Una capa de proxy puede ser muy útil para aumentar la disponibilidad de su base de datos. Puede reducir la cantidad de código en el lado de la aplicación para manejar las fallas de la base de datos y los cambios en la topología de replicación. En esta publicación de blog, discutiremos cómo configurar un HAProxy para que funcione sobre PostgreSQL.
Lo primero es lo primero:HAProxy funciona con bases de datos como un proxy de capa de red. No hay comprensión de la topología subyacente, a veces compleja. Todo lo que hace HAProxy es enviar paquetes por turnos a backends definidos. No inspecciona paquetes ni entiende el protocolo en el que las aplicaciones se comunican con PostgreSQL. Como resultado, no hay forma de que HAProxy implemente la división de lectura/escritura en un solo puerto; requeriría analizar las consultas. Siempre que su aplicación pueda dividir las lecturas de las escrituras y enviarlas a diferentes IP o puertos, puede implementar la división R/W usando dos backends. Echemos un vistazo a cómo se puede hacer.
Configuración de HAProxy
A continuación puede encontrar un ejemplo de dos backends de PostgreSQL configurados en HAProxy.
listen haproxy_10.0.0.101_3307_rw
bind *:3307
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string master\ is\ running
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 check
listen haproxy_10.0.0.101_3308_ro
bind *:3308
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running.
balance leastconn
option tcp-check
option allbackups
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server 10.0.0.101 10.0.0.101:5432 check
server 10.0.0.102 10.0.0.102:5432 check
server 10.0.0.103 10.0.0.103:5432 checkComo podemos ver, usan los puertos 3307 para escritura y 3308 para lectura. En esta configuración hay tres servidores:una réplica activa y dos en espera. Lo que es importante, tcp-check se usa para rastrear la salud de los nodos. HAProxy se conectará al puerto 9201 y espera ver una cadena devuelta. Los miembros sanos del backend devolverán el contenido esperado, aquellos que no devuelvan la cadena se marcarán como no disponibles.
Configuración de Xinetd
Mientras HAProxy verifica el puerto 9201, algo tiene que escucharlo. Podemos usar xinetd para escuchar allí y ejecutar algunos scripts para nosotros. La configuración de ejemplo de dicho servicio puede verse así:
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITED
}Debes asegurarte de agregar la línea:
postgreschk 9201/tcpa /etc/services.
Xinetd inicia un script postgreschk, que tiene contenidos como el siguiente:
#!/bin/bash
#
# This script checks if a PostgreSQL server is healthy running on localhost. It will
# return:
# "HTTP/1.x 200 OK\r" (if postgres is running smoothly)
# - OR -
# "HTTP/1.x 500 Internal Server Error\r" (else)
#
# The purpose of this script is make haproxy capable of monitoring PostgreSQL properly
#
export PGHOST='10.0.0.101'
export PGUSER='someuser'
export PGPASSWORD='somepassword'
export PGPORT='5432'
export PGDATABASE='postgres'
export PGCONNECT_TIMEOUT=10
FORCE_FAIL="/dev/shm/proxyoff"
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"
return_ok()
{
echo -e "HTTP/1.1 200 OK\r\n"
echo -e "Content-Type: text/html\r\n"
if [ "$1x" == "masterx" ]; then
echo -e "Content-Length: 56\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL master is running.</body></html>\r\n"
elif [ "$1x" == "slavex" ]; then
echo -e "Content-Length: 55\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL slave is running.</body></html>\r\n"
else
echo -e "Content-Length: 49\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is running.</body></html>\r\n"
fi
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 0
}
return_fail()
{
echo -e "HTTP/1.1 503 Service Unavailable\r\n"
echo -e "Content-Type: text/html\r\n"
echo -e "Content-Length: 48\r\n"
echo -e "\r\n"
echo -e "<html><body>PostgreSQL is *down*.</body></html>\r\n"
echo -e "\r\n"
unset PGUSER
unset PGPASSWORD
exit 1
}
if [ -f "$FORCE_FAIL" ]; then
return_fail;
fi
# check if in recovery mode (that means it is a 'slave')
SLAVE=$(psql -qt -c "$SLAVE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $SLAVE | egrep -i "(t|true|on|1)" 2>/dev/null >/dev/null; then
return_ok "slave"
fi
# check if writable (then we consider it as a 'master')
READONLY=$(psql -qt -c "$WRITABLE_CHECK" 2>/dev/null)
if [ $? -ne 0 ]; then
return_fail;
elif echo $READONLY | egrep -i "(f|false|off|0)" 2>/dev/null >/dev/null; then
return_ok "master"
fi
return_ok "none";La lógica del script es la siguiente. Hay dos consultas que se utilizan para detectar el estado del nodo.
