Galera Cluster, con su replicación (virtualmente) síncrona, se usa comúnmente en muchos tipos diferentes de entornos. Escalarlo agregando nuevos nodos no es difícil (o simplemente un par de clics cuando usa ClusterControl).
El principal problema con la replicación síncrona es, bueno, la parte síncrona que a menudo resulta en que todo el clúster es tan rápido como su nodo más lento. Cualquier escritura ejecutada en un clúster debe replicarse en todos los nodos y certificarse en ellos. Si, por alguna razón, este proceso se ralentiza, puede afectar seriamente la capacidad del clúster para adaptarse a las escrituras. Luego se activará el control de flujo, esto es para garantizar que el nodo más lento aún pueda mantenerse al día con la carga. Esto hace que sea bastante complicado para algunos de los escenarios comunes que ocurren en un entorno del mundo real.
En primer lugar, analicemos la recuperación ante desastres distribuida geográficamente. Claro, puede ejecutar clústeres en una red de área amplia, pero el aumento de la latencia tendrá un impacto significativo en el rendimiento del clúster. Esto limita seriamente la capacidad de usar una configuración de este tipo, especialmente en distancias más largas cuando la latencia es mayor.
Otro caso de uso bastante común:un entorno de prueba para la actualización de una versión principal. No es una buena idea mezclar diferentes versiones de los nodos de MariaDB Galera Cluster en el mismo clúster, incluso si es posible. Por otro lado, la migración a la versión más reciente requiere pruebas detalladas. Idealmente, se habrían probado tanto las lecturas como las escrituras. Una forma de lograrlo es crear un clúster de Galera separado y ejecutar las pruebas, pero le gustaría ejecutar las pruebas en un entorno lo más cercano posible a la producción. Una vez aprovisionado, un clúster se puede usar para pruebas con consultas del mundo real, pero sería difícil generar una carga de trabajo similar a la de producción. No puede mover parte del tráfico de producción a dicho sistema de prueba, esto se debe a que los datos no están actualizados.
Finalmente, la migración en sí. Nuevamente, lo que dijimos anteriormente, incluso si es posible mezclar versiones antiguas y nuevas de los nodos de Galera en el mismo clúster, no es la forma más segura de hacerlo.
Afortunadamente, la solución más simple para esos tres problemas sería conectar clústeres de Galera separados con una replicación asincrónica. ¿Qué hace que sea una solución tan buena? Bueno, es asíncrono, lo que hace que no afecte la replicación de Galera. No hay control de flujo, por lo que el rendimiento del clúster "maestro" no se verá afectado por el rendimiento del clúster "esclavo". Al igual que con todas las replicaciones asincrónicas, puede aparecer un retraso, pero siempre que se mantenga dentro de los límites aceptables, puede funcionar perfectamente bien. También debe tener en cuenta que hoy en día la replicación asincrónica se puede paralelizar (varios subprocesos pueden trabajar juntos para aumentar el ancho de banda) y reducir aún más el retraso de la replicación.
En esta publicación de blog, discutiremos cuáles son los pasos para implementar la replicación asíncrona entre los clústeres de MariaDB Galera.
¿Cómo configurar la replicación asíncrona entre clústeres de MariaDB Galera?
En primer lugar, tenemos que implementar un clúster. Para nuestros propósitos, configuramos un clúster de tres nodos. Mantendremos la configuración al mínimo, por lo que no discutiremos la complejidad de la aplicación y la capa de proxy. La capa de proxy puede ser muy útil para manejar tareas para las que desea implementar la replicación asincrónica:redirigir un subconjunto del tráfico de solo lectura al clúster de prueba, ayudar en la situación de recuperación ante desastres cuando el clúster "principal" no está disponible al redirigir el tráfico al clúster de recuperación ante desastres. Existen numerosos proxies que puede probar, según sus preferencias:HAProxy, MaxScale o ProxySQL; todos pueden usarse en dichas configuraciones y, según el caso, algunos de ellos pueden ayudarlo a administrar su tráfico.
Configuración del clúster de origen
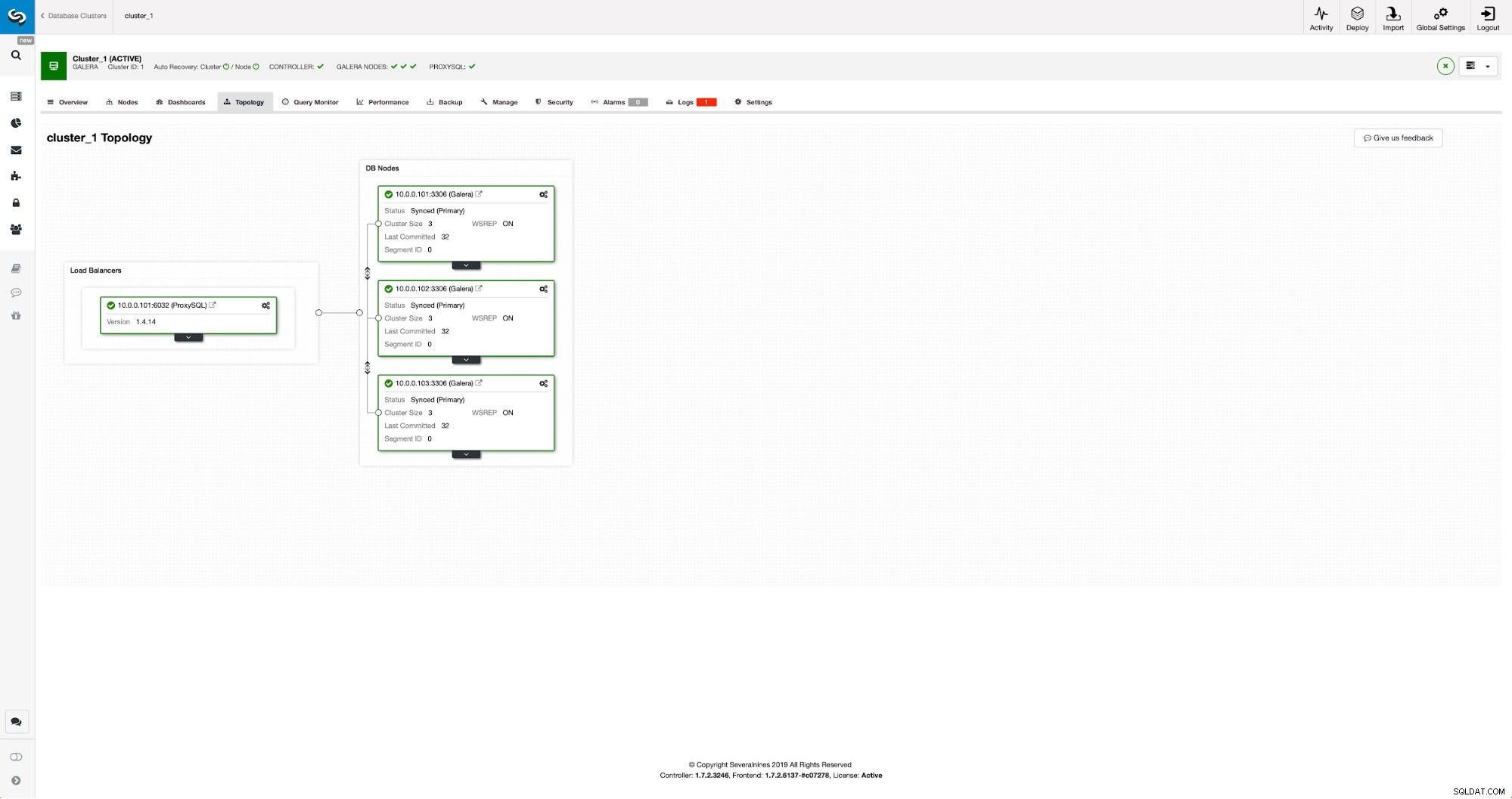
Nuestro clúster consta de tres nodos MariaDB 10.3, también implementamos ProxySQL para realizar la división de lectura y escritura y distribuir el tráfico entre todos los nodos del clúster. Esta no es una implementación de nivel de producción, para eso tendríamos que implementar más nodos ProxySQL y un Keepalived encima de ellos. Todavía es suficiente para nuestros propósitos. Para configurar la replicación asíncrona, deberemos tener un registro binario habilitado en nuestro clúster. Al menos un nodo, pero es mejor mantenerlo habilitado en todos ellos en caso de que el único nodo con binlog habilitado se caiga; entonces querrá tener otro nodo en el clúster en funcionamiento que pueda controlar.
