Atrás quedaron los días en que una base de datos se implementaba como un solo nodo o instancia:un servidor potente e independiente que tenía la tarea de manejar todas las solicitudes a la base de datos. El escalado vertical era el camino a seguir:reemplazar el servidor por otro, incluso más potente. Durante estos tiempos, uno realmente no tenía que preocuparse por el rendimiento de la red. Mientras llegaban las solicitudes, todo estaba bien.
Pero hoy en día, las bases de datos se construyen como clústeres con nodos interconectados a través de una red. No siempre es una red local rápida. Dado que las empresas alcanzan una escala global, la infraestructura de la base de datos también debe extenderse por todo el mundo para permanecer cerca de los clientes y reducir la latencia. Viene con desafíos adicionales que debemos enfrentar al diseñar un entorno de base de datos de alta disponibilidad. En esta publicación de blog, analizaremos los problemas de red que puede enfrentar y le proporcionaremos algunas sugerencias sobre cómo solucionarlos.
Dos opciones principales para MySQL o MariaDB HA
Cubrimos este tema en particular bastante extensamente en uno de los documentos técnicos, pero veamos las dos formas principales de crear alta disponibilidad para MySQL y MariaDB.
Clúster Galera
Galera Cluster es una tecnología de clúster virtualmente síncrona y sin uso compartido para MySQL. Permite crear configuraciones de múltiples escritores que pueden abarcar todo el mundo. Galera prospera en entornos de baja latencia, pero también se puede configurar para funcionar con conexiones WAN largas. Galera tiene un mecanismo de quórum integrado que garantiza que los datos no se verán comprometidos en caso de partición de la red de algunos de los nodos.
Replicación MySQL
La replicación de MySQL puede ser asincrónica o semisíncrona. Ambos están diseñados para construir clústeres de replicación a gran escala. Como en cualquier otra configuración de replicación maestro-esclavo o primario-secundario, solo puede haber un escritor, el maestro. Otros nodos, los esclavos, se utilizan con fines de conmutación por error, ya que contienen la copia del conjunto de datos del máser. Los esclavos también se pueden usar para leer los datos y descargar parte de la carga de trabajo del maestro.
Ambas soluciones tienen sus propios límites y características, ambas adolecen de diferentes problemas. Ambos pueden verse afectados por conexiones de red inestables. Echemos un vistazo a esas limitaciones y cómo podemos diseñar el entorno para minimizar el impacto de una infraestructura de red inestable.
Clúster de Galera:problemas de red
Primero, echemos un vistazo a Galera Cluster. Como comentamos, funciona mejor en un entorno de baja latencia. Uno de los principales problemas relacionados con la latencia en Galera es la forma en que Galera maneja las escrituras. No entraremos en todos los detalles en este blog, sino más información en nuestro tutorial de Galera Cluster para MySQL. La conclusión es que, debido al proceso de certificación para escrituras, en el que todos los nodos del clúster deben ponerse de acuerdo sobre si la escritura se puede aplicar o no, su rendimiento de escritura para una sola fila está estrictamente limitado por el tiempo de ida y vuelta de la red entre el escritor nodo y el nodo más lejano. Siempre que la latencia sea aceptable y no tenga demasiados puntos de acceso en sus datos, las configuraciones de WAN pueden funcionar bien. El problema comienza cuando la latencia de la red aumenta de vez en cuando. Las escrituras tardarán 3 o 4 veces más de lo normal y, como resultado, las bases de datos pueden comenzar a sobrecargarse con escrituras de ejecución prolongada.
Una de las grandes características de Galera Cluster es su capacidad para detectar el estado del clúster y reaccionar ante la partición de la red. Si no se puede acceder a un nodo del clúster, será expulsado del clúster y no podrá realizar ninguna escritura. Esto es crucial para mantener la integridad de los datos durante el tiempo en que se divide el clúster:solo la mayoría del clúster aceptará escrituras. La minoría se quejará. Para manejar esto, Galera presenta una amplia gama de controles y tiempos de espera configurables para evitar alertas falsas en problemas de red muy transitorios. Desafortunadamente, si la red no es confiable, Galera Cluster no podrá funcionar correctamente:los nodos comenzarán a abandonar el clúster, únase a él más tarde. Será especialmente problemático cuando tengamos Galera Cluster que se extienda a través de WAN:las piezas separadas del clúster pueden desaparecer aleatoriamente si la red de interconexión no funciona correctamente.
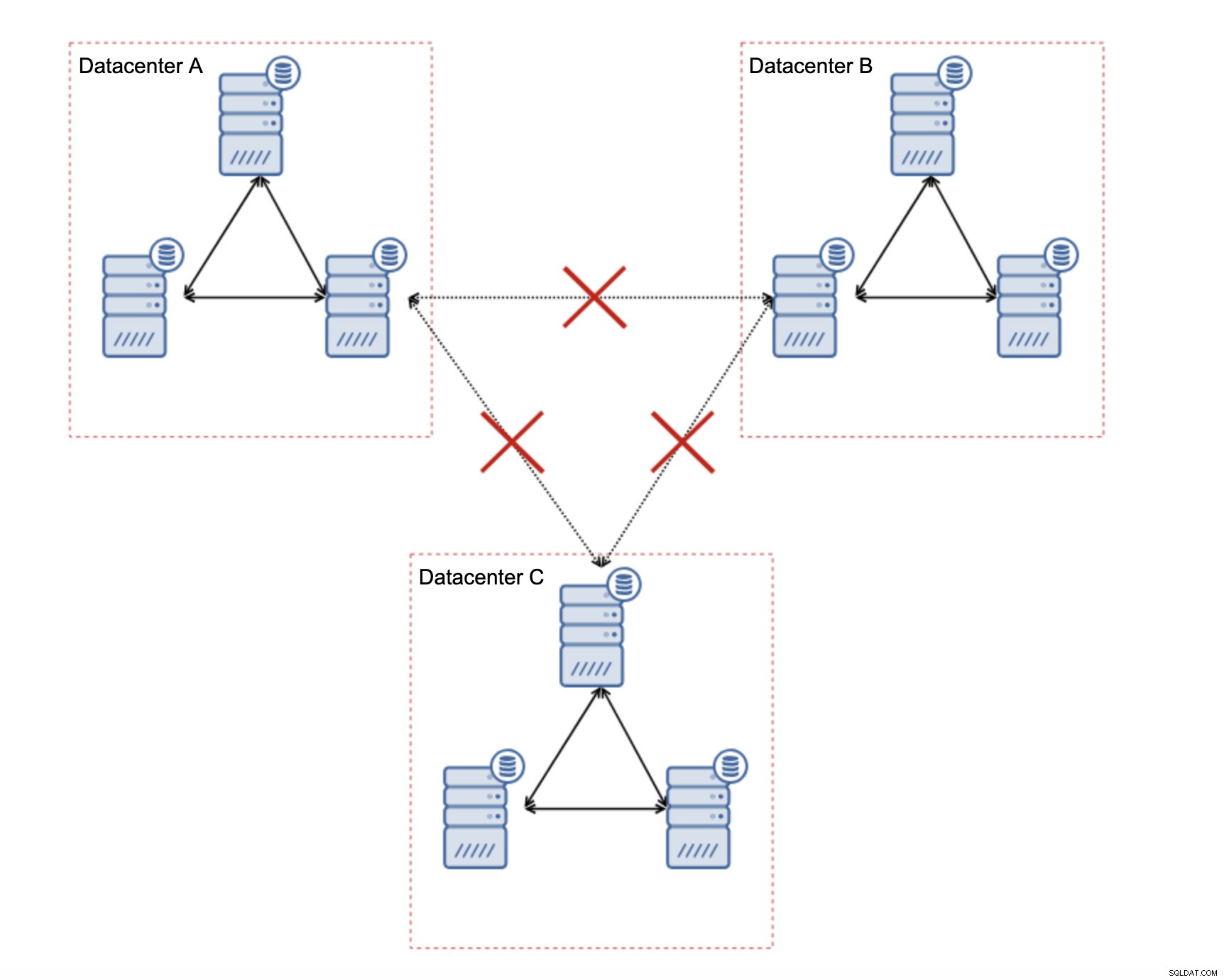
¿Cómo diseñar Galera Cluster para una red inestable?
Lo primero es lo primero, si tiene problemas de red dentro del único centro de datos, no hay mucho que pueda hacer a menos que pueda resolver esos problemas de alguna manera. La red local no confiable no es una opción para Galera Cluster, debe reconsiderar el uso de alguna otra solución (aunque, para ser honesto, la red no confiable siempre será un problema). Por otro lado, si los problemas están relacionados únicamente con las conexiones WAN (y este es uno de los casos más típicos), puede ser posible reemplazar los enlaces WAN Galera con una replicación asincrónica normal (si el ajuste de Galera WAN no ayudó).
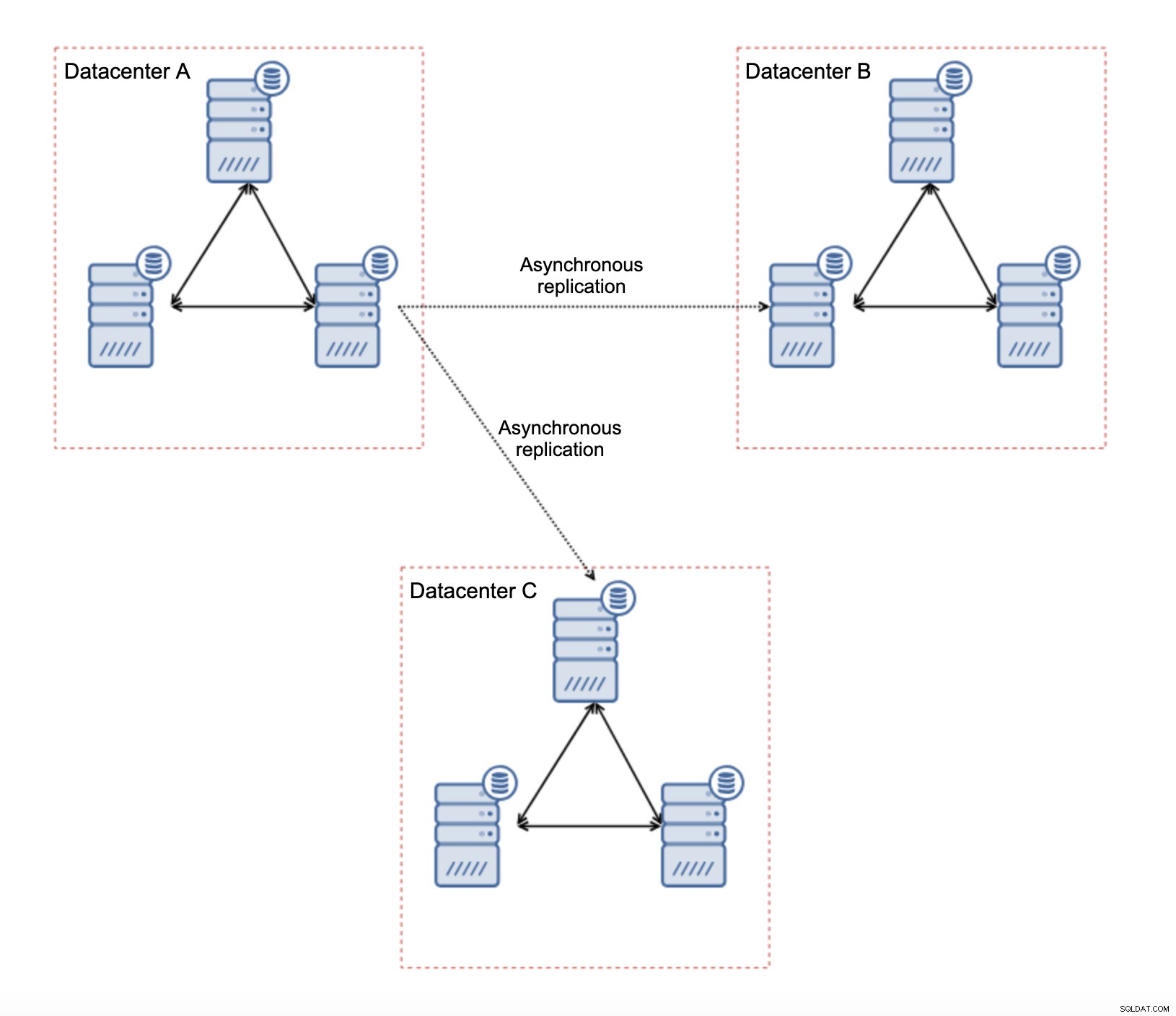
Hay varias limitaciones inherentes en esta configuración:el problema principal es que las escrituras solían ocurrir localmente. Ahora, todas las escrituras deberán dirigirse al centro de datos "maestro" (DC A en nuestro caso). Esto no es tan malo como parece. Tenga en cuenta que en un entorno de Galera, las escrituras se ralentizarán debido a la latencia entre los nodos ubicados en diferentes centros de datos. Incluso las escrituras locales se verán afectadas. Será más o menos la misma desaceleración que con la configuración asincrónica en la que enviaría las escrituras a través de WAN al centro de datos "maestro".
El uso de la replicación asíncrona viene con todos los problemas típicos de la replicación asíncrona. El retraso de la replicación puede convertirse en un problema; no es que Galera tenga un mejor rendimiento, es solo que Galera reduciría la velocidad del tráfico a través del control de flujo, mientras que la replicación no tiene ningún mecanismo para acelerar el tráfico en el maestro.
Otro problema es la conmutación por error:si el nodo Galera "maestro" (el que actúa como maestro para los esclavos en otros centros de datos) falla, se debe crear algún mecanismo para redirigir los esclavos a otro nodo maestro que funcione. Puede ser una especie de secuencia de comandos, también es posible probar algo con VIP donde el clúster de Galera "esclavo" se esclaviza fuera de la IP virtual que siempre se asigna al nodo activo de Galera en el clúster "maestro".
La principal ventaja de esta configuración es que eliminamos el enlace WAN Galera, lo que significa que nuestro clúster "maestro" no se ralentizará por el hecho de que algunos de los nodos estén separados geográficamente. Como mencionamos, perdemos la capacidad de escribir en todos los centros de datos, pero escribir en términos de latencia en la WAN es lo mismo que escribir localmente en el clúster de Galera que se extiende por toda la WAN. Como resultado, la latencia general debería mejorar. La replicación asíncrona también es menos vulnerable a las redes inestables. En el peor de los casos, el enlace de replicación se romperá y se volverá a crear cuando las redes converjan.
¿Cómo diseñar la replicación de MySQL para una red inestable?
En la sección anterior, cubrimos el clúster de Galera y una solución fue usar la replicación asincrónica. ¿Cómo se ve en una configuración de replicación asincrónica simple? Veamos cómo una red inestable puede causar las mayores interrupciones en la configuración de la replicación.
En primer lugar, la latencia:uno de los principales puntos débiles de Galera Cluster. En caso de replicación, es casi un problema. A menos que utilice la replicación semisincrónica, es decir, en tal caso, el aumento de la latencia ralentizará las escrituras. En la replicación asincrónica, la latencia no afecta el rendimiento de escritura. Sin embargo, puede tener algún impacto en el retraso de la replicación. No es algo tan significativo como lo fue para Galera, pero puede esperar más picos de retraso y un rendimiento de replicación menos estable en general si la red entre nodos sufre de alta latencia. Esto se debe principalmente al hecho de que el maestro también puede realizar varias escrituras antes de que se pueda iniciar la transferencia de datos al esclavo en una red de alta latencia.
La inestabilidad de la red definitivamente puede afectar los enlaces de replicación pero, de nuevo, no es tan crítica. Los esclavos de MySQL intentarán volver a conectarse a sus maestros y comenzará la replicación.
El principal problema con la replicación de MySQL es algo que Galera Cluster resuelve internamente:la partición de la red. Estamos hablando de la partición de la red como la condición en la que los segmentos de la red se separan entre sí. La replicación de MySQL utiliza un solo nodo de escritor:maestro. No importa cómo diseñe su entorno, debe enviar sus escrituras al maestro. Si el maestro no está disponible (por cualquier motivo), la aplicación no puede hacer su trabajo a menos que se ejecute en algún tipo de modo de solo lectura. Por lo tanto, es necesario elegir el nuevo maestro lo antes posible. Aquí es donde aparecen los problemas.
Primero, cómo saber qué host es maestro y cuál no. Una de las formas habituales es utilizar la variable "solo lectura" para distinguir los esclavos del maestro. Si el nodo tiene habilitado solo lectura (establecer solo lectura =1), es un esclavo (ya que los esclavos no deben manejar escrituras directas). Si el nodo tiene deshabilitado read_only (set read_only=0), es un maestro. Para hacer las cosas más seguras, un enfoque común es configurar read_only=1 en la configuración de MySQL; en caso de un reinicio, es más seguro si el nodo aparece como esclavo. Tal "lenguaje" puede ser entendido por proxies como ProxySQL o MaxScale.
Veamos un ejemplo.
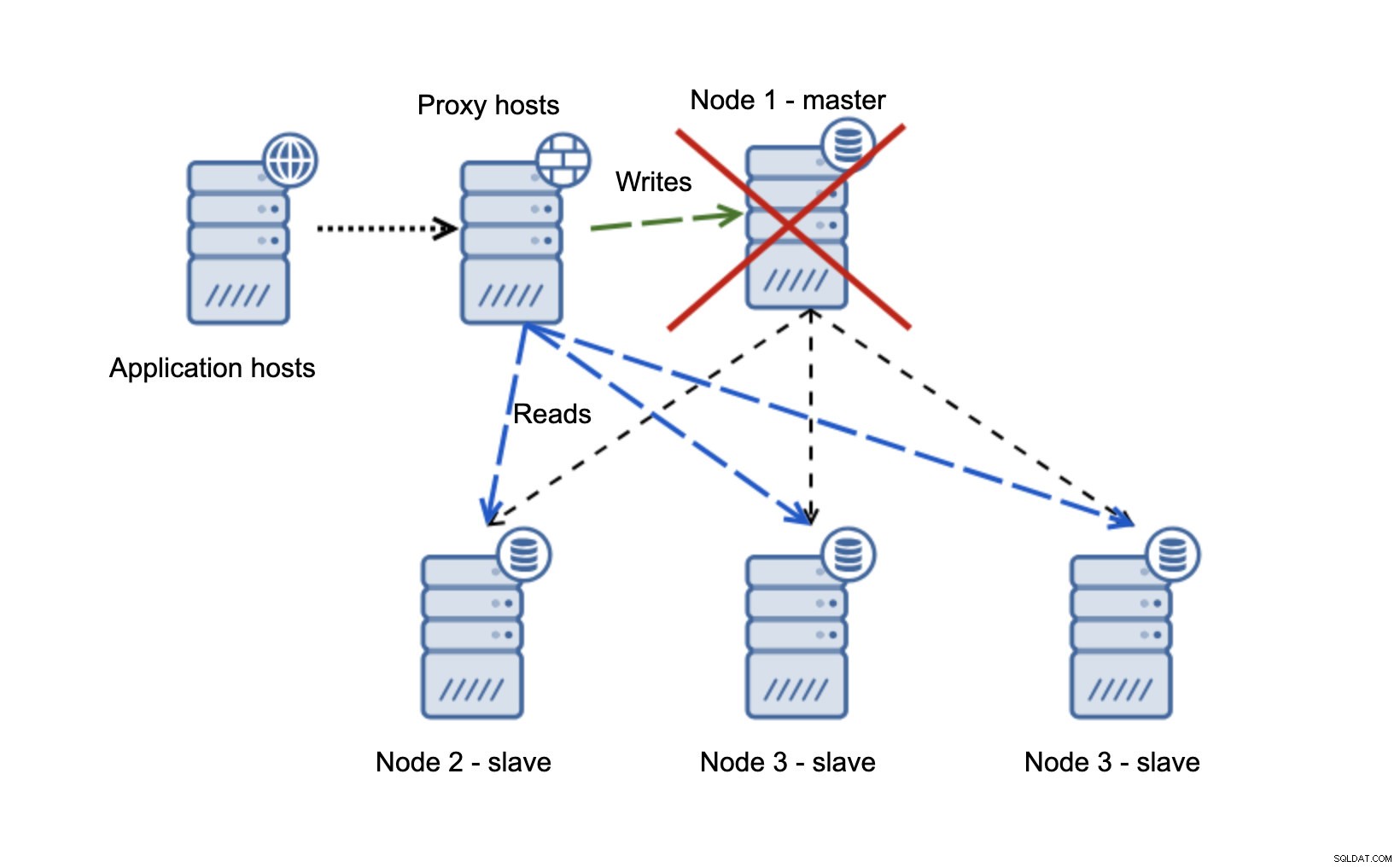
Tenemos hosts de aplicaciones que se conectan a la capa de proxy. Los proxies realizan la división de lectura/escritura enviando SELECT a los esclavos y escrituras al maestro. Si el maestro está inactivo, se realiza la conmutación por error, se promueve un nuevo maestro, la capa de proxy lo detecta y comienza a enviar escrituras a otro nodo.
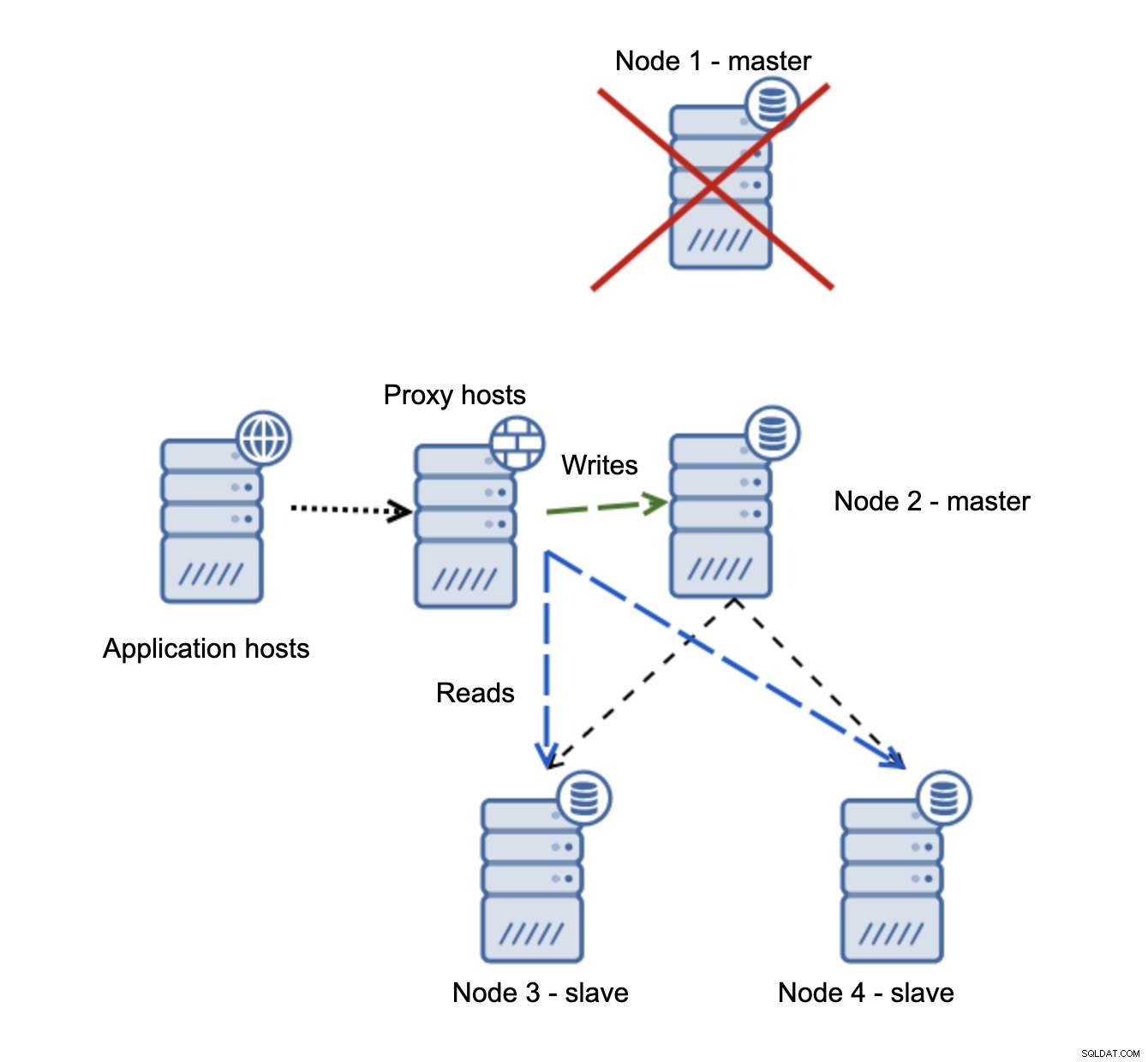
Si el nodo 1 se reinicia, mostrará read_only=1 y se detectará como esclavo. No es ideal ya que no se replica, pero es aceptable. Idealmente, el antiguo maestro no debería aparecer en absoluto hasta que se reconstruya y se esclavice del nuevo maestro.
Una situación mucho más problemática es si tenemos que lidiar con la partición de la red. Consideremos la misma configuración:nivel de aplicación, nivel de proxy y bases de datos.
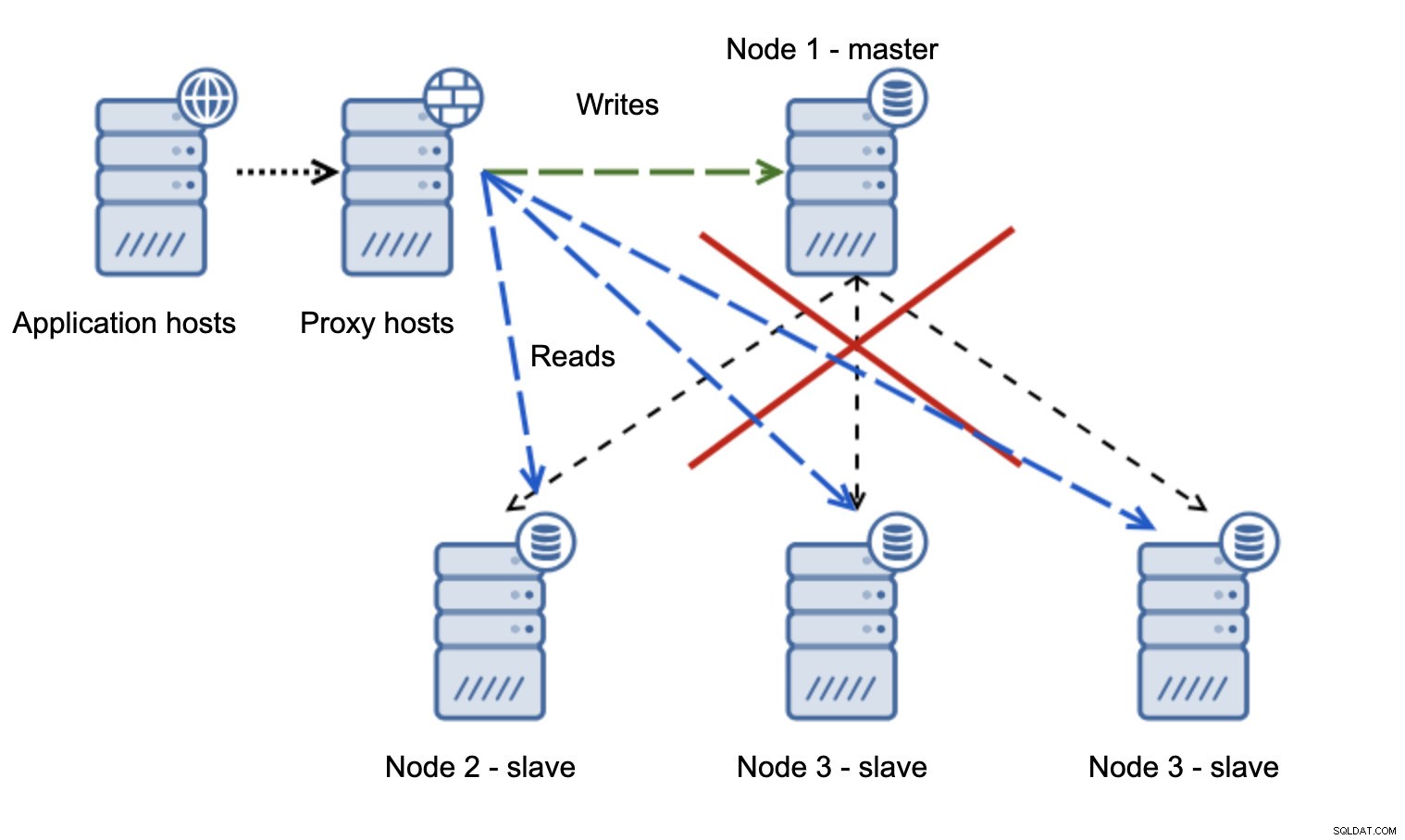
Cuando la red hace que el maestro no sea accesible, la aplicación no se puede utilizar ya que ninguna escritura llega a su destino. Se promueve el nuevo maestro, las escrituras se redireccionan a él. ¿Qué sucederá entonces si cesan los problemas de red y se puede acceder al antiguo maestro? No se ha detenido, por lo que sigue utilizando read_only=0:
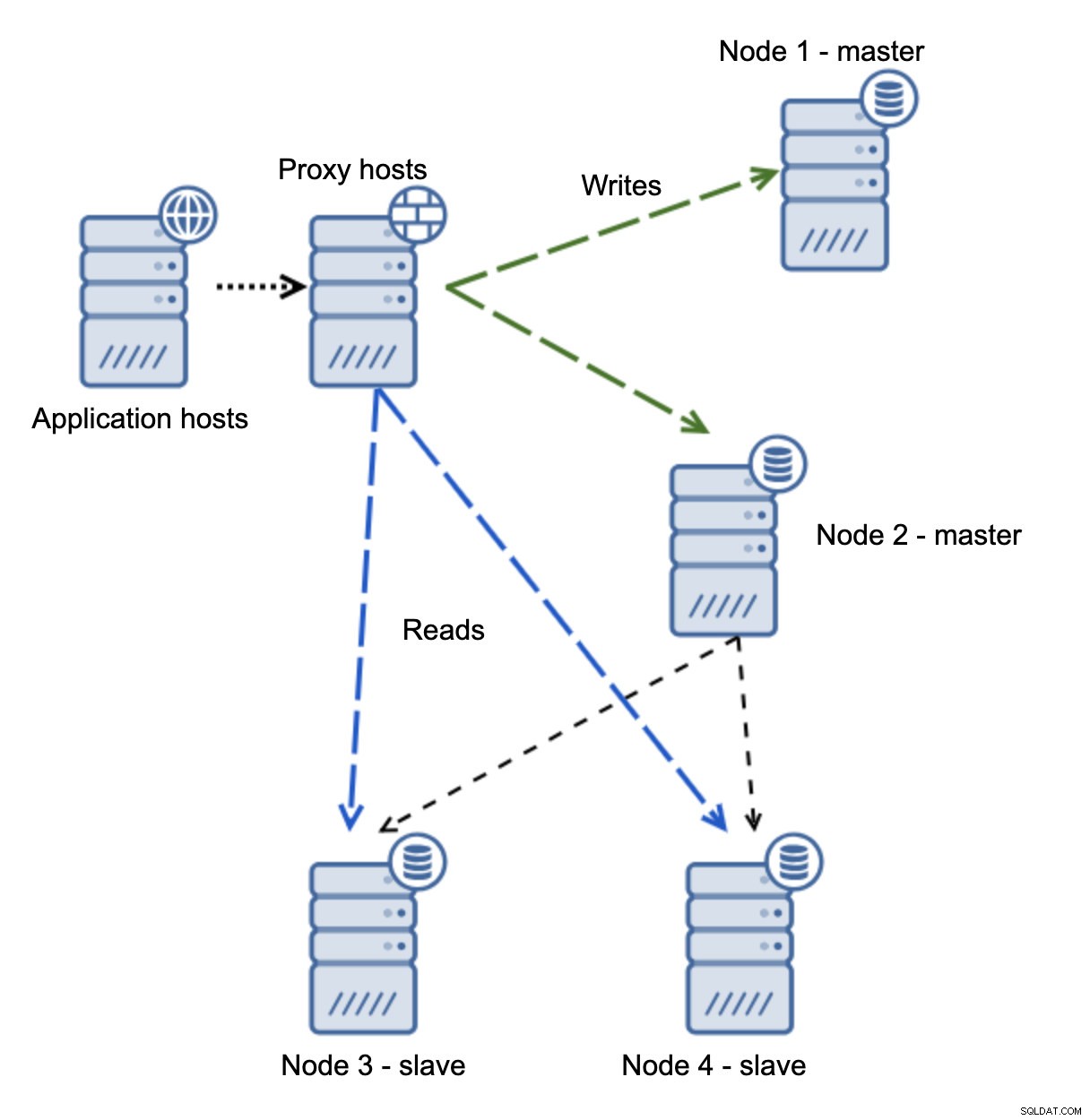
Ahora terminó en un cerebro dividido, cuando las escrituras se dirigieron a dos nodos. Esta situación es bastante mala ya que fusionar conjuntos de datos divergentes puede llevar un tiempo y es un proceso bastante complejo.
¿Qué se puede hacer para evitar este problema? No existe una panacea, pero se pueden tomar algunas medidas para minimizar la probabilidad de que ocurra una división cerebral.
En primer lugar, puede ser más inteligente al detectar el estado del maestro. ¿Cómo lo ven los esclavos? ¿Pueden replicar a partir de él? Tal vez algunos de los esclavos aún puedan conectarse al maestro, lo que significa que el maestro está en funcionamiento o, al menos, haciendo posible detenerlo si fuera necesario. ¿Qué pasa con la capa de proxy? ¿Todos los nodos proxy ven al maestro como no disponible? Si algunos aún pueden conectarse, ¿entonces puede intentar utilizar esos nodos para acceder al maestro y detenerlo antes de la conmutación por error?
