Implementar un clúster de base de datos no es ciencia espacial:hay muchos procedimientos sobre cómo hacerlo. Pero, ¿cómo sabe que lo que acaba de implementar está listo para la producción? Las implementaciones manuales también pueden ser tediosas y repetitivas. Dependiendo de la cantidad de nodos en el clúster, los pasos de implementación pueden llevar mucho tiempo y ser propensos a errores. Las herramientas de administración de configuración como Puppet, Chef y Ansible son populares en la implementación de infraestructura, pero para los clústeres de bases de datos con estado, debe realizar secuencias de comandos significativas para manejar la implementación de toda la pila de HA de la base de datos. Además, la plantilla/módulo/libro de recetas/rol elegido debe probarse meticulosamente antes de que pueda confiar en él como parte de la automatización de su infraestructura. Los cambios de versión requieren que los scripts se actualicen y prueben nuevamente.
La buena noticia es que ClusterControl automatiza las implementaciones de toda la pila, ¡y también de forma gratuita! Hemos implementado miles de clústeres de producción y tomamos una serie de precauciones para garantizar que estén listos para la producción Se admiten diferentes topologías, desde la replicación maestro-esclavo hasta el clúster Galera, NDB e InnoDB, con diferentes proxies de base de datos en la parte superior.
Una pila de alta disponibilidad, implementada a través de ClusterControl, consta de tres capas:
- Capa de base de datos (por ejemplo, Galera Cluster)
- Capa de proxy inverso (por ejemplo, HAProxy o ProxySQL)
- Capa Keepalived, que, con el uso de IP virtual, garantiza una alta disponibilidad de la capa proxy
En este blog, le mostraremos cómo implementar un Galera Cluster de grado de producción completo con balanceadores de carga para una configuración de alta disponibilidad. La configuración completa consta de 6 hosts:
- 1 host - ClusterControl (implementación, monitoreo, servidor de administración)
- 3 hosts:MySQL Galera Cluster
- 2 hosts:los proxies inversos actúan como equilibradores de carga frente al clúster.
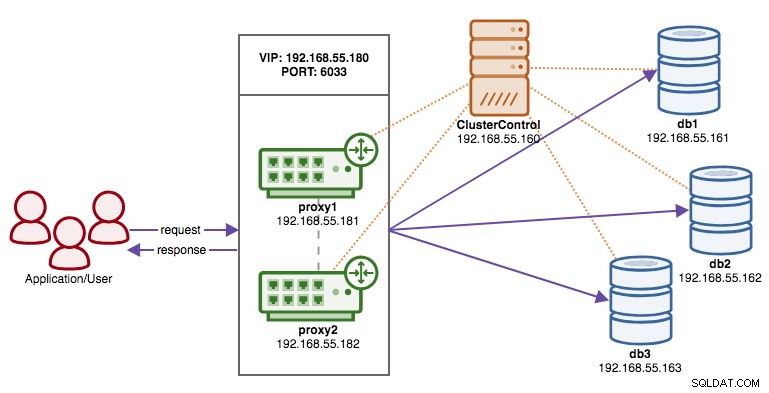
El siguiente diagrama ilustra nuestro resultado final una vez que se completa la implementación:
Requisitos
ClusterControl debe residir en un nodo independiente que no sea parte del clúster. Descargue ClusterControl y la página generará una licencia única para usted y le mostrará los pasos para instalar ClusterControl:
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userSiga las instrucciones en las que se le guiará para configurar el servidor MySQL, la contraseña raíz de MySQL en el nodo ClusterControl, la contraseña cmon para el uso de ClusterControl, etc. Debería obtener la siguiente línea una vez que se haya completado la instalación:
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Luego, en el servidor ClusterControl, genere una clave SSH que usaremos para configurar el SSH sin contraseña más adelante. Puede usar cualquier usuario en el sistema, pero debe tener la capacidad de realizar operaciones de superusuario (sudoer). En este ejemplo, elegimos al usuario root:
$ whoami
root
$ ssh-keygen -t rsaConfigure SSH sin contraseña para todos los nodos que le gustaría monitorear/administrar a través de ClusterControl. En este caso, configuraremos esto en todos los nodos de la pila (incluido el propio nodo ClusterControl). En el nodo ClusterControl, ejecute los siguientes comandos y especifique la contraseña raíz cuando se le solicite:
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Luego puede verificar si funciona ejecutando el siguiente comando en el nodo ClusterControl:
$ ssh example@sqldat.com "ls /root"Asegúrese de poder ver el resultado del comando anterior sin necesidad de ingresar la contraseña.
