Esta es la tercera parte de una serie sobre soluciones al desafío del generador de series numéricas. En la Parte 1 cubrí soluciones que generan las filas sobre la marcha. En la Parte 2, cubrí soluciones que consultan una tabla base física que se rellena previamente con filas. Este mes me voy a centrar en una técnica fascinante que se puede utilizar para manejar nuestro desafío, pero que también tiene aplicaciones interesantes mucho más allá. No conozco un nombre oficial para la técnica, pero es algo similar en concepto a la eliminación de partición horizontal, por lo que me referiré a ella de manera informal como eliminación de unidades horizontales técnica. La técnica puede tener beneficios de rendimiento positivos interesantes, pero también hay advertencias que debe tener en cuenta, donde bajo ciertas condiciones puede incurrir en una penalización de rendimiento.
Gracias nuevamente a Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea y Paul White por compartir sus ideas y comentarios.
Haré mis pruebas en tempdb, habilitando las estadísticas de tiempo:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Ideas anteriores
La técnica de eliminación de unidades horizontales se puede utilizar como alternativa a la lógica de eliminación de columnas, o eliminación de unidades verticales técnica, en la que me basé en varias de las soluciones que cubrí anteriormente. Puede leer sobre los fundamentos de la lógica de eliminación de columnas con expresiones de tabla en Fundamentos de las expresiones de tabla, Parte 3:Tablas derivadas, consideraciones de optimización en "Proyección de columna y una palabra sobre SELECCIONAR *".
La idea básica de la técnica de eliminación de unidades verticales es que si tiene una expresión de tabla anidada que devuelve las columnas x e y, y su consulta externa solo hace referencia a la columna x, el proceso de compilación de la consulta elimina y del árbol de consulta inicial y, por lo tanto, el plan no necesita evaluarlo. Esto tiene varias implicaciones positivas relacionadas con la optimización, como lograr la cobertura del índice solo con x, y si y es el resultado de un cálculo, no es necesario evaluar la expresión subyacente de y en absoluto. Esta idea estaba en el corazón de la solución de Alan Burstein. También me basé en él en varias de las otras soluciones que cubrí, como con la función dbo.GetNumsAlanCharlieItzikBatch (de la Parte 1), las funciones dbo.GetNumsJohn2DaveObbishAlanCharlieItzik y dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 (de la Parte 2) y otras. Como ejemplo, usaré dbo.GetNumsAlanCharlieItzikBatch como solución de referencia con la lógica de eliminación vertical.
Como recordatorio, esta solución usa una unión con una tabla ficticia que tiene un índice de almacén de columnas para obtener el procesamiento por lotes. Aquí está el código para crear la tabla ficticia:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Y aquí está el código con la definición de la función dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Usé el siguiente código para probar el rendimiento de la función con 100 millones de filas, devolviendo la columna de resultado calculada n (manipulación del resultado de la función ROW_NUMBER), ordenada por n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Aquí están las estadísticas de tiempo que obtuve para esta prueba:
Tiempo de CPU =9328 ms, tiempo transcurrido =9330 ms.Usé el siguiente código para probar el rendimiento de la función con 100 millones de filas, devolviendo la columna rn (resultado directo, no manipulado de la función ROW_NUMBER), ordenada por rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Aquí están las estadísticas de tiempo que obtuve para esta prueba:
Tiempo de CPU =7296 ms, tiempo transcurrido =7291 ms.Revisemos las ideas importantes que están integradas en esta solución.
Basándose en la lógica de eliminación de columnas, a Alan se le ocurrió la idea de devolver no solo una columna con la serie de números, sino tres:
- Columna rn representa un resultado no manipulado de la función ROW_NUMBER, que comienza con 1. Es económico de calcular. Es la preservación del orden tanto cuando proporciona constantes como cuando proporciona no constantes (variables, columnas) como entradas a la función. Esto significa que cuando su consulta externa usa ORDER BY rn, no obtiene un operador Ordenar en el plan.