SLAVE_CHECK="SELECT pg_is_in_recovery()"
WRITABLE_CHECK="SHOW transaction_read_only"El primero verifica si PostgreSQL está en recuperación:será "falso" para el servidor activo y "verdadero" para los servidores en espera. El segundo verifica si PostgreSQL está en modo de solo lectura. El servidor activo volverá a estar "apagado", mientras que los servidores en espera volverán a estar "encendidos". Según los resultados, el script llama a la función return_ok() con un parámetro correcto ('maestro' o 'esclavo', según lo que se haya detectado). Si las consultas fallan, se ejecutará una función 'return_fail'.
La función Return_ok devuelve una cadena basada en el argumento que se le pasó. Si el host es un servidor activo, el script devolverá "El maestro de PostgreSQL se está ejecutando". Si es un modo de espera, la cadena devuelta será:"El esclavo de PostgreSQL se está ejecutando". Si el estado no está claro, devolverá:"PostgreSQL se está ejecutando". Aquí es donde termina el bucle. HAProxy comprueba el estado conectándose a xinetd. Este último inicia un script, que luego devuelve una cadena que HAProxy analiza.
Como recordará, HAProxy espera las siguientes cadenas:
tcp-check expect string master\ is\ runningpara el backend de escritura y
tcp-check expect string is\ running.para el backend de solo lectura. Esto hace que el servidor activo sea el único host disponible en el backend de escritura, mientras que en el backend de lectura se pueden usar tanto servidores activos como en espera.
PostgreSQL y HAProxy en ClusterControl
La configuración anterior no es compleja, pero lleva algún tiempo configurarla. Se puede usar ClusterControl para configurar todo esto por usted.
