Esta es la tercera de una serie de cinco partes que profundiza en la forma en que comienzan a ejecutarse los planes paralelos en modo fila de SQL Server. La parte 1 inicializó el contexto de ejecución cero para la tarea principal y la parte 2 creó el árbol de exploración de consultas. Ahora estamos listos para iniciar el análisis de consultas, realizar alguna fase inicial procesamiento e iniciar las primeras tareas paralelas adicionales.
Inicio de exploración de consulta
Recuerde que solo la tarea principal existe en este momento, y los intercambios (operadores de paralelismo) tienen solo un lado del consumidor. Aún así, esto es suficiente para que comience la ejecución de la consulta, en el subproceso de trabajo de la tarea principal. El procesador de consultas comienza la ejecución iniciando el proceso de exploración de consultas a través de una llamada a CQueryScan::StartupQuery . Un recordatorio del plan (haga clic para ampliar):
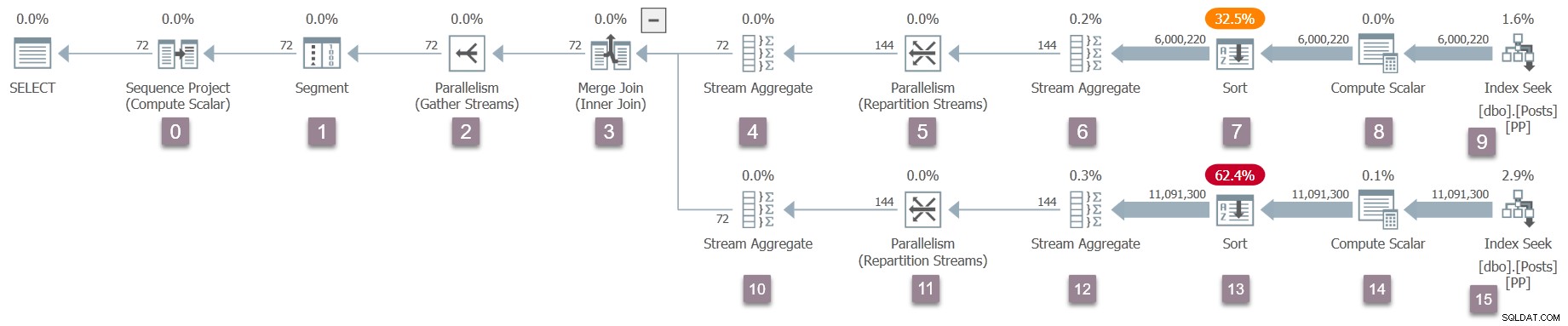
Este es el primer punto en el proceso hasta ahora que un plan de ejecución en curso está disponible (SQL Server 2016 SP1 en adelante) en sys.dm_exec_query_statistics_xml . No hay nada particularmente interesante que ver en un plan de este tipo en este momento, porque todos los contadores transitorios son cero, pero el plan está al menos disponible . No hay indicios de que aún no se hayan creado tareas paralelas, o que los intercambios carezcan de un lado del productor. El plan parece "normal" en todos los aspectos.
