La replicación es una de las formas más comunes de lograr alta disponibilidad para MySQL y MariaDB. Se ha vuelto mucho más robusto con la adición de GTID y miles y miles de usuarios lo han probado exhaustivamente. Sin embargo, la replicación de MySQL no es una propiedad de "establecer y olvidar", necesita ser monitoreada en busca de posibles problemas y mantenida para que se mantenga en buen estado. En esta publicación de blog, nos gustaría compartir algunos consejos y trucos sobre cómo mantener, solucionar y corregir problemas con la replicación de MySQL.
¿Cómo determinar si la replicación de MySQL está en buen estado?
Esta es sin duda la habilidad más importante que debe poseer cualquier persona que se ocupe de una configuración de replicación de MySQL. Echemos un vistazo a dónde buscar información sobre el estado de replicación. Hay una ligera diferencia entre MySQL y MariaDB y también hablaremos de esto.
MOSTRAR ESTADO DE ESCLAVO
Este es sin duda el método más común para verificar el estado de la replicación en un host esclavo:está con nosotros desde siempre y, por lo general, es el primer lugar al que vamos si esperamos que haya algún problema con la replicación.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Algunos detalles pueden diferir entre MySQL y MariaDB, pero la mayoría del contenido tendrá el mismo aspecto. Los cambios serán visibles en la sección GTID ya que MySQL y MariaDB lo hacen de forma diferente. Desde SHOW SLAVE STATUS, puede derivar algunos datos:qué maestro se usa, qué usuario y qué puerto se usa para conectarse al maestro. Tenemos algunos datos sobre la posición del registro binario actual (ya no es tan importante, ya que podemos usar GTID y olvidarnos de los binlogs) y el estado de los subprocesos de replicación de E/S y SQL. Luego puede ver si y cómo está configurado el filtrado. También puede encontrar información sobre errores, retraso de replicación, configuración de SSL y GTID. El ejemplo anterior proviene del esclavo MySQL 5.7 que se encuentra en un estado saludable. Echemos un vistazo a un ejemplo en el que se interrumpe la replicación.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Esta muestra se tomó de MariaDB 10.1, puede ver los cambios en la parte inferior de la salida para que funcione con los GTID de MariaDB. Lo que es importante para nosotros es el error:puede ver que algo no está bien en el hilo de SQL:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Discutiremos este problema en particular más adelante, por ahora es suficiente que vea cómo puede verificar si hay algún error en la replicación usando SHOW SLAVE STATUS.
Otra información importante que proviene de SHOW SLAVE STATUS es:qué tan mal se retrasa nuestro esclavo. Puede comprobarlo en la columna "Seconds_Behind_Master". Esta métrica es especialmente importante para realizar un seguimiento si sabe que su aplicación es sensible cuando se trata de lecturas obsoletas.