Implementación del clúster
ClusterControl es compatible con todos los proveedores de Galera Cluster (Codership, Percona y MariaDB). Hay algunas diferencias menores que pueden influir en su decisión de elegir al proveedor. Si desea conocer las diferencias entre ellos, consulte nuestra publicación de blog anterior:Comparación de clústeres de Galera:Codership vs Percona vs MariaDB.
Para la implementación de producción, un Galera Cluster de tres nodos es lo mínimo que debe tener. Siempre puede escalarlo más tarde una vez que se implementa el clúster, manualmente o a través de ClusterControl. Abriremos nuestra interfaz de usuario de ClusterControl en https://192.168.55.160/clustercontrol y crearemos el primer usuario administrador. Luego, vaya al menú superior y haga clic en Implementar -> MySQL Galera y se le presentará el siguiente cuadro de diálogo:
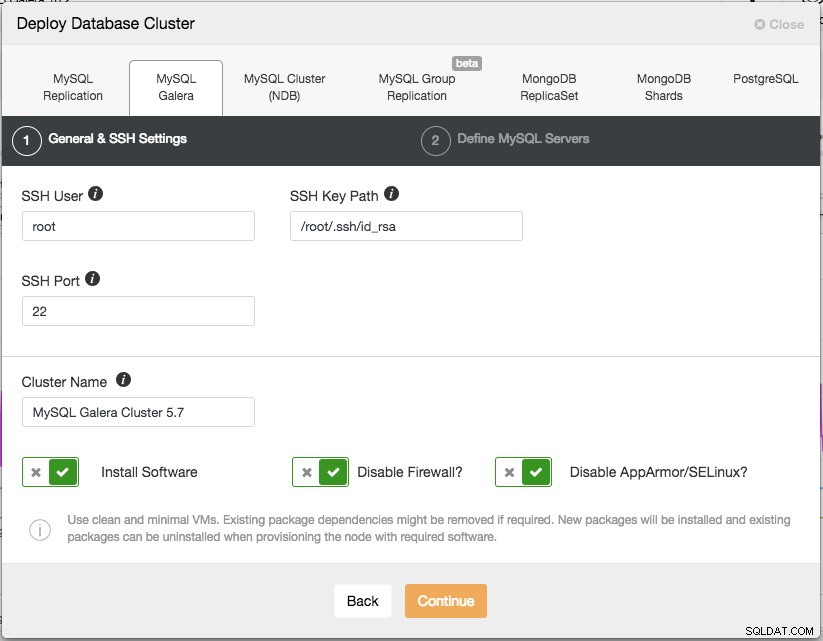
Hay dos pasos, el primero es "Configuración general y SSH". Aquí debemos configurar el usuario SSH que debe usar ClusterControl para conectarse a los nodos de la base de datos, junto con la ruta a la clave SSH (como se genera en la sección de requisitos previos), así como el puerto SSH de los nodos de la base de datos. ClusterControl supone que todos los nodos de la base de datos están configurados con el mismo usuario, clave y puerto SSH. A continuación, asigne un nombre al clúster, en este caso usaremos "MySQL Galera Cluster 5.7". Este valor se puede cambiar más adelante. Luego seleccione las opciones para indicarle a ClusterControl que instale el software requerido, deshabilite el firewall y también deshabilite el módulo de mejora de seguridad en la distribución de Linux en particular. Se recomienda activar todos estos para maximizar el potencial de una implementación exitosa.
