En una publicación anterior, discutimos cómo puede tomar el control del proceso de conmutación por error en ClusterControl utilizando listas blancas y listas negras. En este post, vamos a discutir un concepto similar. Pero esta vez nos centraremos en las integraciones con scripts y aplicaciones externos a través de numerosos ganchos que ofrece ClusterControl.
Los entornos de infraestructura se pueden construir de diferentes maneras, ya que a menudo hay muchas opciones para elegir para una pieza determinada del rompecabezas. ¿Cómo definimos en qué nodo de la base de datos escribir? ¿Utiliza IP virtual? ¿Utiliza algún tipo de descubrimiento de servicios? ¿Tal vez vaya con las entradas de DNS y cambie los registros A cuando sea necesario? ¿Qué pasa con la capa de proxy? ¿Confía en el valor 'solo lectura' para que sus proxies decidan sobre el escritor, o tal vez realice los cambios necesarios directamente en la configuración del proxy? ¿Cómo maneja su entorno los cambios? ¿Puede seguir adelante y ejecutarlo, o tal vez tenga que tomar algunas medidas preliminares de antemano? Por ejemplo, ¿detener algunos otros procesos antes de poder hacer el cambio?
No es posible preconfigurar un software de conmutación por error para cubrir todas las diferentes configuraciones que las personas pueden crear. Esta es la razón principal para proporcionar diferentes formas de conectarse al proceso de conmutación por error. De esta manera, puede personalizarlo y hacer posible el manejo de todas las sutilezas de su configuración. En esta publicación de blog, veremos cómo se puede personalizar el proceso de conmutación por error de ClusterControl utilizando diferentes scripts anteriores y posteriores a la conmutación por error. También discutiremos algunos ejemplos de lo que se puede lograr con dicha personalización.
Integrando ClusterControl
ClusterControl proporciona varios ganchos que se pueden usar para conectar scripts externos. A continuación encontrará una lista de aquellos con alguna explicación.
- Replication_onfail_failover_script:este script se ejecuta tan pronto como se descubre que se necesita una conmutación por error. Si el script devuelve un valor distinto de cero, forzará la cancelación de la conmutación por error. Si el script está definido pero no se encuentra, se anulará la conmutación por error. Se proporcionan cuatro argumentos al script:arg1='todos los servidores' arg2='oldmaster' arg3='candidate', arg4='slaves of oldmaster' y se pasan así:'scripname arg1 arg2 arg3 arg4'. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_pre_failover_script:este script se ejecuta antes de que ocurra la conmutación por error, pero después de que se haya elegido un candidato y es posible continuar con el proceso de conmutación por error. Si el script devuelve un valor distinto de cero, forzará la cancelación de la conmutación por error. Si el script está definido pero no se encuentra, se anulará la conmutación por error. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_post_failover_script:este script se ejecuta después de que se produzca la conmutación por error. Si el script devuelve un valor distinto de cero, se escribirá una Advertencia en el registro del trabajo. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_post_unsuccessful_failover_script:este script se ejecuta después de que falla el intento de conmutación por error. Si el script devuelve un valor distinto de cero, se escribirá una Advertencia en el registro del trabajo. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_failed_reslave_failover_script:este script se ejecuta después de que se haya promovido un nuevo maestro y si falla la reesclavización de los esclavos al nuevo maestro. Si el script devuelve un valor distinto de cero, se escribirá una Advertencia en el registro del trabajo. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_pre_switchover_script:este script se ejecuta antes de que ocurra el cambio. Si el script devuelve un valor distinto de cero, obligará a que falle el cambio. Si el script está definido pero no se encuentra, se cancelará el cambio. El script debe estar accesible en el controlador y ser ejecutable.
- Replication_post_switchover_script:este script se ejecuta después de que se produce el cambio. Si el script devuelve un valor distinto de cero, se escribirá una Advertencia en el registro del trabajo. El script debe estar accesible en el controlador y ser ejecutable.
