En esta era de dura competencia, los portales de empleo no son solo plataformas para publicar y encontrar trabajo. Están aprovechando los servicios y funciones avanzados para mantener a sus clientes comprometidos. Profundicemos en algunas características avanzadas y construyamos un modelo de datos que pueda manejarlas.
Expliqué las características básicas necesarias para un sitio web de portal de empleo en un artículo anterior. El modelo se muestra a continuación. Consideraremos este modelo como base, que cambiaremos para cumplir con los nuevos requisitos. Primero, consideremos cuáles deberían ser estos requisitos (o mejoras).
¿Qué estamos agregando al modelo de datos del portal de empleo en línea?
Brevemente, agregaremos cuatro mejoras a nuestro modelo de datos anterior:
- Un panel personal para buscadores de empleo. Esto realiza un seguimiento de todas sus solicitudes de empleo y proporciona actualizaciones en tiempo real sobre cualquier cambio de estado (es decir, una solicitud cambia de recibida a revisada).
- Un panel de perfil. Esto detalla quién está visitando el perfil de un solicitante de empleo y cuántas veces se descargó su currículum en el último día, semana o mes.
- Gestión de servicios de pago. Los portales de empleo a menudo ofrecen servicios como preparación de currículum de expertos, gestión de perfiles sociales, consultoría profesional, etc. Nuestras nuevas funcionalidades podrán admitir ofertas de pago.
- Gestión de formularios de solicitud previa. A medida que los solicitantes envían una solicitud de empleo, se les puede pedir que completen un breve cuestionario relacionado con los horarios de trabajo, las ubicaciones y la verificación de antecedentes. Construiremos formas para que los reclutadores personalicen este formulario y para que el sistema capture las preguntas y respuestas.
Mejora n.° 1:Tablero personal
Preguntas para responder: ¿Cuál es el estado actual de una solicitud enviada? ¿Está preseleccionado para una entrevista? ¿Ya se ha visto?
Podemos realizar un seguimiento de las solicitudes de empleo poniendo el job_application_status_id columna en job_post_activity mesa. Esta columna contiene el estado actual de una solicitud de empleo. Necesitamos crear otra tabla, job_application_status , para contener todos los estados de aplicación posibles. Algunos estados pueden ser "enviado", "en revisión", "archivado", "rechazado", "preseleccionado para entrevista", "en proceso de contratación", etc.
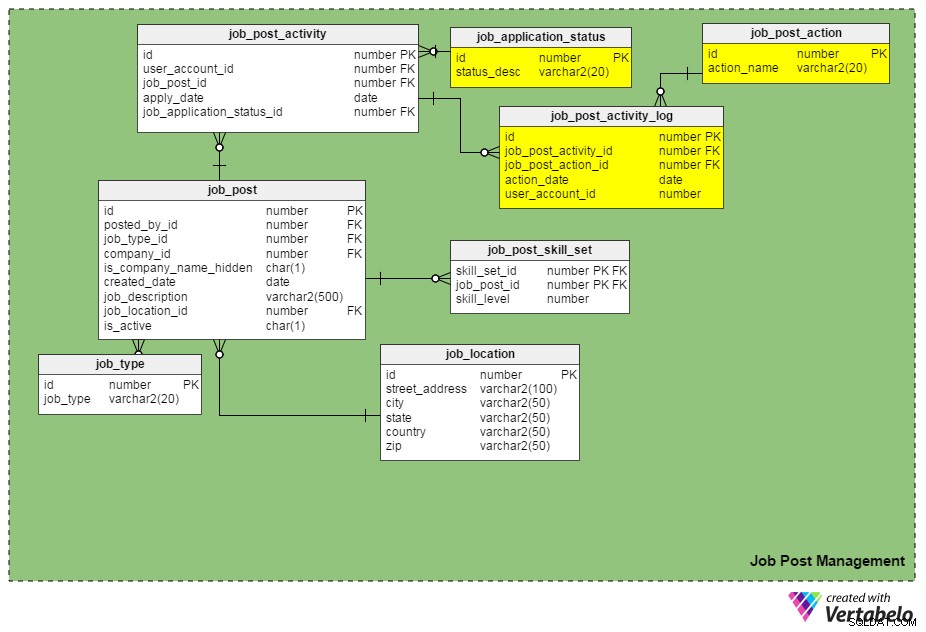
Otra tabla nueva, job_post_activity_log , almacena información sobre todas las acciones realizadas en las solicitudes de empleo, quién realizó la acción y cuándo se realizó. Esta tabla contiene las siguientes columnas:
id– La clave principal de la tabla.job_post_activity_id– El ID de la aplicación en la que se realiza la acción.job_post_action_id– El ID de la acción realizada. Esta es una clave externa que se vincula a lajob_post_actionmesa. Los tipos de acciones que podemos almacenar aquí incluyen 'enviado', 'visto', 'entrevistado', 'prueba escrita realizada', 'oferta en proceso', 'oferta enviada', 'oferta aceptada', etc.action_date– La fecha en que se realizó una acción.user_account_id– El DNI de la persona que realizó la acción.
¿"job_post_action" es idéntico a "job_application_status"? ¿En qué se diferencian?
Parecen idénticos al principio, pero en realidad son diferentes. Hay razones válidas por las que necesitamos dos campos similares:
- Un candidato es entrevistado por dos o más personas por separado. En este caso, el estado de la solicitud de empleo sigue siendo el mismo (es decir, "en proceso de contratación") hasta que se completan todas las rondas de entrevistas. Sin embargo, los registros de cada entrevistador individual se insertan en el
job_post_activity_logmesa, y tienen la acción 'entrevistado'. - Una solicitud puede ser vista por más de un reclutador en la misma empresa. Al usar estos dos atributos, no perderá la información de un solicitante.
- Hacer una oferta a un candidato seleccionado está sujeto a múltiples aprobaciones (es decir, aprobación del equipo de finanzas, aprobación del gerente del departamento de contratación, etc.). En este caso, el estado de una solicitud de empleo sigue siendo "oferta en revisión", pero la base de datos puede registrar qué aprobaciones se han realizado y cuáles no mediante el
job_post_activity_logmesa.
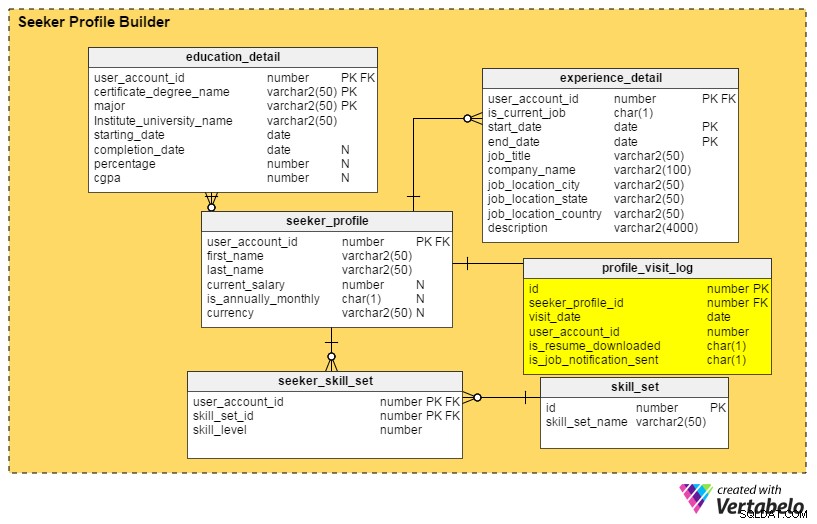
Mejora n.º 2:un panel de perfil
Preguntas para responder: ¿Quién ha encontrado mi perfil recientemente? ¿Cuántas veces fue visto por los reclutadores en el último mes, semana o día? ¿Miraron mi perfil los reclutadores de las principales empresas?
Las respuestas a todas estas preguntas se encuentran en el profile_visit_log mesa. Esta tabla captura todos los datos de visitas al perfil, incluido quién visitó un perfil, cuándo se vio, etc. Las columnas de esta tabla son:
id– La clave principal de la tabla.seeker_profile_id– Qué perfil fue visitado.visit_date– Cuándo se accedió al perfil.user_account_id– Quién vio el perfil.is_resume_downloaded– Una columna indicadora que indica si el currículum relacionado se descargó durante la visita. Esta columna nos ayudará a determinar cuántas veces los reclutadores descargan un currículum.is_job_notification_sent– Otra columna indicadora, esta que indica si se envió una notificación de trabajo al propietario del perfil.
Mejora n.º 3:Gestión de servicios de pago
Pregunta para responder: ¿Cómo pueden los portales en línea aprovechar los servicios de pago adicionales?
Además de una plataforma para publicar y buscar trabajos, muchos portales en línea brindan otros servicios, como creación de currículums expertos, consultoría profesional, etc. También ofrecen productos para ayudar a los buscadores de empleo a encontrar el trabajo de sus sueños en la ciudad de sus sueños. Por ejemplo, uno de los principales sitios de trabajo ofrece un producto que mantiene su perfil en la parte superior de las listas de reclutadores para que pueda obtener más ofertas de entrevistas. La mayoría de estos productos o servicios están disponibles mediante suscripción. Cuando un usuario compra un servicio o producto, paga durante un período de tiempo específico (es decir, un mes, tres meses, un año) por el uso de ese producto o servicio.
Mientras miraba estos portales de empleo, noté que casi ningún producto o servicio se ofrece por separado. En su mayor parte, múltiples productos y servicios se agrupan en un paquete, y este paquete se ofrece a los buscadores de empleo o reclutadores.
Teniendo en cuenta todos estos puntos, se me ocurrió el siguiente modelo de datos para incorporar servicios y productos pagos en nuestro sitio de trabajo en línea existente:
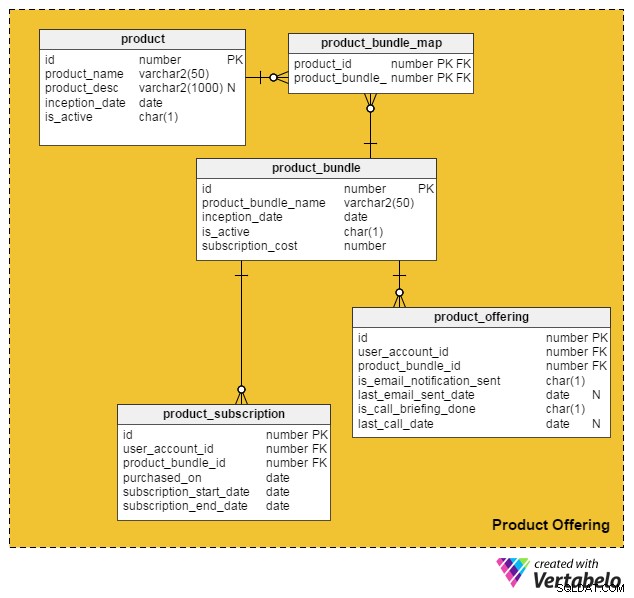
El product la tabla contiene detalles sobre productos individuales. (Nos referiremos tanto a los productos como a los servicios como "productos"). Las columnas de esta tabla son:
id– La clave principal de esta tabla, que otorga una identificación única a cada producto ofrecido en nuestro portal.product_name– Contiene el nombre del producto.product_desc– Almacena una breve descripción del producto.inception_date– La fecha en que se introdujo un producto.is_active– Si un producto está activo o no.
Dado que los productos y servicios pueden agruparse en un paquete y ofrecerse a los clientes, creé el product_bundle tabla para almacenar registros de todos esos paquetes. Los atributos son:
id– La clave principal de la tabla, que proporciona una identificación única para cada paquete de productos.product_bundle_name– Almacena el nombre del paquete.inception_date– La fecha en que se introdujo el paquete.is_active– Indica si un paquete está activo o no.subscription_cost– Almacena el precio solicitado por el paquete.
¿Se puede ofrecer un solo producto a los clientes?
Sí. En este modelo de datos, un solo producto puede ser su propio "paquete". Las siguientes tablas manejan esta y algunas otras funcionalidades importantes.
El product_bundle_map table almacena una lista de todos los productos que forman parte de un paquete. Sus atributos se explican por sí mismos.
