Autor invitado:Derik Hammer (@SQLHammer)
Recientemente, Aaron Bertrand escribió en su blog acerca de los mitos dañinos y generalizados sobre el rendimiento de SQL Server. Como extensión de esta serie de blogs, voy a refutar este mito común:
Lectura del manual
Yendo directamente a la fuente, miré el artículo de Books Online sobre tablas que incluye variables de tabla. A pesar de que el artículo hace referencia a los beneficios del uso de variables de tabla, el hecho de que estén 100 % en la memoria es evidentemente faltante.
Sin embargo, una afirmación faltante no implica una negativa. Desde que se lanzaron las tablas OLTP en memoria, ahora hay mucha más documentación en BOL para el procesamiento en memoria. Ahí es donde encontré este artículo sobre cómo hacer que la tabla temporal y las variables de tabla sean más rápidas mediante el uso de la optimización de memoria.
Todo el artículo gira en torno a cómo hacer que sus objetos temporales usen la función OLTP en memoria, y aquí es donde encontré lo afirmativo que estaba buscando.
"Una variable de tabla tradicional representa una tabla en la base de datos tempdb. Para un rendimiento mucho más rápido, puede optimizar la memoria de su variable de tabla".Las variables de tabla no son construcciones en memoria. Para usar la tecnología en memoria, debe definir explícitamente un TIPO que esté optimizado para memoria y usar ese TIPO para definir su variable de tabla.
Pruébalo
La documentación es una cosa, pero verlo con mis propios ojos es otra muy distinta. Sé que las tablas temporales crean objetos en tempdb y escribirán datos en el disco. Primero le mostraré cómo se ven las tablas temporales y luego usaré el mismo método para validar la hipótesis de que las variables de la tabla actúan de la misma manera.
Análisis de registros
Esta consulta ejecutará un PUNTO DE CONTROL para brindarme un punto de partida limpio y luego mostrará la cantidad de registros y los nombres de las transacciones que existen en el registro.
USE tempdb; GO CHECKPOINT; GO SELECT COUNT(*) [Count] FROM sys.fn_dblog (NULL, NULL); SELECT [Transaction Name] FROM sys.fn_dblog (NULL, NULL) WHERE [Transaction Name] IS NOT NULL;
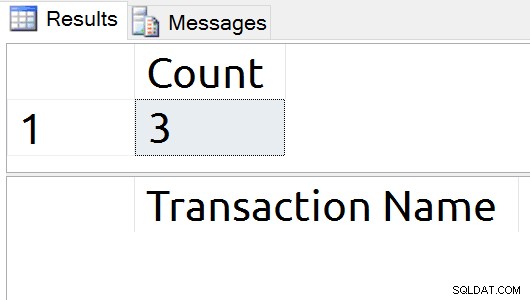
La ejecución repetida de T-SQL resultó en un conteo consistente de tres registros en SQL Server 2016 SP1.
Esto crea una tabla temporal y muestra el registro del objeto, lo que demuestra que se trata de un objeto real en tempdb.
USE tempdb; GO DROP TABLE IF EXISTS #tmp; GO CREATE TABLE #tmp (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;

Ahora volveré a mostrar los registros de registro. No volveré a ejecutar el comando CHECKPOINT.
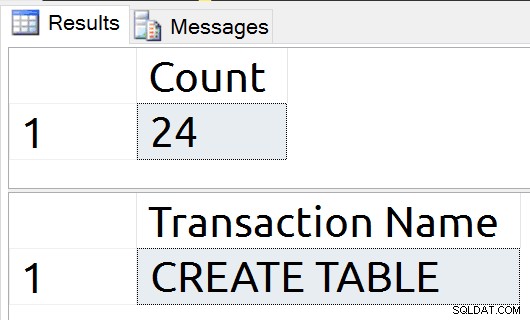
Se escribieron veintiún registros, lo que demuestra que se trata de escrituras en disco, y nuestra CREAR TABLA está claramente incluida en estos registros.
Para comparar estos resultados con las variables de la tabla, reiniciaré el experimento ejecutando CHECKPOINT y luego ejecutando el T-SQL a continuación, creando una variable de tabla.
USE tempdb; GO DECLARE @var TABLE (id int NULL); SELECT name FROM sys.objects o WHERE is_ms_shipped = 0;
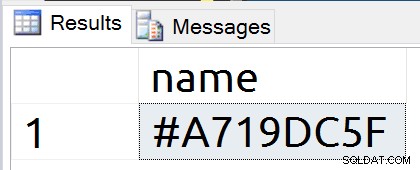
Una vez más tenemos un nuevo registro de objeto. Esta vez, sin embargo, el nombre es más aleatorio que con las tablas temporales.