ramas plano paralelo
Dado que este es un plan paralelo, será útil mostrarlo dividido en ramas. Estos están sombreados a continuación y etiquetados como ramas de la A a la D:
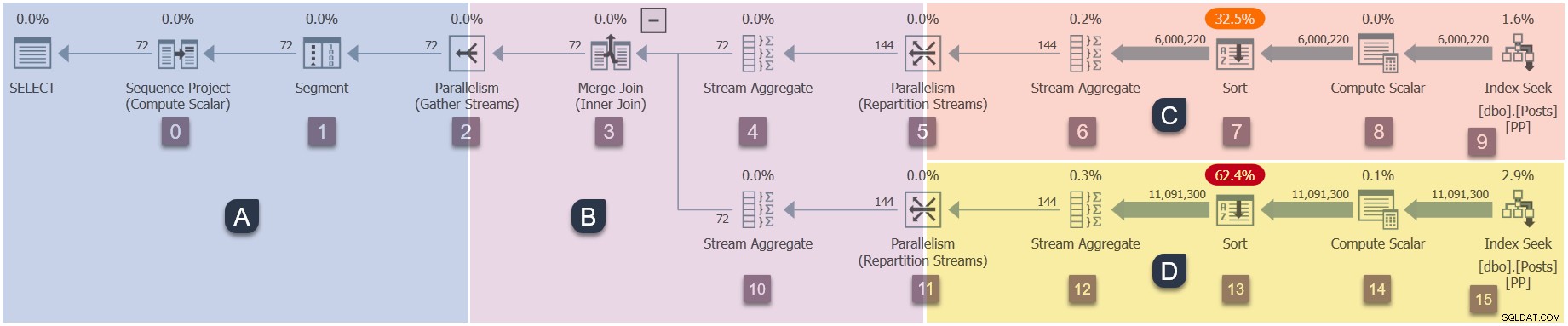
La rama A está asociada con la tarea principal y se ejecuta en el subproceso de trabajo proporcionado por la sesión. Se iniciarán trabajadores paralelos adicionales para ejecutar las tareas paralelas adicionales contenidas en las ramas B, C y D. Esas ramas son paralelas, por lo que habrá tareas y trabajadores adicionales del DOP en cada una.
Nuestra consulta de ejemplo se ejecuta en DOP 2, por lo que la sucursal B obtendrá dos tareas adicionales. Lo mismo ocurre con la rama C y la rama D, dando un total de seis tareas adicionales. Cada tarea se ejecutará en su propio subproceso de trabajo en su propio contexto de ejecución.
Dos programadores (S1 y S2 ) se asignan a esta consulta para ejecutar trabajadores paralelos adicionales. Cada trabajador adicional se ejecutará en uno de esos dos programadores. El trabajador principal puede ejecutarse en un programador diferente, por lo que nuestra consulta DOP 2 puede usar un máximo de tres núcleos de procesador en cualquier momento.
Para resumir, nuestro plan eventualmente tendrá:
- Sucursal A (padre)
- Tarea principal.
- Subproceso de trabajo principal.
- Contexto de ejecución cero.
- Cualquier planificador único disponible para la consulta.
- Sucursal B (adicional)
- Dos tareas adicionales.
- Un subproceso de trabajo adicional vinculado a cada nueva tarea.
- Dos nuevos contextos de ejecución, uno para cada nueva tarea.
- Un subproceso de trabajo se ejecuta en el programador S1 . El otro se ejecuta en el programador S2 .
- Sucursal C (adicional)
- Dos tareas adicionales.
- Un subproceso de trabajo adicional vinculado a cada nueva tarea.
- Dos nuevos contextos de ejecución, uno para cada nueva tarea.
- Un subproceso de trabajo se ejecuta en el programador S1 . El otro se ejecuta en el programador S2 .
- Sucursal D (adicional)
- Dos tareas adicionales.
- Un subproceso de trabajo adicional vinculado a cada nueva tarea.
- Dos nuevos contextos de ejecución, uno para cada nueva tarea.
- Un subproceso de trabajo se ejecuta en el programador S1 . El otro se ejecuta en el programador S2 .
La pregunta es cómo se crean todas estas tareas adicionales, trabajadores y contextos de ejecución, y cuándo comienzan a ejecutarse.
Secuencia de inicio
La secuencia en la que tareas adicionales empezar a ejecutar para este plan en particular es:
- Rama A (tarea principal).
- Sucursal C (tareas paralelas adicionales).
- Sucursal D (tareas paralelas adicionales).
- Sucursal B (tareas paralelas adicionales).
Es posible que ese no sea el orden de puesta en marcha que esperaba.
Puede haber un retraso significativo entre cada uno de estos pasos, por razones que exploraremos en breve. El punto clave en esta etapa es que las tareas adicionales, los trabajadores y los contextos de ejecución no todos creados a la vez, y no todos comienzan a ejecutarse al mismo tiempo.
