SQL Server 2014 trajo muchas características nuevas que los administradores de bases de datos y los desarrolladores esperaban probar y usar en sus entornos, como el índice de almacén de columnas agrupado actualizable, la durabilidad retrasada y las extensiones de grupos de búfer. Una característica que no se discute a menudo son las estadísticas incrementales. A menos que utilice la partición, esta no es una función que pueda implementar. Pero si tiene tablas particionadas en su base de datos, las estadísticas incrementales podrían haber sido algo que esperaba con ansias.
Nota:Benjamin Nevarez cubrió algunos conceptos básicos relacionados con las estadísticas incrementales en su publicación de febrero de 2014, Estadísticas incrementales de SQL Server 2014. Y aunque no ha cambiado mucho el funcionamiento de esta característica desde su publicación y el lanzamiento de abril de 2014, parecía un buen momento para profundizar en cómo habilitar estadísticas incrementales puede ayudar con el rendimiento del mantenimiento.
Las estadísticas incrementales a veces se denominan estadísticas a nivel de partición y esto se debe a que, por primera vez, SQL Server puede crear automáticamente estadísticas que son específicas de una partición. Uno de los desafíos anteriores con la partición fue que, aunque podría tener 1 a n particiones para una tabla, solo había una (1) estadística que representaba la distribución de datos en todas esas particiones. Puede crear estadísticas filtradas para la tabla particionada (una estadística para cada partición) para proporcionar al optimizador de consultas mejor información sobre la distribución de datos. Pero este fue un proceso manual y requirió un script para crearlos automáticamente para cada nueva partición.
En SQL Server 2014, usa el STATISTICS_INCREMENTAL opción para que SQL Server cree esas estadísticas de nivel de partición automáticamente. Sin embargo, estas estadísticas no se utilizan como se podría pensar.
Anteriormente mencioné que, antes de 2014, podía crear estadísticas filtradas para brindar al optimizador mejor información sobre las particiones. ¿Esas estadísticas incrementales? Actualmente no son utilizados por el optimizador. El optimizador de consultas solo usa el histograma principal que representa la tabla completa. (¡Publicaciones por venir que demostrarán esto!)
Entonces, ¿cuál es el punto de las estadísticas incrementales? Si supone que solo cambian los datos de la partición más reciente, lo ideal es que solo actualice las estadísticas de esa partición. Puede hacer esto ahora con estadísticas incrementales, y lo que sucede es que la información se fusiona nuevamente en el histograma principal. El histograma de toda la tabla se actualizará sin tener que leer toda la tabla para actualizar las estadísticas, y esto puede ayudar con el desempeño de sus tareas de mantenimiento.
Configuración
