En mi publicación anterior sobre estadísticas incrementales, una nueva característica de SQL Server 2014, demostré cómo pueden ayudar a reducir la duración de las tareas de mantenimiento. Esto se debe a que las estadísticas se pueden actualizar en el nivel de partición y los cambios se fusionan en el histograma principal de la tabla. También noté que el Optimizador de consultas no usa esas estadísticas de nivel de partición al generar planes de consulta, lo que puede ser algo que la gente esperaba. No existe documentación que indique que el Optimizador de consultas utilizará o no estadísticas incrementales. Entonces, ¿cómo lo sabes? Tienes que probarlo. :-)
La configuración
La configuración para esta prueba será similar a la de la última publicación, pero con menos datos. Tenga en cuenta que los tamaños predeterminados son más pequeños para los archivos de datos y la secuencia de comandos solo se carga en unos pocos millones de filas de datos:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Cuando creamos el índice agrupado para dbo.Orders, lo crearemos sin STATISTICS_INCREMENTAL opción habilitada, por lo que comenzaremos con una tabla particionada tradicional sin estadísticas incrementales:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
A continuación, cargaremos alrededor de 4 millones de filas, lo que lleva poco menos de un minuto en mi máquina:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Después de la carga de datos, actualizaremos las estadísticas con un FULLSCAN (para que podamos crear un histograma lo más consistente posible para las pruebas) y luego verificaremos qué datos tenemos en cada partición:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Datos en cada partición después de la carga de datos
Datos en cada partición después de la carga de datos
La mayoría de los datos están en la partición de 2015, pero también hay datos de 2012, 2013 y 2014. Y si verificamos la salida del DMV no documentado sys.dm_db_stats_properties_internal , podemos ver que no existen estadísticas a nivel de partición:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal salida que muestra solo una estadística para dbo.Orders
sys.dm_db_stats_properties_internal salida que muestra solo una estadística para dbo.Orders
La prueba
La prueba requiere una consulta simple que podemos usar para verificar que se produce la eliminación de la partición y también verificar las estimaciones basadas en estadísticas. La consulta no devuelve ningún dato, pero eso no importa, nos interesa lo que pensó el optimizador. devolvería, según las estadísticas:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
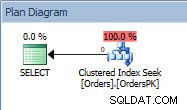 Plan de consulta para la instrucción SELECT
Plan de consulta para la instrucción SELECT
El plan tiene una búsqueda de índice agrupado, y si verificamos las propiedades, vemos que estimó 4000 filas y accedió a la partición 5, que contiene datos de 2014.
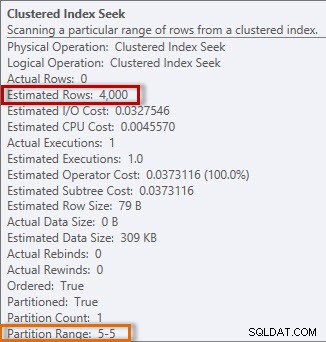 Información estimada y real de la búsqueda de índice agrupado
Información estimada y real de la búsqueda de índice agrupado
