PostgreSQL es un proyecto impresionante y evoluciona a un ritmo asombroso. Nos centraremos en la evolución de las capacidades de tolerancia a fallas en PostgreSQL a lo largo de sus versiones con una serie de publicaciones de blog. Esta es la segunda publicación de la serie y hablaremos sobre la replicación y su importancia en la tolerancia a fallas y la confiabilidad de PostgreSQL.
Si desea presenciar el progreso de la evolución desde el principio, consulte la primera publicación de blog de la serie:Evolución de la tolerancia a fallas en PostgreSQL
Replicación de PostgreSQL
Replicación de bases de datos es el término que usamos para describir la tecnología utilizada para mantener una copia de un conjunto de datos en un control remoto sistema. Mantener una copia confiable de un sistema en ejecución es una de las mayores preocupaciones de la redundancia y a todos nos gustan las copias estables, fáciles de usar y mantenibles de nuestros datos.
Veamos la arquitectura básica. Por lo general, los servidores de bases de datos individuales se denominan nodos. . El grupo completo de servidores de bases de datos involucrados en la replicación se conoce como clúster. . Un servidor de base de datos que permite a un usuario realizar cambios se conoce como maestro o principal , o puede describirse como una fuente de cambios. Un servidor de base de datos que solo permite el acceso de solo lectura se conoce como Hot Standby . (El término Hot Standby se explica detalladamente en el título Modos de espera. )
El aspecto clave de la replicación es que los cambios de datos se capturan en un maestro y luego se transfieren a otros nodos. En algunos casos, un nodo puede enviar cambios de datos a otros nodos, lo cual es un proceso conocido como cascada. o retransmisión . Por lo tanto, el maestro es un nodo de envío, pero no todos los nodos de envío necesitan ser maestros. La replicación a menudo se clasifica en función de si se permite más de un nodo maestro, en cuyo caso se denominará replicación multimaestro. .
Veamos cómo PostgreSQL maneja la replicación a lo largo del tiempo y cuál es el estado del arte para la tolerancia a fallas según los términos de la replicación.
Historial de replicación de PostgreSQL
Históricamente (alrededor del año 2000-2005), Postgres solo se concentró en la tolerancia/recuperación de fallas de un solo nodo, que se logra principalmente mediante el registro de transacciones WAL. La tolerancia a fallas es manejada parcialmente por MVCC (sistema de concurrencia de múltiples versiones), pero es principalmente una optimización.
El registro de escritura anticipada fue y sigue siendo el mayor método de tolerancia a fallas en PostgreSQL. Básicamente, solo tiene archivos WAL donde escribe todo y puede recuperarse en términos de falla al reproducirlos. Esto fue suficiente para las arquitecturas de un solo nodo y la replicación se considera la mejor solución para lograr la tolerancia a fallas con múltiples nodos.
La comunidad de Postgres solía creer durante mucho tiempo que la replicación es algo que Postgres no debería proporcionar y debería ser manejado por herramientas externas, es por eso que surgieron herramientas como Slony y Londiste. (Cubriremos las soluciones de replicación basadas en disparadores en las próximas publicaciones de blog de la serie).
Eventualmente quedó claro que la tolerancia de un servidor no es suficiente y más personas exigieron una tolerancia a fallas adecuada del hardware y una forma adecuada de conmutación, algo incorporado en Postgres. Fue entonces cuando la replicación física (luego transmisión física) cobró vida.
Revisaremos todos los métodos de replicación más adelante en la publicación, pero veamos los eventos cronológicos del historial de replicación de PostgreSQL por versiones principales:
- PostgreSQL 7.x (~2000)
- La replicación no debe ser parte del núcleo de Postgres
- Londiste – Slony (replicación lógica basada en disparadores)
- PostgreSQL 8.0 (2005)
- Recuperación de un punto en el tiempo (WAL)
- PostgreSQL 9.0 (2010)
- Replicación de transmisión (física)
- PostgreSQL 9.4 (2014)
- Descodificación lógica (extracción de conjuntos de cambios)
Replicación física
PostgreSQL resolvió la necesidad central de replicación con lo que hacen la mayoría de las bases de datos relacionales; tomó el WAL e hizo posible enviarlo a través de la red. Luego, estos archivos WAL se aplican en una instancia de Postgres separada que se ejecuta en modo de solo lectura.
