La replicación juega un papel crucial en el mantenimiento de una alta disponibilidad. Los servidores pueden fallar, es posible que sea necesario actualizar el sistema operativo o el software de la base de datos. Esto significa reorganizar las funciones del servidor y mover los enlaces de replicación, manteniendo la coherencia de los datos en todas las bases de datos. Se requerirán cambios de topología, y hay diferentes formas de realizarlos.
Promoción de un servidor en espera
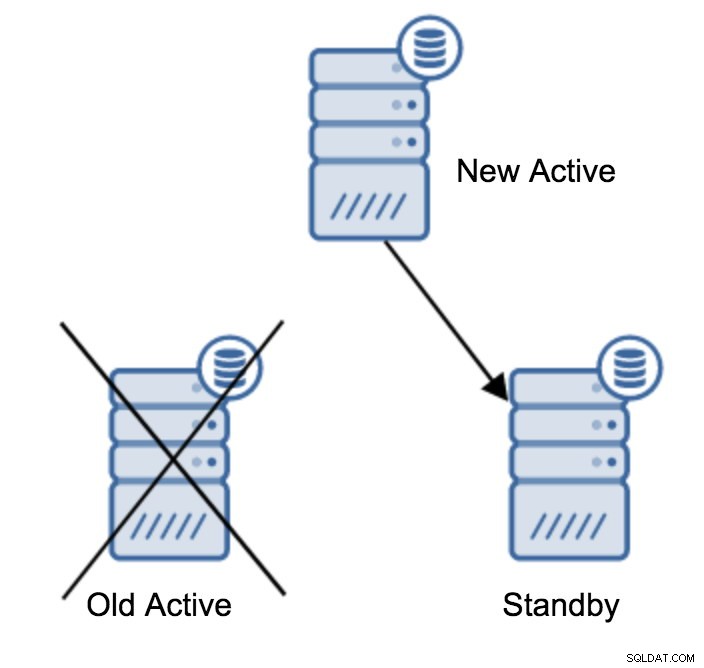
Podría decirse que esta es la operación más común que deberá realizar. Hay varias razones, por ejemplo, el mantenimiento de la base de datos en el servidor principal que afectaría la carga de trabajo de manera inaceptable. Podría haber un tiempo de inactividad planificado debido a algunas operaciones de hardware. El bloqueo del servidor principal que lo hace inaccesible para la aplicación. Todas estas son razones para realizar una conmutación por error, ya sea planificada o no. En todos los casos, deberá promocionar uno de los servidores en espera para que se convierta en un nuevo servidor principal.
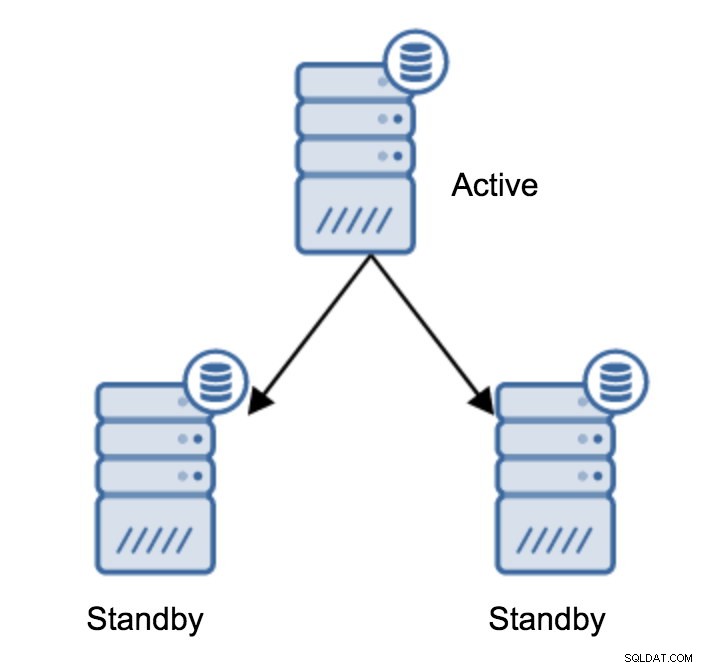
Para promocionar un servidor en espera, debe ejecutar:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
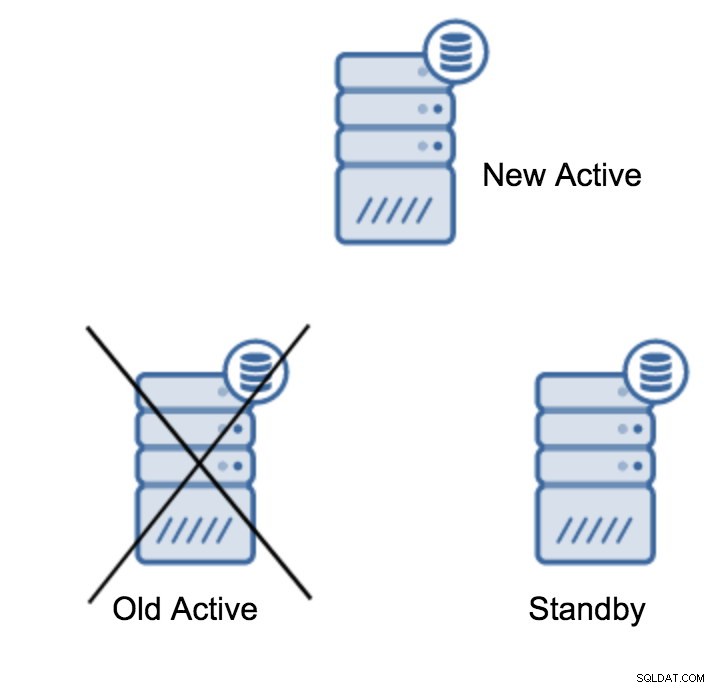