Comenzaremos con la creación de una función y un esquema de partición, y luego una nueva tabla que dividiremos. Tenga en cuenta que creé un grupo de archivos para cada función de partición como lo haría en un entorno de producción. Puede crear el esquema de partición en el mismo grupo de archivos (por ejemplo, PRIMARY ) si no puede eliminar fácilmente su base de datos de prueba. Cada grupo de archivos también tiene un tamaño de unos pocos GB, ya que vamos a agregar casi 400 millones de filas.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Antes de agregar los datos, crearemos el índice agrupado y notaremos que la sintaxis incluye WITH (STATISTICS_INCREMENTAL = ON) opción:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Lo que es interesante notar aquí es que si miras la ALTER TABLE entrada en MSDN, no incluye esta opción. Solo lo encontrarás en el ALTER INDEX entrada... pero esto funciona. Si desea seguir la documentación al pie de la letra, ejecutaría:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Una vez que se haya creado el índice agrupado para el esquema de partición, cargaremos nuestros datos y luego verificaremos cuántas filas existen por partición (tenga en cuenta que esto toma más de 7 minutos en mi computadora portátil, es posible que desee agregar menos filas según la cantidad de almacenamiento (y tiempo) que tenga disponible):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
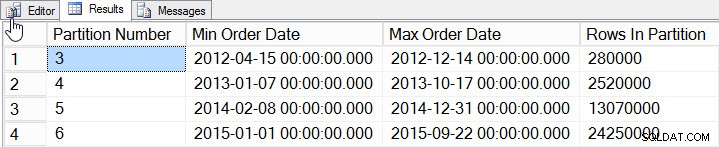 Datos por partición
Datos por partición
Agregamos datos de 2012 a 2015, con muchos más datos en 2014 y 2015. Veamos cómo se ven nuestras estadísticas:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
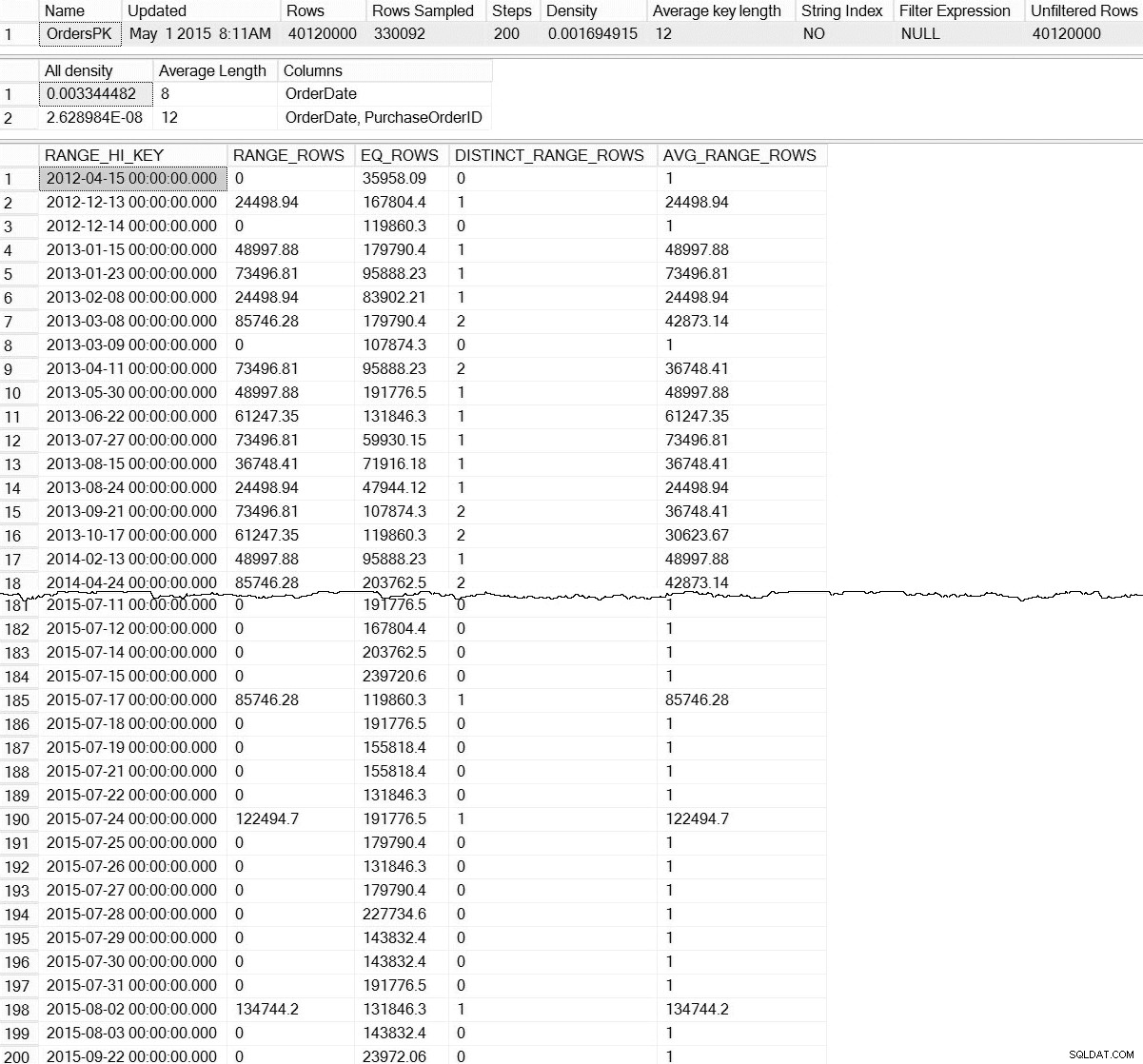 Salida DBCC SHOW_STATISTICS para dbo.Orders (haga clic para agrandar)
Salida DBCC SHOW_STATISTICS para dbo.Orders (haga clic para agrandar)
Con el DBCC SHOW_STATISTICS predeterminado comando, no tenemos ninguna información sobre estadísticas a nivel de partición. No temáis; no estamos completamente condenados:hay una función de administración dinámica no documentada, sys.dm_db_stats_properties_internal . Recuerde que no documentado significa que no es compatible (no hay una entrada de MSDN para el DMF) y que puede cambiar en cualquier momento sin previo aviso de Microsoft. Dicho esto, es un buen comienzo para tener una idea de lo que existe para nuestras estadísticas incrementales:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Información de histograma de dm_db_stats_properties_internal (haga clic para ampliar)
Información de histograma de dm_db_stats_properties_internal (haga clic para ampliar)
Esto es mucho más interesante. Aquí podemos ver pruebas de que existen estadísticas a nivel de partición (y más). Debido a que este DMF no está documentado, tenemos que hacer alguna interpretación. Por hoy, nos centraremos en las primeras siete filas de la salida, donde la primera fila representa el histograma de toda la tabla (tenga en cuenta las rows valor de 40 millones), y las filas subsiguientes representan los histogramas para cada partición. Desafortunadamente, el partition_number el valor en este histograma no se alinea con el número de partición de sys.dm_db_index_physical_stats para la partición basada en la derecha (se correlaciona correctamente para la partición basada en la izquierda). También tenga en cuenta que esta salida también incluye el last_updated y modification_counter columnas, que son útiles para solucionar problemas y se pueden usar para desarrollar secuencias de comandos de mantenimiento que actualizan de manera inteligente las estadísticas en función de la antigüedad o las modificaciones de filas.