La instancia en espera de solo lectura solo aplica los cambios (mediante WAL) y las únicas operaciones de escritura vienen de nuevo del mismo registro WAL. Así es básicamente cómo replicación de transmisión funciona el mecanismo. Al principio, la replicación originalmente enviaba todos los archivos -envío de registros- , pero luego evolucionó a la transmisión.
En el envío de registros, enviábamos archivos completos a través del archive_command . La lógica es bastante simple allí:simplemente envía el archivo y log a algún lugar, como todo el archivo WAL de 16 MB, y luego solicitar a algún lugar, y luego buscar el siguiente y aplicar ese y va así. Más tarde, se transmitió a través de la red mediante el uso del protocolo libpq en la versión 9.0 de PostgreSQL.
La replicación existente se conoce más correctamente como Replicación de transmisión física. ya que estamos transmitiendo una serie de cambios físicos de un nodo a otro. Eso significa que cuando insertamos una fila en una tabla generamos cambiar registros para el inserto más todas las entradas de índice .
Cuando VACUUM una tabla también generamos registros de cambios.
Además, la replicación de transmisión física registra todos los cambios a nivel de byte/bloque. , por lo que es muy difícil hacer algo más que reproducir todo
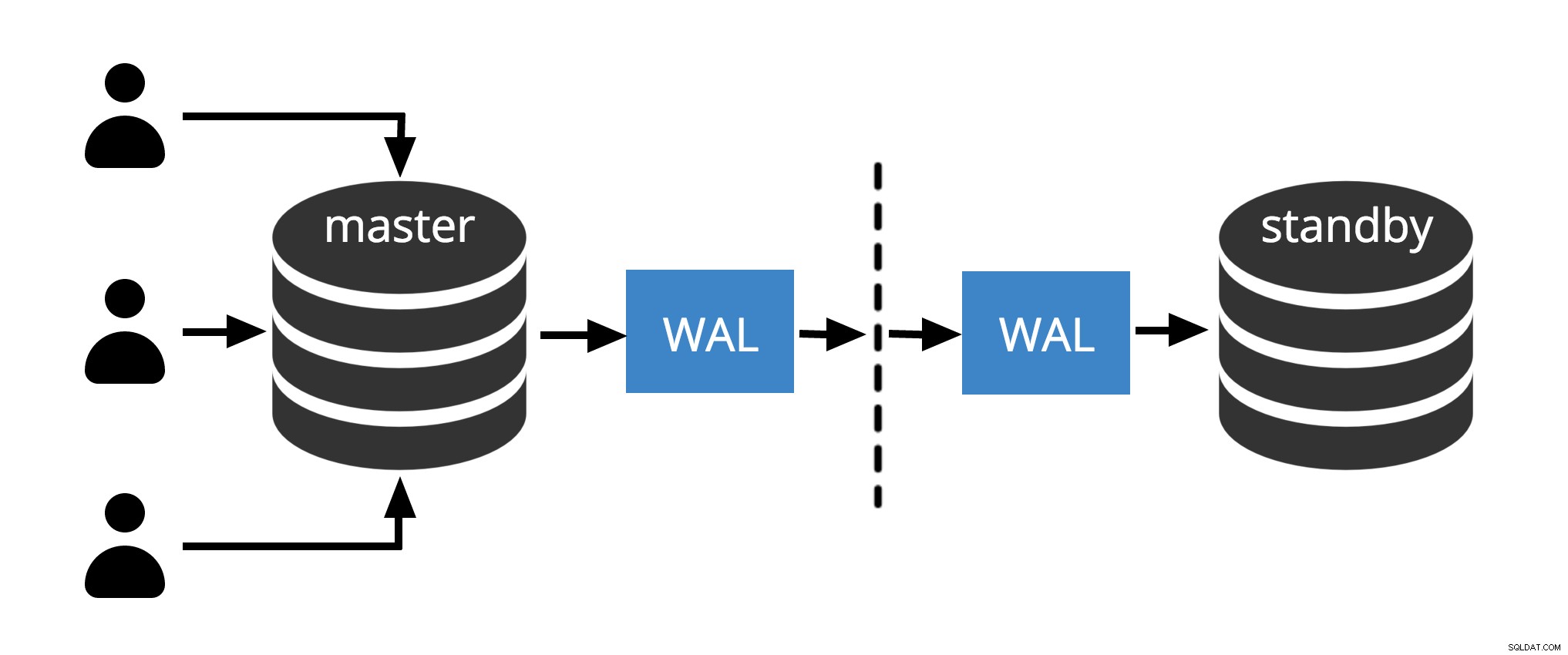
Fig.1 Replicación física
