Este artículo analiza la estimación de selectividad y cardinalidad para predicados en COUNT(*) expresiones, como puede verse en HAVING cláusulas. Se espera que los detalles sean interesantes en sí mismos. También brindan información sobre algunos de los enfoques y algoritmos generales utilizados por el estimador de cardinalidad.
Un ejemplo simple usando la base de datos de muestra AdventureWorks:
SELECT A.City FROM Person.[Address] AS A GROUP BY A.City HAVING COUNT_BIG(*) = 1;
Estamos interesados en ver cómo SQL Server deriva una estimación para el predicado en la expresión de conteo en HAVING cláusula.
Por supuesto el HAVING la cláusula es solo azúcar de sintaxis. Podríamos igualmente haber escrito la consulta utilizando una tabla derivada o una expresión de tabla común:
-- Derived table
SELECT SQ1.City
FROM
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
) AS SQ1
WHERE SQ1.Expr1001 = 1;
-- CTE
WITH Grouped AS
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
)
SELECT G.City
FROM Grouped AS G
WHERE G.Expr1001 = 1; Los tres formularios de consulta producen el mismo plan de ejecución, con valores hash del plan de consulta idénticos.
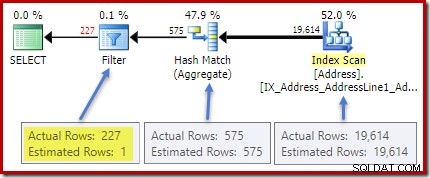
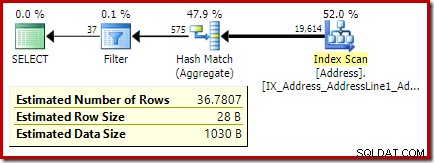
El plan posterior a la ejecución (real) muestra una estimación perfecta para el agregado; sin embargo, la estimación de HAVING filtro de cláusula (o equivalente, en los otros formularios de consulta) es pobre:
Estadísticas sobre la City columna proporciona información precisa sobre el número de valores de ciudades distintas:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH DENSITY_VECTOR;
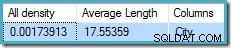
La toda densidad cifra es el recíproco del número de valores únicos. Simplemente calculando (1 / 0.00173913) =575 da la cardinalidad estimada para el agregado. La agrupación por ciudad obviamente produce una fila para cada valor distinto.
Tenga en cuenta que toda la densidad proviene del vector densidad. Tenga cuidado de no usar accidentalmente la densidad valor de la salida del encabezado de estadísticas de DBCC SHOW_STATISTICS . La densidad del encabezado se mantiene solo por compatibilidad con versiones anteriores; el optimizador no lo usa durante la estimación de cardinalidad en estos días.
El problema
El agregado introduce una nueva columna calculada en el flujo de trabajo, denominada Expr1001 en el plan de ejecución. Contiene el valor de COUNT(*) en cada fila de salida agrupada:
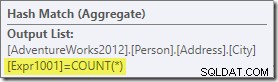
Obviamente, no hay información estadística en la base de datos sobre esta nueva columna calculada. Si bien el optimizador sabe que habrá 575 filas, no sabe nada sobre la distribución de valores de conteo dentro de esas filas.
Bueno, no del todo:el optimizador es consciente de que los valores de conteo serán números enteros positivos (1, 2, 3…). Aún así, es la distribución de estos valores de conteo de enteros entre las 575 filas lo que sería necesario para estimar con precisión la selectividad del COUNT(*) = 1 predicado.
Uno podría pensar que algún tipo de información de distribución podría derivarse del histograma, pero el histograma solo proporciona información de conteo específica (en EQ_ROWS ) para valores de paso de histograma. Entre los pasos del histograma, todo lo que tenemos es un resumen:RANGE_ROWS las filas tienen DISTINCT_RANGE_ROWS valores distintos. Para las tablas que son lo suficientemente grandes como para que nos importe la calidad de la estimación de selectividad, es muy probable que la mayor parte de la tabla esté representada por estos resúmenes entre pasos.