Al habilitar el registro binario, asegúrese de configurar la rotación del registro binario para que los registros antiguos se eliminen en algún momento. Utilizará el formato de registro binario ROW. También debe asegurarse de tener GTID configurado y en uso; será muy útil cuando tenga que volver a esclavizar su clúster "esclavo" o si necesita habilitar la replicación de subprocesos múltiples. Como se trata de un clúster de Galera, desea tener configurado 'wsrep_gtid_domain_id' y habilitado 'wsrep_gtid_mode'. Esas configuraciones garantizarán que se generen GTID para el tráfico proveniente del clúster de Galera. Se puede encontrar más información en la documentación. Una vez hecho todo esto, puede continuar con la configuración del segundo clúster.
Configuración del clúster de destino
Dado que actualmente no hay un clúster de destino, debemos comenzar con su implementación. No cubriremos esos pasos en detalle, puede encontrar instrucciones en la documentación. En términos generales, el proceso consta de varios pasos:
- Configurar repositorios de MariaDB
- Instalar paquetes de MariaDB 10.3
- Configurar nodos para formar un clúster
Al principio comenzaremos con un solo nodo. Puede configurarlos todos para formar un grupo, pero luego debe detenerlos y usar solo uno para el siguiente paso. Ese nodo se convertirá en esclavo del clúster original. Usaremos mariabackup para aprovisionarlo. Luego configuraremos la replicación.
Primero, tenemos que crear un directorio donde almacenaremos la copia de seguridad:
mkdir /mnt/mariabackupLuego ejecutamos la copia de seguridad y la creamos en el directorio preparado en el paso anterior. Asegúrese de utilizar el usuario y la contraseña correctos para conectarse a la base de datos:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/A continuación, tenemos que copiar los archivos de copia de seguridad en el primer nodo del segundo clúster. Usamos scp para eso, puedes usar lo que quieras:rsync, netcat, cualquier cosa que funcione.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Después de que se haya copiado la copia de seguridad, debemos prepararla aplicando los archivos de registro:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!En caso de cualquier error, es posible que deba volver a ejecutar la copia de seguridad. Si todo salió bien, podemos eliminar los datos antiguos y reemplazarlos con la información de respaldo
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!También queremos establecer el propietario correcto de los archivos:
chown -R mysql.mysql /var/lib/mysql/Confiaremos en GTID para mantener la replicación consistente, por lo que necesitamos ver cuál fue el último GTID aplicado en esta copia de seguridad. Esa información se puede encontrar en el archivo xtrabackup_info que forma parte de la copia de seguridad:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'También tendremos que asegurarnos de que el nodo esclavo tenga registros binarios habilitados junto con 'log_slave_updates'. Idealmente, esto estará habilitado en todos los nodos en el segundo clúster, en caso de que el nodo "esclavo" falle y tenga que configurar la replicación usando otro nodo en el clúster esclavo.
Lo último que debemos hacer antes de que podamos configurar la replicación es crear un usuario que usaremos para ejecutar la replicación:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Eso es todo lo que necesitamos. Ahora, podemos iniciar el primer nodo en el segundo clúster, nuestro futuro esclavo:
galera_new_clusterUna vez que se inicia, podemos ingresar a MySQL CLI y configurarlo para que se convierta en esclavo, usando la posición GITD que encontramos un par de pasos antes:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Una vez hecho esto, finalmente podemos configurar la replicación e iniciarla:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)En este punto tenemos un Galera Cluster que consta de un nodo. Ese nodo también es un esclavo del clúster original (en particular, su maestro es el nodo 10.0.0.101). Para unirnos a otros nodos, usaremos SST, pero para que funcione primero debemos asegurarnos de que la configuración de SST sea correcta; tenga en cuenta que acabamos de reemplazar a todos los usuarios en nuestro segundo clúster con el contenido del clúster de origen. Lo que debe hacer ahora es asegurarse de que la configuración 'wsrep_sst_auth' del segundo clúster coincida con la del primer clúster. Una vez hecho esto, puede comenzar con los nodos restantes uno por uno y deben unirse al nodo existente (10.0.0.104), obtener los datos a través de SST y formar el clúster de Galera. Eventualmente, debería terminar con dos clústeres, tres nodos cada uno, con un enlace de replicación asincrónica entre ellos (de 10.0.0.101 a 10.0.0.104 en nuestro ejemplo). Puede confirmar que la replicación está funcionando comprobando el valor de:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)¿Cómo configurar la replicación asíncrona entre clústeres de MariaDB Galera mediante ClusterControl?
Al momento de escribir este blog, ClusterControl no tiene la funcionalidad para configurar la replicación asincrónica en múltiples clústeres, estamos trabajando en ello mientras escribo esto. No obstante, ClusterControl puede ser de gran ayuda en este proceso:le mostraremos cómo puede acelerar los laboriosos pasos manuales utilizando la automatización proporcionada por ClusterControl.
De lo que mostramos antes, podemos concluir que esos son los pasos generales a seguir al configurar la replicación entre dos clústeres de Galera:
- Implementar un nuevo clúster de Galera
- Aprovisionar un nuevo clúster usando datos del antiguo
- Configurar nuevo clúster (configuración de SST, registros binarios)
- Configurar la replicación entre el clúster antiguo y el nuevo
Los primeros tres puntos son algo que puede hacer fácilmente usando ClusterControl incluso ahora. Le mostraremos cómo hacerlo.