El software de administración de conmutación por error también puede ser más inteligente para detectar el estado de la red. Tal vez utilice RAFT o algún otro protocolo de agrupación en clústeres para crear un clúster consciente del quórum. Si un software de administración de conmutación por error puede detectar el cerebro dividido, también puede tomar algunas acciones basadas en esto, como, por ejemplo, establecer todos los nodos en el segmento particionado en solo lectura, asegurándose de que el antiguo maestro no se mostrará como grabable cuando las redes convergen.
También puede incluir herramientas como Consul o Etcd para almacenar el estado del clúster. La capa de proxy se puede configurar para usar datos de Consul, no el estado de la variable de solo lectura. Será entonces cuando el software de administración de conmutación por error realice los cambios necesarios en Consul para que todos los proxies envíen el tráfico a un maestro nuevo y correcto.
Algunas de esas sugerencias incluso se pueden combinar para hacer que la detección de fallas sea aún más confiable. En general, es posible minimizar las posibilidades de que el clúster de replicación sufra de redes poco confiables.
Como puede ver, no importa si estamos hablando de Galera o MySQL Replication, las redes inestables pueden convertirse en un problema grave. Por otro lado, si diseña el entorno correctamente, aún puede hacer que funcione. Esperamos que esta publicación de blog lo ayude a crear entornos que funcionen de manera estable incluso si las redes no lo son.