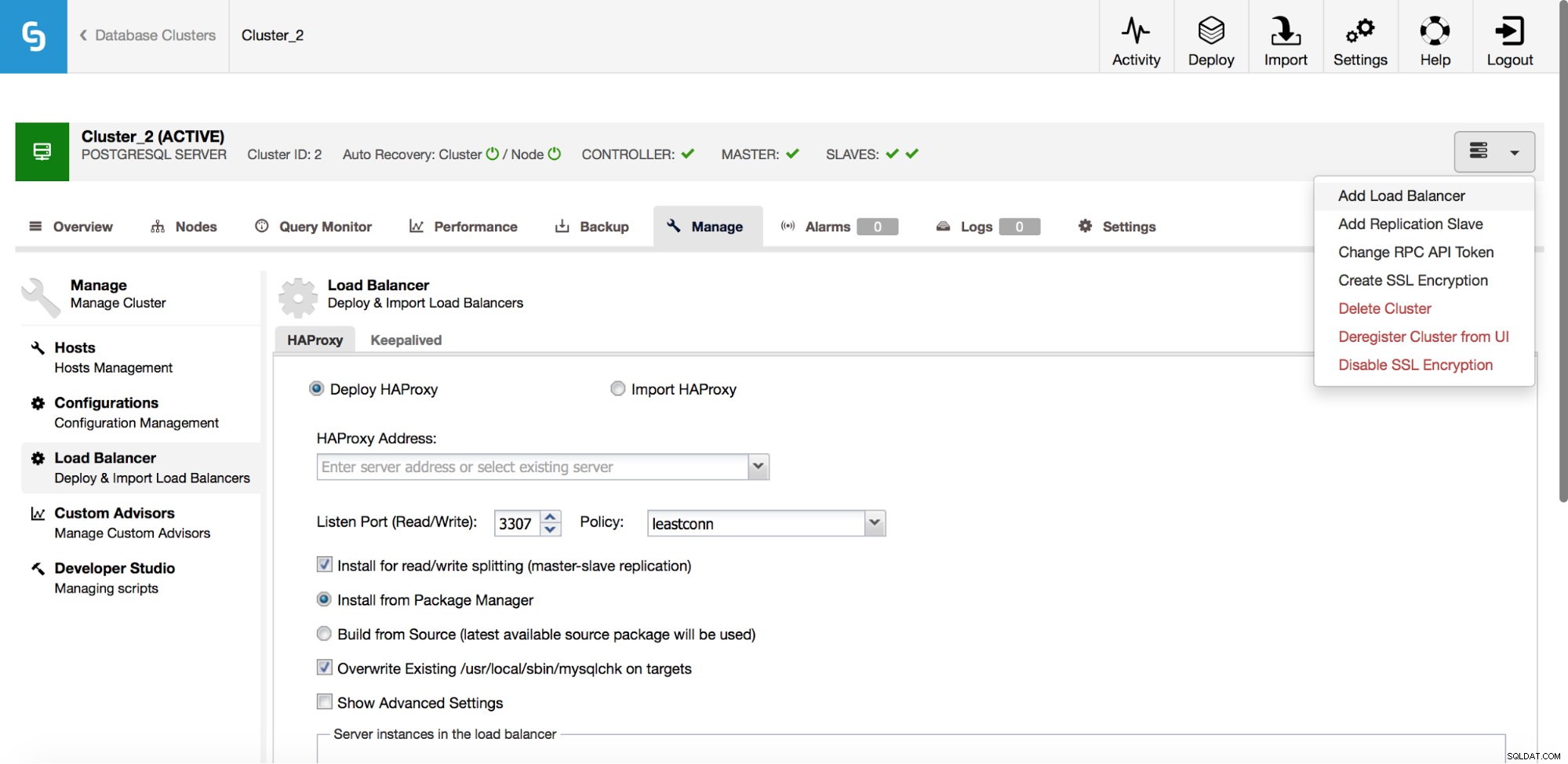
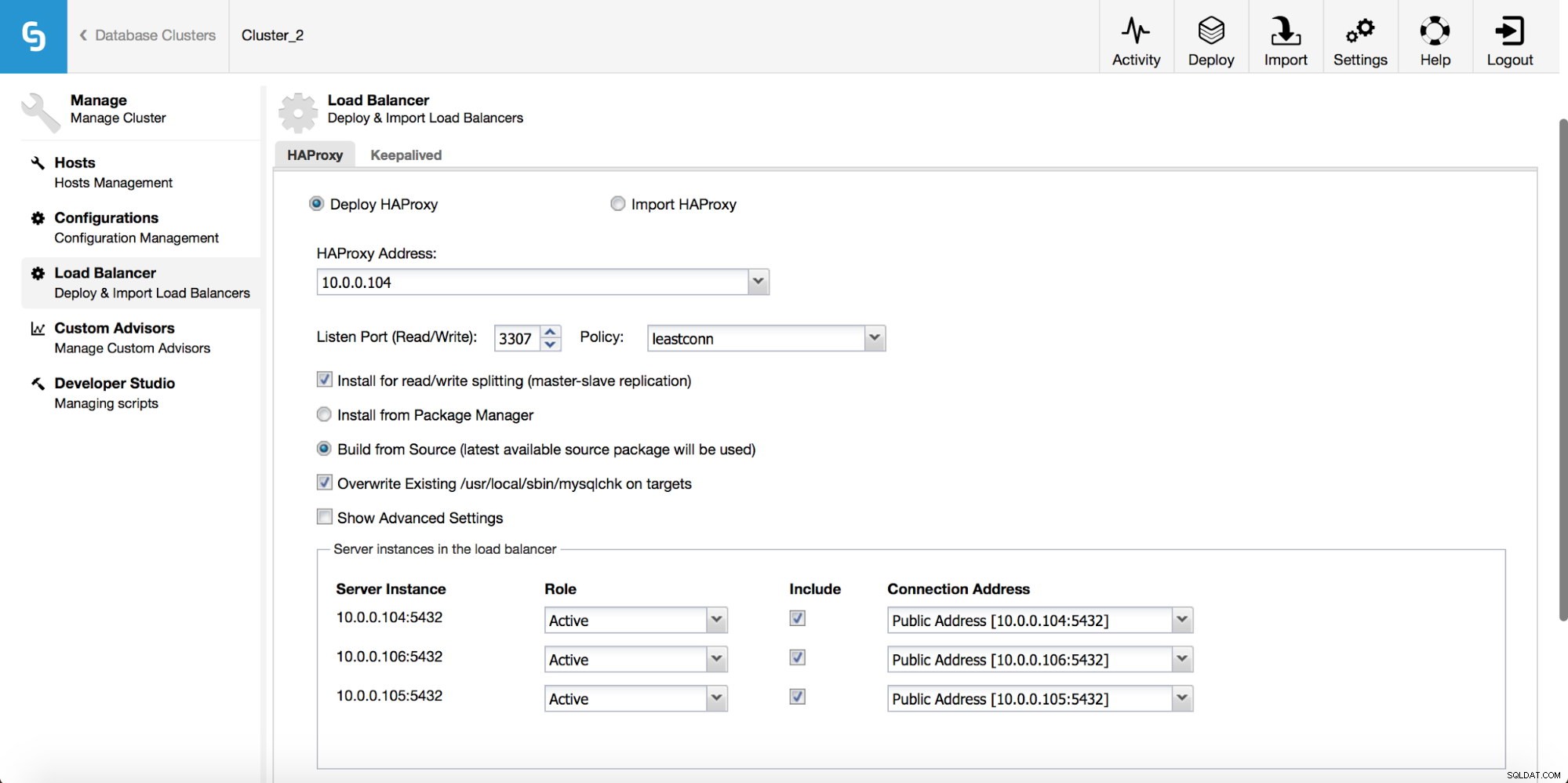
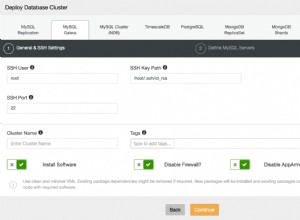
En el menú desplegable del trabajo del clúster, tiene la opción de agregar un balanceador de carga. Luego aparece una opción para implementar HAProxy. Debe completar dónde desea instalarlo y tomar algunas decisiones:desde los repositorios que ha configurado en el host o la última versión, compilada a partir del código fuente. También deberá configurar qué nodos del clúster desea agregar a HAProxy.
Una vez que se implementa la instancia de HAProxy, puede acceder a algunas estadísticas en la pestaña "Nodos":
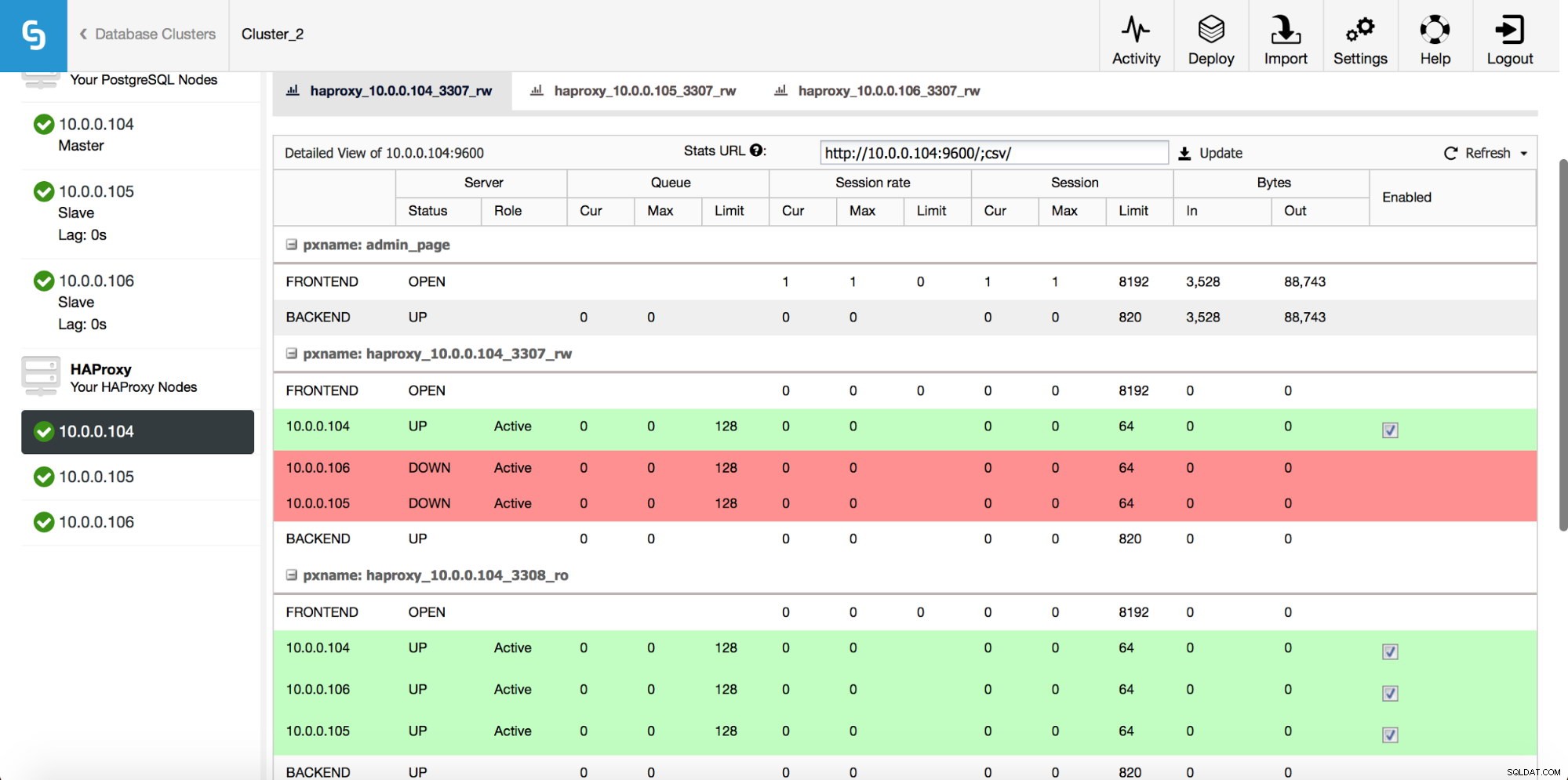
Como podemos ver, para el backend R/W, solo un host (servidor activo) está marcado como activo. Para el backend de solo lectura, todos los nodos están activos.
Descargue el documento técnico hoy Administración y automatización de PostgreSQL con ClusterControlObtenga información sobre lo que necesita saber para implementar, monitorear, administrar y escalar PostgreSQLDescargar el documento técnicoMantener vivo
HAProxy se ubicará entre sus aplicaciones y las instancias de la base de datos, por lo que desempeñará un papel central. Desafortunadamente, también puede convertirse en un punto único de falla; si falla, no habrá ruta a las bases de datos. Para evitar tal situación, puede implementar varias instancias de HAProxy. Pero entonces la pregunta es:cómo decidir a qué host proxy conectarse. Si implementó HAProxy desde ClusterControl, es tan simple como ejecutar otro trabajo de "Agregar balanceador de carga", esta vez implementando Keepalived.
