En la publicación anterior, discutimos cómo verificar que la replicación de MySQL esté en buenas condiciones. También analizamos algunos de los problemas típicos. En esta publicación, veremos algunos problemas más que puede encontrar al tratar con la replicación de MySQL.
Entradas faltantes o duplicadas
Esto es algo que no debería suceder, pero sucede muy a menudo:una situación en la que una instrucción SQL ejecutada en el maestro tiene éxito pero la misma instrucción ejecutada en uno de los esclavos falla. La razón principal es la deriva del esclavo:algo (generalmente transacciones erráticas pero también otros problemas o errores en la replicación) hace que el esclavo difiera de su maestro. Por ejemplo, una fila que existía en el maestro no existe en un esclavo y no se puede eliminar ni actualizar. La frecuencia con la que aparece este problema depende principalmente de la configuración de replicación. En resumen, hay tres formas en que MySQL almacena eventos de registro binario. Primero, "declaración", significa que SQL está escrito en texto sin formato, tal como se ha ejecutado en un maestro. Esta configuración tiene la tolerancia más alta en la deriva de esclavos, pero también es la que no puede garantizar la consistencia de los esclavos; es difícil recomendar su uso en producción. El segundo formato, "fila", almacena el resultado de la consulta en lugar de la declaración de la consulta. Por ejemplo, un evento puede tener el siguiente aspecto:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4Esto significa que estamos actualizando una fila en la tabla de 'pestaña' en el esquema de 'prueba' donde la primera columna tiene un valor de 2 y la segunda columna tiene un valor de 5. Establecemos la primera columna en 2 (el valor no cambia) y la segunda columna a 4. Como puede ver, no hay mucho espacio para la interpretación:se define con precisión qué fila se usa y cómo se cambia. Como resultado, este formato es excelente para la consistencia de los esclavos pero, como puede imaginar, es muy vulnerable cuando se trata de la deriva de datos. Aún así, es la forma recomendada de ejecutar la replicación de MySQL.
Finalmente, el tercero, "mixto", funciona de manera que aquellos eventos que son seguros de escribir en forma de declaraciones utilizan el formato de "declaración". Aquellos que podrían causar la deriva de datos utilizarán el formato de "fila".
¿Cómo los detecta?
Como de costumbre, SHOW SLAVE STATUS nos ayudará a identificar el problema.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Como puede ver, los errores son claros y se explican por sí mismos (y son básicamente idénticos entre MySQL y MariaDB.
¿Cómo solucionas el problema?
Esta es, desafortunadamente, la parte compleja. En primer lugar, debe identificar una fuente de verdad. ¿Qué host contiene los datos correctos? ¿Amo o esclavo? Por lo general, asumiría que es el maestro, pero no lo asuma por defecto:¡investigue! Podría ser que después de la conmutación por error, alguna parte de la aplicación aún emitiera escrituras al antiguo maestro, que ahora actúa como esclavo. Podría ser que read_only no se haya configurado correctamente en ese host o que la aplicación utilice un superusuario para conectarse a la base de datos (sí, lo hemos visto en entornos de producción). En tal caso, el esclavo podría ser la fuente de la verdad, al menos hasta cierto punto.
Dependiendo de qué datos deben permanecer y cuáles deben desaparecer, el mejor curso de acción sería identificar qué se necesita para volver a sincronizar la replicación. En primer lugar, la replicación está interrumpida, por lo que debe atender esto. Inicie sesión en el maestro y verifique el registro binario, incluso lo que causó la interrupción de la replicación.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Como puede ver, nos perdemos un evento:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Comprobémoslo en los registros binarios del maestro:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Podemos ver que era una inserción que establece la primera columna en 3 y la segunda en 7. Verifiquemos cómo se ve nuestra tabla ahora:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Ahora tenemos dos opciones, según qué datos deben prevalecer. Si los datos correctos están en el maestro, simplemente podemos eliminar la fila con id=3 en el esclavo. Solo asegúrese de deshabilitar el registro binario para evitar introducir transacciones erróneas. Por otro lado, si decidimos que los datos correctos están en el esclavo, debemos ejecutar el comando REEMPLAZAR en el maestro para configurar la fila con id=3 para corregir el contenido de (3, 10) del actual (3, 7). En el esclavo, sin embargo, tendremos que omitir el GTID actual (o, para ser más precisos, tendremos que crear un evento de GTID vacío) para poder reiniciar la replicación.
Eliminar una fila en un esclavo es simple:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Insertar un GTID vacío es casi tan simple:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Otro método para resolver este problema en particular (siempre que aceptemos al maestro como fuente de la verdad) es usar herramientas como pt-table-checksum y pt-table-sync para identificar dónde el esclavo no es consistente con su maestro y qué SQL debe ejecutarse en el maestro para que el esclavo vuelva a estar sincronizado. Desafortunadamente, este método es bastante pesado:se agrega mucha carga al maestro y se escriben un montón de consultas en el flujo de replicación que pueden afectar el retraso en los esclavos y el rendimiento general de la configuración de replicación. Esto es especialmente cierto si hay una cantidad significativa de filas que deben sincronizarse.