Haga clic en Continuar y aparecerá el siguiente cuadro de diálogo:
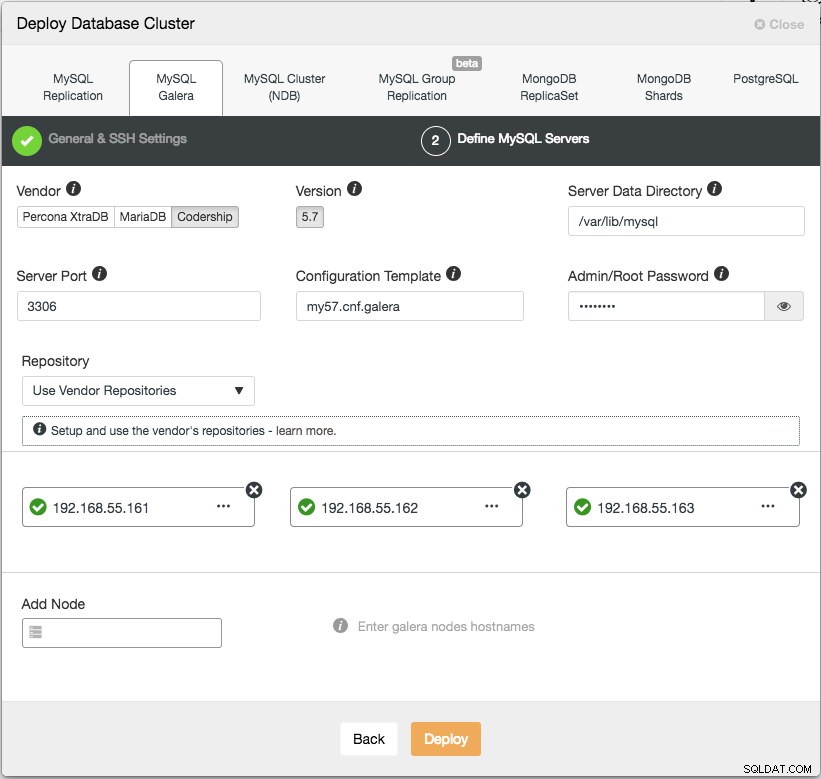
En el siguiente paso, debemos configurar los servidores de la base de datos (proveedor, versión, directorio de datos, puerto, etc.), que se explican por sí mismos. "Plantilla de configuración" es el nombre de archivo de la plantilla en /usr/share/cmon/templates del nodo ClusterControl. "Repositorio" es cómo ClusterControl debe configurar el repositorio en el nodo de la base de datos. De forma predeterminada, utilizará el repositorio del proveedor e instalará la última versión proporcionada por el repositorio. Sin embargo, en algunos casos, el usuario puede tener un repositorio preexistente duplicado del repositorio original debido a la restricción de la política de seguridad. Sin embargo, ClusterControl es compatible con la mayoría de ellos, como se describe en la guía del usuario, en Repositorio.
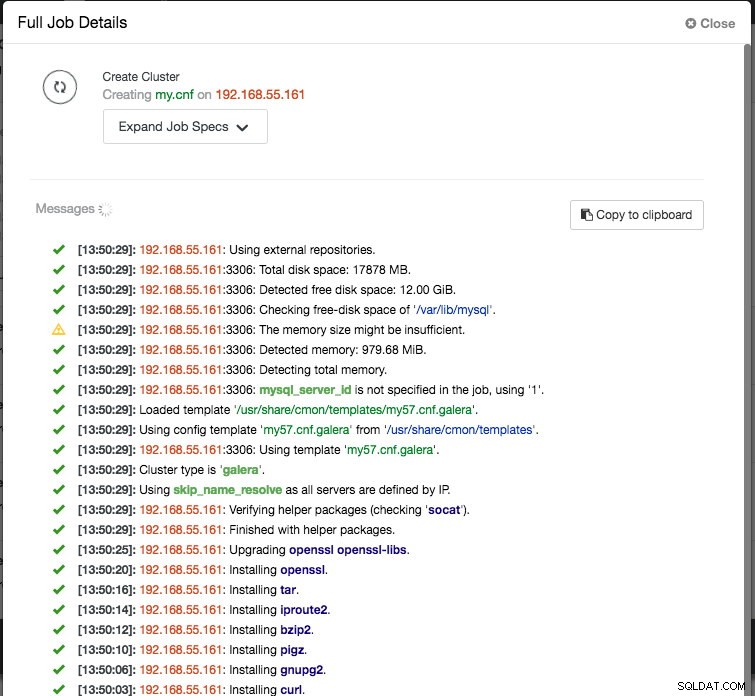
Por último, agregue la dirección IP o el nombre de host (debe ser un FQDN válido) de los nodos de la base de datos. Verá un icono de marca verde a la izquierda del nodo, lo que indica que ClusterControl pudo conectarse al nodo a través de SSH sin contraseña. Ahora estás listo para irte. Haga clic en Implementar para iniciar la implementación. Esto puede tardar de 15 a 20 minutos en completarse. Puede monitorear el progreso de la implementación en Actividad (menú superior) -> Trabajos -> Crear clúster :
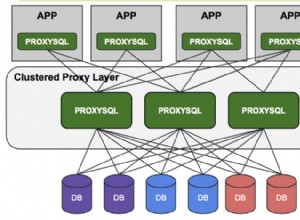
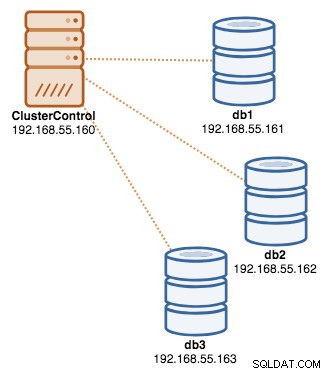
Una vez completada la implementación, en este punto, nuestra arquitectura se puede ilustrar de la siguiente manera:
Implementación de los balanceadores de carga
En Galera Cluster, todos los nodos son iguales:cada nodo tiene la misma función y el mismo conjunto de datos. Por lo tanto, no hay conmutación por error dentro del clúster si falla un nodo. Solo el lado de la aplicación requiere conmutación por error, para omitir los nodos que no funcionan mientras el clúster está particionado. Por lo tanto, se recomienda enfáticamente colocar balanceadores de carga encima de un Galera Cluster para:
- Unifique los múltiples puntos finales de la base de datos en un solo punto final (host del equilibrador de carga o dirección IP virtual como punto final).
- Equilibre las conexiones de la base de datos entre los servidores de la base de datos back-end.
- Realice comprobaciones de estado y solo reenvíe las conexiones de la base de datos a nodos en buen estado.
- Redirigir/reescribir/bloquear consultas ofensivas (mal escritas) antes de que lleguen a los servidores de la base de datos.
Hay tres opciones principales de proxies inversos para Galera Cluster:HAProxy, MariaDB MaxScale o ProxySQL; ClusterControl puede instalarlos y configurarlos automáticamente. En esta implementación, elegimos ProxySQL porque verifica todo lo anterior y además comprende el protocolo MySQL de los servidores back-end.
En esta arquitectura, queremos usar dos servidores ProxySQL para eliminar cualquier punto único de falla (SPOF) en el nivel de la base de datos, que se vinculará mediante una dirección IP virtual flotante. Explicaremos esto en la siguiente sección. Un nodo actuará como proxy activo y el otro como hot-standby. Cualquier nodo que tenga la dirección IP virtual en un momento dado es el nodo activo.