server promotedEs fácil ejecutar este comando, pero primero, asegúrese de evitar cualquier pérdida de datos. Si estamos hablando de un escenario de "servidor principal inactivo", es posible que no tenga demasiadas opciones. Si se trata de un mantenimiento planificado, es posible prepararse para ello. Debe detener el tráfico en el servidor principal y luego verificar que el servidor en espera recibió y aplicó todos los datos. Esto se puede hacer en el servidor en espera, utilizando la consulta de la siguiente manera:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
(1 row)Una vez que todo esté bien, puede detener el antiguo servidor principal y promover el servidor en espera.
Descargue el documento técnico hoy Gestión y automatización de PostgreSQL con ClusterControl Obtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoVolver a esclavizar un servidor en espera de un nuevo servidor principal
Es posible que tenga más de un servidor en espera trabajando como esclavo de su servidor principal. Después de todo, los servidores en espera son útiles para descargar el tráfico de solo lectura. Después de promover un servidor en espera a un nuevo servidor principal, debe hacer algo con respecto a los servidores en espera restantes que todavía están conectados (o que están intentando conectarse) al antiguo servidor principal. Desafortunadamente, no puede simplemente cambiar el archivo recovery.conf y conectarlo al nuevo servidor principal. Para conectarlos, primero debe reconstruirlos. Hay dos métodos que puede probar aquí:copia de seguridad base estándar o pg_rewind.