SQL Server podría haber sido diseñado para iniciar todos los bits paralelos adicionales a la vez. Eso podría ser fácil de comprender, pero no sería muy eficiente en general. Maximizaría la cantidad de subprocesos adicionales y otros recursos utilizados por la consulta, y generaría una gran cantidad de esperas paralelas innecesarias.
Con el diseño empleado por SQL Server, los planes paralelos a menudo usarán menos subprocesos de trabajo totales que (DOP multiplicado por el número total de sucursales). Esto se logra reconociendo que algunas ramas pueden ejecutarse hasta su finalización antes de que otra rama deba comenzar. Esto puede permitir la reutilización de subprocesos dentro de la misma consulta y, en general, reduce el consumo general de recursos.
Pasemos ahora a los detalles de cómo se pone en marcha nuestro plan paralelo.
Apertura de Sucursal A
El escaneo de consultas comienza a ejecutarse con la tarea principal llamando a Open() en el iterador en la raíz del árbol. Este es el comienzo de la secuencia de ejecución:
- Rama A (tarea principal).
- Sucursal C (tareas paralelas adicionales).
- Sucursal D (tareas paralelas adicionales).
- Sucursal B (tareas paralelas adicionales).
Estamos ejecutando esta consulta con un plan "real" solicitado, por lo que el iterador raíz no el operador de proyecto de secuencia en el nodo 0. Más bien, es el iterador de perfilado invisible que registra métricas de tiempo de ejecución en planes de modo de fila.
La siguiente ilustración muestra los iteradores de exploración de consultas en la Rama A del plan, con la posición de los iteradores de perfilado invisibles representada por los íconos de 'gafas'.
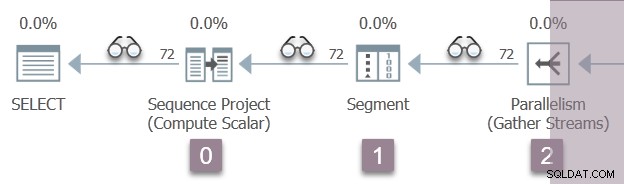
La ejecución comienza con una llamada para abrir el primer generador de perfiles, CQScanProfileNew::Open . Esto establece el tiempo abierto para el operador del proyecto de secuencia secundaria a través de la API del contador de rendimiento de consultas del sistema operativo.
Podemos ver este número en sys.dm_exec_query_profiles :
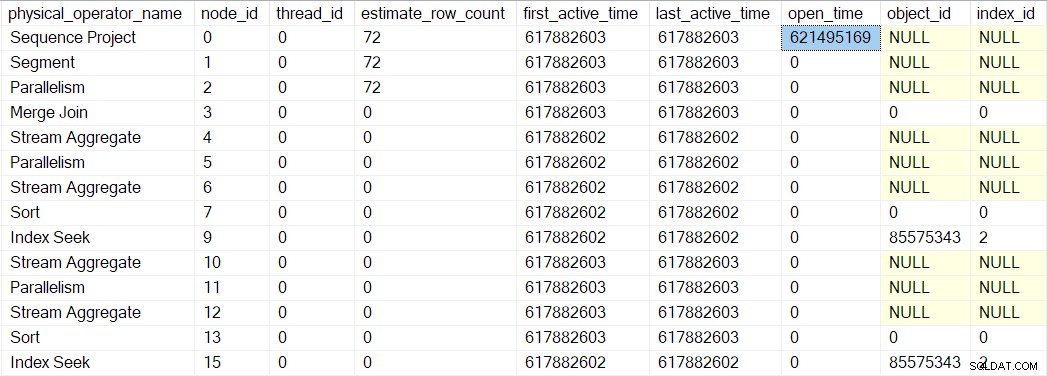
Las entradas allí pueden tener los nombres de los operadores enumerados, pero los datos provienen del perfilador sobre el operador, no el operador mismo.