Para implementar el primer servidor ProxySQL, simplemente vaya al menú de acciones del clúster (lado derecho de la barra de resumen) y haga clic en Agregar equilibrador de carga -> ProxySQL -> Implementar ProxySQL y verá lo siguiente:
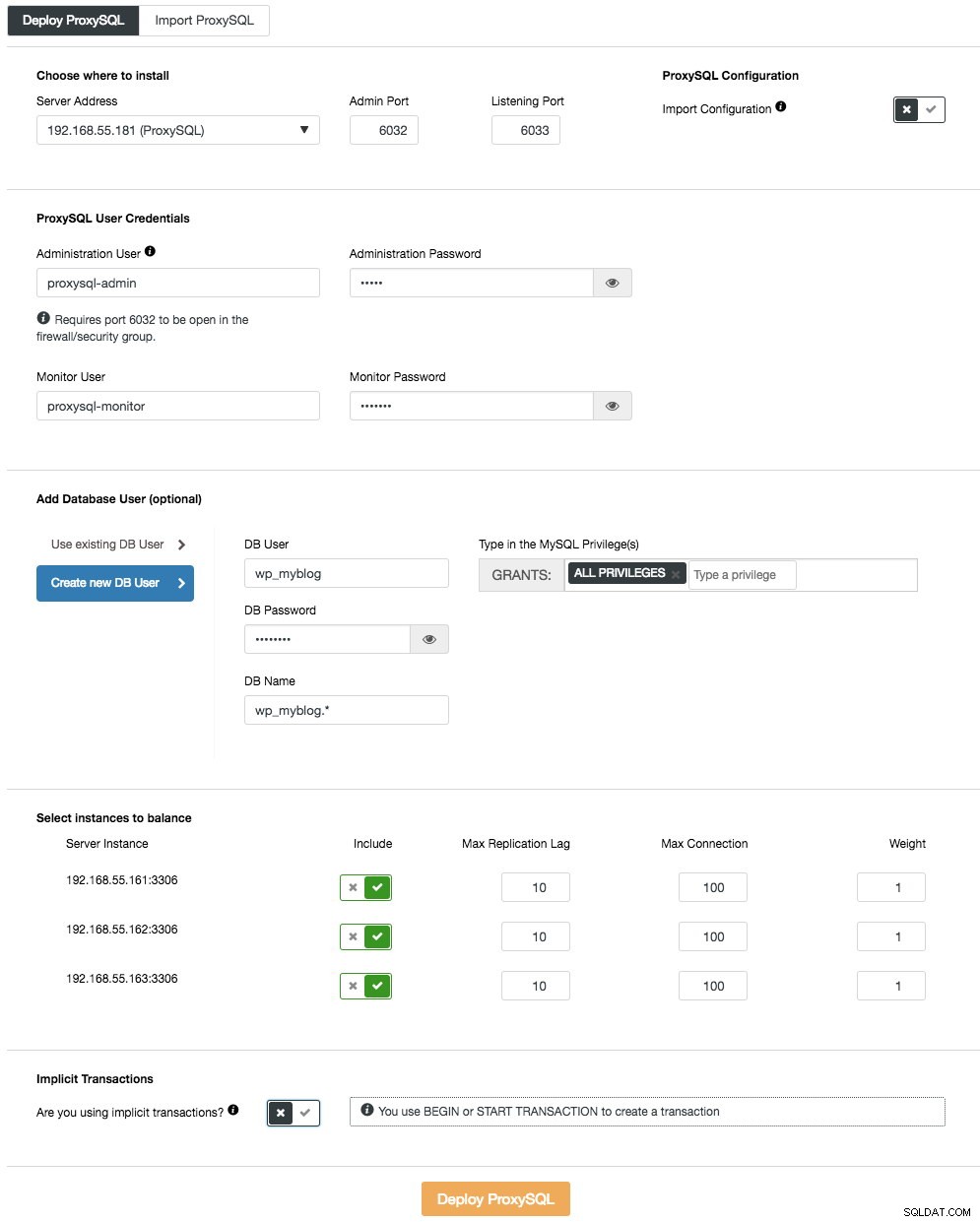
Una vez más, la mayoría de los campos se explican por sí mismos. En la sección "Usuario de la base de datos", ProxySQL actúa como una puerta de enlace a través de la cual su aplicación se conecta a la base de datos. La aplicación se autentica contra ProxySQL, por lo tanto, debe agregar todos los usuarios de todos los nodos MySQL de back-end, junto con sus contraseñas, en ProxySQL. Desde ClusterControl, puede crear un nuevo usuario para que lo use la aplicación:puede decidir su nombre, contraseña, acceso a qué bases de datos se otorgan y qué privilegios de MySQL tendrá ese usuario. Dicho usuario se creará tanto en MySQL como en ProxySQL. La segunda opción, más adecuada para las infraestructuras existentes, es utilizar la base de datos de usuarios existente. Debe pasar el nombre de usuario y la contraseña, y dicho usuario se creará solo en ProxySQL.
La última sección, "Transacción implícita", ClusterControl configurará ProxySQL para enviar todo el tráfico al maestro si iniciamos la transacción con SET autocommit=0. De lo contrario, si usa BEGIN o START TRANSACTION para crear una transacción, ClusterControl configurará la división de lectura/escritura en las reglas de consulta. Esto es para garantizar que ProxySQL manejará las transacciones correctamente. Si no tiene idea de cómo su aplicación hace esto, puede elegir lo último.
Repita la misma configuración para el segundo nodo ProxySQL, excepto el valor "Dirección del servidor", que es 192.168.55.182. Una vez hecho esto, ambos nodos aparecerán en la pestaña "Nodos" -> ProxySQL, donde podrá monitorearlos y administrarlos directamente desde la interfaz de usuario:
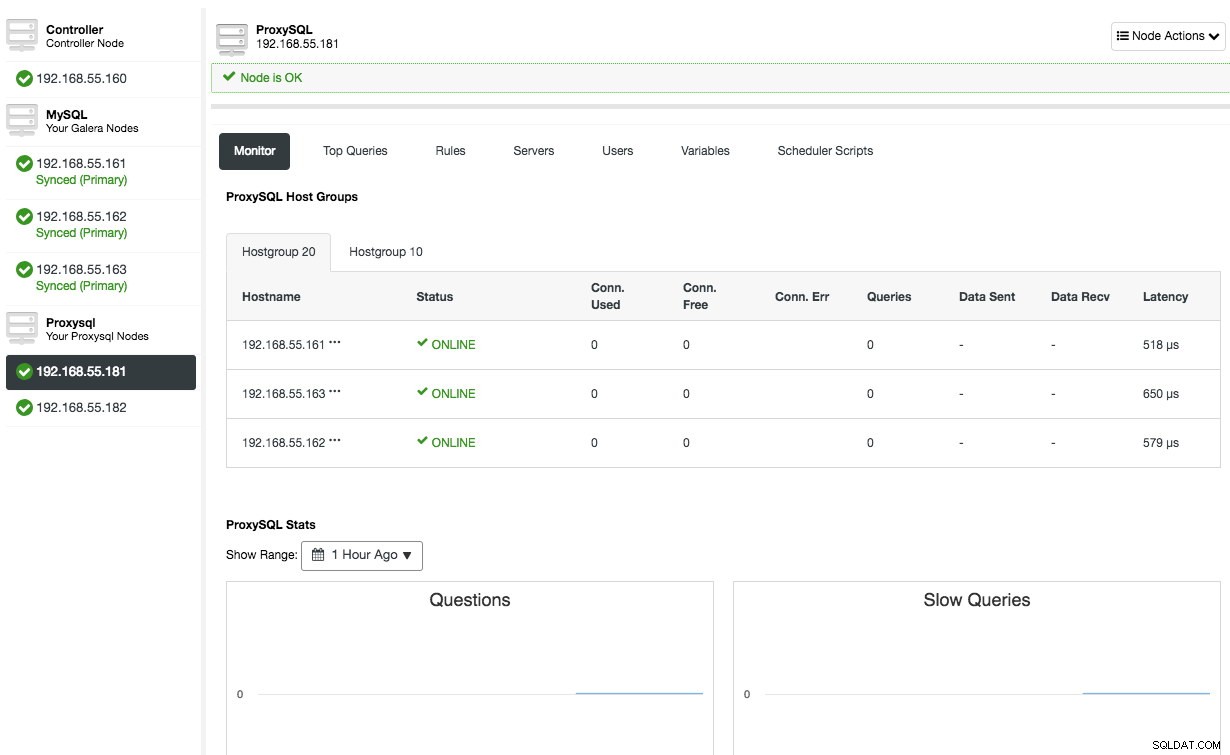
En este punto, nuestra arquitectura se ve así:
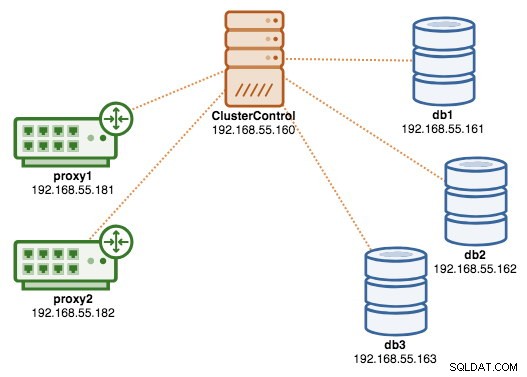
Si desea obtener más información sobre ProxySQL, consulte este tutorial - Balanceo de carga de base de datos para MySQL y MariaDB con ProxySQL - Tutorial.