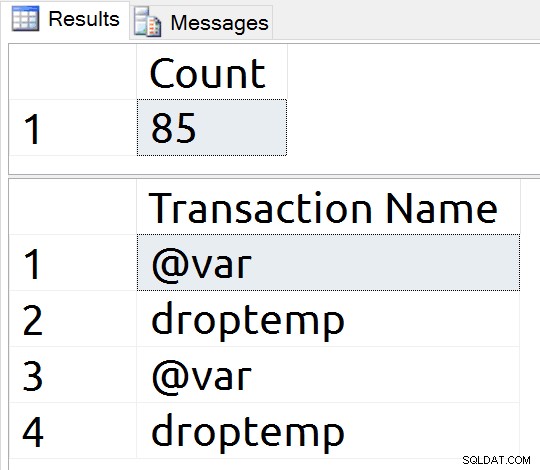
Hay ochenta y dos nuevos registros y nombres de transacciones que prueban que mi variable se está escribiendo en el registro y, por lo tanto, en el disco.
Realmente en memoria
Ahora es el momento de que desaparezcan los registros.
Creé un grupo de archivos OLTP en memoria y luego creé un tipo de tabla optimizada para memoria.
USE Test; GO CREATE TYPE dbo.inMemoryTableType AS TABLE ( id INT NULL INDEX ix1 ) WITH (MEMORY_OPTIMIZED = ON); GO
Ejecuté el CHECKPOINT nuevamente y luego creé la tabla optimizada para memoria.
USE Test; GO DECLARE @var dbo.inMemoryTableType; INSERT INTO @var (id) VALUES (1) SELECT * from @var; GO
Después de revisar el registro, no vi ninguna actividad de registro. De hecho, este método está 100 % en memoria.
Para llevar
Las variables de tabla usan tempdb de forma similar a como las tablas temporales usan tempdb. Las variables de tabla no son construcciones en memoria, pero pueden convertirse en ellas si utiliza tipos de tabla definidos por el usuario optimizados para memoria. A menudo encuentro que las tablas temporales son una opción mucho mejor que las variables de tabla. La razón principal de esto es que las variables de la tabla no tienen estadísticas y, según la versión y la configuración de SQL Server, las estimaciones de fila resultan ser 1 fila o 100 filas. En ambos casos, se trata de conjeturas y se convierten en elementos de desinformación perjudiciales en su proceso de optimización de consultas.
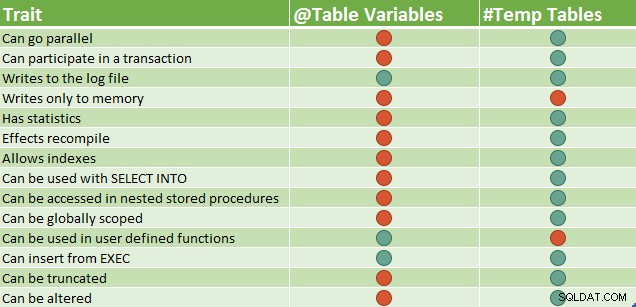
Tenga en cuenta que algunas de estas diferencias de características pueden cambiar con el tiempo; por ejemplo, en versiones recientes de SQL Server, puede crear índices adicionales en una variable de tabla utilizando la sintaxis de índice en línea. La siguiente tabla tiene tres índices; la clave principal (agrupada de forma predeterminada) y dos índices no agrupados:
DECLARE @t TABLE ( a int PRIMARY KEY, b int, INDEX x (b, a DESC), INDEX y (b DESC, a) );
Hay una gran respuesta en DBA Stack Exchange donde Martin Smith detalla exhaustivamente las diferencias entre las variables de tabla y las tablas #temp:
- ¿Cuál es la diferencia entre una tabla temporal y una variable de tabla en SQL Server?
Sobre el autor
 Derik es un profesional de datos y recientemente nombrado MVP de Microsoft Data Platform que se enfoca en SQL Server. Su pasión se centra en la alta disponibilidad, la recuperación ante desastres, la integración continua y el mantenimiento automatizado. Su experiencia ha abarcado la administración de bases de datos a largo plazo, la consultoría y las empresas empresariales que trabajan en las industrias financiera y de atención médica. Actualmente es administrador sénior de bases de datos a cargo del equipo de operaciones de bases de datos en la sede mundial de franquicias de Subway. Cuando no está trabajando o blogueando en SQLHammer.com, Derik dedica su tiempo a la familia #sql como líder del capítulo del grupo de usuarios de FairfieldPASS SQL Server en Stamford, CT.
Derik es un profesional de datos y recientemente nombrado MVP de Microsoft Data Platform que se enfoca en SQL Server. Su pasión se centra en la alta disponibilidad, la recuperación ante desastres, la integración continua y el mantenimiento automatizado. Su experiencia ha abarcado la administración de bases de datos a largo plazo, la consultoría y las empresas empresariales que trabajan en las industrias financiera y de atención médica. Actualmente es administrador sénior de bases de datos a cargo del equipo de operaciones de bases de datos en la sede mundial de franquicias de Subway. Cuando no está trabajando o blogueando en SQLHammer.com, Derik dedica su tiempo a la familia #sql como líder del capítulo del grupo de usuarios de FairfieldPASS SQL Server en Stamford, CT.