Por ejemplo, las dos primeras filas de City histograma de columna son:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH HISTOGRAM;

Esto nos dice que hay exactamente una fila para "Abingdon" y otras 29 filas después de "Abingdon" pero antes de "Ballard", con 19 valores distintos en ese rango de 29 filas. La siguiente consulta muestra la distribución real de filas entre valores únicos en ese rango intra-paso de 29 filas:
SELECT A.City, NumRows = COUNT_BIG(*) FROM Person.[Address] AS A WHERE A.City > N'Abingdon' AND A.City < N'Ballard' GROUP BY ROLLUP (A.City);

Hay 29 filas con 19 valores distintos, tal como dice el histograma. Aún así, está claro que no tenemos ninguna base para evaluar la selectividad de un predicado en la columna de recuento en esa consulta. Por ejemplo, HAVING COUNT_BIG(*) = 2 devolvería 5 filas (para Alexandria, Altadena, Atlanta, Augsburg y Austin) pero no tenemos forma de determinar eso a partir del histograma.
Una conjetura fundamentada
El enfoque que adopta SQL Server es asumir que cada grupo es lo más probable para contener la media general (promedio) del número de filas. Esto es simplemente la cardinalidad dividida por el número de valores únicos. Por ejemplo, para 1000 filas con 20 valores únicos, SQL Server asumiría que (1000/20) =50 filas por grupo es el valor más probable.
Volviendo a nuestro ejemplo original, esto significa que es "muy probable" que la columna de conteo calculado contenga un valor alrededor de (19614/575) ~=34.1113 . Desde densidad es el recíproco del número de valores únicos, también podemos expresarlo como cardinalidad * densidad =(19614 * 0.00173913), dando un resultado muy similar.
Distribución
Decir que el valor medio es muy probable solo nos lleva hasta cierto punto. También necesitamos establecer exactamente qué tan probable es eso; y cómo cambia la probabilidad a medida que nos alejamos del valor medio. ¡Asumir que todos los grupos tienen exactamente 34.113 filas en nuestro ejemplo no sería una conjetura muy "educada"!
SQL Server maneja esto asumiendo una distribución normal. Esto tiene la forma de campana característica con la que quizás ya esté familiarizado (imagen de la entrada de Wikipedia vinculada):
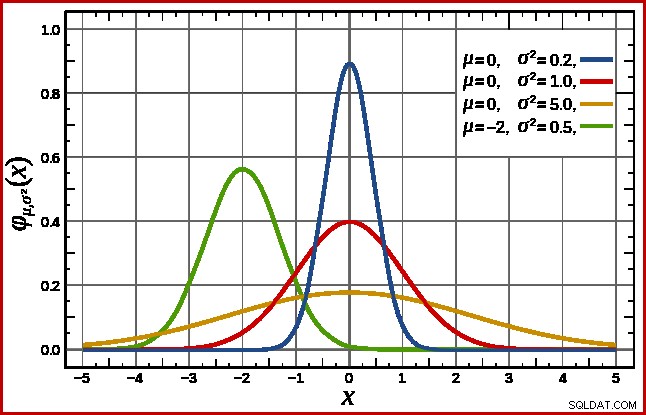
La forma exacta de la distribución normal depende de dos parámetros :la media (µ ) y la desviación estándar (σ ). La media determina la ubicación del pico. La desviación estándar especifica cuán "aplanada" es la curva de campana. Cuanto más plana es la curva, más bajo es el pico y más se distribuye la densidad de probabilidad entre otros valores.
SQL Server puede derivar la media de la información estadística como ya se indicó. La desviación estándar de los valores de columna de conteo calculados es desconocido. SQL Server lo estima como la raíz cuadrada de la media (con un ligero ajuste detallado más adelante). En nuestro ejemplo, esto significa que los dos parámetros de la distribución normal son aproximadamente 34,1113 y 5,84 (la raíz cuadrada).
El estándar La distribución normal (la curva roja en el diagrama de arriba) es un caso especial digno de mención. Esto ocurre cuando la media es cero y la desviación estándar es 1. Cualquier distribución normal se puede transformar en la distribución normal estándar restando la media y dividiendo por la desviación estándar.
Áreas e Intervalos
Estamos interesados en estimar la selectividad, por lo que buscamos la probabilidad de que la columna calculada de conteo tenga un cierto valor (x). Esta probabilidad no viene dada por el valor del eje y anterior, sino por el área bajo la curva a la izquierda de x.
Para la distribución normal con media 34,1113 y desviación estándar 5,84, el área bajo la curva a la izquierda de x =30 es de aproximadamente 0,2406:
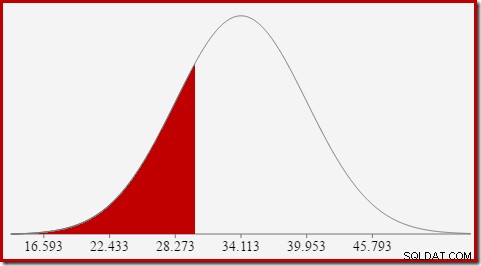
Esto corresponde a la probabilidad de que la columna de conteo calculado sea menor o igual que 30 para nuestra consulta de ejemplo.
