Recientemente, participé en el desarrollo de la funcionalidad que requería una transferencia rápida y frecuente de grandes volúmenes de datos al disco. Además, se suponía que estos datos debían leerse del disco de vez en cuando. Por lo tanto, estaba destinado a averiguar el lugar, la forma y los medios para almacenar estos datos. En este artículo, revisaré brevemente la tarea, además de investigar y comparar soluciones para completarla.
Contexto de la tarea :Trabajo en un equipo que desarrolla herramientas para el desarrollo de bases de datos relativas (SQL Server, MySQL, Oracle). La gama de herramientas incluye herramientas independientes y complementos para MS SSMS.
Tarea :Restauración de documentos que se abrieron en el momento del cierre de IDE en el próximo inicio de IDE.
Caso de uso :Para cerrar IDE rápidamente antes de salir de la oficina sin pensar en qué documentos se guardaron y cuáles no. En el próximo inicio de IDE, necesitamos obtener el mismo entorno que estaba en el momento del cierre y continuar con el trabajo. Todos los resultados del trabajo deben guardarse en el momento del cierre desordenado, p. durante el bloqueo de un programa o sistema operativo, o durante el apagado.
Análisis de tareas :La característica similar está presente en los navegadores web. Sin embargo, los navegadores almacenan solo direcciones URL que constan de aproximadamente 100 símbolos. En nuestro caso, necesitamos almacenar todo el contenido del documento. Por lo tanto, necesitamos un lugar para guardar y almacenar los documentos de los usuarios. Es más, en ocasiones los usuarios trabajan con SQL de forma diferente a como lo hacen con otros lenguajes. Por ejemplo, si escribo una clase C# de más de 1000 filas, difícilmente será aceptable. Mientras que, en el universo SQL, junto con las consultas de 10 a 20 filas, existen monstruosos volcados de bases de datos. Dichos volcados son difícilmente editables, lo que significa que los usuarios preferirían mantener sus ediciones seguras.
Requisitos para un almacenamiento:
- Debería ser una solución integrada ligera.
- Debe tener una alta velocidad de escritura.
- Debe tener una opción de acceso multiprocesamiento. Este requisito no es crítico, ya que podemos asegurar el acceso con la ayuda de los objetos de sincronización, pero aun así, sería bueno tener esta opción.
Candidatos
El primer candidato es bastante torpe, es decir, almacenar todo en una carpeta, en algún lugar de AppData.
El segundo candidato es obvio:SQLite, un estándar de bases de datos integradas. Candidato muy sólido y popular.
El tercer candidato es la base de datos LiteDB. Es el primer resultado de la consulta "base de datos integrada para .net" en Google.
Primera vista
Sistema de archivos. Los archivos son archivos, requieren mantenimiento y una denominación adecuada. Además del contenido del archivo, necesitaremos almacenar un pequeño conjunto de propiedades (ruta original en el disco, cadena de conexión, versión de IDE en la que se abrió). Significa que tendremos que crear dos archivos para un documento o inventar un formato que separe las propiedades del contenido.
SQLite es una base de datos relacional clásica. La base de datos está representada por un archivo en el disco. Este archivo se vincula con el esquema de la base de datos, después de lo cual tenemos que interactuar con él con la ayuda de los medios SQL. Podremos crear 2 tablas, una para propiedades y otra para contenido, en caso de que necesitemos usar propiedades o contenido por separado.
LiteDB es una base de datos no relacional. Similar a SQLite, la base de datos está representada por un solo archivo. Está completamente escrito en С#. Tiene una simplicidad de uso cautivadora:solo necesitamos dar un objeto a la biblioteca, mientras que la serialización se realizará por sus propios medios.
Prueba de rendimiento
Antes de proporcionar el código, me gustaría explicar la concepción general y proporcionar resultados de comparación.
La concepción general es comparar la velocidad de escritura de una gran cantidad de archivos pequeños en la base de datos, una cantidad promedio de archivos promedio y una pequeña cantidad de archivos grandes. El caso con archivos promedio es mayormente cercano al caso real, mientras que los casos con archivos pequeños y grandes son casos límite, que también deben tenerse en cuenta.
Estaba escribiendo contenido en un archivo con la ayuda de FileStream con el tamaño de búfer estándar.