No entraremos en detalles sobre cómo realizar una copia de seguridad base; lo cubrimos en nuestra publicación de blog anterior, que se centró en realizar copias de seguridad y restaurarlas en PostgreSQL. Si usa ClusterControl, también puede usarlo para crear una copia de seguridad base:
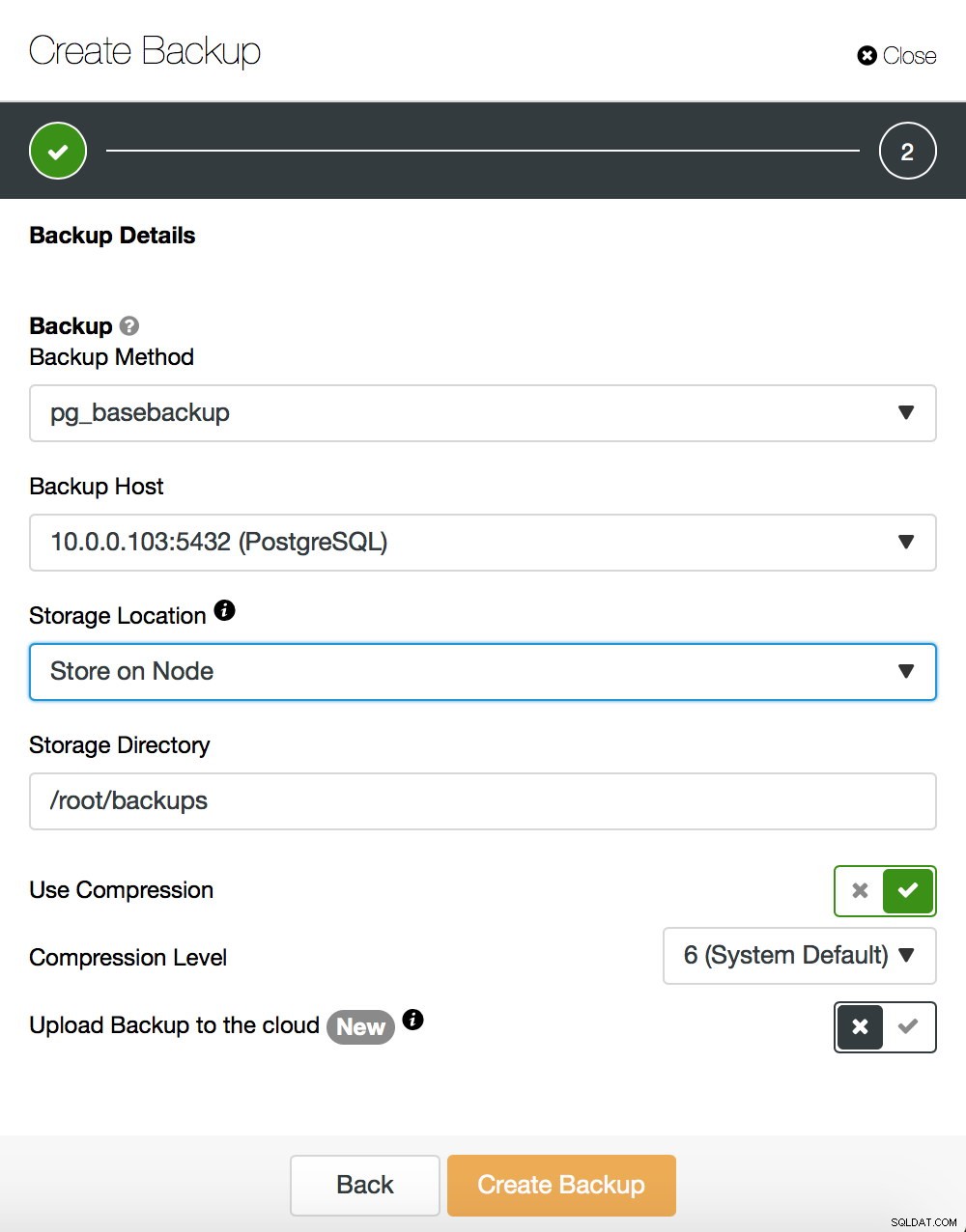
Por otro lado, digamos un par de palabras sobre pg_rewind. La principal diferencia entre ambos métodos es que la copia de seguridad base crea una copia completa del conjunto de datos. Si hablamos de conjuntos de datos pequeños, puede estar bien, pero para conjuntos de datos con un tamaño de cientos de gigabytes (o incluso más grandes), puede convertirse rápidamente en un problema. Al final, desea tener sus servidores en espera en funcionamiento rápidamente, para descargar su servidor activo y tener otro en espera para la conmutación por error, en caso de que surja la necesidad. Pg_rewind funciona de manera diferente:copia solo los bloques que se han modificado. En lugar de copiar todo, copia solo los cambios, lo que acelera el proceso de manera significativa. Supongamos que su nuevo maestro tiene una IP de 10.0.0.103. Así es como puedes ejecutar pg_rewind. Tenga en cuenta que debe detener el servidor de destino; PostgreSQL no puede estar ejecutándose allí.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Esto hará una prueba , probando el proceso pero sin hacer ningún cambio. Si todo está bien, todo lo que tendrá que hacer será ejecutarlo nuevamente, esta vez sin el parámetro '--dry-run'. Una vez hecho esto, el último paso restante será crear un archivo recovery.conf, que apuntará al nuevo maestro. Puede verse así:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Ahora está listo para iniciar su servidor en espera y se replicará en el nuevo servidor activo.