Da la casualidad de que un proyecto de secuencia (CQScanSeqProjectNew ) no necesita hacer ningún trabajo cuando se abre , por lo que en realidad no tiene un Open() método. El generador de perfiles sobre el proyecto de secuencia es llamado, por lo que se registra un tiempo abierto para el proyecto de secuencia en el DMV.
Open del generador de perfiles el método no llama a Open en el proyecto de secuencia (ya que no tiene uno). En su lugar, llama a Open en el generador de perfiles para el siguiente iterador en secuencia. Este es el segmento iterador en el nodo 1. Eso establece el tiempo abierto para el segmento, tal como lo hizo el generador de perfiles anterior para el proyecto de secuencia:
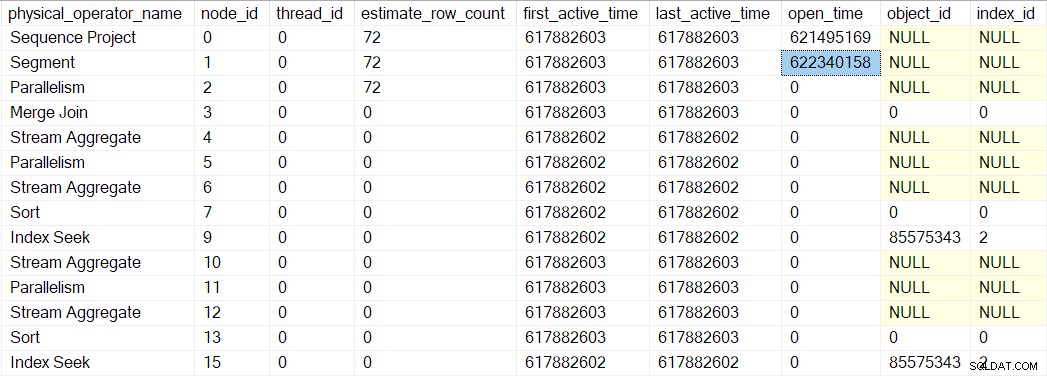
Un iterador de segmento sí tiene cosas que hacer cuando se abre, por lo que la siguiente llamada es CQScanSegmentNew::Open . Una vez que el segmento ha hecho lo que debe hacer, llama al generador de perfiles para el siguiente iterador en secuencia:el consumidor. lado del intercambio de flujos de recopilación en el nodo 2:
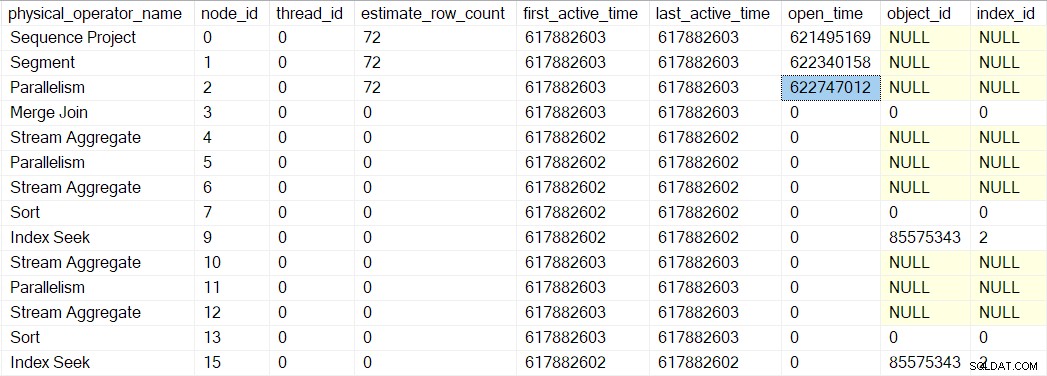
La siguiente llamada al árbol de exploración de consultas en el proceso de apertura es CQScanExchangeNew::Open , que es donde las cosas empiezan a ponerse más interesantes.