Implementar y aprovisionar un nuevo clúster de MariaDB Galera mediante ClusterControl
La situación inicial es similar:tenemos un clúster en funcionamiento. Tenemos que configurar el segundo. Una de las características más recientes de ClusterControl es una opción para implementar un nuevo clúster y aprovisionarlo utilizando los datos de la copia de seguridad. Esto es muy útil para crear entornos de prueba, también es una opción que usaremos para aprovisionar nuestro nuevo clúster para la configuración de la replicación. Por lo tanto, el primer paso que daremos será crear una copia de seguridad usando mariabackup:
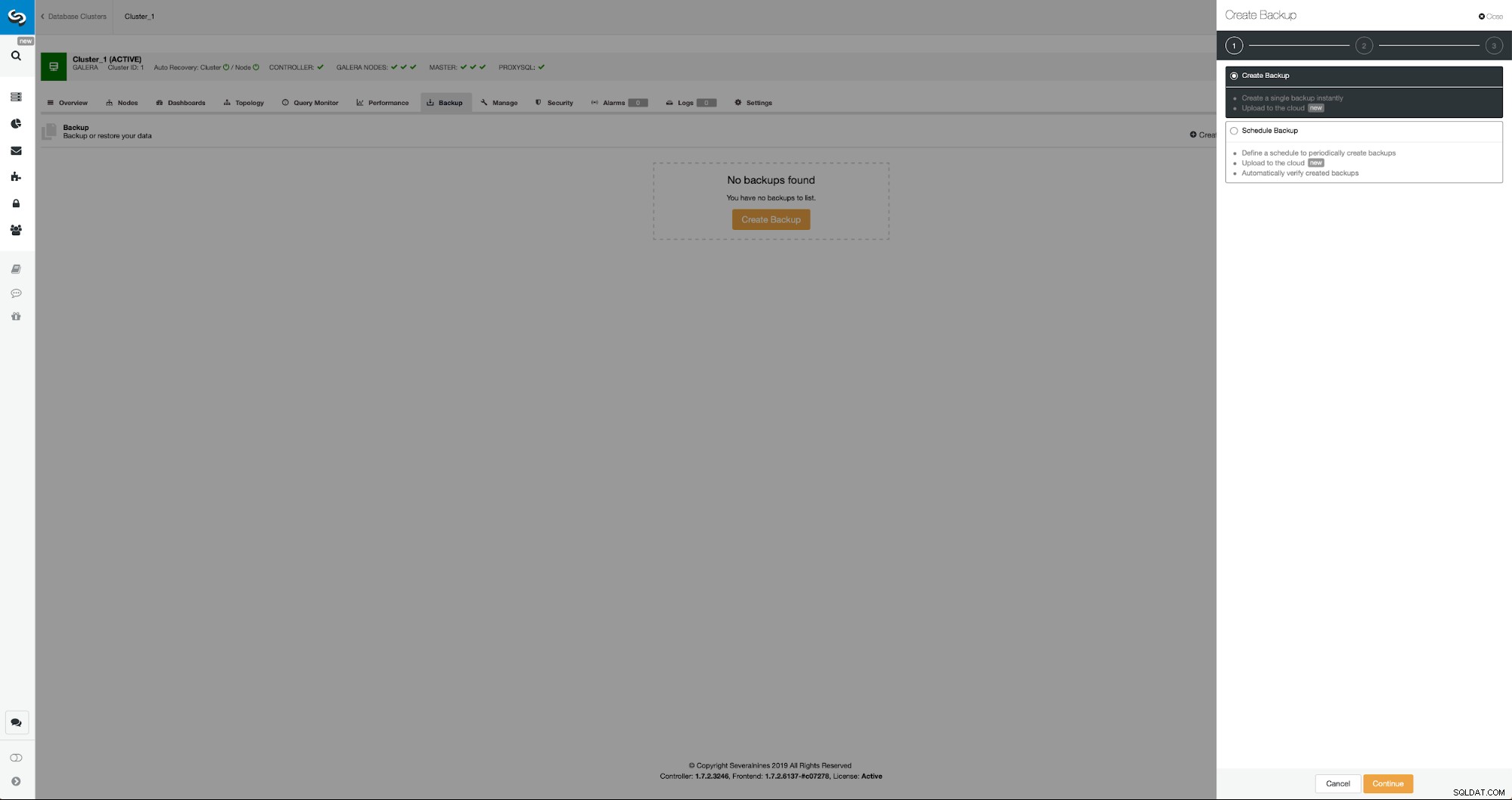
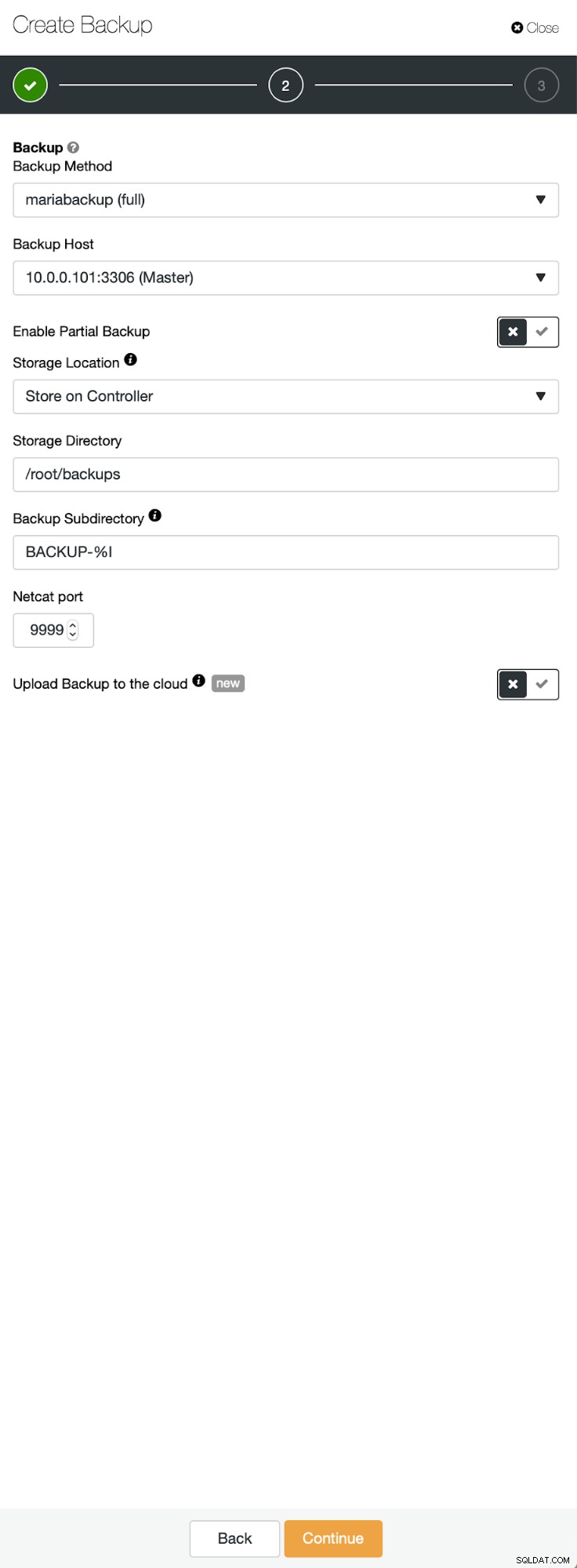
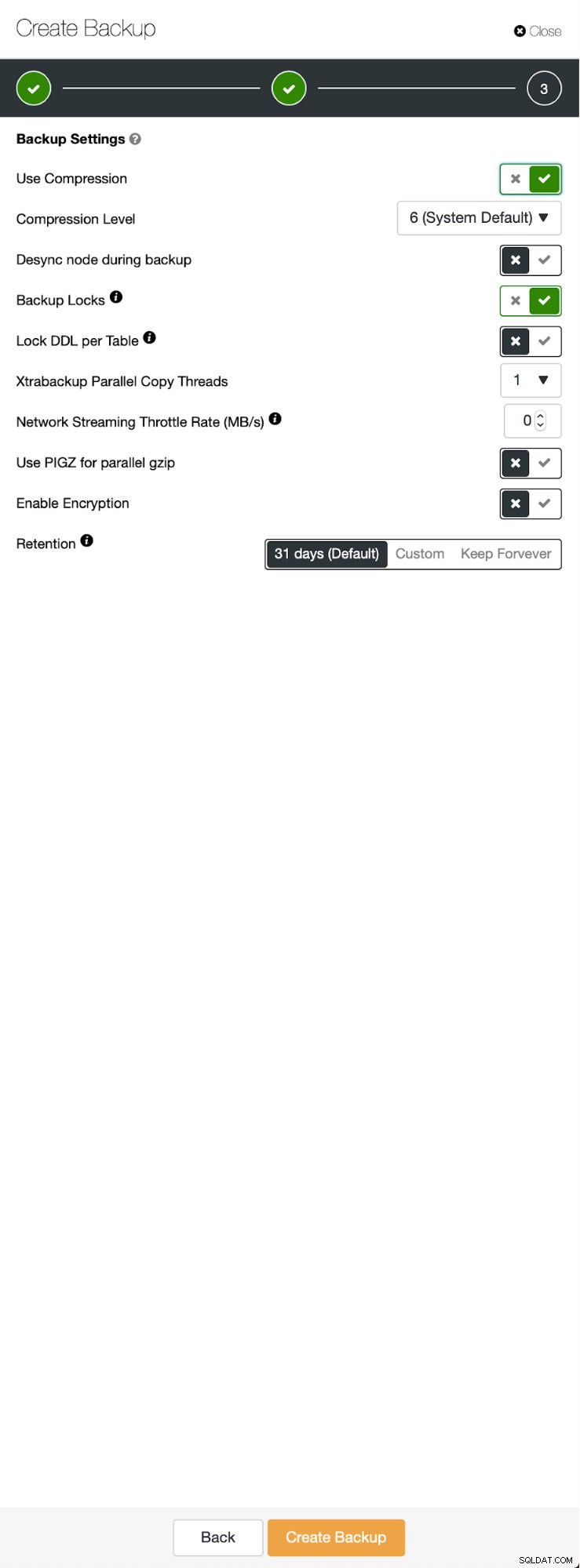