Como puede ver, los ganchos cubren la mayoría de los casos en los que es posible que desee realizar algunas acciones:antes y después de una conmutación, antes y después de una conmutación por error, cuando ha fallado la reesclavización o cuando ha fallado la conmutación por error. Todos los scripts se invocan con cuatro argumentos (que pueden o no ser manejados en el script, no es necesario que el script los utilice todos):todos los servidores, nombre de host (o IP, como se define en ClusterControl) del antiguo maestro, nombre de host (o IP, como se define en ClusterControl) del candidato a maestro y el cuarto, todas réplicas del antiguo maestro. Esas opciones deberían permitir manejar la mayoría de los casos.
Todos esos ganchos deben definirse en un archivo de configuración para un clúster determinado (/etc/cmon.d/cmon_X.cnf donde X es la identificación del clúster). Un ejemplo puede verse así:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shPor supuesto, los scripts invocados deben ser ejecutables, de lo contrario, cmon no podrá ejecutarlos. Tomemos un momento y analicemos el proceso de conmutación por error en ClusterControl y veamos cuándo se ejecutan los scripts externos.
Proceso de conmutación por error en ClusterControl
Definimos todos los ganchos que están disponibles:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
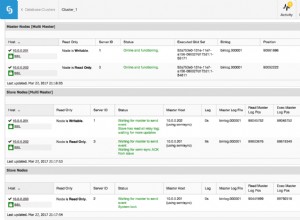
replication_post_switchover_script=/tmp/7.shDespués de esto, debe reiniciar el proceso cmon. Una vez hecho esto, estamos listos para probar la conmutación por error. La topología original se ve así:
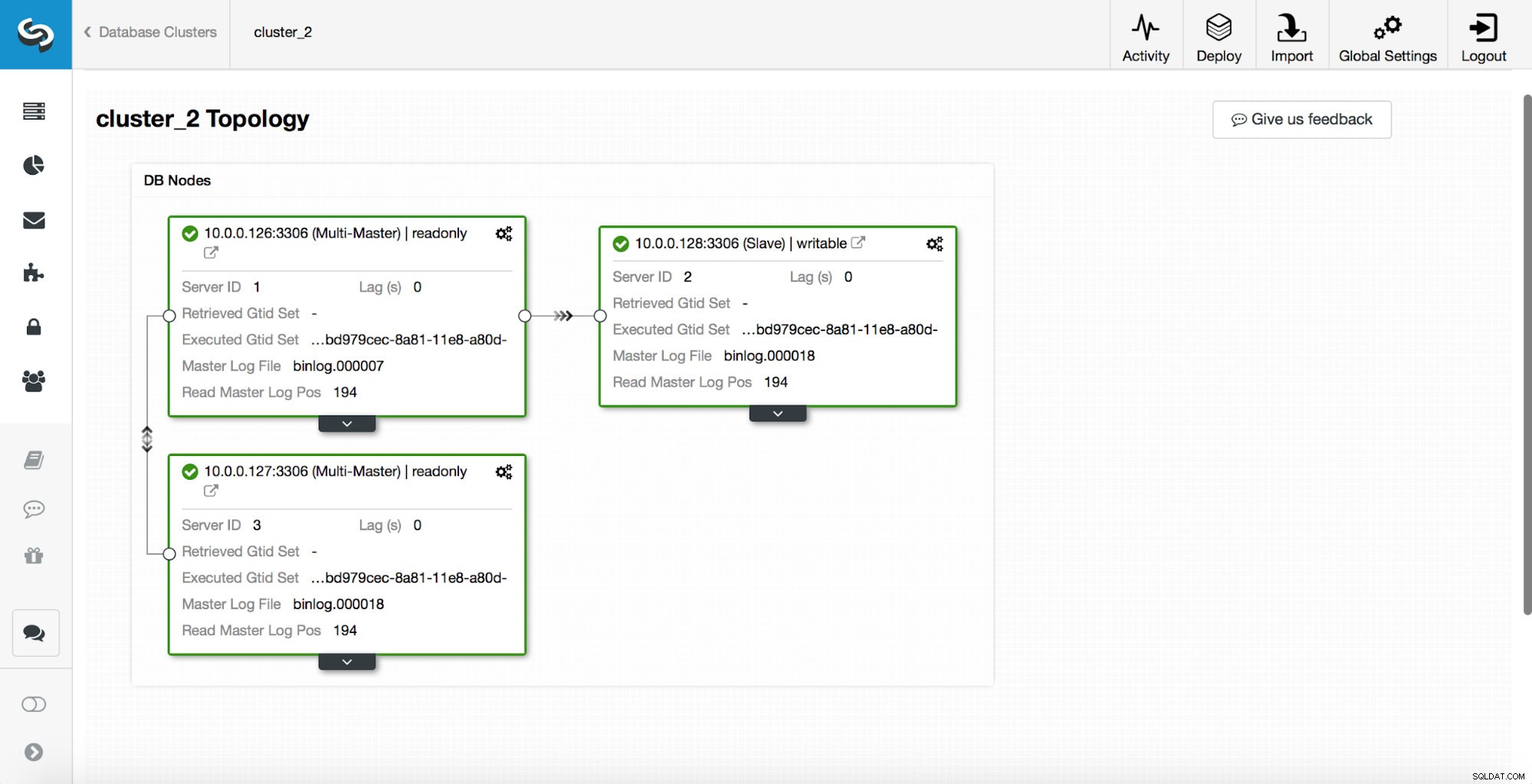
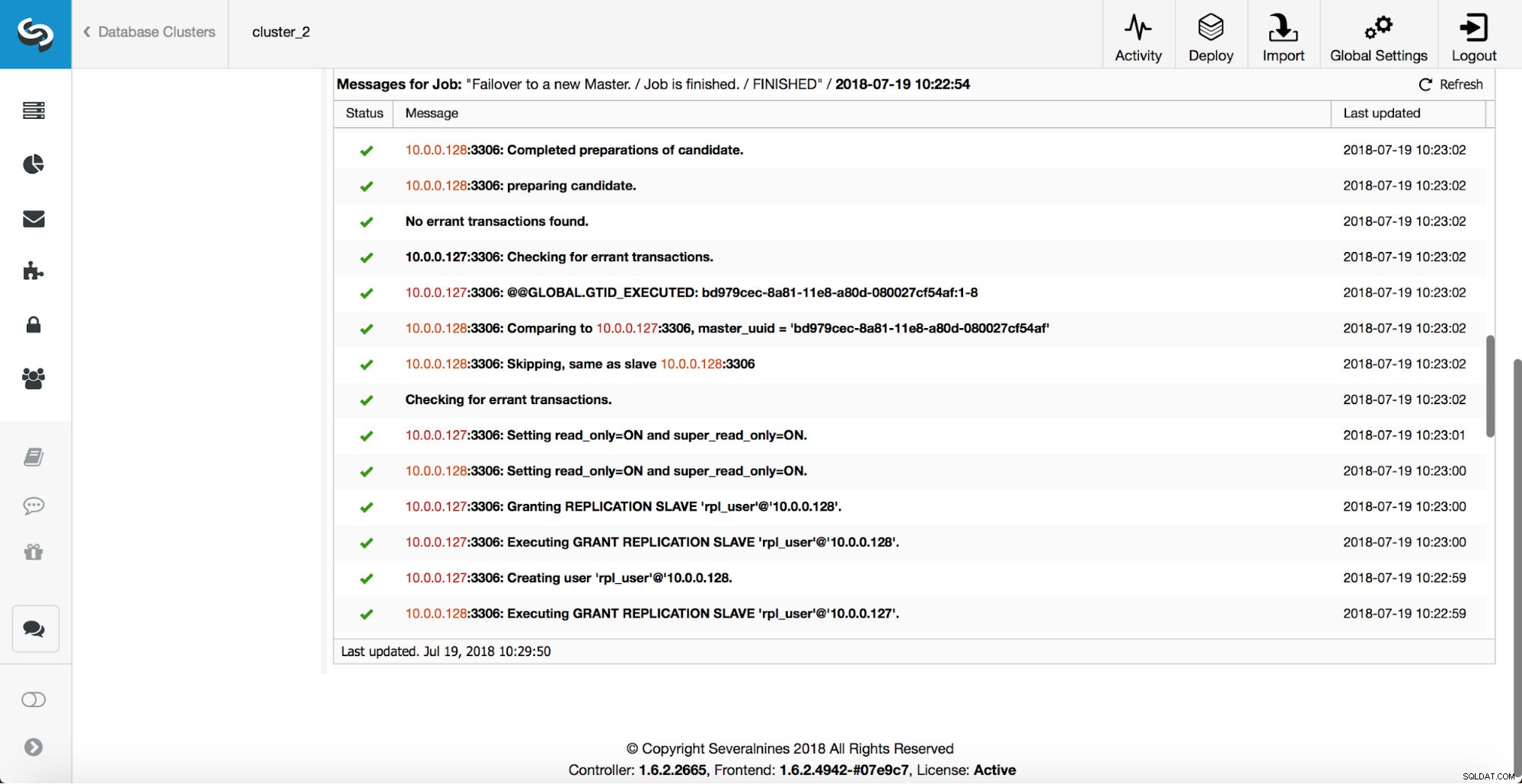
Se eliminó un maestro y se inició el proceso de conmutación por error. Tenga en cuenta que las entradas de registro más recientes se encuentran en la parte superior, por lo que desea seguir la conmutación por error de abajo hacia arriba.