Abriendo el intercambio de recopilación de flujos
Pedirle al lado del consumidor del intercambio que abra:
- Abre una transacción local (anidada en paralelo) (
CXTransLocal::Open). Cada proceso necesita una transacción que lo contenga, y las tareas paralelas adicionales no son una excepción. No pueden compartir la transacción principal (base) directamente, por lo que se utilizan transacciones anidadas. Cuando una tarea paralela necesita acceder a la transacción base, se sincroniza en un pestillo y puede encontrarNESTING_TRANSACTION_READONLYoNESTING_TRANSACTION_FULLespera. - Registra el subproceso de trabajo actual con el puerto de intercambio (
CXPort::Register). - Se sincroniza con otros subprocesos en el lado del consumidor del intercambio (
sqlmin!CXTransLocal::Synchronize). No hay otros subprocesos en el lado del consumidor de un flujo de recopilación, por lo que esto es esencialmente una operación no operativa en esta ocasión.
Procesamiento de “Fases Iniciales”
La tarea principal ahora ha llegado al borde de la Rama A. El siguiente paso es particular a planes paralelos en modo fila:la tarea principal continúa la ejecución llamando a CQScanExchangeNew::EarlyPhases en el iterador de intercambio de flujos de recopilación en el nodo 2. Este es un método de iterador adicional más allá del habitual Open , GetRow y Close métodos con los que muchos de ustedes estarán familiarizados. EarlyPhases solo se llama en planes paralelos en modo fila.
Quiero dejar algo claro en este punto:el lado del productor del intercambio de flujos de recopilación en el nodo 2 no se ha creado todavía, y no se han creado tareas paralelas adicionales. Todavía estamos ejecutando código para la tarea principal, utilizando el único subproceso que se está ejecutando en este momento.
No todos los iteradores implementan EarlyPhases , porque no todos tienen nada especial que hacer a estas alturas en los planes paralelos en modo fila. Esto es análogo al proyecto de secuencia que no implementa Open método porque no tiene nada que hacer en ese momento. Los principales iteradores con EarlyPhases los métodos son:
CQScanConcatNew(concatenación).CQScanMergeJoinNew(combinar unir).CQScanSwitchNew(interruptor).CQScanExchangeNew(paralelismo).CQScanNew(acceso al conjunto de filas, por ejemplo, escaneos y búsquedas).CQScanProfileNew(perfiladores invisibles).CQScanLightProfileNew(perfiladores invisibles ligeros).
Primeras fases de la rama B
La tarea principal continúa llamando a EarlyPhases en operadores secundarios más allá del intercambio de flujos de recopilación en el nodo 2. Una tarea que se mueve sobre un límite de rama puede parecer inusual, pero recuerde que el contexto de ejecución cero contiene todo el plan en serie, con intercambios incluidos. El procesamiento de fase temprana se trata de inicializar el paralelismo, por lo que no cuenta como ejecución per se .
Para ayudarlo a realizar un seguimiento, la siguiente imagen muestra los iteradores en la Rama B del plan:
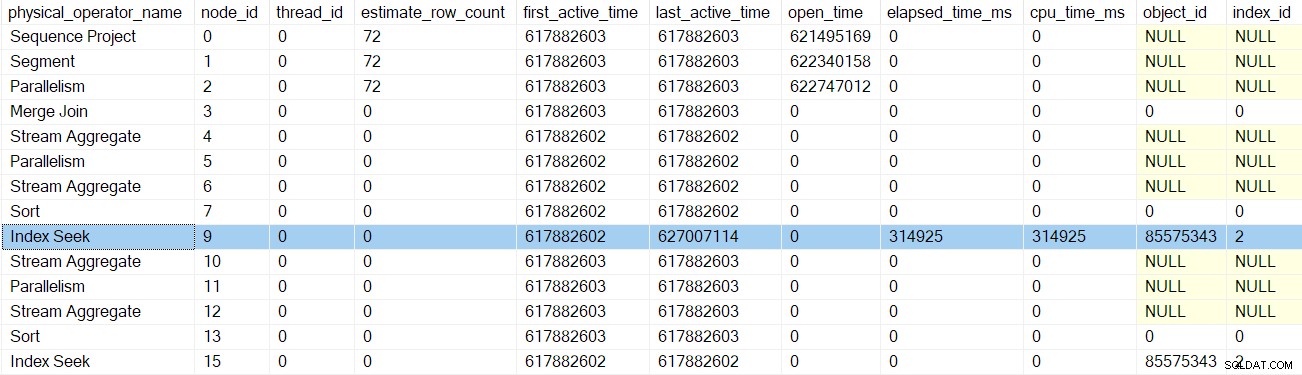
Recuerde, todavía estamos en el contexto de ejecución cero, por lo que solo me refiero a esto como Rama B por conveniencia. No hemos empezado ninguna ejecución paralela todavía.