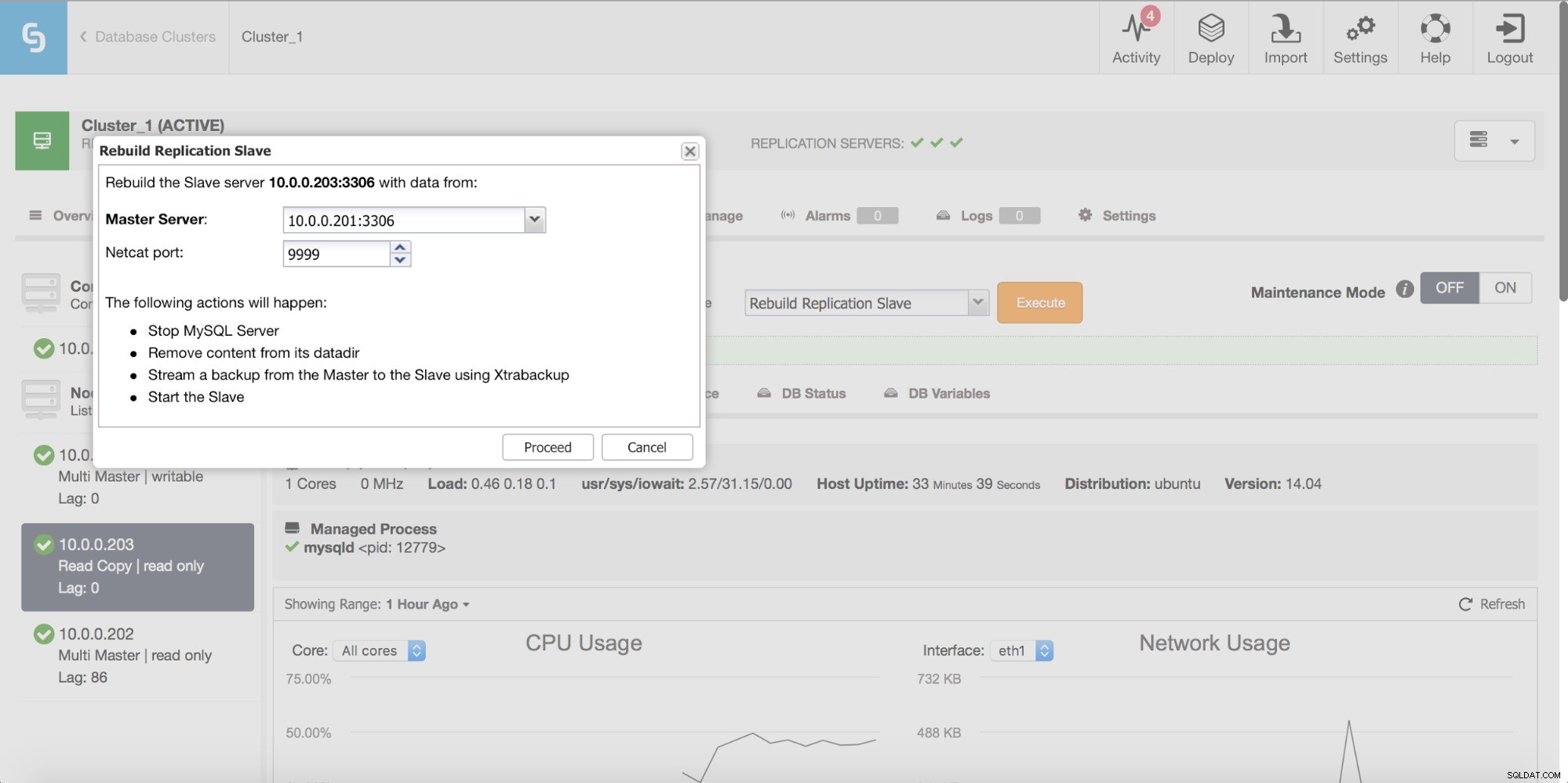
Finalmente, como siempre, puede reconstruir su esclavo utilizando datos del maestro; de esta manera, puede estar seguro de que el esclavo se actualizará con los datos más recientes y actualizados. En realidad, esto no es necesariamente una mala idea:cuando hablamos de una gran cantidad de filas para sincronizar usando pt-table-checksum/pt-table-sync, esto conlleva una sobrecarga significativa en el rendimiento de la replicación, la CPU general y la E/S. carga y horas-hombre requeridas.
ClusterControl le permite reconstruir un esclavo, utilizando una copia nueva de los datos maestros.