Esto lleva muy bien a la idea de que, en general, no buscamos la probabilidad de un valor específico, sino un intervalo . Para encontrar la probabilidad de que la cuenta es igual un valor entero, debemos tener en cuenta el hecho de que los enteros abarcan un intervalo de tamaño 1. La forma en que convertimos un entero en un intervalo es algo arbitraria. SQL Server maneja esto sumando y restando 0.5 para dar los límites inferior y superior del intervalo.
Por ejemplo, para encontrar la probabilidad de que el valor de conteo calculado sea igual a 30, necesitamos restar el área bajo la curva de distribución normal para (x =29,5) del área para (x =30,5). El resultado corresponde al segmento para (29,5
El área de la rebanada roja es aproximadamente 0.0533 . En una buena primera aproximación, esta es la selectividad de un predicado count =30 en nuestra consulta de prueba.
Calcular el área bajo una distribución normal a la izquierda de un valor dado no es sencillo. La fórmula general viene dada por la función de distribución acumulada (CDF). El problema es que la CDF no se puede expresar en términos de funciones matemáticas elementales, por lo que en su lugar se deben utilizar métodos de aproximación numérica.
Dado que todas las distribuciones normales se pueden transformar fácilmente a la distribución normal estándar (media =0, desviación estándar =1), todas las aproximaciones funcionan para estimar la normal estándar. Esto significa que necesitamos transformar nuestros límites de intervalo desde la distribución normal particular apropiada para la consulta, hasta la distribución normal estándar. Esto se hace, como se mencionó anteriormente, restando la media y dividiendo por la desviación estándar.
Si está familiarizado con Excel, es posible que conozca las funciones DISTR.NORM.DIST y DISTR.NORM.ESTÁNDAR que pueden calcular CDF (usando métodos de aproximación numérica) para una distribución normal particular o la distribución normal estándar.
No hay una calculadora CDF integrada en SQL Server, pero podemos crear una fácilmente. Dado que la CDF para la distribución normal estándar es:
…donde erf es la función de error:
A continuación se muestra una implementación de T-SQL para obtener la CDF para la distribución normal estándar. Utiliza una aproximación numérica para la función de error que es muy parecido al que SQL Server usa internamente:
Un ejemplo, para calcular la CDF para x =30 usando la distribución normal para nuestra consulta de prueba:
Tenga en cuenta el paso de normalización para convertir a la distribución normal estándar. El procedimiento devuelve el valor 0,2407196…, que coincide con el resultado de Excel correspondiente con siete decimales.
El siguiente código modifica nuestra consulta de ejemplo para producir una estimación mayor para el filtro (la comparación ahora es con el valor 32, que está mucho más cerca de la media que antes):
La estimación del optimizador ahora es 36,7807 .
Para calcular la estimación manualmente, primero debemos abordar algunos detalles finales:
El siguiente procedimiento incorpora todos los detalles de este artículo. Requiere el procedimiento CDF dado anteriormente:
Ahora podemos usar este procedimiento para generar una estimación para nuestra nueva consulta de prueba:
La salida es:
Esto se compara muy bien con la estimación de cardinalidad del optimizador de 36,7807.