Si observamos el histograma de la tabla dbo.Orders, específicamente en el área de datos de abril de 2014, vemos que no hay ningún paso para 2014-04-01, por lo que el optimizador estima el número de filas para esa fecha usando el paso para 2014-04-24, donde AVG_RANGE_ROWS es 4000 (para cualquier valor entre 2014-02-14 y 2014-04-23 inclusive, el optimizador estimará que se devolverán 4000 filas).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
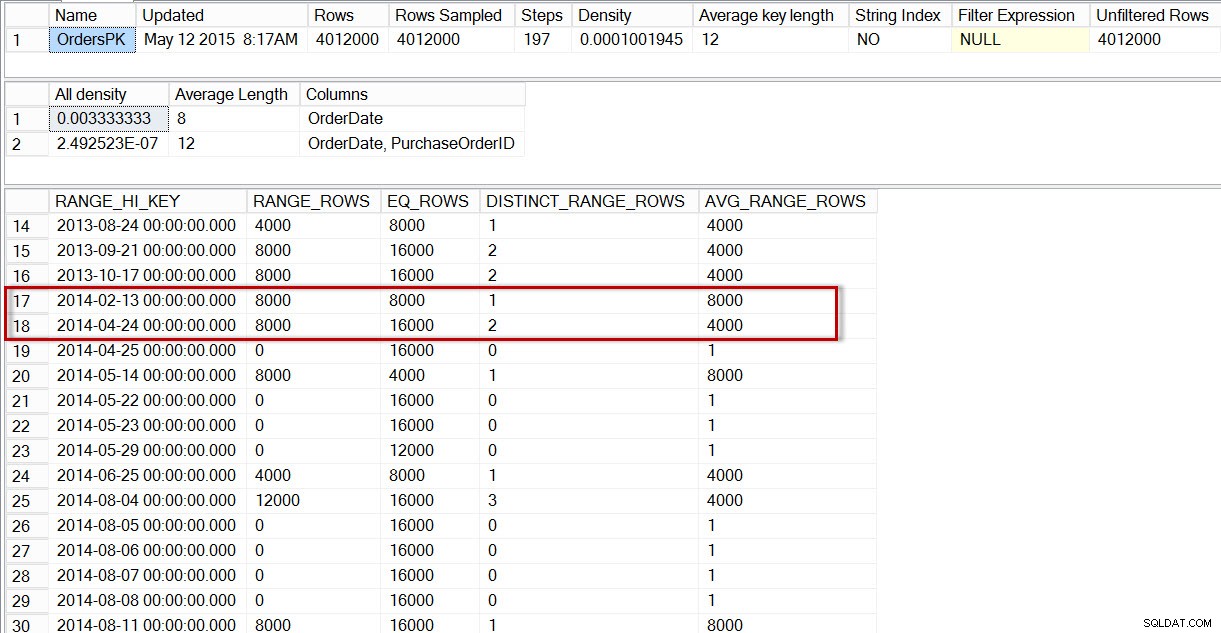 Distribución en el histograma dbo.Orders
Distribución en el histograma dbo.Orders
La estimación y el plan son completamente esperados. Habilitemos las estadísticas incrementales y veamos qué obtenemos.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Si volvemos a ejecutar nuestra consulta contra sys.dm_db_stats_properties_internal , podemos ver las estadísticas incrementales:
 sys.dm_db_stats_properties_internal mostrando información de estadísticas incrementales
sys.dm_db_stats_properties_internal mostrando información de estadísticas incrementales
Ahora volvamos a ejecutar nuestra consulta dbo.Orders, y ejecutaremos DBCC FREEPROCCACHE primero para asegurarse de que el plan no se reutilice:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Obtenemos el mismo plan y el mismo presupuesto:
Plan de consulta para la instrucción SELECT
Información estimada y real de la búsqueda de índice agrupado
Si revisamos el histograma principal para dbo.Orders, vemos casi el mismo histograma que antes:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histograma para dbo.Orders, después de habilitar estadísticas incrementales
Histograma para dbo.Orders, después de habilitar estadísticas incrementales
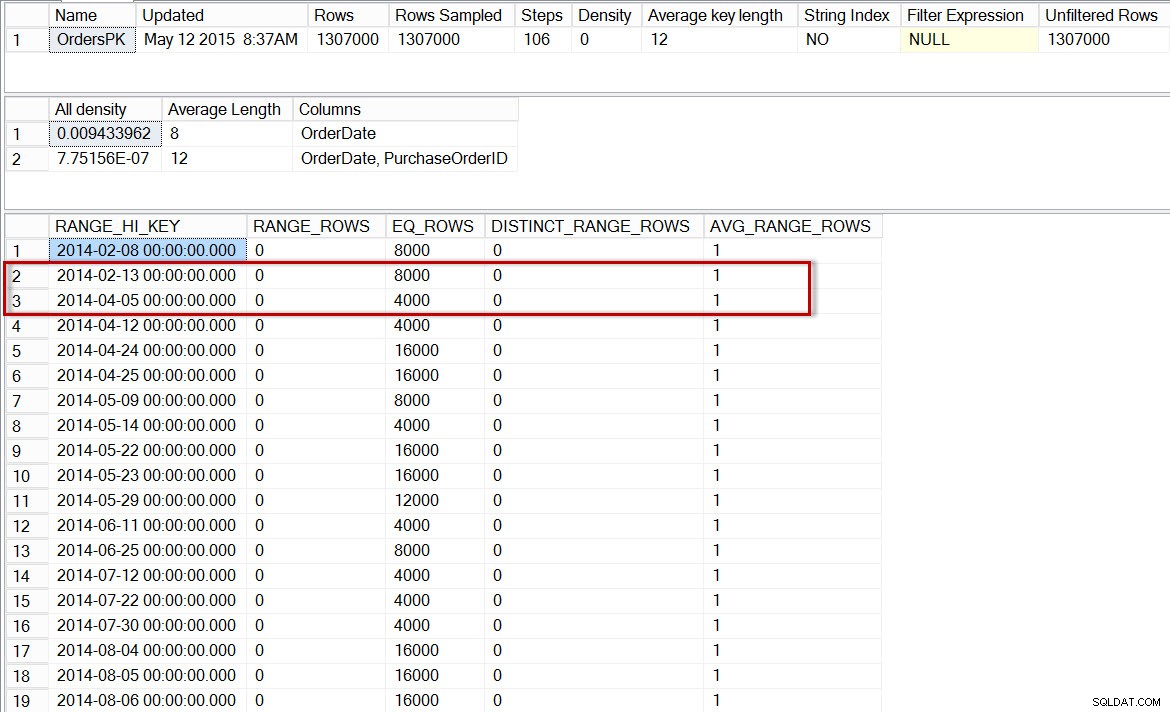
Ahora, verifiquemos el histograma de la partición con datos de 2014 (podemos hacerlo usando el indicador de seguimiento no documentado 2309, que permite especificar un número de partición como argumento adicional para DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histograma para la partición de 2014 de dbo.Orders, después de habilitar estadísticas incrementales
Aquí vemos que, nuevamente, no hay ningún paso para 2014-04-01, pero hay 0 RANGE_ROWS entre 2014-02-13 y 2014-04-05, con un AVG_RANGE_ROWS de 1. Si el optimizador estuviera usando el histograma para las estadísticas de nivel de partición, entonces la estimación del número de filas para 2014-04-01 sería 1.
Nota:la partición identificada como utilizada en el plan de consulta es 5, pero notará que DBCC SHOW_STATISTICS La declaración hace referencia a la partición 6. La suposición es una incoherencia en los metadatos estadísticos (un error común de uno en uno, probablemente debido al conteo basado en 0 frente a 1), que puede corregirse o no en el futuro. Comprenda que el indicador de seguimiento no está documentado en este momento y que no se recomienda su uso en un entorno de producción.
Resumen
La adición de estadísticas incrementales en la versión de SQL Server 2014 es un paso en la dirección correcta para mejorar las estimaciones de cardinalidad para las tablas particionadas. Sin embargo, como hemos demostrado, el valor actual de las estadísticas incrementales se limita a duraciones de mantenimiento reducidas, ya que el Optimizador de consultas aún no utiliza esas estadísticas incrementales.