- Columna n representa un cálculo basado en @low, una constante y rownum (resultado de la función ROW_NUMBER). Se preserva el orden con respecto a rownum cuando proporciona constantes como entradas a la función. Eso es gracias a la idea de Charlie sobre el plegado constante (ver la Parte 1 para más detalles). Sin embargo, no se preserva el orden cuando proporciona no constantes como entradas, ya que no obtiene plegamiento constante. Demostraré esto más adelante en la sección sobre advertencias.
- Columna op representa n en orden opuesto. Es el resultado de un cálculo y no preserva el orden.
Confiando en la lógica de eliminación de columnas, si necesita devolver una serie de números que comienza con 1, consulta la columna rn, que es más económica que consultar n. Si necesita una serie de números que comience con un valor distinto de 1, consulte n y pague el costo adicional. Si necesita el resultado ordenado por la columna de números, con constantes como entradas, puede usar ORDER BY rn u ORDER BY n. Pero con no constantes como entradas, debe asegurarse de usar ORDER BY rn. Puede ser una buena idea ceñirse siempre al uso de ORDER BY rn cuando necesite que el resultado esté ordenado para estar seguro.
La idea de eliminación de unidades horizontales es similar a la idea de eliminación de unidades verticales, solo que se aplica a conjuntos de filas en lugar de conjuntos de columnas. De hecho, Joe Obbish se basó en esta idea en su función dbo.GetNumsObbish (de la Parte 2), y lo llevaremos un paso más allá. En su solución, Joe unificó múltiples consultas que representan subintervalos de números separados, utilizando un filtro en la cláusula WHERE de cada consulta para definir la aplicabilidad del subintervalo. Cuando llama a la función y pasa entradas constantes que representan los delimitadores de su rango deseado, SQL Server elimina las consultas inaplicables en tiempo de compilación, por lo que el plan ni siquiera las refleja.
Eliminación de unidades horizontales, tiempo de compilación versus tiempo de ejecución
Quizás sería una buena idea comenzar demostrando el concepto de eliminación de unidades horizontales en un caso más general, y también discutir una distinción importante entre la eliminación en tiempo de compilación y en tiempo de ejecución. Luego podemos discutir cómo aplicar la idea a nuestro desafío de series de números.
Usaré tres tablas llamadas dbo.T1, dbo.T2 y dbo.T3 en mi ejemplo. Utilice el siguiente código DDL y DML para crear y completar estas tablas:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Suponga que desea implementar un TVF en línea llamado dbo.OneTable que acepta uno de los tres nombres de tabla anteriores como entrada y devuelve los datos de la tabla solicitada. Basado en el concepto de eliminación de unidades horizontales, podría implementar la función así:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Recuerde que un TVF en línea aplica la incorporación de parámetros. Esto significa que cuando pasa una constante como N'dbo.T2' como entrada, el proceso de inserción sustituye todas las referencias a @WhichTable con la constante antes de la optimización . El proceso de eliminación puede eliminar las referencias a T1 y T3 del árbol de consulta inicial y, por lo tanto, la optimización de consultas da como resultado un plan que hace referencia solo a T2. Probemos esta idea con la siguiente consulta:
SELECT * FROM dbo.OneTable(N'dbo.T2');
El plan para esta consulta se muestra en la Figura 1.
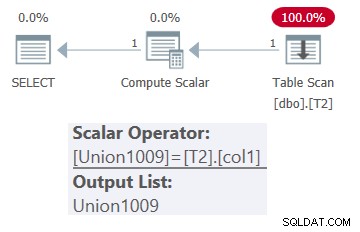 Figura 1:Plan para dbo.OneTable con entrada constante
Figura 1:Plan para dbo.OneTable con entrada constante
Como puede ver, en el plan solo aparece la tabla T2.
Las cosas son un poco más complicadas cuando pasas una no constante como entrada. Este podría ser el caso cuando se usa una variable, un parámetro de procedimiento o se pasa una columna a través de APLICAR. El valor de entrada es desconocido en el momento de la compilación o se debe tener en cuenta el potencial de reutilización del plan parametrizado.
