El concepto de buen o mal diseño es relativo. Al mismo tiempo, existen algunos estándares de programación que, en la mayoría de los casos, garantizan la eficacia, la mantenibilidad y la capacidad de prueba. Por ejemplo, en lenguajes orientados a objetos, este es el uso de encapsulación, herencia y polimorfismo. Hay un conjunto de patrones de diseño que en varios casos tienen un efecto positivo o negativo en el diseño de la aplicación según la situación. Por otro lado, hay opuestos, siguiendo lo que a veces conduce al diseño del problema.
Este diseño suele tener los siguientes indicadores (uno o varios a la vez):
- Rigidez (es difícil modificar el código, ya que un simple cambio afecta a muchos lugares);
- Inmovilidad (es complicado dividir el código en módulos que se pueden usar en otros programas);
- Viscosidad (es bastante difícil desarrollar o probar el código);
- Complejidad innecesaria (hay una funcionalidad no utilizada en el código);
- Repetición innecesaria (Copiar/Pegar);
- Pobre legibilidad (es difícil entender para qué está diseñado el código y mantenerlo);
- Fragilidad (es fácil romper la funcionalidad incluso con pequeños cambios).
Debe poder comprender y distinguir estas características para evitar un diseño problemático o predecir las posibles consecuencias de su uso. Estos indicadores se describen en el libro «Principios, patrones y prácticas ágiles en C#» de Robert Martin. Sin embargo, hay una breve descripción y no hay ejemplos de código en este artículo ni en otros artículos de revisión.
Vamos a eliminar este inconveniente centrándonos en cada característica.
Rigidez
Como se ha mencionado, un código rígido es difícil de modificar, incluso las cosas más pequeñas. Esto puede no ser un problema si el código no se cambia con frecuencia o en absoluto. Por lo tanto, el código resulta ser bastante bueno. Sin embargo, si es necesario modificar el código y es difícil hacerlo, se convierte en un problema, incluso si funciona.
Uno de los casos de rigidez más populares es especificar explícitamente los tipos de clase en lugar de usar abstracciones (interfaces, clases base, etc.). A continuación, puede encontrar un ejemplo del código:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Aquí la clase A depende mucho de la clase B. Por lo tanto, si en el futuro necesita usar otra clase en lugar de la clase B, esto requerirá cambiar la clase A y conducirá a que se vuelva a probar. Además, si la clase B afecta a otras clases, la situación se complicará mucho.
La solución es una abstracción que consiste en introducir la interfaz IComponent a través del constructor de la clase A. En este caso, ya no dependerá de la clase B en particular y dependerá solo de la interfaz IComponent. La clase В a su vez debe implementar la interfaz IComponent.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Proporcionemos un ejemplo específico. Suponga que hay un conjunto de clases que registran la información:ProductManager y Consumer. Su tarea es almacenar un producto en la base de datos y ordenarlo correspondientemente. Ambas clases registran eventos relevantes. Imagine que al principio hubo un inicio de sesión en un archivo. Para ello se utilizó la clase FileLogger. Además, las clases estaban ubicadas en diferentes módulos (ensamblajes).
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Si al principio fue suficiente usar solo el archivo, y luego se vuelve necesario iniciar sesión en otros repositorios, como una base de datos o un servicio de recopilación y almacenamiento de datos basado en la nube, entonces necesitaremos cambiar todas las clases en la lógica comercial. módulo (Módulo 2) que utiliza FileLogger. Después de todo, esto puede resultar difícil. Para resolver este problema, podemos introducir una interfaz abstracta para trabajar con el registrador, como se muestra a continuación.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} En este caso, al cambiar un tipo de registrador, basta con modificar el código del cliente (Main), que inicializa el registrador y lo agrega al constructor de ProductManager y Consumer. Por lo tanto, cerramos las clases de lógica empresarial a partir de la modificación del tipo de registrador según sea necesario.
Además de los enlaces directos a las clases utilizadas, podemos monitorear la rigidez en otras variantes que pueden generar dificultades al modificar el código. Puede haber un conjunto infinito de ellos. Sin embargo, intentaremos dar otro ejemplo. Suponga que hay un código que muestra el área de un patrón geométrico en la consola.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Como puede ver, al agregar un nuevo patrón, tendremos que cambiar los métodos de la clase ShapeHelper. Una de las opciones es pasar el algoritmo de renderizado en las clases de patrones geométricos (Rectángulo y Círculo), como se muestra a continuación. De esta forma, aislaremos la lógica relevante en las clases correspondientes reduciendo así la responsabilidad de la clase ShapeHelper antes de mostrar información en la consola.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} Como resultado, en realidad cerramos la clase ShapeHelper para cambios que agregan nuevos tipos de patrones mediante herencia y polimorfismo.
Inmovilidad
Podemos monitorear la inmovilidad al dividir el código en módulos reutilizables. Como resultado, el proyecto puede dejar de desarrollarse y ser competitivo.
Como ejemplo, consideraremos un programa de escritorio, cuyo código completo se implementa en el archivo de aplicación ejecutable (.exe) y ha sido diseñado para que la lógica comercial no se construya en módulos o clases separados. Posteriormente, el desarrollador se ha enfrentado a los siguientes requisitos comerciales:
- Para cambiar la interfaz de usuario convirtiéndola en una aplicación web;
- Publicar la funcionalidad del programa como un conjunto de servicios web disponibles para clientes de terceros para ser utilizados en sus propias aplicaciones.
En este caso, estos requisitos son difíciles de cumplir, ya que todo el código se encuentra en el módulo ejecutable.
La siguiente imagen muestra un ejemplo de un diseño inmóvil en contraste con el que no tiene este indicador. Están separados por una línea punteada. Como puede ver, la asignación del código en módulos reutilizables (Logic), así como la publicación de la funcionalidad a nivel de servicios Web, permiten utilizarlo en varias aplicaciones cliente (App), lo que es un beneficio indudable.
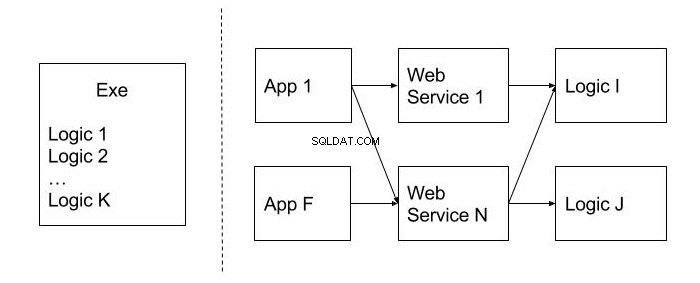
La inmovilidad también se puede llamar un diseño monolítico. Es difícil dividirlo en unidades más pequeñas y útiles del código. ¿Cómo podemos evadir este problema? En la etapa de diseño, es mejor pensar qué tan probable es usar esta o aquella función en otros sistemas. Es mejor colocar el código que se espera reutilizar en módulos y clases separados.
Viscosidad
Hay dos tipos:
- Viscosidad de revelado
- Viscosidad ambiental
Podemos ver la viscosidad de desarrollo mientras tratamos de seguir el diseño de la aplicación seleccionada. Esto puede suceder cuando un programador necesita cumplir con demasiados requisitos mientras existe una forma más fácil de desarrollo. Además, la viscosidad de desarrollo se puede ver cuando el proceso de ensamblaje, implementación y prueba no es efectivo.
Como un ejemplo simple, podemos considerar el trabajo con constantes que deben colocarse (por diseño) en un módulo separado (Módulo 1) para ser utilizado por otros componentes (Módulo 2 y Módulo 3).
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Si por alguna razón el proceso de ensamblaje toma mucho tiempo, será difícil para los desarrolladores esperar hasta que finalice. Además, cabe señalar que el módulo constante contiene entidades mixtas que pertenecen a diferentes partes de la lógica empresarial (módulos financieros y de marketing). Por lo tanto, el módulo constante se puede cambiar con bastante frecuencia por razones que son independientes entre sí, lo que puede generar problemas adicionales, como la sincronización de los cambios.
Todo esto ralentiza el proceso de desarrollo y puede estresar a los programadores. Las variantes del diseño menos viscoso serían crear módulos de constantes separados, por uno para el módulo correspondiente de lógica de negocios, o pasar constantes al lugar correcto sin tomar un módulo separado para ellos.
Un ejemplo de la viscosidad del entorno puede ser el desarrollo y la prueba de la aplicación en la máquina virtual del cliente remoto. A veces, este flujo de trabajo se vuelve insoportable debido a una conexión a Internet lenta, por lo que el desarrollador puede ignorar sistemáticamente las pruebas de integración del código escrito, lo que eventualmente puede generar errores en el lado del cliente al usar esta función.
Complejidad innecesaria
En este caso, el diseño tiene una funcionalidad realmente no utilizada. Este hecho puede complicar el soporte y mantenimiento del programa, así como aumentar el tiempo de desarrollo y pruebas. Por ejemplo, considere el programa que requiere leer algunos datos de la base de datos. Para ello se creó el componente DataManager, que se utiliza en otro componente.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Si el desarrollador agrega un nuevo método a DataManager para escribir datos en la base de datos (WriteData), que es poco probable que se use en el futuro, también será una complejidad innecesaria.
Otro ejemplo es una interfaz a todos los efectos. Por ejemplo, vamos a considerar una interfaz con el único método Process que acepta un objeto del tipo cadena.
interface IProcessor
{
void Process(string message);
} Si la tarea fuera procesar cierto tipo de mensaje con una estructura bien definida, entonces sería más fácil crear una interfaz estrictamente tipificada, en lugar de hacer que los desarrolladores deserialicen esta cadena en un tipo de mensaje particular cada vez.
El uso excesivo de patrones de diseño en los casos en que esto no es necesario en absoluto también puede conducir al diseño de viscosidad.
¿Por qué perder el tiempo escribiendo un código potencialmente no utilizado? A veces, el control de calidad debe probar este código, porque en realidad está publicado y está abierto para que lo usen clientes de terceros. Esto también pospone el tiempo de lanzamiento. Solo vale la pena incluir una característica para el futuro si su posible beneficio supera los costos de su desarrollo y prueba.
Repetición innecesaria
Quizás, la mayoría de los desarrolladores se han enfrentado o se encontrarán con esta característica, que consiste en copiar varias veces la misma lógica o el mismo código. La principal amenaza es la vulnerabilidad de este código al modificarlo:al arreglar algo en un lugar, puede olvidarse de hacerlo en otro. Además, lleva más tiempo realizar cambios en comparación con la situación en la que el código no contiene esta función.
La repetición innecesaria puede deberse a la negligencia de los desarrolladores, así como a la rigidez/fragilidad del diseño cuando es mucho más difícil y arriesgado no repetir el código que hacer esto. Sin embargo, en cualquier caso, la repetibilidad no es una buena idea, y es necesario mejorar constantemente el código, pasando partes reutilizables a métodos y clases comunes.
Pobre legibilidad
Puede monitorear esta función cuando es difícil leer un código y comprender para qué se creó. Los motivos de una mala legibilidad pueden ser el incumplimiento de los requisitos para la ejecución del código (sintaxis, variables, clases), una lógica de implementación complicada, etc.
A continuación puede encontrar el ejemplo del código difícil de leer, que implementa el método con la variable booleana.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Aquí, podemos esbozar varias cuestiones. En primer lugar, los nombres de métodos y variables no se ajustan a las convenciones generalmente aceptadas. En segundo lugar, la implementación del método no es la mejor.
Tal vez valga la pena tomar un valor booleano, en lugar de una cadena. Sin embargo, es mejor convertirlo a un valor booleano al comienzo del método, en lugar de usar el método para determinar la longitud de la cadena.
En tercer lugar, el texto de la excepción no corresponde al estilo oficial. Al leer tales textos, puede tener la sensación de que el código fue creado por un aficionado (aún así, puede haber un punto en cuestión). El método podría reescribirse de la siguiente manera si toma un valor booleano:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Aquí hay otro ejemplo de refactorización si aún necesita tomar una cadena:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Se recomienda realizar la refactorización con el código difícil de leer, por ejemplo, cuando su mantenimiento y clonación generan múltiples errores.
Fragilidad
La fragilidad de un programa significa que puede bloquearse fácilmente cuando se modifica. Hay dos tipos de bloqueos:errores de compilación y errores de tiempo de ejecución. Los primeros pueden ser un reverso de la rigidez. Estos últimos son los más peligrosos ya que ocurren del lado del cliente. Por lo tanto, son un indicador de la fragilidad.
Sin duda, el indicador es relativo. Alguien corrige el código con mucho cuidado y la posibilidad de que se cuelgue es bastante baja, mientras que otros lo hacen a toda prisa y sin cuidado. Aún así, un código diferente con los mismos usuarios puede causar una cantidad diferente de errores. Probablemente, podemos decir que cuanto más difícil es entender el código y confiar en el tiempo de ejecución del programa, en lugar de en la etapa de compilación, más frágil es el código.
Además, la funcionalidad que no se va a modificar a menudo falla. Puede sufrir del alto acoplamiento de la lógica de diferentes componentes.
Considere el ejemplo particular. Aquí la lógica de autorización de usuario con un determinado rol (definido como el parámetro rodado) para acceder a un recurso en particular (definido como resourceUri) se encuentra en el método estático.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Como puede ver, la lógica es complicada. Es obvio que agregar nuevos roles y recursos lo romperá fácilmente. Como resultado, un determinado rol puede obtener o perder el acceso a un recurso. La creación de la clase de recursos que almacena internamente el identificador de recursos y la lista de roles admitidos, como se muestra a continuación, reduciría la fragilidad.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} En este caso, para agregar nuevos recursos y roles, no es necesario modificar el código lógico de autorización en absoluto, es decir, en realidad no hay nada que romper.
¿Qué puede ayudar a detectar errores de tiempo de ejecución? La respuesta es pruebas manuales, automáticas y unitarias. Cuanto mejor esté organizado el proceso de prueba, más probable es que el código frágil ocurra en el lado del cliente.
A menudo, la fragilidad es el reverso de otros identificadores de mal diseño, como la rigidez, la mala legibilidad y la repetición innecesaria.
Conclusión
Hemos tratado de esbozar y describir los principales identificadores del mal diseño. Algunos de ellos son interdependientes. Debe comprender que el problema del diseño no siempre conduce inevitablemente a dificultades. Solo apunta que pueden ocurrir. Cuanto menos se supervisen estos identificadores, menor será la probabilidad.