La figura 1 muestra cómo funciona la replicación física con solo dos nodos. El cliente ejecuta consultas en el nodo maestro, los cambios se escriben en un registro de transacciones (WAL) y se copian a través de la red a WAL en el nodo en espera. El proceso de recuperación en el nodo en espera luego lee los cambios de WAL y los aplica a los archivos de datos al igual que durante la recuperación de fallas. Si el modo de espera está en modo de espera activo modo, los clientes pueden emitir consultas de solo lectura en el nodo mientras esto sucede.
Modos de espera
Múltiples nodos proporcionan alta disponibilidad. Por esa razón, las arquitecturas modernas suelen tener nodos de reserva. Hay diferentes modos para los nodos de espera (espera cálida y caliente). La siguiente lista explica las diferencias básicas entre los diferentes modos de espera y también muestra el caso de la arquitectura multimaestro.
Modo de espera cálido
Se puede activar inmediatamente, pero no puede realizar un trabajo útil hasta que se active. Si alimentamos continuamente la serie de archivos WAL a otra máquina que se ha cargado con el mismo archivo de copia de seguridad base, tenemos un sistema de espera en caliente:en cualquier momento podemos abrir la segunda máquina y tendrá una copia casi actual de la base de datos. Warm standby no permite consultas de solo lectura, la figura 2 simplemente representa este hecho.
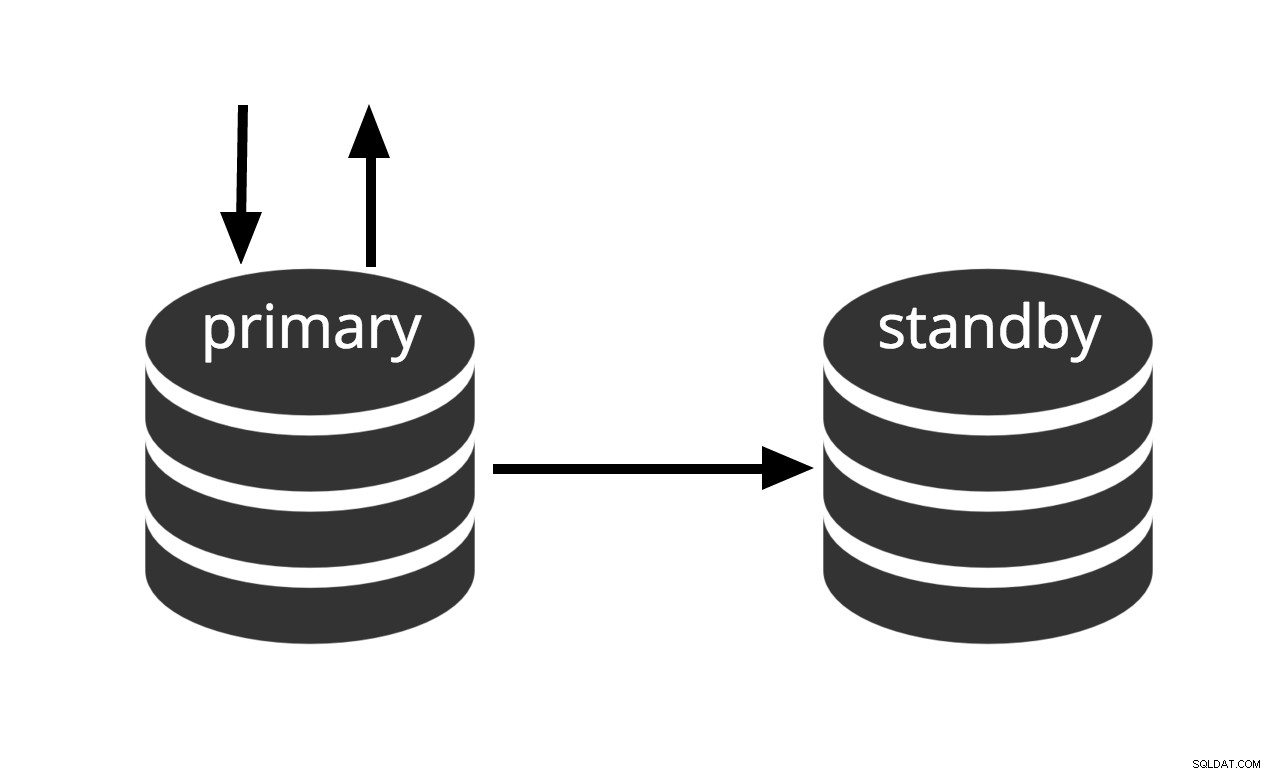