Replicación encadenada
Existen numerosas razones por las que es posible que desee crear una replicación encadenada, aunque normalmente se hace para reducir la carga en el servidor principal. Servir el WAL a los servidores en espera agrega algunos gastos generales. No es un gran problema si tiene uno o dos en espera, pero si estamos hablando de una gran cantidad de servidores en espera, esto puede convertirse en un problema. Por ejemplo, podemos minimizar la cantidad de servidores en espera que se replican directamente desde el activo creando una topología como la siguiente:
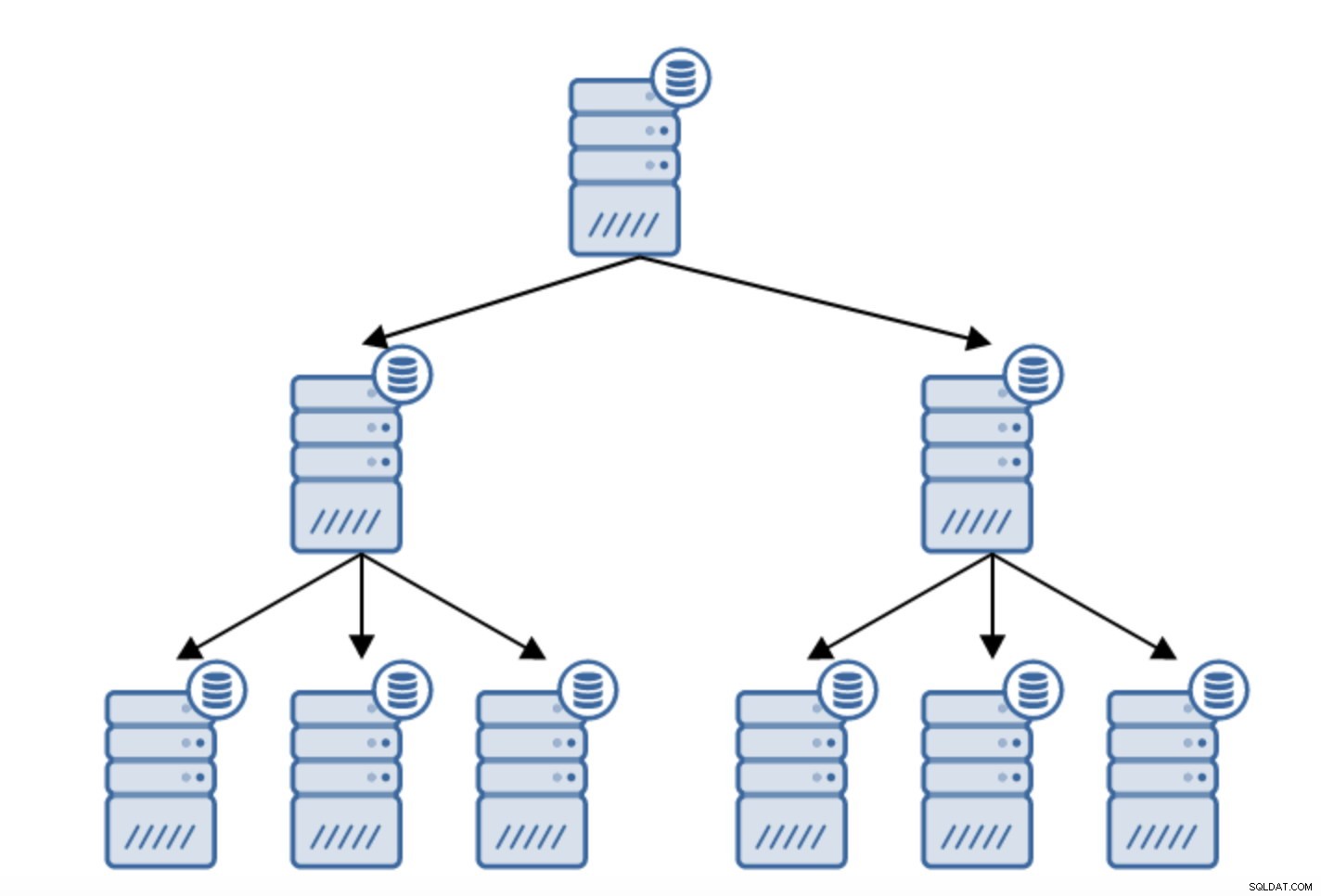
El paso de una topología de dos servidores en espera a una replicación encadenada es bastante sencillo.