La siguiente tabla, product_subscription , entra en juego cuando los clientes se suscriben a paquetes de productos. Registra los detalles de qué clientes se han apuntado a qué paquetes. Las columnas de esta tabla son:
id– La clave principal de la tabla.user_account_id– El usuario que compró el paquete.product_bundle_id– El paquete de productos comprado por el usuario.purchased_on– La fecha de compra.subscription_start_date– La fecha de inicio de la suscripción. Tenga en cuenta que la fecha de compra del producto y la fecha de inicio de la suscripción pueden diferir. Por lo tanto, tenemos dos columnas diferentes para estos.subscription_end_date– Cuándo finalizará la suscripción.
La mesa final, product_offering , se utiliza principalmente para la comercialización. Por lo general, los portales de empleo analizan las actividades recientes de los usuarios (tanto buscadores de empleo como reclutadores) y luego deciden qué productos serán beneficiosos para qué usuarios. Luego usan correos electrónicos o llamadas telefónicas para contactar a los clientes con ofertas seleccionadas. Las columnas de esta tabla son:
id– La clave principal de la tabla.user_account_id– El usuario al que se dirige el portal de empleo.product_bundle_id– El paquete de productos que los especialistas en marketing del portal han asociado al usuario.is_email_notification_sent– Si se ha enviado un correo electrónico sobre la oferta del producto.last_email_sent_date– Cuando el usuario recibió por última vez un correo electrónico de producto del equipo de marketing. Es común que los especialistas en marketing envíen múltiples notificaciones a un usuario y envíen otras notificaciones periódicamente. Esta columna almacena la fecha en que se envió la última notificación.is_call_briefing_done– Si el cliente recibió una llamada telefónica para informarle sobre un producto.last_call_date–La fecha de la llamada telefónica más reciente. Puede haber varias llamadas (llamadas de seguimiento) realizadas a los clientes.
Mejora n.º 4:Gestión de formularios de solicitud previa
Pregunta para responder: ¿Cómo puede un reclutador obtener un formulario de consentimiento personalizado para todos los posibles candidatos?
Muchas veces, los solicitantes de empleo tienen que responder preguntas específicas cuando solicitan un puesto. Esto comúnmente incluye cosas como dar su consentimiento para una verificación de antecedentes penales. Sin embargo, hay varios otros tipos de consentimientos que pueden ser necesarios. Por ejemplo, un trabajo en marketing puede requerir muchos viajes; los trabajos en la subcontratación de procesos comerciales (BPO) pueden requerir que los empleados trabajen en turnos de noche (es decir, hasta altas horas de la noche). Estos se abordan en los formularios de solicitud previa.
Siempre es mejor obtener el consentimiento cuando se envía la solicitud de empleo. De esta manera, los candidatos que no estén dispuestos a cumplir con estos requisitos no se postularán para el puesto.
Antes de pasar al modelo de datos, permítanme resaltar algunos datos básicos sobre los formularios de consentimiento:
- Un puesto de trabajo puede tener más de un formulario de consentimiento.
- Cada formulario de consentimiento tiene varias preguntas asociadas con varias secciones.
- Una pregunta se puede establecer como obligatoria u opcional, según cómo se etiquete la pregunta en el formulario. Una pregunta puede ser opcional en una forma y obligatoria en otra.
- Cada pregunta puede responderse como (1) sí, (2) no o (3) no corresponde.
- Todas las respuestas serán grabadas.