En ClusterControl puede rastrear estos datos en la sección "Descripción general":
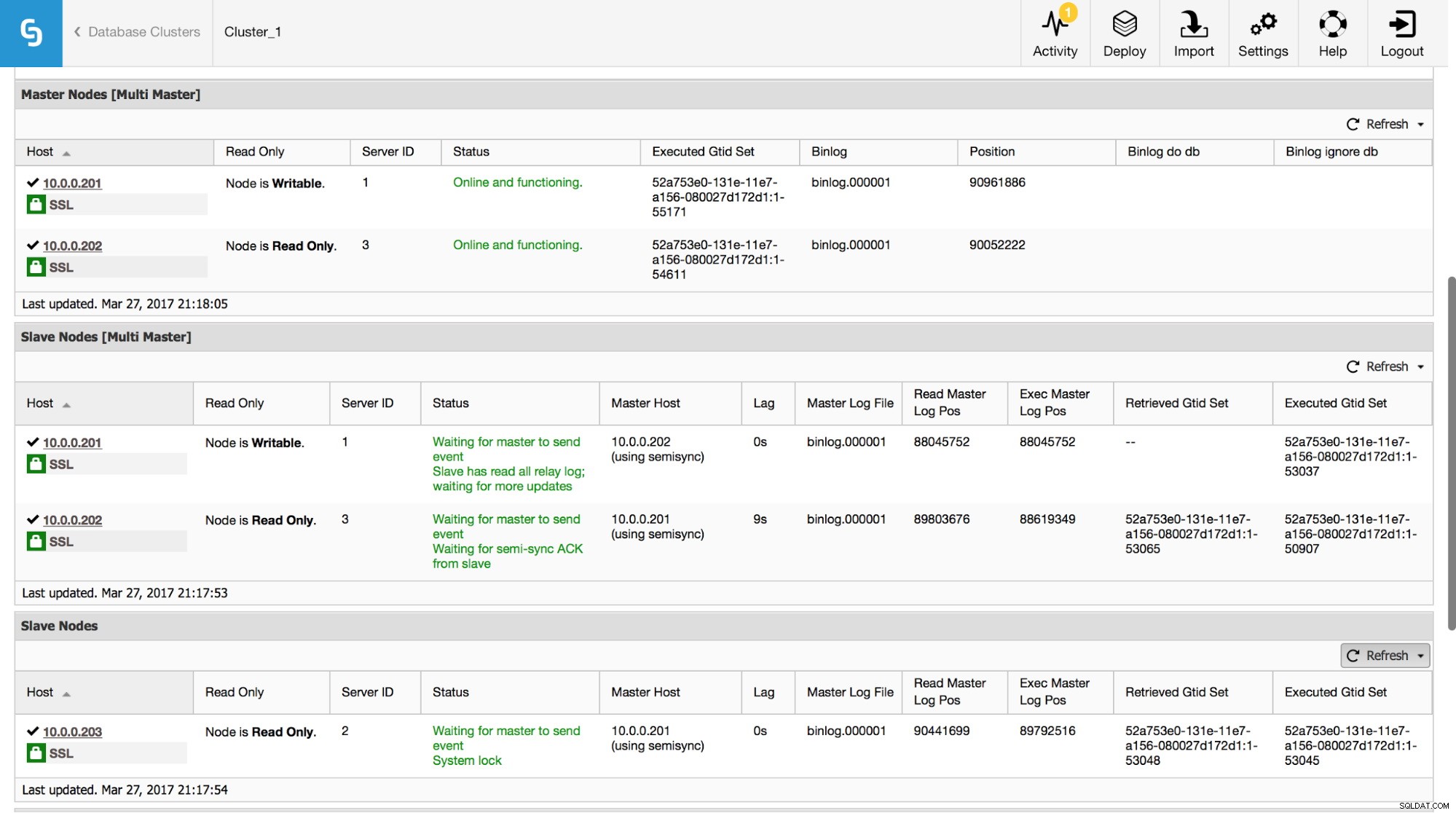
Hicimos visible toda la información más importante del comando SHOW SLAVE STATUS. Puede verificar el estado de la replicación, quién es el maestro, si hay un retraso en la replicación o no, las posiciones del registro binario. También puede encontrar GTID recuperados y ejecutados.
Esquema de rendimiento
Otro lugar donde puede buscar información sobre la replicación es performance_schema. Esto se aplica solo a MySQL 5.7 de Oracle; las versiones anteriores y MariaDB no recopilan estos datos.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)A continuación puede encontrar algunos ejemplos de datos disponibles en algunas de esas tablas.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Como puede ver, podemos verificar el estado de la replicación, el último error, el conjunto de transacciones recibidas y algunos datos más. Lo que es importante:si habilitó la replicación de subprocesos múltiples, en la tabla replication_applier_status_by_worker, verá el estado de cada uno de los trabajadores; esto lo ayudará a comprender el estado de replicación de cada uno de los subprocesos de trabajo.