El optimizador no puede eliminar ninguna de las tablas del plan, pero aún tiene truco. Puede usar operadores de filtro de inicio sobre los subárboles que acceden a las tablas y ejecutar solo el subárbol relevante según el valor de tiempo de ejecución de @WhichTable. Utilice el siguiente código para probar esta estrategia:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
El plan para esta ejecución se muestra en la Figura 2:
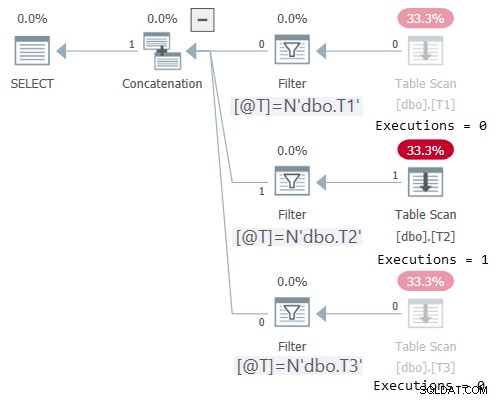 Figura 2:Plan para dbo.OneTable con entrada no constante
Figura 2:Plan para dbo.OneTable con entrada no constante
Plan Explorer hace que sea maravillosamente obvio ver que solo se ejecutó el subárbol aplicable (Ejecuciones =1), y atenúa los subárboles que no se ejecutaron (Ejecuciones =0). Además, STATISTICS IO muestra información de E/S solo para la tabla a la que se accedió:
Mesa 'T2'. Recuento de escaneos 1, lecturas lógicas 1, lecturas físicas 0, lecturas del servidor de páginas 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas del servidor de páginas lob 0, lecturas lob- adelante lee 0, la lectura anticipada del servidor de páginas lob lee 0.Aplicando la lógica de eliminación de unidades horizontales al desafío de la serie numérica
Como se mencionó, puede aplicar el concepto de eliminación de unidades horizontales modificando cualquiera de las soluciones anteriores que actualmente usan la lógica de eliminación vertical. Usaré la función dbo.GetNumsAlanCharlieItzikBatch como punto de partida para mi ejemplo.
Recuerde que Joe Obbish usó la eliminación de unidades horizontales para extraer los subrangos disjuntos relevantes de la serie numérica. Usaremos el concepto para separar horizontalmente el cálculo menos costoso (rn) donde @low =1 del cálculo más costoso (n) donde @low <> 1.
Ya que estamos en eso, podemos experimentar agregando la idea de Jeff Moden en su función fnTally, donde usa una fila centinela con el valor 0 para los casos en los que el rango comienza con @low =0.
Entonces tenemos cuatro unidades horizontales:
- Fila centinela con 0 donde @low =0, con n =0
- filas SUPERIORES (@alto) donde @bajo =0, con n barato =número de fila y op =@alto – número de fila
- filas TOP (@high) donde @low =1, con n económico =número de fila y op =@high + 1 – número de fila
- TOP(@alto – @bajo + 1) filas donde @bajo <> 0 Y @bajo <> 1, con n más caro =@bajo – 1 + número de fila, y op =@alto + 1 – número de fila
Esta solución combina ideas de Alan, Charlie, Joe, Jeff y las mías, por lo que llamaremos a la versión en modo por lotes de la función dbo.GetNumsAlanCharlieJoeJeffItzikBatch.
Primero, recuerde asegurarse de que todavía tiene presente la tabla ficticia dbo.BatchMe para obtener el procesamiento por lotes en nuestra solución, o use el siguiente código si no la tiene:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Aquí está el código con la definición de la función dbo.GetNumsAlanCharlieJoeJeffItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Importante:El concepto de eliminación de unidades horizontales es sin duda más complejo de implementar que el vertical, así que ¿para qué molestarse? Porque elimina la responsabilidad de elegir la columna correcta del usuario. El usuario solo debe preocuparse por consultar una columna llamada n, en lugar de recordar usar rn cuando el rango comienza con 1 y n en caso contrario.
Comencemos probando la solución con las entradas constantes 1 y 100,000,000, solicitando que se ordene el resultado:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 3.
 Figura 3:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Figura 3:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Observe que la única columna devuelta se basa en la expresión directa, no manipulada, ROW_NUMBER (Expr1313). También observe que no hay necesidad de ordenar en el plan.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =7359 ms, tiempo transcurrido =7354 ms.El tiempo de ejecución refleja adecuadamente el hecho de que el plan utiliza el modo por lotes, la expresión ROW_NUMBER no manipulada y sin clasificación.
Luego, prueba la función con el rango constante de 0 a 99,999,999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 4.
 Figura 4:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Figura 4:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
El plan utiliza un operador Merge Join (Concatenación) para fusionar la fila centinela con el valor 0 y el resto. A pesar de que la segunda parte es tan eficiente como la anterior, la lógica de combinación tiene un costo bastante alto de alrededor del 26 % en el tiempo de ejecución, lo que da como resultado las siguientes estadísticas de tiempo:
Tiempo de CPU =9265 ms, tiempo transcurrido =9298 ms.Probemos la función con el rango constante de 2 a 100,000,001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 5.
 Figura 5:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Figura 5:Plan para dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Esta vez no hay una lógica de combinación costosa ya que la parte de la fila centinela es irrelevante. Sin embargo, observe que la columna devuelta es la expresión manipulada @low – 1 + número de fila, que después de incrustar/alinear parámetros y doblar constantemente se convirtió en 1 + número de fila.
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =9000 ms, tiempo transcurrido =9015 ms.Como era de esperar, esto no es tan rápido como con un rango que comienza con 1, pero curiosamente, más rápido que con un rango que comienza con 0.
Eliminar la fila centinela 0
Dado que la técnica con la fila centinela con el valor 0 parece ser más lenta que aplicar la manipulación a rownum, tiene sentido simplemente evitarla. Esto nos lleva a una solución simplificada basada en la eliminación horizontal que combina las ideas de Alan, Charlie, Joe y las mías. Llamaré a la función con esta solución dbo.GetNumsAlanCharlieJoeItzikBatch. Aquí está la definición de la función:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Probémoslo con el rango de 1 a 100M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
El plan es el mismo que se muestra anteriormente en la Figura 3, como se esperaba.
En consecuencia, obtuve las siguientes estadísticas de tiempo:
Tiempo de CPU =7219 ms, tiempo transcurrido =7243 ms.Pruébalo con el rango de 0 a 99,999,999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Esta vez obtiene el mismo plan que el que se muestra anteriormente en la Figura 5, no en la Figura 4.
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =9313 ms, tiempo transcurrido =9334 ms.Pruébelo con el rango de 2 a 100,000,001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Nuevamente obtiene el mismo plan que el que se muestra anteriormente en la Figura 5.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =9125 ms, tiempo transcurrido =9148 ms.Advertencias al usar entradas no constantes
Con las técnicas de eliminación de unidades verticales y horizontales, las cosas funcionan idealmente siempre que pase constantes como entradas. Sin embargo, debe tener en cuenta las advertencias que pueden resultar en penalizaciones de rendimiento cuando pasa entradas no constantes. La técnica de eliminación de unidades verticales tiene menos problemas, y los problemas que existen son más fáciles de manejar, así que comencemos con eso.
Recuerde que en este artículo usamos la función dbo.GetNumsAlanCharlieItzikBatch como nuestro ejemplo que se basa en el concepto de eliminación de unidades verticales. Ejecutemos una serie de pruebas con entradas no constantes, como variables.
Como primera prueba, devolveremos rn y pediremos los datos ordenados por rn:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Recuerde que rn representa la expresión ROW_NUMBER no manipulada, por lo que el hecho de que usemos entradas no constantes no tiene un significado especial en este caso. No hay necesidad de clasificación explícita en el plan.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =7390 ms, tiempo transcurrido =7386 ms.Estos números representan el caso ideal.
En la siguiente prueba, ordene las filas de resultados por n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 6.
 Figura 6:Plan para dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ordenar por n
Figura 6:Plan para dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ordenar por n
¿Ves el problema? Después de insertar, @low se reemplazó con @mylow, no con el valor en @mylow, que es 1. En consecuencia, no se produjo el plegamiento constante y, por lo tanto, n no conserva el orden con respecto a rownum. Esto resultó en una clasificación explícita en el plan.
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =25141 ms, tiempo transcurrido =25628 ms.El tiempo de ejecución casi se triplicó en comparación con cuando no se necesitaba la clasificación explícita.
Una solución sencilla es utilizar la idea original de Alan Burstein de ordenar siempre por rn cuando necesite ordenar el resultado, tanto al devolver rn como al devolver n, así:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Esta vez no hay clasificación explícita en el plan.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Tiempo de CPU =9156 ms, tiempo transcurrido =9184 ms.Los números reflejan adecuadamente el hecho de que está devolviendo la expresión manipulada, pero no incurriendo en una clasificación explícita.
Con soluciones que se basan en la técnica de eliminación de unidades horizontales, como nuestra función dbo.GetNumsAlanCharlieJoeItzikBatch, la situación es más complicada cuando se usan entradas no constantes.
Primero probemos la función con un rango muy pequeño de 10 números:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 7.
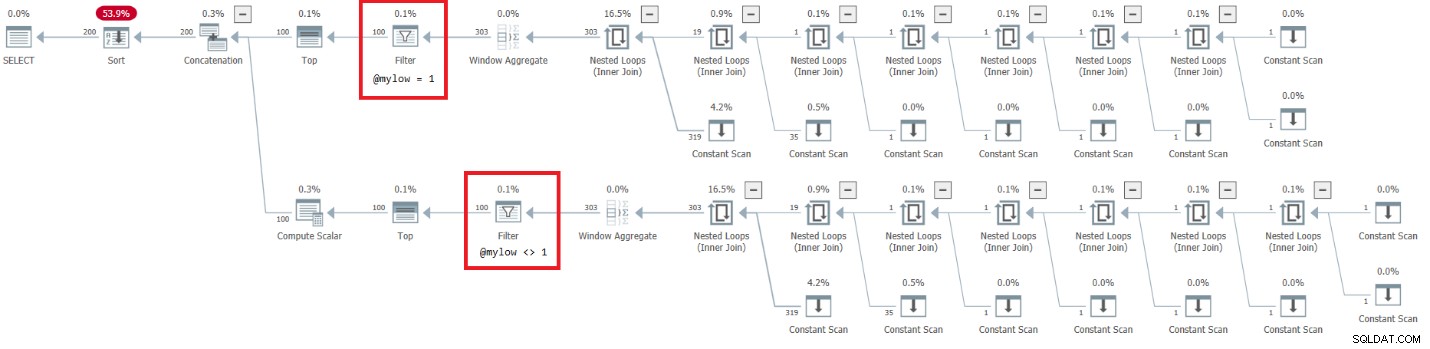 Figura 7:Plan para dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 7:Plan para dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Hay un lado muy alarmante en este plan. Observe que los operadores de filtro aparecen abajo los mejores operadores! En cualquier llamada dada a la función con entradas no constantes, naturalmente, una de las ramas debajo del operador Concatenación siempre tendrá una condición de filtro falsa. Sin embargo, ambos operadores Top solicitan un número de filas distinto de cero. Entonces, el operador superior sobre el operador con la condición de filtro falsa solicitará filas y nunca estará satisfecho, ya que el operador de filtro seguirá descartando todas las filas que obtendrá de su nodo secundario. El trabajo en el subárbol debajo del operador Filtro deberá ejecutarse hasta su finalización. En nuestro caso, esto significa que el subárbol realizará el trabajo de generar filas 4B, que el operador de filtro descartará. Se pregunta por qué el operador de filtro se molesta en solicitar filas de su nodo secundario, pero parece que así es como funciona actualmente. Es difícil ver esto con un plan estático. Es más fácil ver esto en vivo, por ejemplo, con la opción de ejecución de consultas en vivo en SentryOne Plan Explorer, como se muestra en la Figura 8. Pruébelo.
