaparecería en 115 instancias .
- hace más de una semana , desaparecería en 139 instancias .
También teníamos un puñado de servidores en el otro extremo, pero no son interesantes en este contexto; esos servidores están así simplemente porque no sucede nada interesante allí (por ejemplo, no están ocupados ni forman parte de ninguna carga de trabajo crítica).
En el lado positivo...
La investigación del rastreo predeterminado reveló algunas configuraciones incorrectas en algunos de nuestros servidores:
- Varios servidores aún tenían telemetría habilitada . Estoy a favor de ayudar a Microsoft en ciertos entornos, pero no a ningún costo general en los sistemas críticos para el negocio.
- Algunas tareas de sincronización en segundo plano estaban agregando miembros a roles a ciegas , una y otra vez, sin verificar si ya estaban en esos roles. Esto no es dañino en sí mismo, especialmente porque estos eventos ya no llenarán el seguimiento predeterminado, pero es probable que también llenen las auditorías con ruido, y probablemente haya otras operaciones de reaplicación ciega que suceden en el mismo patrón.
- Alguien había habilitado la reducción automática en algún lugar (¡Dios mío!), así que esto era algo que quería rastrear y evitar que volviera a suceder (el nuevo XE también capturará estos eventos).
Esto condujo a tareas de seguimiento para solucionar estos problemas y/o agregar condiciones a la automatización existente que ya estaba en marcha. Por lo tanto, podemos prevenir la recurrencia sin depender de tener la suerte de encontrarlos en alguna revisión de seguimiento predeterminada futura, antes de que se implementen.
…pero el problema persiste
De lo contrario, todo es información sobre la que no podemos actuar o, como se describe en el gráfico anterior, eventos que ya capturamos en otro lugar. Y nuevamente, los únicos datos que me interesan del seguimiento predeterminado que aún no capturamos por otros medios son los eventos relacionados con el crecimiento y reducción de archivos (aunque el seguimiento predeterminado solo captura la variedad automática).
Pero el mayor problema no es realmente el volumen del ruido. Puedo manejar grandes archivos de rastreo masivos con mucha basura, ya que las cláusulas WHERE se inventaron exactamente para este propósito. El problema real es que los eventos importantes estaban desapareciendo demasiado rápido.
La respuesta
La respuesta, al menos en nuestro escenario, fue simple:deshabilite el seguimiento predeterminado, ya que no vale la pena ejecutarlo si no se puede confiar en él.
Pero dada la cantidad de ruido anterior, ¿qué debería reemplazarlo? ¿Algo?
Es posible que desee una sesión de eventos extendidos que capture todo la traza predeterminada capturada. Si es así, Jonathan Kehayias lo tiene cubierto. Esto le daría la misma información, pero con control sobre cosas como la retención, dónde se almacenan los datos y, a medida que se sienta más cómodo, la capacidad de eliminar algunos de los eventos más ruidosos o menos útiles, gradualmente, con el tiempo.
Mi plan era un poco más agresivo y rápidamente se convirtió en un proceso "simple" para realizar lo siguiente en todos los servidores del entorno (a través de CMS):
Tenga en cuenta que no estoy sugiriendo que deshabilite ciegamente el seguimiento predeterminado , simplemente explicando por qué elegí hacerlo en nuestro entorno. En las próximas publicaciones de esta serie, mostraré la nueva sesión de eventos extendidos, la vista que expone los datos subyacentes, el código que usé para implementar estos cambios en todos los servidores y los posibles efectos secundarios que debe tener en cuenta.
[ Parte 1 | Parte 2 | Parte 3 ]