Tres pasos en los que elegimos el nodo para quitarle la copia de seguridad. Este nodo (10.0.0.101) se convertirá en maestro. Tiene que tener registros binarios habilitados. En nuestro caso, todos los nodos tienen binlog habilitado, pero si no lo tuvieran, es muy fácil habilitarlo desde ClusterControl; mostraremos los pasos más adelante, cuando lo hagamos para el segundo clúster.
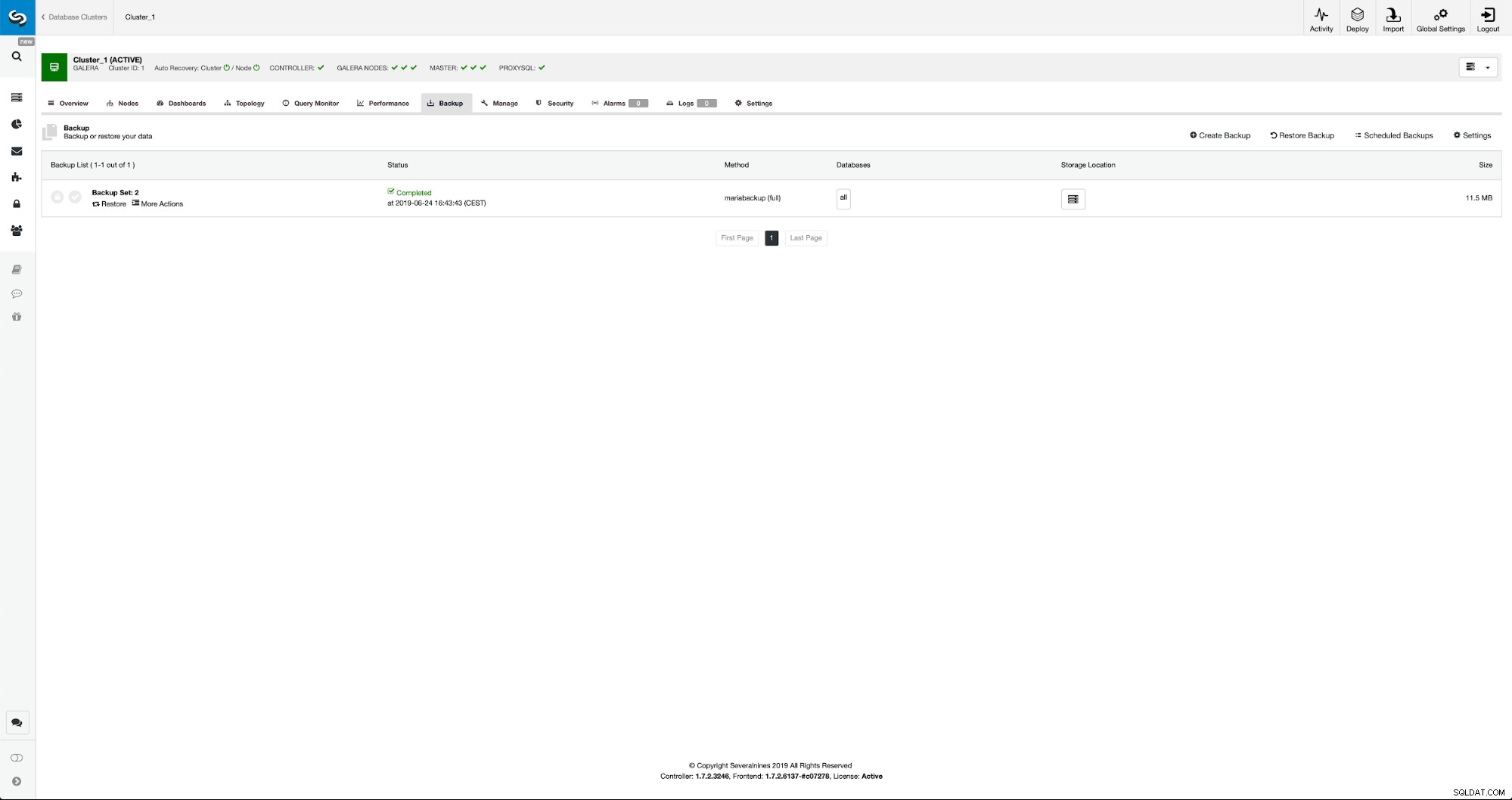
Una vez que se complete la copia de seguridad, se hará visible en la lista. Entonces podemos continuar y restaurarlo:

Si quisiéramos eso, incluso podríamos hacer la Recuperación de un punto en el tiempo, pero en nuestro caso realmente no importa:una vez que se configure la replicación, todas las transacciones requeridas de binlogs se aplicarán en el nuevo clúster.