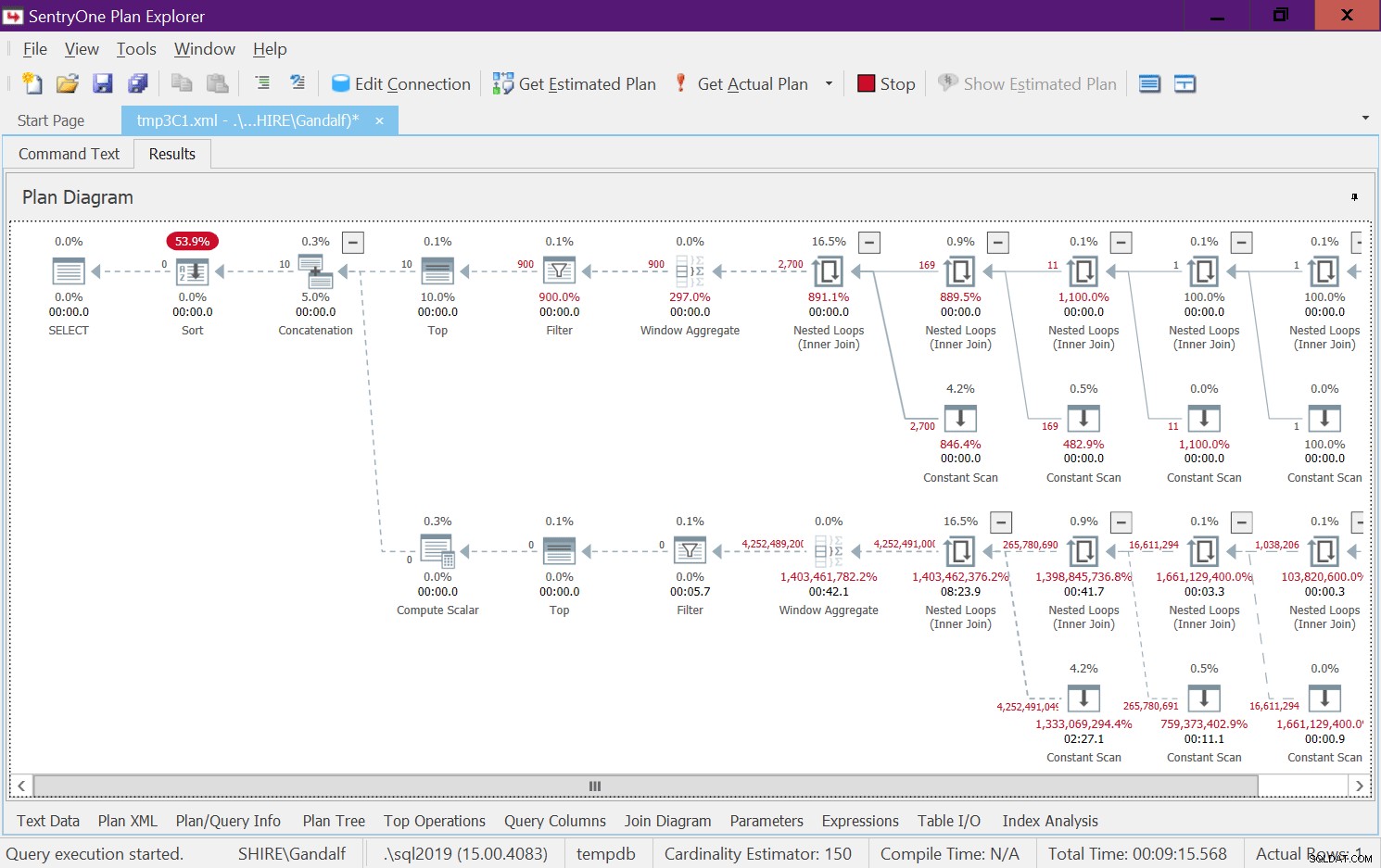 Figura 8:Estadísticas de consultas en vivo para dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 8:Estadísticas de consultas en vivo para dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Esta prueba tardó 9:15 minutos en completarse en mi máquina y recuerde que la solicitud era para devolver un rango de 10 números.