Retraso de replicación
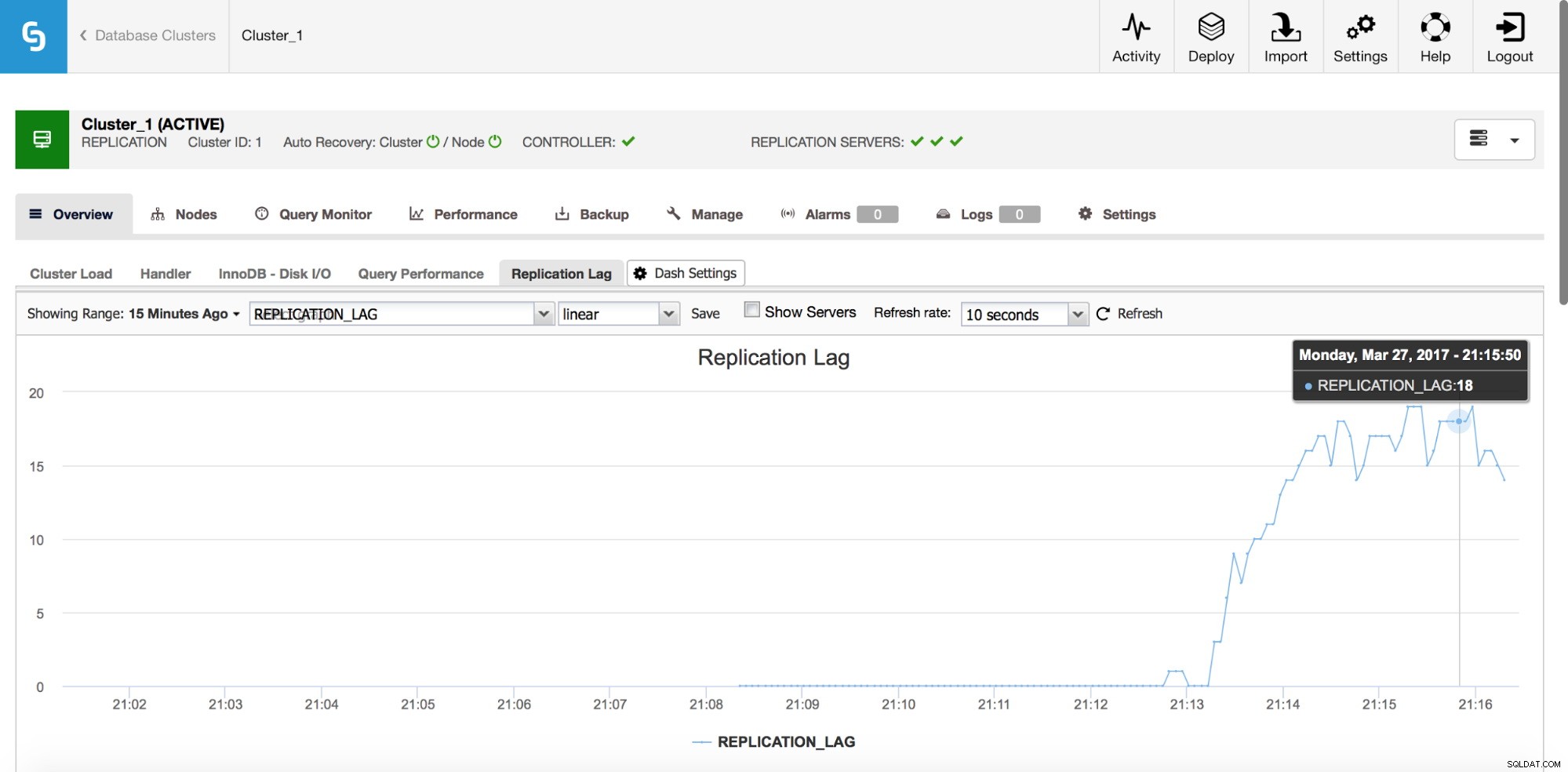
El retraso es definitivamente uno de los problemas más comunes que enfrentará cuando trabaje con la replicación de MySQL. El retraso en la replicación aparece cuando uno de los esclavos no puede mantenerse al día con la cantidad de operaciones de escritura realizadas por el maestro. Las razones pueden ser diferentes:configuración de hardware diferente, carga más pesada en el esclavo, alto grado de paralelización de escritura en el maestro que debe serializarse (cuando usa un solo hilo para la replicación) o las escrituras no pueden paralelizarse en la misma medida que lo ha hecho. estado en el maestro (cuando usa la replicación de subprocesos múltiples).