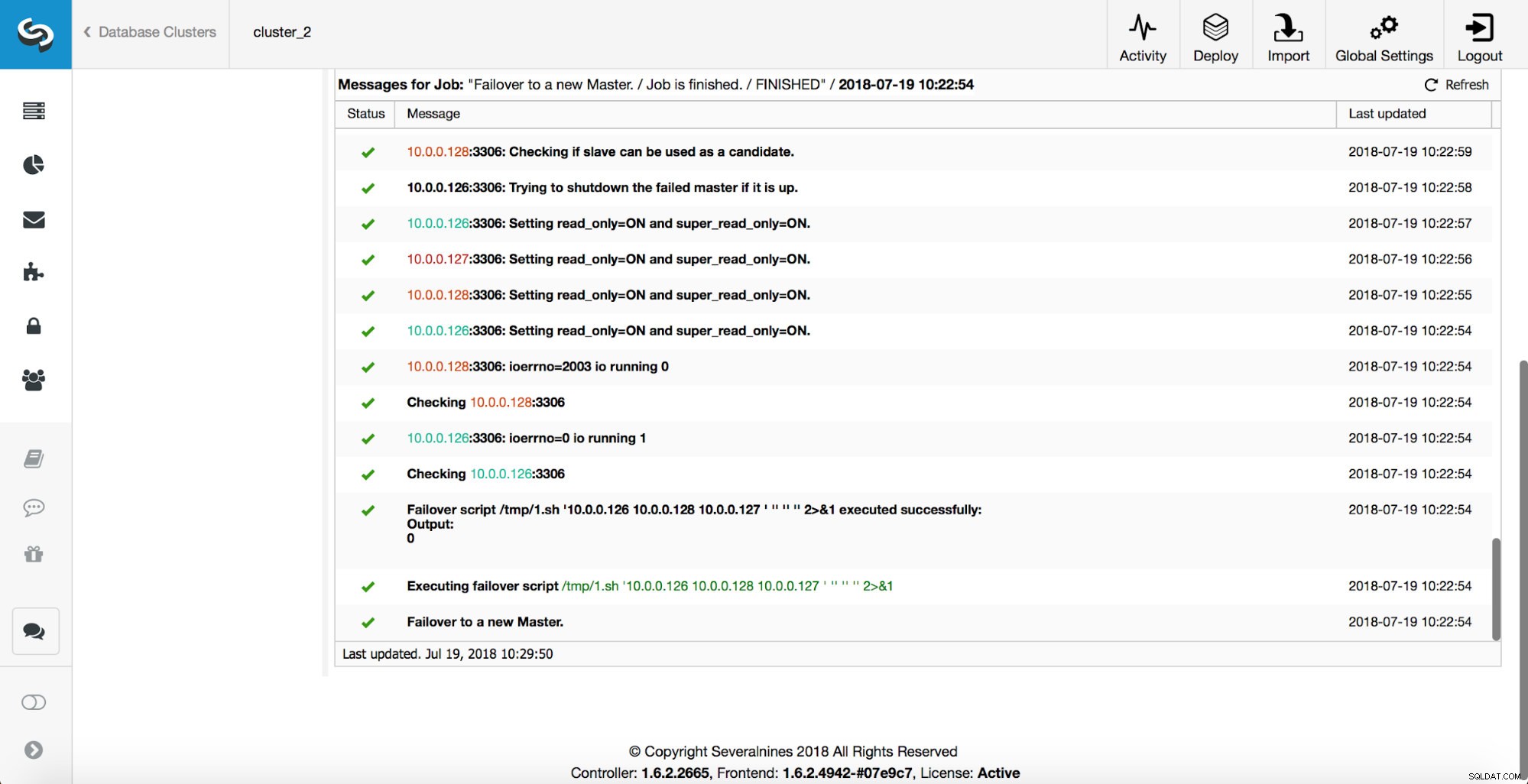
Como puede ver, inmediatamente después de que comenzó el trabajo de conmutación por error, se activa el gancho 'replication_onfail_failover_script'. Luego, todos los hosts accesibles se marcan como de solo lectura y ClusterControl intenta evitar que se ejecute el antiguo maestro.
