El análisis de datos de XML usando XQuery es una práctica rutinaria. Para hacer esto de la manera más efectiva, se requiere poco esfuerzo.
Supongamos que necesitamos analizar datos del archivo de disco con la siguiente estructura:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Use BULK INSERT, si necesita leer datos de un archivo:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Un archivo xml de muestra está aquí.
Sin embargo, tenga en cuenta una cosa en particular... Trate de no leer los datos directamente:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Asignar datos a una variable. De esta manera puede obtener un plan de ejecución más eficiente:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Compara los resultados:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Como puede ver, la segunda opción es sustancialmente más rápida.
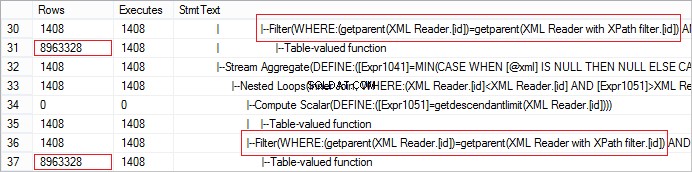
Otra característica importante de SQL Server cuando se trabaja con XQuery es que la lectura de un elemento principal puede generar un rendimiento deficiente. Considere el siguiente ejemplo:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Veamos el número real de filas recibidas del operador. El valor es anormalmente grande:
La solicitud se puede optimizar fácilmente usando CROSS APPLY:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Comparemos el tiempo de ejecución:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Como puede ver en el ejemplo, la solicitud con CROSS APPLY funciona instantáneamente.
Gracias por tu atención. Espero que este artículo haya sido útil. No dude en hacer cualquier pregunta, dejar sus comentarios y sugerencias sobre este artículo.