La secuencia de invocaciones de código de fase temprana en la Rama B es:
CQScanProfileNew::EarlyPhasespara el generador de perfiles sobre el nodo 3.CQScanMergeJoinNew::EarlyPhasesen el nodo 3 merge join .CQScanProfileNew::EarlyPhasespara el generador de perfiles sobre el nodo 4. El nodo 4 agregado de flujo en sí mismo no tiene un método de fases tempranas.CQScanProfileNew::EarlyPhasesen el generador de perfiles sobre el nodo 5.CQScanExchangeNew::EarlyPhasespara los flujos de reparto intercambio en el nodo 5.
Tenga en cuenta que solo estamos procesando la entrada externa (superior) a la unión de fusión en esta etapa. Esta es solo la secuencia iterativa de ejecución del modo de fila normal. No es particular de los planes paralelos.
Primeras fases de la rama C
El procesamiento de la fase inicial continúa con los iteradores en la Rama C:

La secuencia de llamadas aquí es:
CQScanProfileNew::EarlyPhasespara el generador de perfiles sobre el nodo 6.CQScanProfileNew::EarlyPhasespara el generador de perfiles sobre el nodo 7.CQScanProfileNew::EarlyPhasesen el generador de perfiles sobre el nodo 9.CQScanNew::EarlyPhasespara la búsqueda de índice en el nodo 9.
No hay EarlyPhases método en el flujo agregado u ordenado. El trabajo realizado por el escalar de cómputo en el nodo 8 es diferido (a la clasificación), por lo que no aparece en el árbol de exploración de consultas y no tiene un perfilador asociado.
Acerca de los tiempos del generador de perfiles
Tarea principal procesamiento de fase temprana comenzó en el intercambio de flujos de recopilación en el nodo 2. Descendió por el árbol de exploración de consultas, siguiendo la entrada externa (superior) hasta la combinación de combinación, hasta la búsqueda de índice en el nodo 9. En el camino, la tarea principal ha llamado las EarlyPhases método en cada iterador que lo admita.
Hasta ahora, ninguna de las actividades de las primeras fases se ha actualizado. en cualquier momento en la elaboración de perfiles del DMV. Específicamente, ninguno de los iteradores tocados por el procesamiento de las primeras fases ha tenido su "tiempo abierto" establecido. Esto tiene sentido, porque el procesamiento de la fase inicial solo está configurando la ejecución paralela:estos operadores serán abiertos para su ejecución posterior.
El índice de búsqueda en el nodo 9 es un nodo hoja, no tiene hijos. La tarea principal ahora comienza a regresar desde las EarlyPhases anidadas. llamadas, ascendente el árbol de exploración de consultas de vuelta al intercambio de flujos de recopilación.
Cada uno de los generadores de perfiles llama al Contador de rendimiento de consultas API en la entrada a sus EarlyPhases método, y lo vuelven a llamar a la salida. La diferencia entre los dos números representa el tiempo transcurrido para el iterador y todos sus hijos (ya que las llamadas a métodos están anidadas).