Comprobaciones de coherencia
Como mencionamos en el capítulo anterior, la consistencia puede convertirse en un problema grave y causar muchos dolores de cabeza a los usuarios que ejecutan configuraciones de replicación de MySQL. Veamos cómo puede verificar que sus esclavos MySQL estén sincronizados con el maestro y qué puede hacer al respecto.
Cómo detectar un esclavo inconsistente
Desafortunadamente, la forma típica en que un usuario se da cuenta de que un esclavo es inconsistente es al encontrarse con uno de los problemas que mencionamos en el capítulo anterior. Para evitar que se requiera un monitoreo proactivo de la consistencia del esclavo. Veamos cómo se puede hacer.
Vamos a utilizar una herramienta de Percona Toolkit:pt-table-checksum. Está diseñado para escanear el clúster de replicación e identificar cualquier discrepancia.
Construimos un escenario personalizado usando sysbench e introdujimos un poco de inconsistencia en uno de los esclavos. Lo que es importante (si desea probarlo como lo hicimos nosotros), debe aplicar un parche a continuación para obligar a pt-table-checksum a reconocer el esquema 'sbtest' como un esquema que no pertenece al sistema:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Primero, vamos a ejecutar pt-table-checksum de la siguiente manera:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Un par de notas importantes sobre cómo invocamos la herramienta. En primer lugar, el usuario que configuramos debe existir en todos los esclavos. Si lo desea, también puede usar '--slave-user' para definir otro usuario menos privilegiado para acceder a los esclavos. Otra cosa que vale la pena explicar:usamos la replicación basada en filas que no es totalmente compatible con pt-table-checksum. Si tiene una replicación basada en filas, lo que sucede es que pt-table-checksum cambiará el formato de registro binario en un nivel de sesión a 'declaración', ya que este es el único formato admitido. El problema es que dicho cambio funcionará solo en un primer nivel de esclavos que están conectados directamente a un maestro. Si tiene maestros intermedios (es decir, más de un nivel de esclavos), el uso de pt-table-checksum puede interrumpir la replicación. Por eso, de forma predeterminada, si la herramienta detecta la replicación basada en filas, sale e imprime el error:
“La réplica Slave1 tiene binlog_format ROW que podría causar que pt-table-checksum interrumpa la replicación. Lea "Réplicas que usan replicación basada en filas" en la sección LIMITACIONES de la documentación de la herramienta. Si comprende los riesgos, especifique --no-check-binlog-format para deshabilitar esta verificación”.
Utilizamos solo un nivel de esclavos, por lo que era seguro especificar "--no-check-binlog-format" y seguir adelante.
Finalmente, establecemos un retraso máximo de 5 segundos. Si se alcanza este umbral, pt-table-checksum se detendrá durante el tiempo necesario para llevar el retraso por debajo del umbral.
Como puede ver en la salida,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2se ha detectado una inconsistencia en la tabla sbtest.sbtest2.
De forma predeterminada, pt-table-checksum almacena las sumas de verificación en la tabla percona.checksums. Estos datos se pueden usar para otra herramienta de Percona Toolkit, pt-table-sync, para identificar qué partes de la tabla deben verificarse en detalle para encontrar la diferencia exacta en los datos.
Cómo arreglar un esclavo inconsistente
Como se mencionó anteriormente, usaremos pt-table-sync para hacer eso. En nuestro caso, vamos a utilizar los datos recopilados por pt-table-checksum, aunque también es posible apuntar pt-table-sync a dos hosts (el maestro y el esclavo) y comparará todos los datos en ambos hosts. Definitivamente es un proceso que consume más tiempo y recursos, por lo tanto, siempre que ya tenga datos de pt-table-checksum, es mucho mejor usarlo. Así es como lo ejecutamos para probar la salida:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Como puede ver, como resultado se ha generado algo de SQL. Importante tener en cuenta es la variable --replicate. Lo que sucede aquí es que apuntamos pt-table-sync a la tabla generada por pt-table-checksum. También lo apuntamos a maestro.
Para verificar si SQL tiene sentido usamos la opción --print. Tenga en cuenta que el SQL generado es válido solo en el momento en que se genera; realmente no puede almacenarlo en algún lugar, revisarlo y luego ejecutarlo. Todo lo que puede hacer es verificar si el SQL tiene algún sentido e, inmediatamente después, vuelva a ejecutar la herramienta con el indicador --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeEsto debería hacer que el esclavo vuelva a estar sincronizado con el maestro. Podemos verificarlo con pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Como puede ver, ya no hay diferencias en la tabla sbtest.sbtest2.
Esperamos que haya encontrado esta publicación de blog informativa y útil. Haga clic aquí para obtener más información sobre la replicación de MySQL. Si tiene alguna pregunta o sugerencia, no dude en comunicarse con nosotros a través de los comentarios a continuación.