El procedimiento se puede utilizar para otros intervalos de conteo además de las pruebas de igualdad. Todo lo que se requiere es establecer el
Para usar esto con nuestro procedimiento, establecemos
El resultado es 572.5964:
Un último ejemplo usando
La estimación del optimizador es
Desde
Nuevamente, esto concuerda con la estimación del optimizador.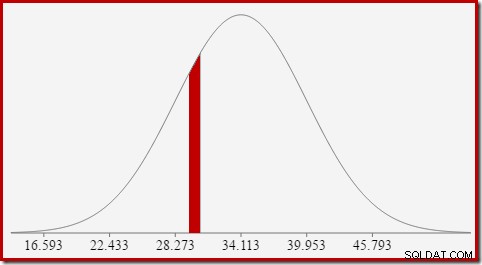
La función de distribución acumulativa
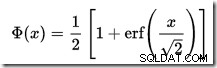
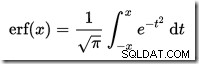
CREATE PROCEDURE dbo.GetStandardNormalCDF
(
@x float,
@cdf float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE
@sign float,
@erf float;
SET @sign = SIGN(@x);
SET @x = ABS(@x) / SQRT(2);
SET @erf = 1;
SET @erf = @erf + (0.0705230784 * @x);
SET @erf = @erf + (0.0422820123 * POWER(@x, 2));
SET @erf = @erf + (0.0092705272 * POWER(@x, 3));
SET @erf = @erf + (0.0001520143 * POWER(@x, 4));
SET @erf = @erf + (0.0002765672 * POWER(@x, 5));
SET @erf = @erf + (0.0000430638 * POWER(@x, 6));
SET @erf = POWER(@erf, -16);
SET @erf = 1 - @erf;
SET @erf = @erf * @sign;
SET @cdf = 0.5 * (1 + @erf);
END; DECLARE @cdf float;
DECLARE @x float;
-- HAVING COUNT_BIG(*) = x
SET @x = 30;
-- Normalize 30 by subtracting the mean
-- and dividing by the standard deviation
SET @x = (@x - 34.1113) / 5.84;
EXECUTE dbo.GetStandardNormalCDF
@x = @x,
@cdf = @cdf OUTPUT;
SELECT CDF = @cdf; Detalles finales y ejemplos
SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) = 32;
COUNT(*) = 1 , que no se detalla aquí. COUNT(*) = 1 caso, el CE heredado usa la misma lógica que el nuevo CE (disponible en SQL Server 2014 en adelante).CREATE PROCEDURE dbo.GetCountPredicateEstimate
(
@From integer,
@To integer,
@Cardinality float,
@Density float,
@Selectivity float OUTPUT,
@Estimate float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
DECLARE
@Start float,
@End float,
@Distinct float,
@Mean float,
@MeanAdj float,
@Stdev float,
@NormStart float,
@NormEnd float,
@CDFStart float,
@CDFEnd float;
-- Validate input and apply defaults
IF ISNULL(@From, 0) = 0 SET @From = 1;
IF @From < 1 RAISERROR ('@From must be >= 1', 16, 1);
IF ISNULL(@Cardinality, -1) <= 0 RAISERROR('@Cardinality must be positive', 16, 1);
IF ISNULL(@Density, -1) <= 0 RAISERROR('@Density must be positive', 16, 1);
IF ISNULL(@To, 0) = 0 SET @To = CEILING(1 / @Density);
IF @To < @From RAISERROR('@To must be >= @From', 16, 1);
-- Convert integer range to interval
SET @Start = @From - 0.5;
SET @End = @To + 0.5;
-- Get number of distinct values
SET @Distinct = 1 / @Density;
-- Calculate mean
SET @Mean = @Cardinality * @Density;
-- Adjust mean;
SET @MeanAdj = @Mean * ((@Distinct - 1) / @Distinct);
-- Get standard deviation (guess)
SET @Stdev = SQRT(@MeanAdj);
-- Normalize interval
SET @NormStart = (@Start - @Mean) / @Stdev;
SET @NormEnd = (@End - @Mean) / @Stdev;
-- Calculate CDFs
EXECUTE dbo.GetStandardNormalCDF
@x = @NormStart,
@cdf = @CDFStart OUTPUT;
EXECUTE dbo.GetStandardNormalCDF
@x = @NormEnd,
@cdf = @CDFEnd OUTPUT;
-- Selectivity
SET @Selectivity =
CASE
-- Unbounded start
WHEN @From = 1 THEN @CDFEnd
-- Unbounded end
WHEN @To >= @Distinct THEN 1 - @CDFStart
-- Normal interval
ELSE @CDFEnd - @CDFStart
END;
-- Return row estimate
SET @Estimate = @Selectivity * @Distinct;
END TRY
BEGIN CATCH
DECLARE @EM nvarchar(4000) = ERROR_MESSAGE();
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION;
RAISERROR (@EM, 16, 1);
RETURN;
END CATCH;
END; DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = 32,
@To = 32,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
Ejemplos de intervalos de desigualdad
@From y @To parámetros a los límites del intervalo entero. Para especificar ilimitado, pase cero o NULL como prefieras.SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) < 50;

@From = NULL y @To = 49 (porque 50 está excluido por menos de):DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = NULL,
@To = 49,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
BETWEEN :SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) BETWEEN 25 AND 30;

BETWEEN es inclusivo, pasamos el procedimiento @From = 25 y @To = 30 . El resultado es:



