Es posible que haya oído hablar del término "cerebro dividido". ¿Lo que es? ¿Cómo afecta a sus clústeres? En esta publicación de blog, discutiremos qué es exactamente, qué peligro puede representar para su base de datos, cómo podemos prevenirlo y, si todo sale mal, cómo recuperarse.
Atrás quedaron los días de instancias únicas, hoy en día casi todas las bases de datos se ejecutan en grupos o clústeres de replicación. Esto es excelente para una alta disponibilidad y escalabilidad, pero una base de datos distribuida presenta nuevos peligros y limitaciones. Un caso que puede ser mortal es una división de red. Imagine un grupo de múltiples nodos que, debido a problemas de red, se dividió en dos partes. Por razones obvias (coherencia de datos), ambas partes no deben manejar el tráfico al mismo tiempo, ya que están aisladas entre sí y no se pueden transferir datos entre ellas. También es incorrecto desde el punto de vista de la aplicación, incluso si, eventualmente, hubiera una forma de sincronizar los datos (aunque la reconciliación de 2 conjuntos de datos no es trivial). Durante un tiempo, parte de la aplicación no estaría al tanto de los cambios realizados por otros hosts de aplicaciones, que acceden a la otra parte del clúster de la base de datos. Esto puede conducir a problemas graves.
La condición en la que el clúster se ha dividido en dos o más partes que están dispuestas a aceptar escrituras se denomina "cerebro dividido".
El mayor problema con el cerebro dividido es la deriva de datos, ya que las escrituras ocurren en ambas partes del clúster. Ninguno de los sabores de MySQL proporciona medios automatizados para fusionar conjuntos de datos que han divergido. No encontrará dicha función en la replicación MySQL, Group Replication o Galera. Una vez que los datos han divergido, la única opción es usar una de las partes del clúster como fuente de la verdad y descartar los cambios ejecutados en la otra parte, a menos que podamos seguir algún proceso manual para fusionar los datos.
Es por eso que comenzaremos con cómo evitar que suceda el cerebro dividido. Esto es mucho más fácil que tener que corregir cualquier discrepancia de datos.
Cómo prevenir el cerebro dividido
La solución exacta depende del tipo de base de datos y la configuración del entorno. Echaremos un vistazo a algunos de los casos más comunes para Galera Cluster y MySQL Replication.
Clúster Galera
Galera tiene un "disyuntor" incorporado para manejar el cerebro dividido:se basa en un mecanismo de quórum. Si la mayoría (50 % + 1) de los nodos están disponibles en el clúster, Galera funcionará con normalidad. Si no hay mayoría, Galera dejará de atender el tráfico y cambiará al estado denominado "no primario". Esto es prácticamente todo lo que necesitas para lidiar con una situación de cerebro dividido mientras usas Galera. Claro, existen métodos manuales para forzar a Galera al estado "Principal", incluso si no hay una mayoría. La cuestión es que, a menos que hagas eso, deberías estar a salvo.
La forma en que se calcula el quórum tiene repercusiones importantes:en un solo nivel de centro de datos, desea tener una cantidad impar de nodos. Tres nodos le brindan una tolerancia para la falla de un nodo (2 nodos cumplen con el requisito de que más del 50 % de los nodos en el clúster estén disponibles). Cinco nodos le darán una tolerancia al fallo de dos nodos (5 - 2 =3, que es más del 50 % de 5 nodos). Por otro lado, el uso de cuatro nodos no mejorará su tolerancia sobre el clúster de tres nodos. Todavía manejaría solo una falla de un nodo (4 - 1 =3, más del 50% de 4) mientras que la falla de dos nodos inutilizará el clúster (4 - 2 =2, solo 50%, no más).
Al implementar el clúster de Galera en un solo centro de datos, tenga en cuenta que, idealmente, le gustaría distribuir los nodos en varias zonas de disponibilidad (fuente de alimentación separada, red, etc.), siempre que existan en su centro de datos, es decir . Una configuración simple puede verse a continuación:
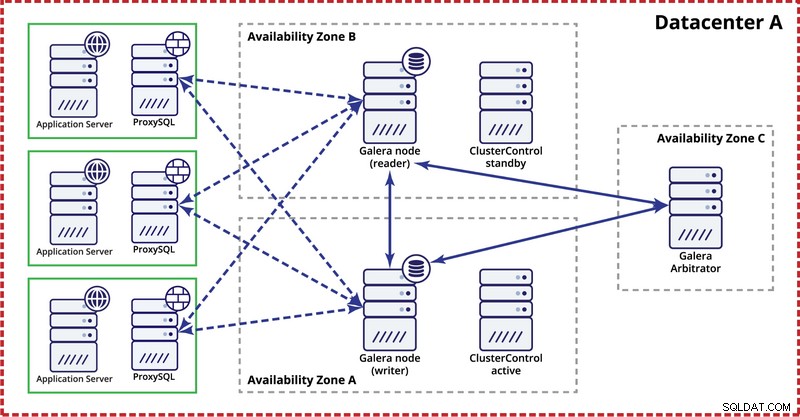
En el nivel de múltiples centros de datos, esas consideraciones también son aplicables. Si desea que el clúster de Galera maneje automáticamente las fallas del centro de datos, debe usar una cantidad impar de centros de datos. Para reducir costos, puede usar un árbitro Galera en uno de ellos en lugar de un nodo de base de datos. Galera arbitrator (garbd) es un proceso que participa en el cálculo del quórum pero no contiene ningún dato. Esto hace posible su uso incluso en instancias muy pequeñas, ya que no consume muchos recursos, aunque la conectividad de la red debe ser buena, ya que "ve" todo el tráfico de replicación. La configuración de ejemplo puede verse como en un diagrama a continuación:
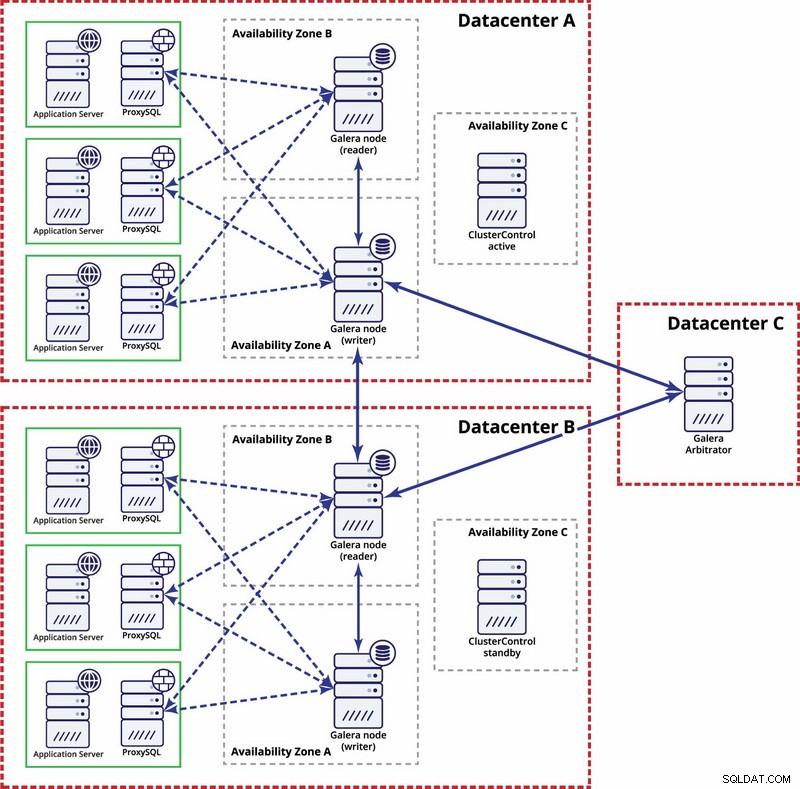
Replicación MySQL
Con la replicación de MySQL, el mayor problema es que no hay un mecanismo de quórum incorporado, como lo está en el clúster de Galera. Por lo tanto, se requieren más pasos para garantizar que su configuración no se vea afectada por un cerebro dividido.
Un método es evitar las conmutaciones por error automatizadas entre centros de datos. Puede configurar su solución de conmutación por error (puede ser a través de ClusterControl, MHA u Orchestrator) para la conmutación por error solo dentro de un único centro de datos. Si hubiera una interrupción total del centro de datos, sería el administrador quien decidiría cómo realizar la conmutación por error y cómo asegurarse de que no se utilizarán los servidores del centro de datos que falló.
Hay opciones para hacerlo más automatizado. Puede usar Consul para almacenar datos sobre los nodos en la configuración de replicación y cuál de ellos es el maestro. Luego, dependerá del administrador (o mediante algún script) actualizar esta entrada y mover las escrituras al segundo centro de datos. Puede beneficiarse de una configuración de Orchestrator/Raft en la que los nodos de Orchestrator se pueden distribuir en varios centros de datos y detectar el cerebro dividido. En base a esto podrías realizar diferentes acciones como, como mencionamos anteriormente, actualizar entradas en nuestro Cónsul o etcd. El punto es que este es un entorno mucho más complejo de configurar y automatizar que el clúster de Galera. A continuación, puede encontrar un ejemplo de configuración de varios centros de datos para la replicación de MySQL.
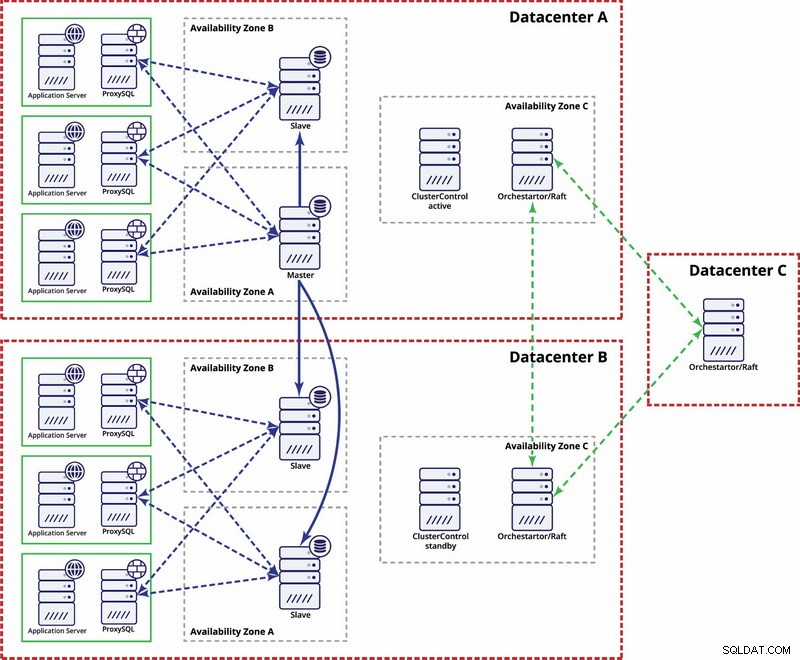
Tenga en cuenta que aún tiene que crear secuencias de comandos para que funcione, es decir, monitorear los nodos de Orchestrator en busca de un cerebro dividido y tomar las medidas necesarias para implementar STONITH y asegurarse de que el maestro en el centro de datos A no se usará una vez que la red converja y la conectividad ser restaurado.
Se produjo un cerebro dividido:¿qué hacer a continuación?
Ocurrió el peor de los casos y tenemos deriva de datos. Intentaremos darle algunos consejos sobre lo que se puede hacer aquí. Lamentablemente, los pasos exactos dependerán principalmente del diseño de su esquema, por lo que no será posible escribir una guía práctica precisa.
Lo que debes tener en cuenta es que el objetivo final será copiar datos de un maestro a otro y recrear todas las relaciones entre tablas.
En primer lugar, debe identificar qué nodo seguirá sirviendo datos como maestro. Este es un conjunto de datos al que fusionará los datos almacenados en la otra instancia "maestra". Una vez hecho esto, debe identificar los datos del maestro antiguo que faltan en el maestro actual. Esto será trabajo manual. Si tiene marcas de tiempo en sus tablas, puede aprovecharlas para identificar los datos que faltan. En última instancia, los registros binarios contendrán todas las modificaciones de datos para que pueda confiar en ellos. También es posible que deba confiar en su conocimiento de la estructura de datos y las relaciones entre las tablas. Si sus datos están normalizados, un registro en una tabla podría estar relacionado con registros en otras tablas. Por ejemplo, su aplicación puede insertar datos en la tabla de "usuario" que está relacionada con la tabla de "dirección" usando user_id. Deberá encontrar todas las filas relacionadas y extraerlas.
El siguiente paso será cargar estos datos en el nuevo maestro. Aquí viene la parte difícil:si preparó sus configuraciones de antemano, esto podría ser simplemente una cuestión de ejecutar un par de inserciones. Si no, esto puede ser bastante complejo. Se trata de la clave principal y los valores de índice únicos. Si los valores de su clave principal se generan como únicos en cada servidor usando algún tipo de generador de UUID o usando las configuraciones auto_increment_increment y auto_increment_offset en MySQL, puede estar seguro de que los datos del antiguo maestro que tiene que insertar no causarán una clave principal o un valor único. la clave entra en conflicto con los datos del nuevo maestro. De lo contrario, es posible que deba modificar manualmente los datos del maestro anterior para asegurarse de que pueda insertarse correctamente. Suena complejo, así que echemos un vistazo a un ejemplo.
Imaginemos que insertamos filas usando auto_increment en el nodo A, que es un maestro. En aras de la simplicidad, nos centraremos en una sola fila solamente. Hay columnas 'id' y 'valor'.
Si lo insertamos sin ninguna configuración particular, veremos entradas como la siguiente:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Esos se replicarán en el esclavo (B). Si ocurre el cerebro dividido y las escrituras se ejecutarán tanto en el maestro antiguo como en el nuevo, terminaremos con la siguiente situación:
A
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Como puede ver, no hay forma de simplemente volcar registros con ID de 1004, 1005 y 1006 del nodo A y almacenarlos en el nodo B porque terminaremos con entradas de clave principal duplicadas. Lo que debe hacerse es cambiar los valores de la columna de identificación en las filas que se insertarán a un valor mayor que el valor máximo de la columna de identificación de la tabla. Esto es todo lo que se necesita para filas individuales. Para relaciones más complejas, en las que intervienen varias tablas, es posible que deba realizar los cambios en varias ubicaciones.
Por otro lado, si hubiéramos anticipado este problema potencial y configurado nuestros nodos para almacenar identificaciones impares en el nodo A e identificaciones pares en el nodo B, el problema habría sido mucho más fácil de resolver.
El nodo A se configuró con auto_increment_offset =1 y auto_increment_increment =2
El nodo B se configuró con auto_increment_offset =2 y auto_increment_increment =2
Así es como se verían los datos en el nodo A antes del cerebro dividido:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Cuando ocurrió el cerebro dividido, se verá como a continuación.
Nodo A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nodo B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Ahora podemos copiar fácilmente los datos faltantes del nodo A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Y cárguelo en el nodo B y termine con el siguiente conjunto de datos:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Claro, las filas no están en el orden original, pero esto debería estar bien. En el peor de los casos, tendrá que ordenar por la columna "valor" en las consultas y quizás agregarle un índice para que la clasificación sea más rápida.
Ahora, imagine cientos o miles de filas y una estructura de tabla altamente normalizada:restaurar una fila puede significar que tendrá que restaurar varias de ellas en tablas adicionales. Con la necesidad de cambiar las identificaciones (porque no tenía configuraciones de protección en su lugar) en todas las filas relacionadas y todo esto siendo un trabajo manual, puede imaginar que esta no es la mejor situación para estar. Se necesita tiempo para recuperarse y es un proceso propenso a errores. Afortunadamente, como discutimos al principio, existen medios para minimizar las posibilidades de que el cerebro dividido afecte su sistema o para reducir el trabajo que debe realizarse para sincronizar sus nodos. Asegúrate de usarlos y mantente preparado.