Fig.2 Espera en caliente
El rendimiento de recuperación de un modo de espera tibio es lo suficientemente bueno como para que el modo de espera normalmente esté a solo unos minutos de la disponibilidad total una vez que se haya activado. Como resultado, esto se denomina configuración de espera en caliente que ofrece alta disponibilidad.
Modo de espera en caliente
Hot standby es el término que se usa para describir la capacidad de conectarse al servidor y ejecutar consultas de solo lectura mientras el servidor está en recuperación de archivos o en modo de espera. Esto es útil tanto para fines de replicación como para restaurar una copia de seguridad al estado deseado con gran precisión.
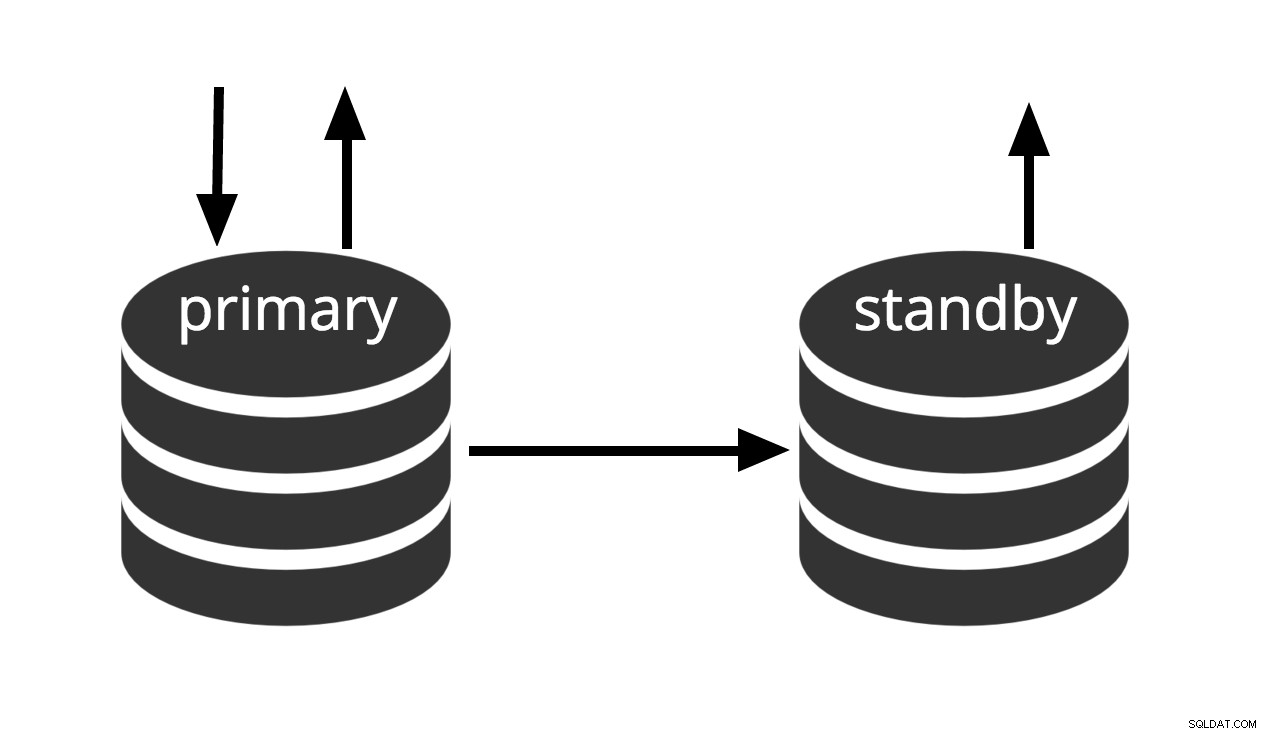 Fig.3 Hot Standby
Fig.3 Hot Standby
El término espera en caliente también se refiere a la capacidad del servidor para pasar de la recuperación al funcionamiento normal mientras los usuarios continúan ejecutando consultas y/o mantienen sus conexiones abiertas. La figura 3 muestra que el modo de espera permite consultas de solo lectura.
Multimaestro
Todos los nodos pueden realizar trabajos de lectura/escritura. (Cubriremos las arquitecturas multimaestro en las próximas publicaciones de blog de la serie).
Parámetro de nivel WAL
Existe una relación entre configurar wal_level parámetro en el archivo postgresql.conf y para qué es adecuada esta configuración. Creé una tabla para mostrar la relación de PostgreSQL versión 9.6.