Luego elegimos la opción para crear un clúster a partir de la copia de seguridad. Esto abre otro cuadro de diálogo:
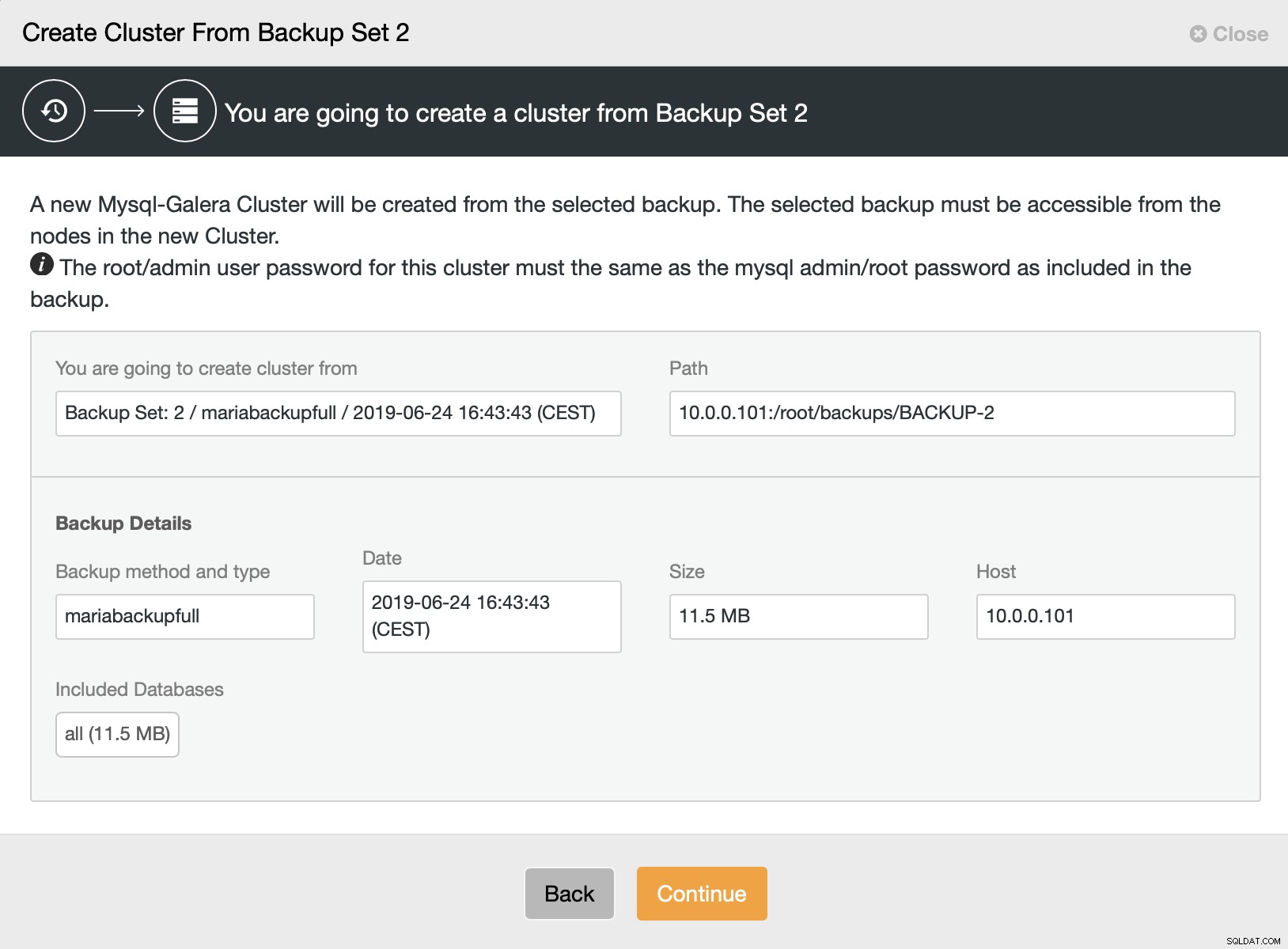
Es una confirmación de qué copia de seguridad se usará, de qué host se tomó la copia de seguridad, qué método se usó para crearla y algunos metadatos para ayudar a verificar si la copia de seguridad se ve bien.
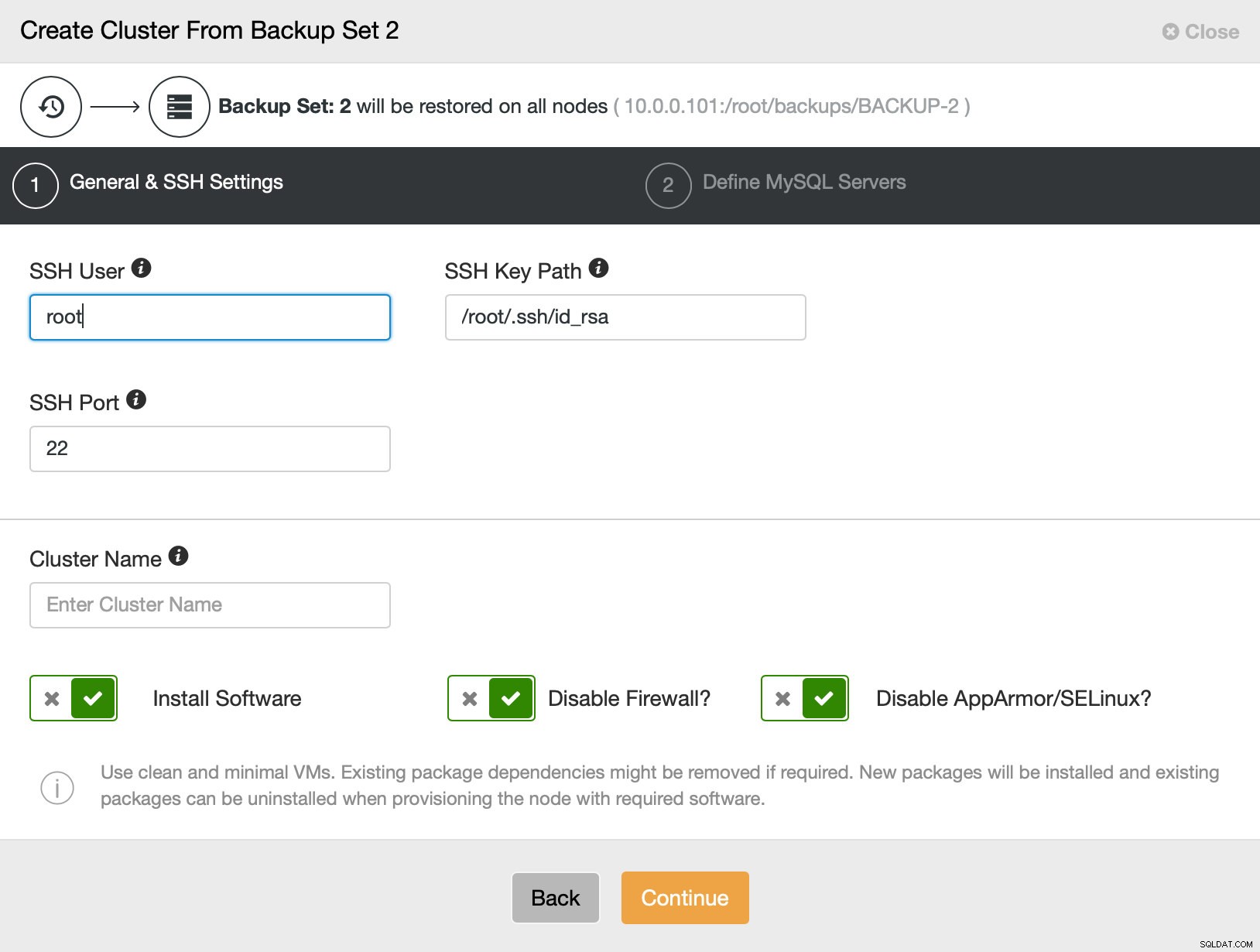