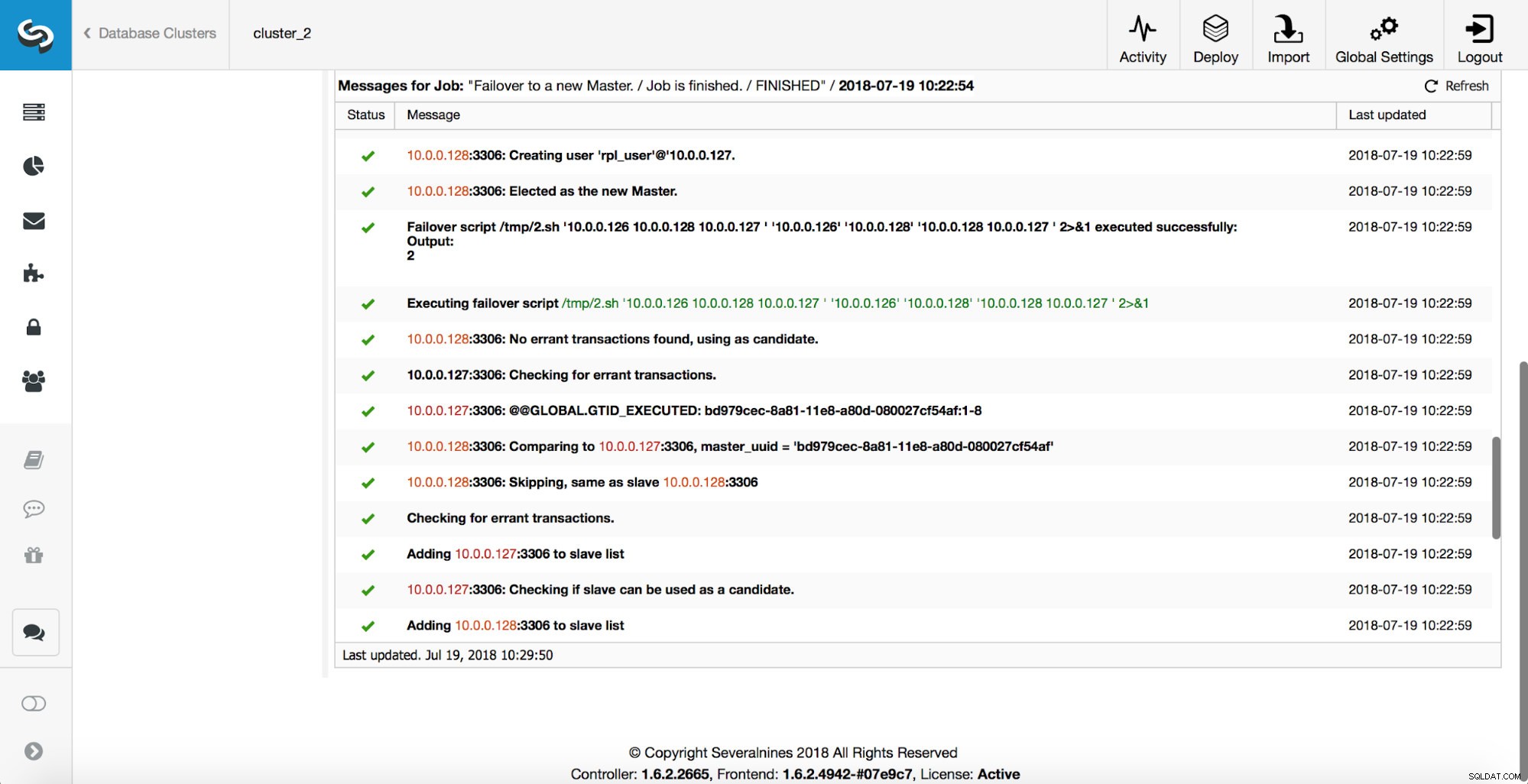
A continuación, se elige al candidato maestro y se ejecutan controles de cordura. Una vez que se confirma que el candidato a maestro se puede usar como un nuevo maestro, se ejecuta el 'replication_pre_failover_script'.