¿Cómo detectarlo?
Hay un par de métodos para detectar el retraso en la replicación. En primer lugar, puede marcar "Seconds_Behind_Master" en la salida SHOW SLAVE STATUS; le dirá si el esclavo se está retrasando o no. Funciona bien en la mayoría de los casos, pero en topologías más complejas, cuando usa maestros intermedios, en hosts en algún lugar bajo en la cadena de replicación, puede que no sea preciso. Otra solución mejor es confiar en herramientas externas como pt-heartbeat. La idea es simple:se crea una tabla con, entre otros, una columna de marca de tiempo. Esta columna se actualiza en el maestro a intervalos regulares. En un esclavo, puede comparar la marca de tiempo de esa columna con la hora actual; le dirá qué tan atrás está el esclavo.
Independientemente de la forma en que calcule el retraso, asegúrese de que sus hosts estén sincronizados en el tiempo. Use ntpd u otros medios de sincronización de tiempo:si hay una desviación de tiempo, verá un retraso "falso" en sus esclavos.
¿Cómo reducir el retraso?
Esta no es una pregunta fácil de responder. En resumen, depende de qué está causando el retraso y qué se convirtió en un cuello de botella. Hay dos patrones típicos:el esclavo está vinculado a E/S, lo que significa que su subsistema de E/S no puede hacer frente a la cantidad de operaciones de escritura y lectura. Segundo:el esclavo está vinculado a la CPU, lo que significa que el subproceso de replicación usa toda la CPU que puede (un subproceso puede usar solo un núcleo de CPU) y aún no es suficiente para manejar todas las operaciones de escritura.
Cuando la CPU es un cuello de botella, la solución puede ser tan simple como usar la replicación de subprocesos múltiples. Aumente el número de subprocesos de trabajo para permitir una mayor paralelización. Sin embargo, no siempre es posible; en tal caso, es posible que desee jugar un poco con las variables de confirmación de grupo (tanto para MySQL como para MariaDB) para retrasar las confirmaciones durante un breve período de tiempo (estamos hablando de milisegundos aquí) y, de esta manera , aumenta la paralelización de las confirmaciones.
Si el problema está en la E/S, el problema es un poco más difícil de resolver. Por supuesto, debe revisar la configuración de E/S de InnoDB; tal vez haya espacio para mejoras. Si el ajuste de my.cnf no ayuda, no tiene demasiadas opciones:mejore sus consultas (siempre que sea posible) o actualice su subsistema de E/S a algo más capaz.
La mayoría de los proxies (por ejemplo, todos los proxies que se pueden implementar desde ClusterControl:ProxySQL, HAProxy y MaxScale) le brindan la posibilidad de eliminar un esclavo fuera de rotación si el retraso de la replicación cruza algún umbral predefinido. Este no es de ninguna manera un método para reducir el retraso, pero puede ser útil para evitar lecturas obsoletas y, como efecto secundario, para reducir la carga en un esclavo, lo que debería ayudarlo a ponerse al día.
Por supuesto, el ajuste de consultas puede ser una solución en ambos casos:siempre es bueno mejorar las consultas que requieren mucha CPU o E/S.