Luego, básicamente vamos al asistente de implementación regular en el que tenemos que definir la conectividad SSH entre el host de ClusterControl y los nodos para implementar el clúster (el requisito para ClusterControl) y, en el segundo paso, el proveedor, la versión, la contraseña y los nodos para implementar. en:
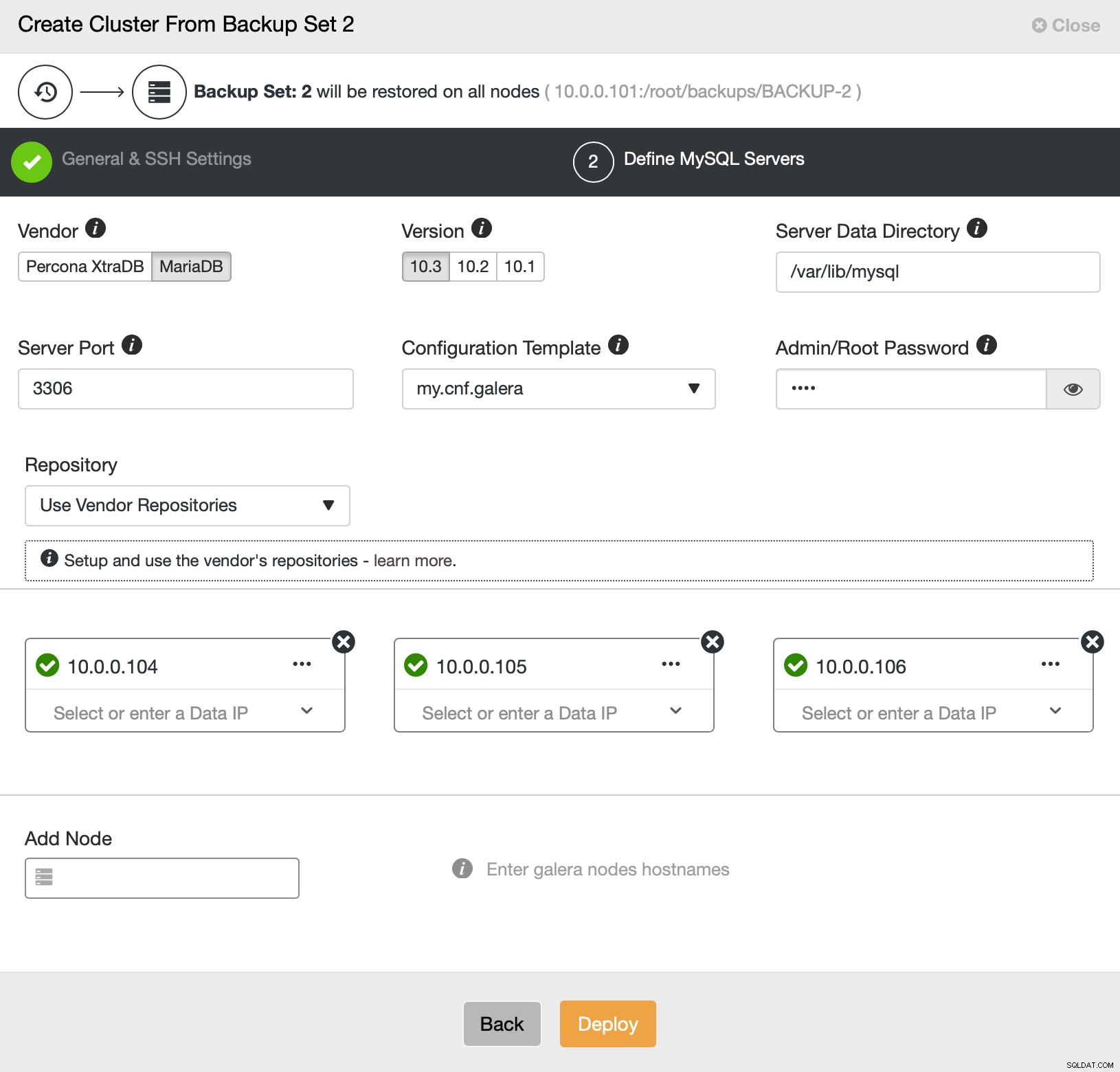
Eso es todo con respecto a la implementación y el aprovisionamiento. ClusterControl configurará el nuevo clúster y lo aprovisionará utilizando los datos del antiguo.