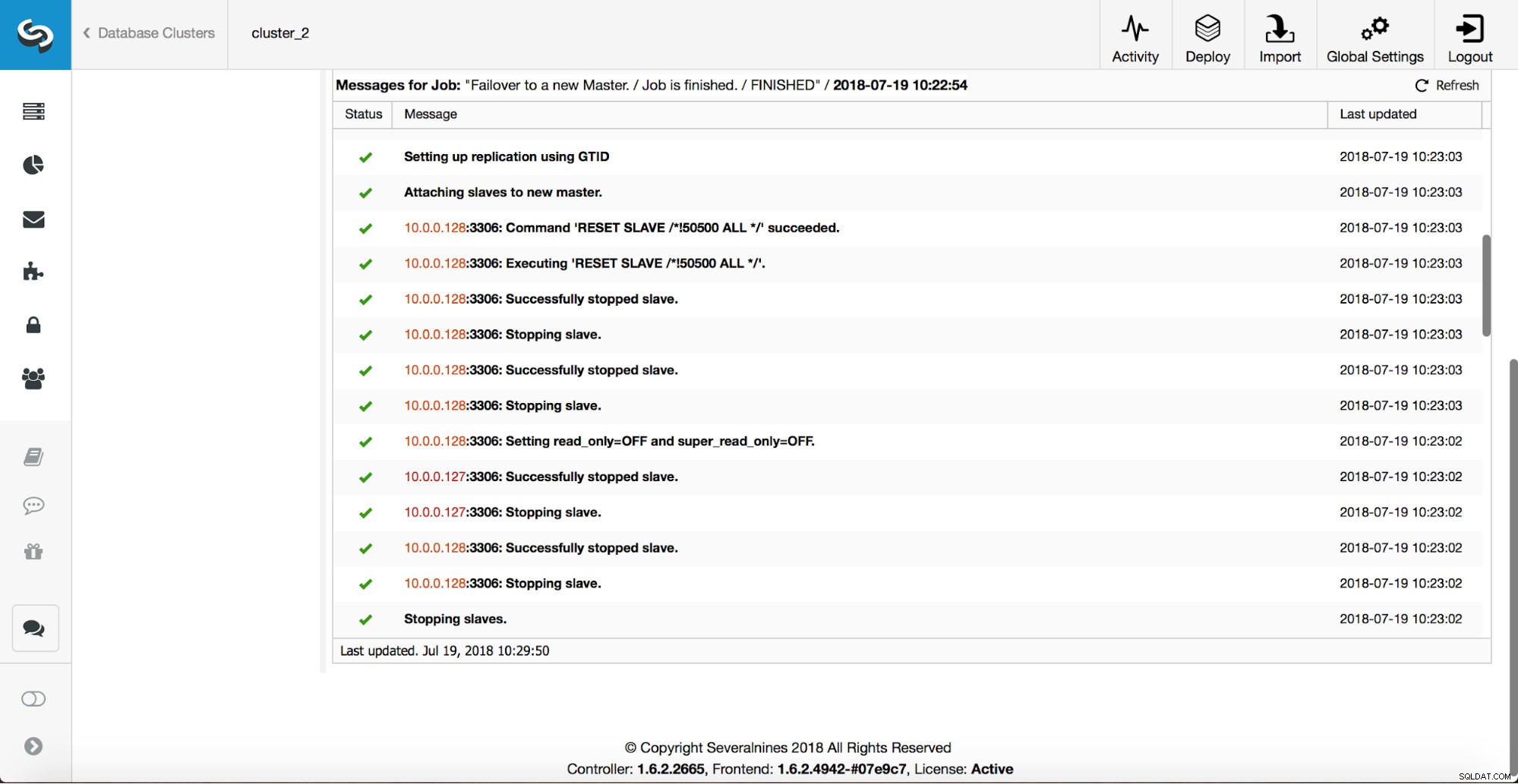
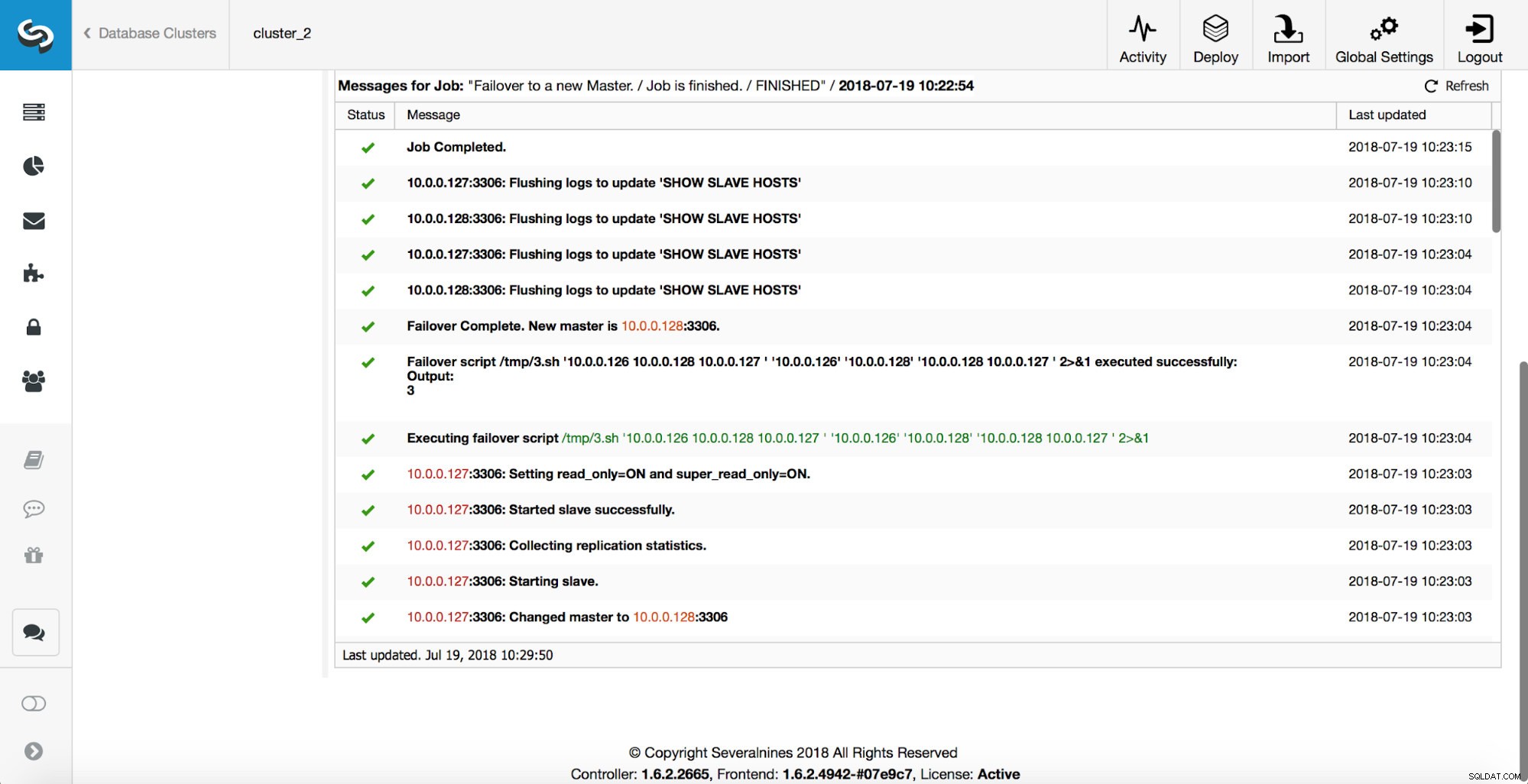
Se realizan más comprobaciones, se detienen las réplicas y se esclavizan del nuevo maestro. Finalmente, una vez completada la conmutación por error, se activa un enlace final, 'replication_post_failover_script'.