Después de que vuelve el generador de perfiles para la búsqueda de índice, el DMV del generador de perfiles muestra el tiempo transcurrido y el tiempo de CPU para la búsqueda de índice únicamente, así como un último activo actualizado tiempo. Tenga en cuenta también que esta información se registra en la tarea principal (la única opción en este momento):
Ninguno de los iteradores anteriores tocados por las llamadas de las primeras fases ha transcurrido el tiempo o ha actualizado los últimos tiempos activos. Estos números solo se actualizan cuando ascendemos en el árbol.
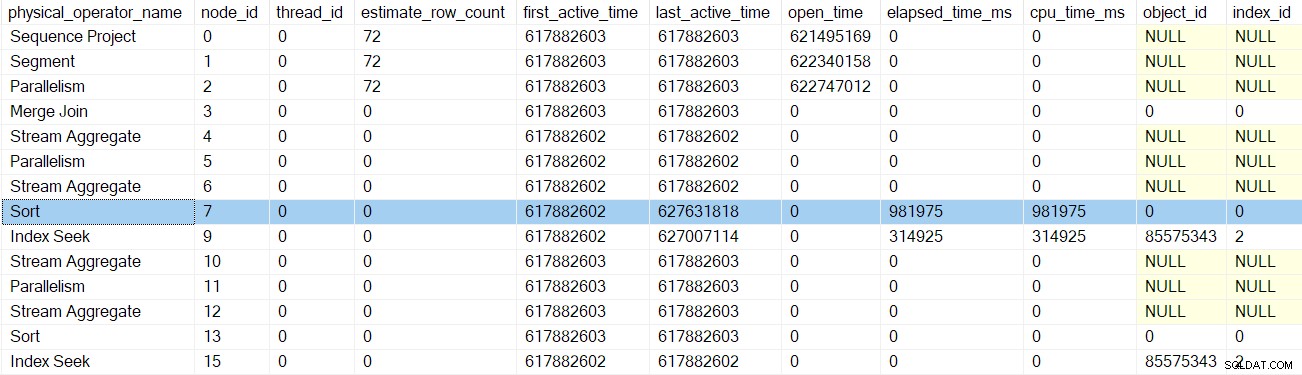
Después de la próxima devolución de llamada de las primeras fases del generador de perfiles, el ordenar los tiempos se actualizan:
El siguiente retorno nos lleva más allá del generador de perfiles para el agregado de flujo en el nodo 6:
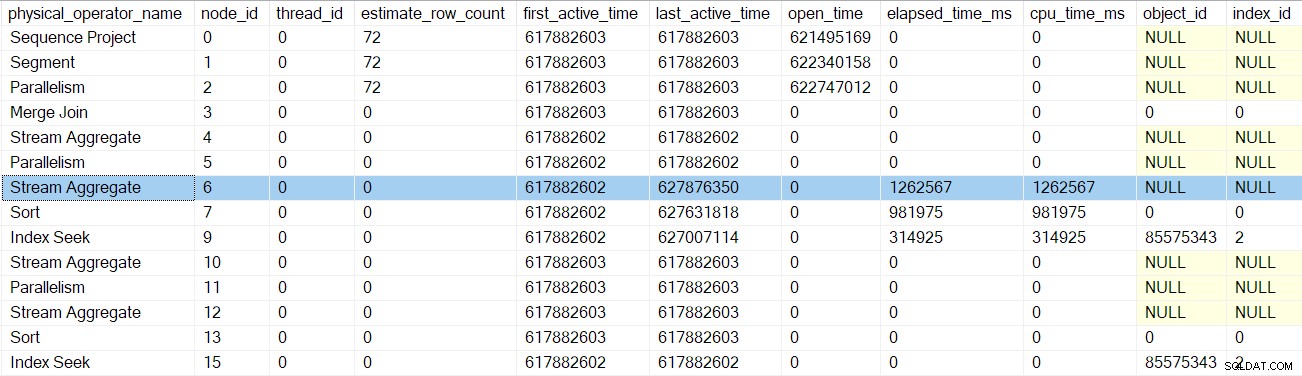
Regresar de este generador de perfiles nos lleva de regreso a las EarlyPhases llamar a las corrientes de partición intercambio en nodo 5 . Recuerde que aquí no es donde comenzó la secuencia de llamadas de las primeras fases; ese fue el intercambio de flujos de recopilación en el nodo 2.