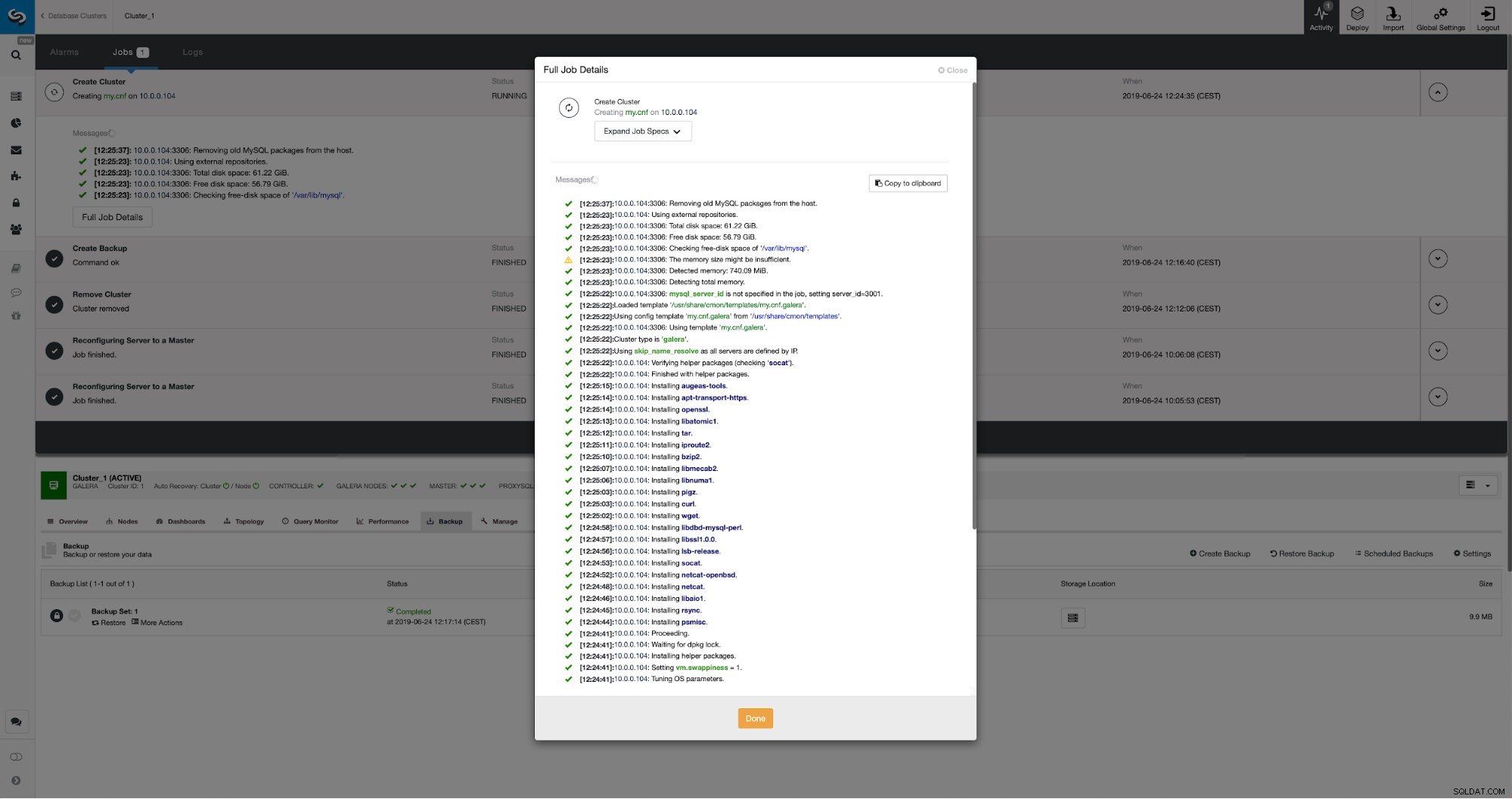
Podemos monitorear el progreso en la pestaña de actividad. Una vez completado, el segundo grupo aparecerá en la lista de grupos en ClusterControl.
Reconfiguración del nuevo clúster mediante ClusterControl
Ahora, tenemos que volver a configurar el clúster:habilitaremos los registros binarios. En el proceso manual tuvimos que hacer cambios en la configuración de wsrep_sst_auth y también en las entradas de configuración en las secciones [mysqldump] y [xtrabackup] de la configuración. Esas configuraciones se pueden encontrar en el archivo secrets-backup.cnf. Esta vez no es necesario ya que ClusterControl generó nuevas contraseñas para el clúster y configuró los archivos correctamente. Sin embargo, lo que es importante tener en cuenta es que si cambia la contraseña del usuario 'backupuser'@'127.0.0.1' en el clúster original, deberá realizar cambios de configuración en el segundo clúster también para reflejar eso como cambios en el primer grupo se replicará en el segundo grupo.