Hubo un matiz en SQLite que me gustaría mencionar. No pudimos poner todo el contenido del documento (como mencioné anteriormente, pueden ser muy grandes) en una celda de la base de datos. La cuestión es que, con fines de optimización, almacenamos el texto del documento línea por línea. Esto significa que para colocar texto en una sola celda, debemos colocar todos los documentos en una sola fila, lo que duplicaría la cantidad de memoria operativa utilizada. El otro lado del problema se revelaría durante la lectura de datos de la base de datos. Es por eso que había una tabla separada en SQLite, donde los datos se almacenaban fila por fila y los datos se vinculaban con la ayuda de una clave externa con la tabla que contenía solo las propiedades del archivo. Además, logré acelerar la base de datos con la inserción de datos por lotes (varios miles de filas a la vez) en el modo de sincronización APAGADO sin registro y dentro de una transacción.
LiteDB recibió un objeto que tenía Lista entre sus propiedades y la biblioteca lo guardó en el disco por su cuenta.
Durante el desarrollo de la aplicación de prueba, entendí que prefiero LiteDB. La cuestión es que el código de prueba para SQLite ocupa más de 120 filas, mientras que el código que resuelve el mismo problema en LiteDb ocupa solo 20 filas.
Generación de datos de prueba
Cadenas de archivo.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
} LiteDB
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
La siguiente tabla muestra los resultados promedio de varias ejecuciones del código de prueba. Durante las modificaciones, la desviación estadística fue bastante imperceptible.
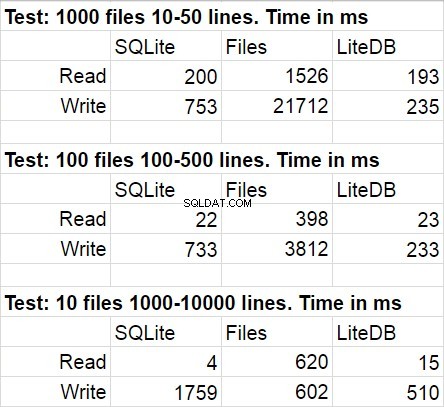
No me sorprendió que LiteDB ganara en esta comparación. Sin embargo, me sorprendió la victoria de LiteDB sobre los archivos. Después de un breve estudio del repositorio de la biblioteca, descubrí que la escritura en disco paginal implementada muy meticulosamente, pero estoy seguro de que este es solo uno de los muchos trucos de rendimiento que se usan allí. Una cosa más que me gustaría señalar es que la velocidad de acceso al sistema de archivos disminuye cuando la cantidad de archivos en la carpeta se vuelve muy grande.
Seleccionamos LiteDB para el desarrollo de nuestra función y no nos arrepentimos de esta elección. Lo que pasa es que la librería está escrita en nativo para todo el mundo C#, y si algo no quedó del todo claro, siempre podemos consultar el código fuente.
Desventajas
Además de las ventajas mencionadas anteriormente de LiteDB en comparación con sus competidores, comenzamos a notar las desventajas durante el desarrollo. La mayoría de estos inconvenientes pueden explicarse por la "juventud" de la biblioteca. Habiendo comenzado a usar la biblioteca un poco más allá de los límites del escenario "estándar", descubrimos varios problemas (#419, #420, #483, #496). El autor de la biblioteca respondió a las preguntas con bastante rapidez y la mayoría de los problemas se resolvieron rápidamente. Ahora, solo queda una tarea (no se confunda con su estado Cerrado). Esta es una cuestión de acceso competitivo. Parece que una condición de carrera muy desagradable se esconde en algún lugar profundo de la biblioteca. Pasamos por alto este error de una manera bastante original (tengo la intención de escribir un artículo separado sobre este tema).
También me gustaría mencionar la ausencia de un editor y un visor ordenados. Existe LiteDBShell, pero solo para verdaderos fanáticos de las consolas.
Resumen
Hemos construido una funcionalidad grande e importante sobre LiteDB, y ahora estamos trabajando en otra característica grande en la que también usaremos esta biblioteca. Para aquellos que buscan una base de datos en proceso, les sugiero que presten atención a LiteDB y a la forma en que demostrará su valía en el contexto de su tarea, ya que, como saben, si algo hubiera funcionado para una tarea, no necesariamente funcionaría. hacer ejercicio para otra tarea.