Tareas paralelas de la rama C en cola
Además de actualizar los datos de perfiles, las llamadas de las primeras fases anteriores no parecían hacer mucho. Todo eso cambia con los flujos de partición intercambio en el nodo 5.
Voy a describir la Rama C con bastante detalle para presentar una serie de conceptos importantes, que también se aplicarán a las otras ramas paralelas. Cubrir este terreno una vez ahora significa que la discusión posterior de la rama puede ser más sucinta.
Habiendo completado el procesamiento de fase inicial anidado para su subárbol (hasta la búsqueda de índice en el nodo 9), el intercambio puede comenzar su propio trabajo de fase inicial. Esto comienza igual que apertura el intercambio de flujos de recopilación en el nodo 2:
CXTransLocal::Open(abriendo la subtransacción paralela local).CXPort::Register(registrarse en el puerto de intercambio).
Los siguientes pasos son diferentes porque la rama C contiene un bloqueo completo. iterador (la clasificación en el nodo 7). El procesamiento de fase inicial en los flujos de partición del nodo 5 hace lo siguiente:
- Llamadas
CQScanExchangeNew::StartAllProducers. Esta es la primera vez que encontramos algo que hace referencia al lado del productor. del intercambio Node 5 es el primer intercambio en este plan para crear su lado productor. - Adquiere un mutex por lo que ningún otro subproceso puede poner en cola tareas al mismo tiempo.
- Inicia transacciones anidadas paralelas para las tareas del productor (
CXPort::StartNestedTransactionsyReadOnlyXactImp::BeginParallelNestedXact). - Registra las subtransacciones con el objeto de exploración de consulta principal (
CQueryScan::AddSubXact). - Crea descriptores de productores (
CQScanExchangeNew::PxproddescCreate). - Crea nuevos contextos de ejecución de productor (
CExecContext) derivado del contexto de ejecución cero. - Actualiza el mapa vinculado de los iteradores del plan.
- Establece DOP para el nuevo contexto (
CQueryExecContext::SetDop) para que todas las tareas sepan cuál es la configuración DOP general. - Inicializa la caché de parámetros (
CQueryExecContext::InitParamCache). - Enlaza las transacciones anidadas paralelas a la transacción base (
CExecContext::SetBaseXact). - Pone en cola los nuevos subprocesos para su ejecución (
SubprocessMgr::EnqueueMultipleSubprocesses). - Crea nuevas tareas paralelas tareas a través de
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
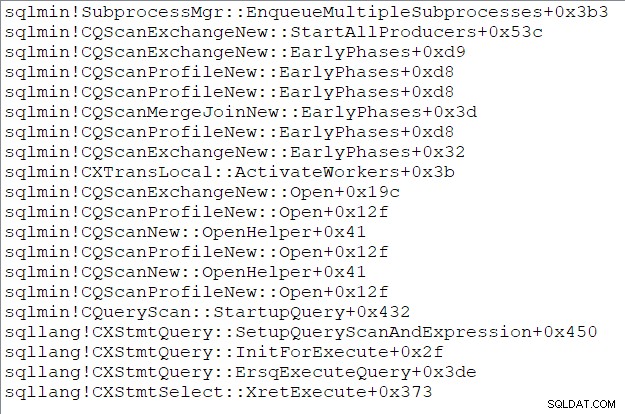
La pila de llamadas de la tarea principal (para aquellos de ustedes que disfrutan de estas cosas) en este momento es:
Fin de la tercera parte
Ahora hemos creado el lado del productor del intercambio de flujos de partición en el nodo 5, creó tareas paralelas adicionales para ejecutar la rama C y vincular todo de nuevo a principal estructuras según se requiera. La sucursal C es la primera rama para iniciar cualquier tarea paralela. La parte final de esta serie analizará la apertura de la sucursal C en detalle y comenzará las tareas paralelas restantes.