Minimizar el mantenimiento necesario
El valor principal de las estadísticas incrementales en este momento es la capacidad de actualizar las estadísticas de una partición y combinarlas en el histograma de nivel de tabla, sin tener que actualizar la estadística de toda la tabla (y, por lo tanto, leer toda la tabla). Para ver esto en acción, primero actualicemos las estadísticas de la partición que contiene los datos de 2015, la partición 5, y registraremos el tiempo necesario y tomaremos una instantánea de sys.dm_io_virtual_file_stats DMF antes y después para ver cuántas E/S ocurren:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Salida:
Tiempos de ejecución de SQL Server:Tiempo de CPU =203 ms, tiempo transcurrido =240 ms.
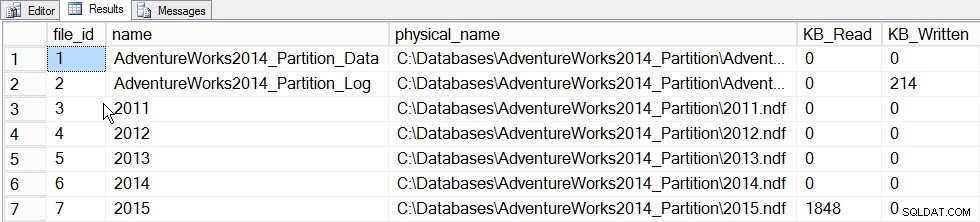 Datos de File_stats después de actualizar una partición
Datos de File_stats después de actualizar una partición
Si miramos el sys.dm_db_stats_properties_internal salida, vemos que last_updated cambiado tanto para el histograma de 2015 como para el histograma de nivel de tabla (así como para algunos otros nodos, que quedan para una investigación posterior):
 Información de histograma actualizada de dm_db_stats_properties_internal
Información de histograma actualizada de dm_db_stats_properties_internal
Ahora actualizaremos las estadísticas con un FULLSCAN para la tabla, y tomaremos una instantánea de file_stats antes y después de nuevo:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Salida:
Tiempos de ejecución de SQL Server:Tiempo de CPU =12720 ms, tiempo transcurrido =13646 ms
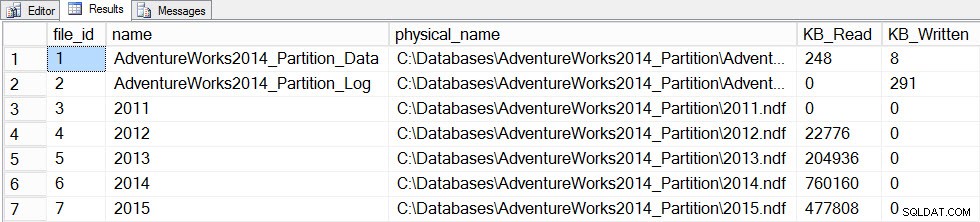 Datos de Filestats después de actualizar con un escaneo completo
Datos de Filestats después de actualizar con un escaneo completo
La actualización tardó mucho más (13 segundos frente a un par de cientos de milisegundos) y generó muchas más operaciones de E/S. Si marcamos sys.dm_db_stats_properties_internal de nuevo, encontramos que last_updated cambiado para todos los histogramas:
 Información de histograma de dm_db_stats_properties_internal después de un escaneo completo
Información de histograma de dm_db_stats_properties_internal después de un escaneo completo
Resumen
Si bien el optimizador de consultas aún no usa las estadísticas incrementales para proporcionar información sobre cada partición, sí brindan un beneficio de rendimiento al administrar estadísticas para tablas particionadas. Si las estadísticas solo necesitan actualizarse para particiones seleccionadas, solo esas pueden actualizarse. Luego, la nueva información se fusiona con el histograma a nivel de tabla, lo que proporciona al optimizador información más actualizada, sin el costo de leer toda la tabla. En el futuro, esperamos que esas estadísticas a nivel de partición se ser utilizado por el optimizador. Estén atentos...