Pensemos si hay alguna forma de evitar activar el subárbol irrelevante en su totalidad. Para lograr esto, querrá que los operadores de filtro de inicio aparezcan arriba los operadores superiores en lugar de debajo de ellos. Si lee Aspectos básicos de las expresiones de tabla, Parte 4:Tablas derivadas, consideraciones de optimización, continuación, sabrá que un filtro TOP evita el anidamiento de expresiones de tabla. Entonces, todo lo que necesita hacer es colocar la consulta TOP en una tabla derivada y aplicar el filtro en una consulta externa contra la tabla derivada.
Aquí está nuestra función modificada que implementa este truco:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Como era de esperar, las ejecuciones con constantes siguen comportándose y funcionando igual que sin el truco.
En cuanto a las entradas no constantes, ahora con rangos pequeños es muy rápido. Aquí hay una prueba con un rango de 10 números:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
El plan para esta ejecución se muestra en la Figura 9.
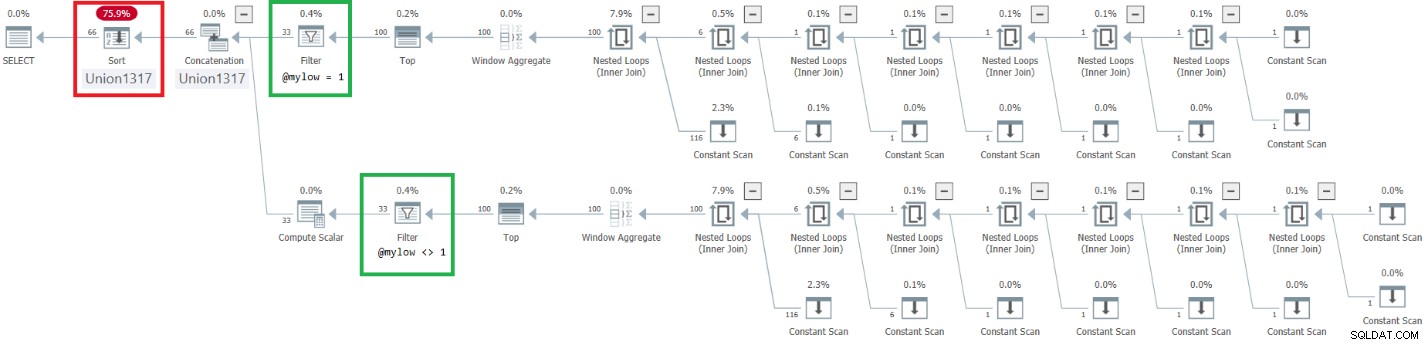 Figura 9:Plan para mejorar dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Figura 9:Plan para mejorar dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Observe que se logró el efecto deseado de colocar los operadores Filtro encima de los operadores Superior. Sin embargo, la columna de orden n se trata como un resultado de la manipulación y, por lo tanto, no se considera una columna que preserva el orden con respecto a número de fila. En consecuencia, hay una clasificación explícita en el plan.
Pruebe la función con un amplio rango de 100 millones de números:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Obtuve las siguientes estadísticas de tiempo:
Tiempo de CPU =29907 ms, tiempo transcurrido =29909 ms.Qué fastidio; ¡fue casi perfecto!
Resumen de rendimiento e información
La Figura 10 tiene un resumen de las estadísticas de tiempo para las diferentes soluciones.