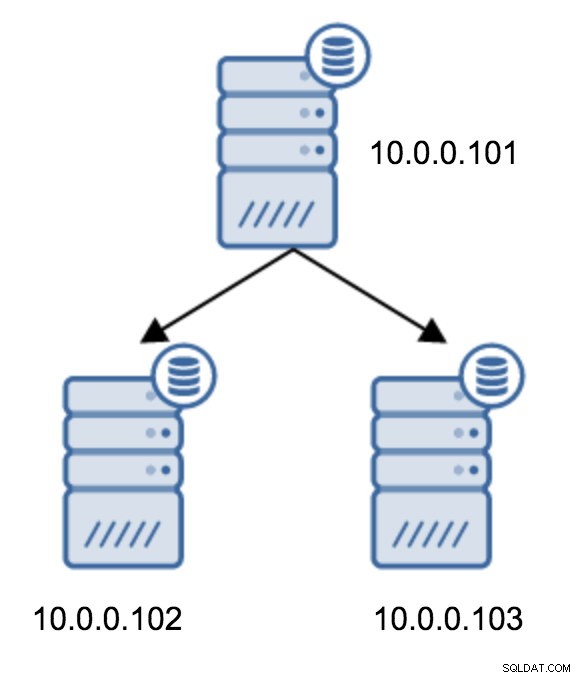
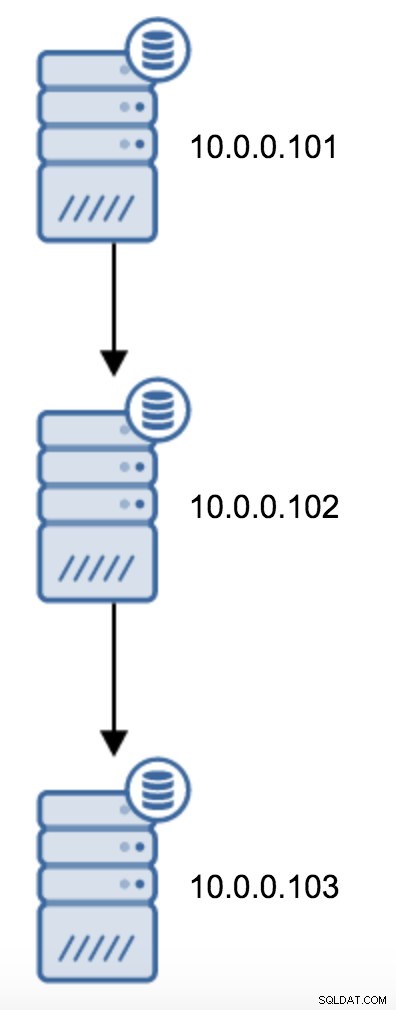
Deberá modificar recovery.conf en 10.0.0.103, apuntarlo hacia 10.0.0.102 y luego reiniciar PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Después de reiniciar, 10.0.0.103 debería comenzar a aplicar las actualizaciones de WAL.
Estos son algunos casos comunes de cambios de topología. Un tema que no se discutió, pero que sigue siendo importante, es el impacto de estos cambios en las aplicaciones. Cubriremos eso en una publicación separada, así como también cómo hacer que estos cambios de topología sean transparentes para las aplicaciones.