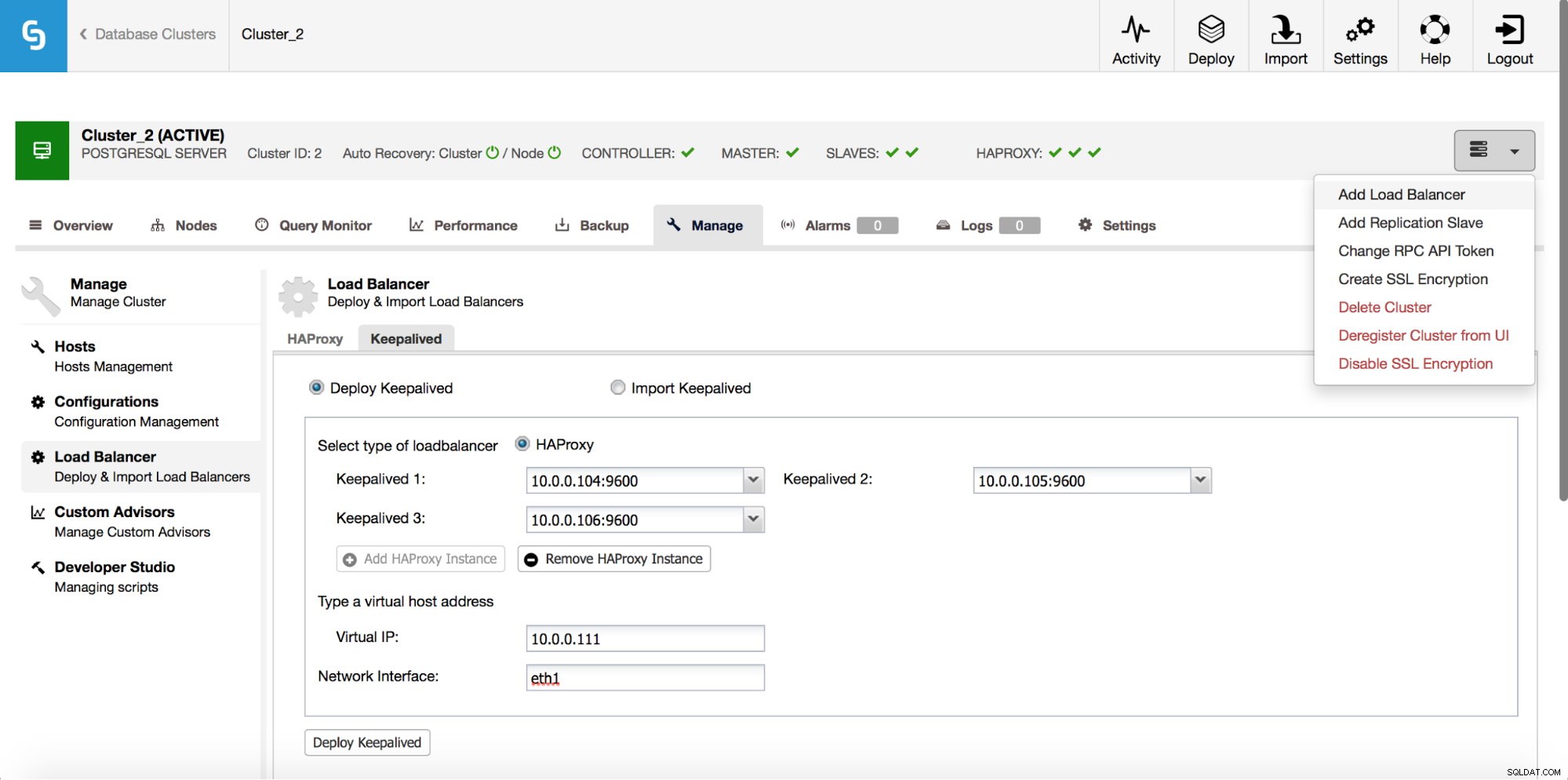
Como podemos ver en la captura de pantalla anterior, puede seleccionar hasta tres hosts HAProxy y Keepalived se implementará encima de ellos, monitoreando su estado. A uno de ellos se le asignará una IP Virtual (VIP). Su aplicación debe usar este VIP para conectarse a la base de datos. Si el HAProxy "activo" deja de estar disponible, el VIP se moverá a otro host.
Como hemos visto, es bastante fácil implementar una pila completa de alta disponibilidad para PostgreSQL. Pruébelo y háganos saber si tiene algún comentario.