Implementación de la dirección IP virtual
La parte final es la dirección IP virtual. Sin él, nuestros balanceadores de carga (proxies inversos) serían el eslabón débil, ya que serían un único punto de falla, a menos que la aplicación tenga la capacidad de redirigir automáticamente las conexiones fallidas de la base de datos a otro balanceador de carga. Sin embargo, es una buena práctica unificarlos usando una dirección IP virtual y simplificar el punto final de conexión a la capa de la base de datos.
Desde IU de ClusterControl -> Agregar balanceador de carga -> Keepalived -> Implementar Keepalived y seleccione los dos hosts ProxySQL que hemos implementado:
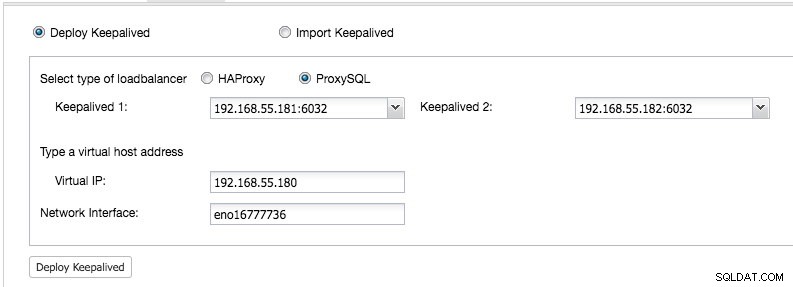
Además, especifique la dirección IP virtual y la interfaz de red para vincular la dirección IP. La interfaz de red debe existir en ambos nodos ProxySQL. Una vez implementado, debería ver las siguientes marcas verdes en la barra de resumen del clúster:

En este punto, nuestra arquitectura se puede ilustrar de la siguiente manera:
Nuestro clúster de base de datos ya está listo para su uso en producción. Puede importar su base de datos existente o crear una nueva base de datos nueva. Puede utilizar la función Gestión de esquemas y usuarios si la licencia de prueba no ha caducado.
Para comprender cómo ClusterControl configura Keepalived, consulte esta publicación de blog, Cómo ClusterControl configura la IP virtual y qué esperar durante la conmutación por error.
Conexión al clúster de la base de datos
Desde el punto de vista de la aplicación y del cliente, deben conectarse a 192.168.55.180 en el puerto 6033, que es la dirección IP virtual que flota sobre los balanceadores de carga. Por ejemplo, la configuración de la base de datos de Wordpress será algo como esto:
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Si desea acceder al clúster de la base de datos directamente, sin pasar por el balanceador de carga, simplemente puede conectarse al puerto 3306 de los hosts de la base de datos. Esto generalmente lo requiere el personal de DBA para administración, gestión y resolución de problemas. Con ClusterControl, la mayoría de estas operaciones se pueden realizar directamente desde la interfaz de usuario.
Reflexiones finales
Como se muestra arriba, implementar un clúster de base de datos ya no es una tarea difícil. Una vez implementado, existe un conjunto completo de funciones de monitoreo gratuitas, así como funciones comerciales para la administración de copias de seguridad, conmutación por error/recuperación y otras. La implementación rápida de diferentes tipos de topologías de clúster/replicación puede ser útil al evaluar soluciones de bases de datos de alta disponibilidad y cómo se adaptan a su entorno particular.