¿Cuándo pueden ser útiles los ganchos?
En esta sección, veremos un par de casos de ejemplo en los que podría ser una buena idea implementar scripts externos. No entraremos en detalles ya que están demasiado relacionados con un entorno en particular. Será más una lista de sugerencias que podría ser útil implementar.
Secuencia de comandos STONITH
Shoot The Other Node In The Head (STONITH) es un proceso para asegurarse de que el viejo maestro, que está muerto, permanecerá muerto (y sí... no nos gustan los zombis deambulando por nuestra infraestructura). Lo último que probablemente desee es tener un maestro antiguo que no responde y luego vuelve a estar en línea y, como resultado, termina con dos maestros escribibles. Hay precauciones que puede tomar para asegurarse de que el antiguo maestro no se utilizará incluso si aparece nuevamente, y es más seguro que permanezca fuera de línea. Las formas de garantizar que diferirán de un entorno a otro. Por lo tanto, lo más probable es que no haya soporte integrado para STONITH en la herramienta de conmutación por error. Dependiendo del entorno, es posible que desee ejecutar el comando CLI que detendrá (e incluso eliminará) una VM en la que se ejecuta el maestro anterior. Si tiene una configuración local, es posible que tenga más control sobre el hardware. Podría ser posible utilizar algún tipo de administración remota (Lights-out integrado o algún otro acceso remoto al servidor). También puede tener acceso a tomas de corriente manejables y desconectar la alimentación en una de ellas para asegurarse de que el servidor nunca vuelva a iniciarse sin la intervención humana.
Descubrimiento de servicios
Ya mencionamos un poco sobre el descubrimiento de servicios. Existen numerosas formas de almacenar información sobre una topología de replicación y detectar qué host es un maestro. Definitivamente, una de las opciones más populares es usar etc.d o Consul para almacenar datos sobre la topología actual. Con él, una aplicación o proxy puede confiar en estos datos para enviar el tráfico al nodo correcto. ClusterControl (al igual que la mayoría de las herramientas que admiten el manejo de conmutación por error) no tiene una integración directa con etc.d o Consul. La tarea de actualizar los datos de topología es del usuario. Puede usar ganchos como replication_post_failover_script o replication_post_switchover_script para invocar algunos de los scripts y realizar los cambios necesarios. Otra solución bastante común es usar DNS para dirigir el tráfico a las instancias correctas. Si mantiene bajo el tiempo de vida de un registro DNS, debería poder definir un dominio, que apuntará a su maestro (es decir, writes.cluster1.example.com). Esto requiere un cambio en los registros DNS y, de nuevo, ganchos como replication_post_failover_script o replication_post_switchover_script pueden ser realmente útiles para realizar las modificaciones necesarias después de que ocurra una conmutación por error.
Reconfiguración de proxy
Cada servidor proxy que se utiliza tiene que enviar tráfico a las instancias correctas. Dependiendo del propio proxy, la forma en que se realiza una detección maestra puede estar codificada (parcialmente) o puede depender del usuario para definir lo que quiera. El mecanismo de conmutación por error de ClusterControl está diseñado de manera que se integra bien con los proxies que implementó y configuró. Todavía puede suceder que haya proxies en su lugar, que no fueron instalados por ClusterControl y requieren que se lleven a cabo algunas acciones manuales mientras se ejecuta la conmutación por error. Dichos proxies también se pueden integrar con el proceso de conmutación por error de ClusterControl a través de secuencias de comandos externas y ganchos como replication_post_failover_script o replication_post_switchover_script.
Registro adicional
Puede suceder que desee recopilar datos del proceso de conmutación por error con fines de depuración. ClusterControl tiene amplias copias impresas para asegurarse de que es posible seguir el proceso y averiguar qué sucedió y por qué. Todavía puede suceder que desee recopilar información personalizada adicional. Básicamente, todos los ganchos se pueden utilizar aquí:puede recopilar el estado inicial, antes de la conmutación por error, puede realizar un seguimiento del estado del entorno en todas las etapas de la conmutación por error.