Transacciones Errantes
Las transacciones erráticas son transacciones que se han ejecutado solo en un esclavo, no en el maestro. En resumen, hacen que un esclavo sea incompatible con el amo. Cuando se utiliza la replicación basada en GTID, esto puede causar serios problemas si el esclavo se convierte en maestro. Tenemos una publicación detallada sobre este tema y lo alentamos a que la investigue y se familiarice con la forma de detectar y solucionar problemas con transacciones erróneas. También incluimos allí información sobre cómo ClusterControl detecta y maneja transacciones errantes.
No hay archivo Binlog en el maestro
¿Cómo identificar el problema?
En algunas circunstancias, puede suceder que un esclavo se conecte a un maestro y solicite un archivo de registro binario que no existe. Una razón para esto podría ser la transacción errada:en algún momento, se ejecutó una transacción en un esclavo y luego este esclavo se convierte en maestro. Otros hosts, que están configurados para ser esclavos de ese maestro, solicitarán esa transacción faltante. Si se ejecutó hace mucho tiempo, existe la posibilidad de que los archivos de registro binarios ya se hayan eliminado.
Otro ejemplo más típico:desea aprovisionar un esclavo utilizando xtrabackup. Copie la copia de seguridad en un host, aplique el registro, cambie el propietario del directorio de datos MySQL:operaciones típicas que realiza para restaurar una copia de seguridad. Tu ejecutas
SET GLOBAL gtid_purged=basado en los datos de xtrabackup_binlog_info y ejecuta CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (esto es en MySQL, MariaDB tiene un proceso ligeramente diferente), inicia el esclavo y luego termina con un error como:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'en MySQL o:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'en MariaDB.
Básicamente, esto significa que el maestro no tiene todos los registros binarios necesarios para ejecutar todas las transacciones que faltan. Lo más probable es que la copia de seguridad sea demasiado antigua y que el maestro ya eliminó algunos de los registros binarios creados entre el momento en que se creó la copia de seguridad y cuando se aprovisionó el esclavo.
¿Cómo resolver este problema?
Desafortunadamente, no hay mucho que puedas hacer en este caso particular. Si tiene algunos hosts MySQL que almacenan registros binarios durante más tiempo que el maestro, puede intentar usar esos registros para reproducir transacciones faltantes en el esclavo. Echemos un vistazo a cómo se puede hacer.
En primer lugar, echemos un vistazo al GTID más antiguo en los registros binarios del maestro:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Entonces, 'binlog.000021' es el último (y único) archivo. Veamos cuál es la primera entrada de GTID en este archivo:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Como podemos ver, la entrada de registro binario más antigua disponible es:5d1e2227-07c6-11e7-8123-080027495a77:1106669
También debemos verificar cuál es el último GTID cubierto en la copia de seguridad:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Es:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666 por lo que nos faltan dos eventos:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Veamos si podemos encontrar esas transacciones en otro esclavo.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Parece que 'binlog.000003' es el registro binario más reciente. Necesitamos verificar si nuestros GTID faltantes se pueden encontrar en él:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Tenga en cuenta que es posible que desee copiar archivos binlog fuera del servidor de producción, ya que procesarlos puede agregar algo de carga. Como comprobamos que esos GTID existen, podemos extraerlos:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlDespués de un scp rápido, podemos aplicar esos eventos en el esclavo
slave1:~# mysql -ppass < to_apply_on_slave1.sqlUna vez hecho esto, podemos verificar si esos GTID se han aplicado mirando el resultado de SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set se ve bien, por lo que podemos iniciar subprocesos esclavos:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Vamos a comprobar si funcionó bien. Usaremos, de nuevo, la salida MOSTRAR ESTADO DE ESCLAVO:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Se ve bien, ¡está funcionando!
Otro método para resolver este problema será realizar una copia de seguridad una vez más y aprovisionar el esclavo nuevamente, utilizando datos nuevos. Es muy probable que sea más rápido y definitivamente más confiable. No es frecuente que tenga diferentes políticas de purga de binlog en el maestro y en los esclavos)
Continuaremos discutiendo otros tipos de problemas de replicación en la próxima publicación del blog.