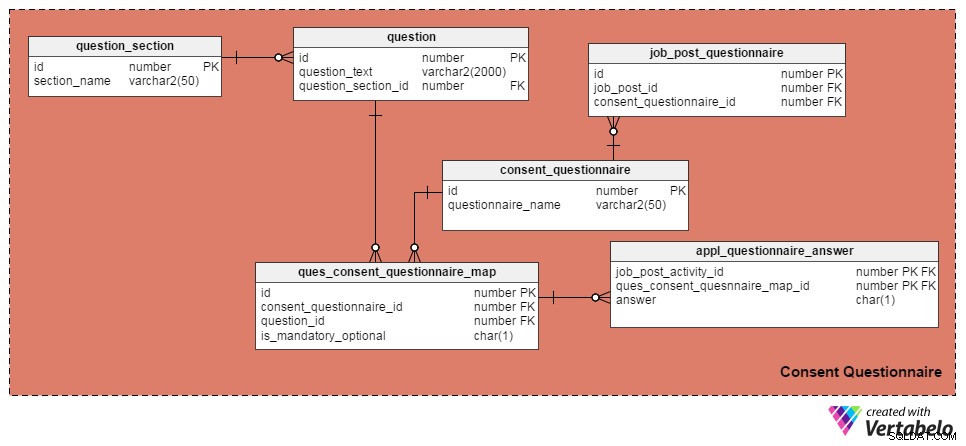
He usado las siguientes cuatro tablas para administrar preguntas y formularios de consentimiento. La primera, la question tabla, contiene una lista de preguntas. Tiene estos atributos:
id– La clave principal de la tabla, que otorga un número de identificación único a cada pregunta.question_text– Almacena el texto de la pregunta real.question_section_id– La sección donde aparece la pregunta. (Por ejemplo, "¿Ha trabajado en el desarrollo de software durante al menos cinco años?" aparecería en la sección "Experiencia laboral"). Esta es una columna de clave externa a la que se hace referencia desde laquestion_sectionmesa.
La question_section tabla almacena información de la sección. Es una forma de agrupar preguntas relacionadas con un mismo tema. Aparte del id atributo, que es la clave principal de la tabla, el único atributo es section_name , que se explica por sí mismo.
El consent_questionnaire la tabla contiene nombres de formularios de consentimiento. Sus dos atributos también se explican por sí mismos.
El ques_consent_questionnaire_map table es el núcleo de esta área temática. Todas las demás tablas en esta área temática están directa o indirectamente conectadas con ella. Su propósito es mantener una lista de preguntas etiquetadas en los formularios de consentimiento. Las columnas de esta tabla son:
id– La clave principal de esta tabla.consent_questionnaire_id– El número de identificación del formulario de consentimiento.question_id– El número de identificación de la pregunta.is_mandatory_optional– Indica si la pregunta es obligatoria u opcional para un formulario de consentimiento dado. Una pregunta puede formar parte de múltiples formularios de consentimiento, pero puede ser obligatoria en algunos y opcional en otros. Esa es la única razón para mantener esta columna aquí en lugar de tenerla en laquestionmesa.
En las siguientes tablas, analizaremos los formularios de consentimiento de etiquetas para puestos de trabajo individuales y registraremos las respuestas de los candidatos. Comencemos con el job_post_questionnaire table, que almacena información sobre qué formularios de consentimiento forman parte de un puesto de trabajo. Puede haber uno o más formularios de consentimiento etiquetados con una publicación de trabajo. Las columnas de esta tabla son:
id– La clave principal de la tabla.job_post_id– Indica con qué puesto de trabajo está etiquetado el formulario de consentimiento.consent_questionnaire_id– El formulario de consentimiento etiquetado en una publicación de trabajo.
A continuación, la appl_questionnaire_answer La tabla registra las respuestas individuales de cada pregunta del formulario de consentimiento tal como las completaron los solicitantes. Las columnas de esta tabla son:
job_post_activity_id– Una columna de clave externa referida desdejob_post_activitymesa. Almacena información sobre el candidato que ha respondido la pregunta.quest_consent_quesnnaire_map_id– Otra columna de clave externa referida desde elquest_consent_questionnaire_mapmesa. Almacena qué pregunta de qué formulario de consentimiento se está respondiendo.answer– La respuesta real del solicitante de empleo. Lo he mantenido como una columna CHAR(1) porque todas las preguntas en nuestro modelo pueden responderse como 'Sí' (respuesta ='S'), 'No' (respuesta ='N') o 'No aplicable' (respuesta ='X').
El nuevo y mejorado modelo de datos del portal de empleo en línea
Puede ver el modelo de datos completo a continuación.
¿Qué agregarías?
¿Se te ocurren otras características para agregar a nuestro portal de empleo en línea? Comparta sus opiniones en la sección de comentarios.