Failover y Switchover
En la replicación de maestro único, si el maestro muere, uno de los recursos de reserva debe ocupar su lugar (promoción ). De lo contrario, no podremos aceptar nuevas transacciones de escritura. Por lo tanto, las designaciones de término, maestro y en espera, son solo roles que cualquier nodo puede asumir en algún momento. Para mover el rol maestro a otro nodo, realizamos un procedimiento llamado Switchover .
Si el maestro muere y no se recupera, el cambio de función más grave se conoce como failover. . En muchos sentidos, estos pueden ser similares, pero es útil usar términos diferentes para cada evento. (Conocer los términos de conmutación por error y conmutación nos ayudará a comprender los problemas de la línea de tiempo en la próxima publicación del blog).
Conclusión
En esta publicación de blog, discutimos la replicación de PostgreSQL y su importancia para proporcionar confiabilidad y tolerancia a fallas. Cubrimos la replicación de transmisión física y hablamos sobre los modos de espera para PostgreSQL. Mencionamos Failover y Switchover. Continuaremos con los cronogramas de PostgreSQL en la próxima publicación del blog.
Referencias
Documentación de PostgreSQL
Replicación lógica en PostgreSQL 5432... Presentación de MeetUs por Petr Jelinek
Recetario de administración de PostgreSQL 9:segunda edición