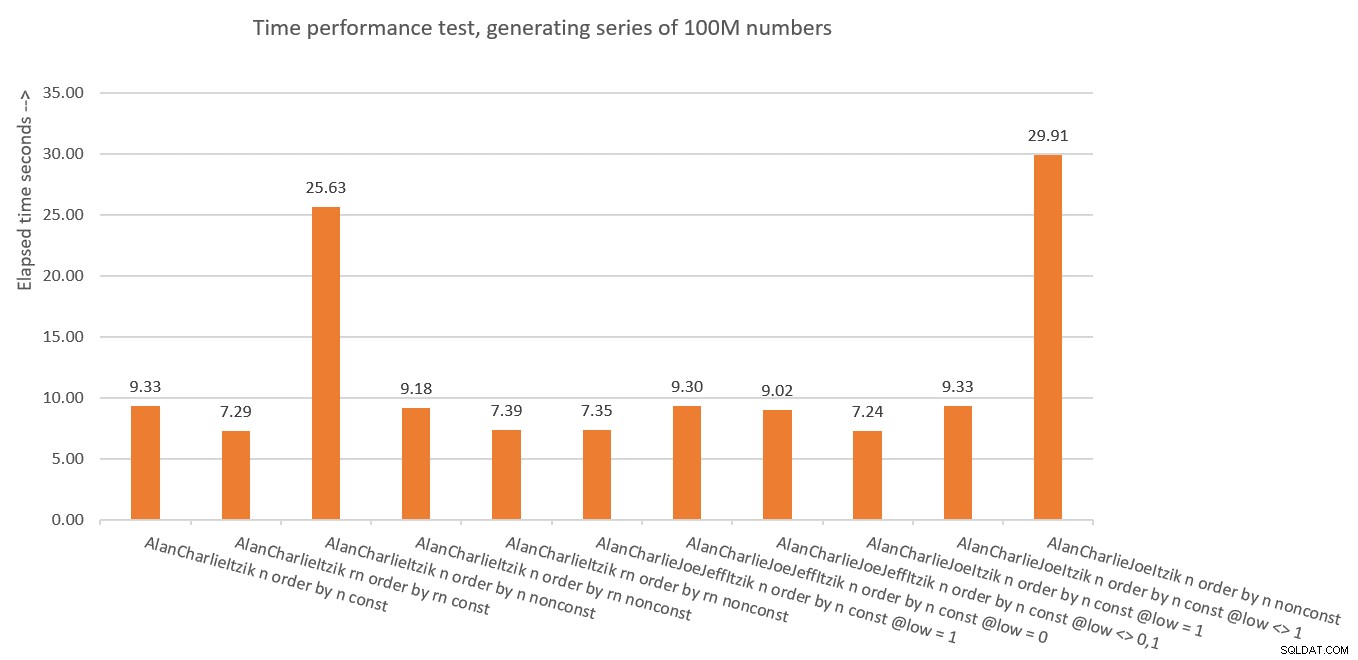 Figura 10:Resumen de rendimiento de tiempo de las soluciones
Figura 10:Resumen de rendimiento de tiempo de las soluciones
Entonces, ¿qué hemos aprendido de todo esto? ¡Supongo que no volveré a hacerlo! Es una broma. Aprendimos que es más seguro usar el concepto de eliminación vertical como en dbo.GetNumsAlanCharlieItzikBatch, que expone tanto el resultado ROW_NUMBER no manipulado (rn) como el manipulado (n). Solo asegúrese de que cuando necesite devolver el resultado ordenado, siempre ordene por rn, ya sea que devuelva rn o n.
Si está absolutamente seguro de que su solución siempre se usará con constantes como entradas, puede usar el concepto de eliminación de unidades horizontales. Esto dará como resultado una solución más intuitiva para el usuario, ya que estará interactuando con una columna para los valores ascendentes. Todavía sugeriría usar el truco con las tablas derivadas para evitar el anidamiento y colocar los operadores de filtro sobre los operadores superiores si la función se usa alguna vez con entradas no constantes, solo para estar seguro.
Todavía no hemos terminado. El próximo mes continuaré explorando soluciones adicionales.