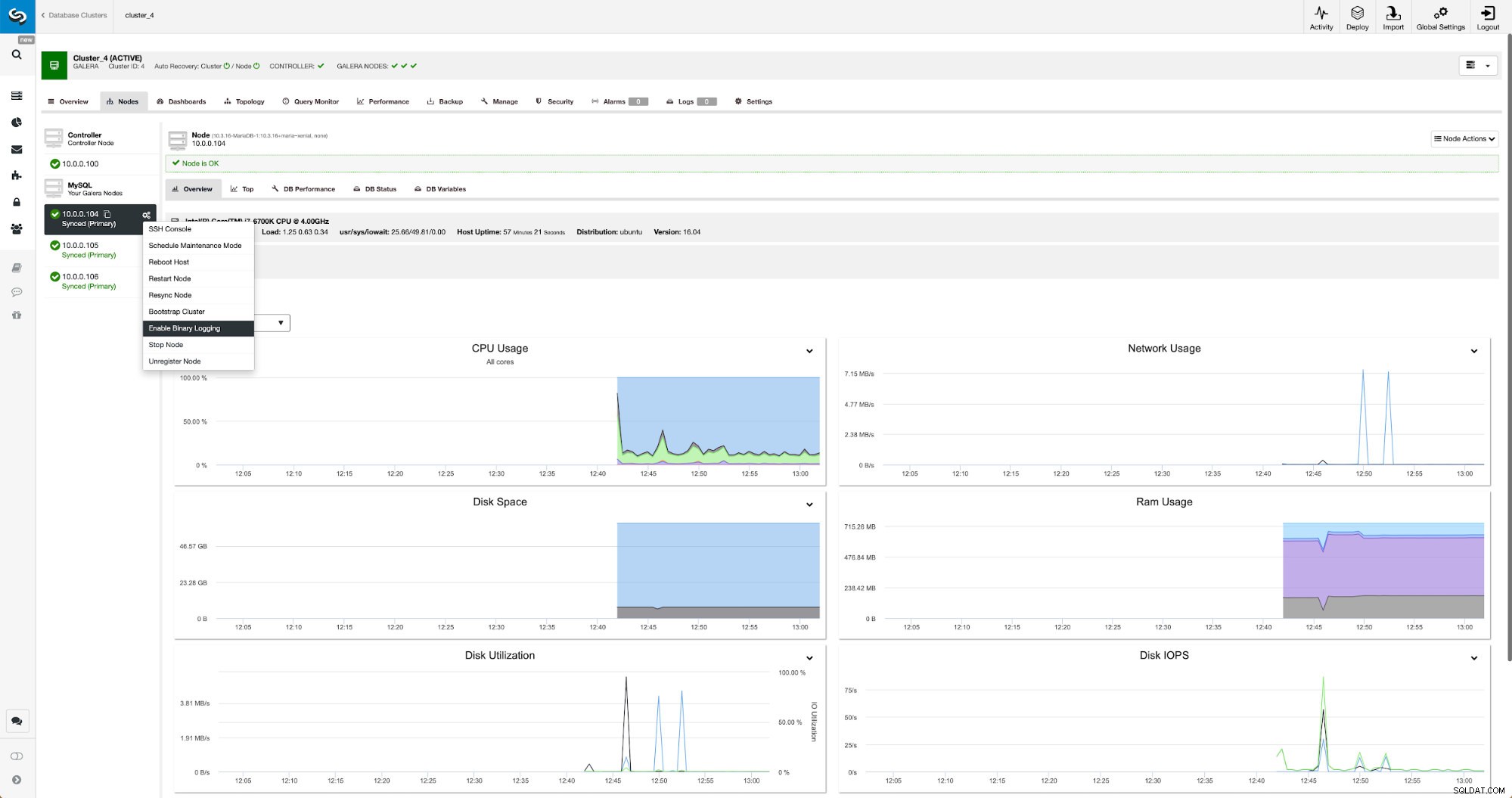
Los registros binarios se pueden habilitar desde la sección Nodos. Debe elegir nodo por nodo y ejecutar el trabajo "Habilitar registro binario". Se le presentará un cuadro de diálogo:
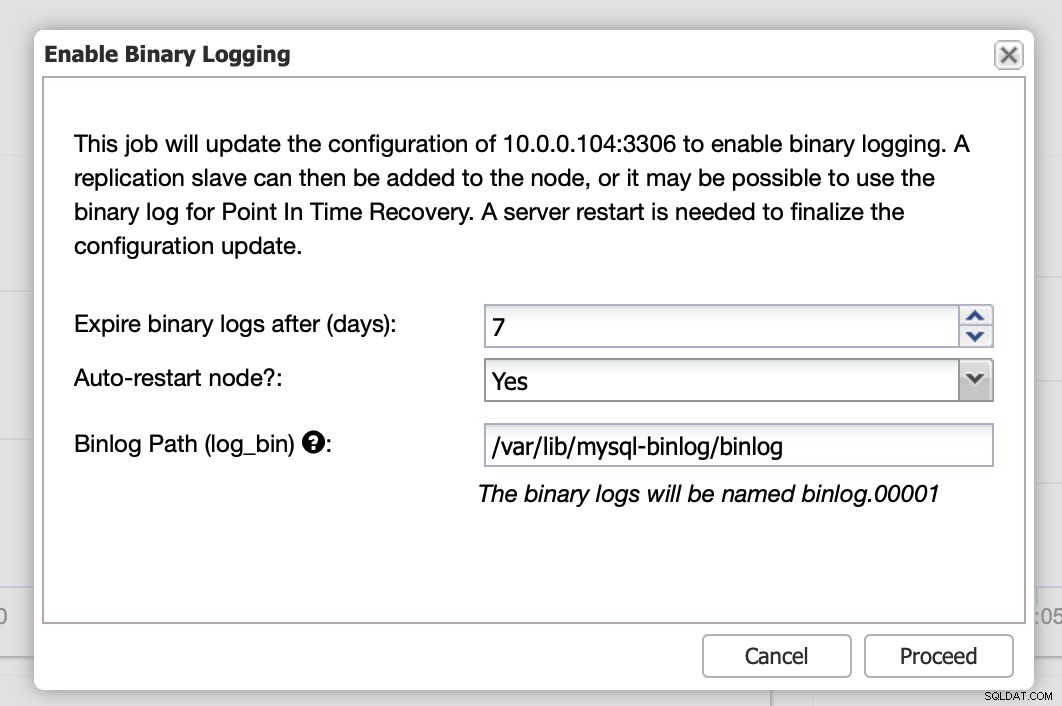
Aquí puede definir cuánto tiempo le gustaría conservar los registros, dónde deben almacenarse y si ClusterControl debe reiniciar el nodo para que pueda aplicar los cambios:la configuración del registro binario no es dinámica y MariaDB debe reiniciarse para aplicar esos cambios.
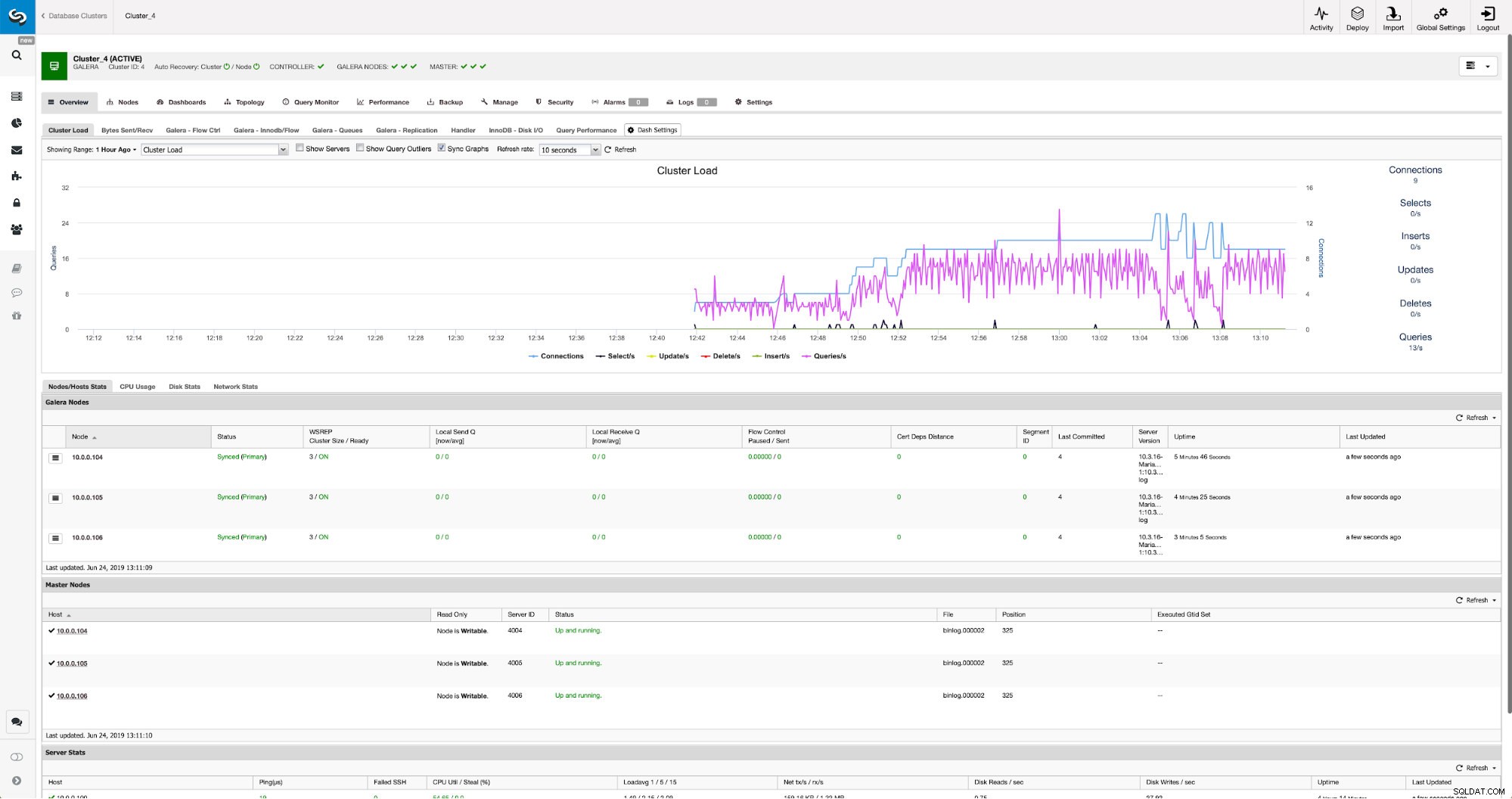
Cuando se completen los cambios, verá todos los nodos marcados como "maestros", lo que significa que esos nodos tienen habilitado el registro binario y pueden actuar como maestros.
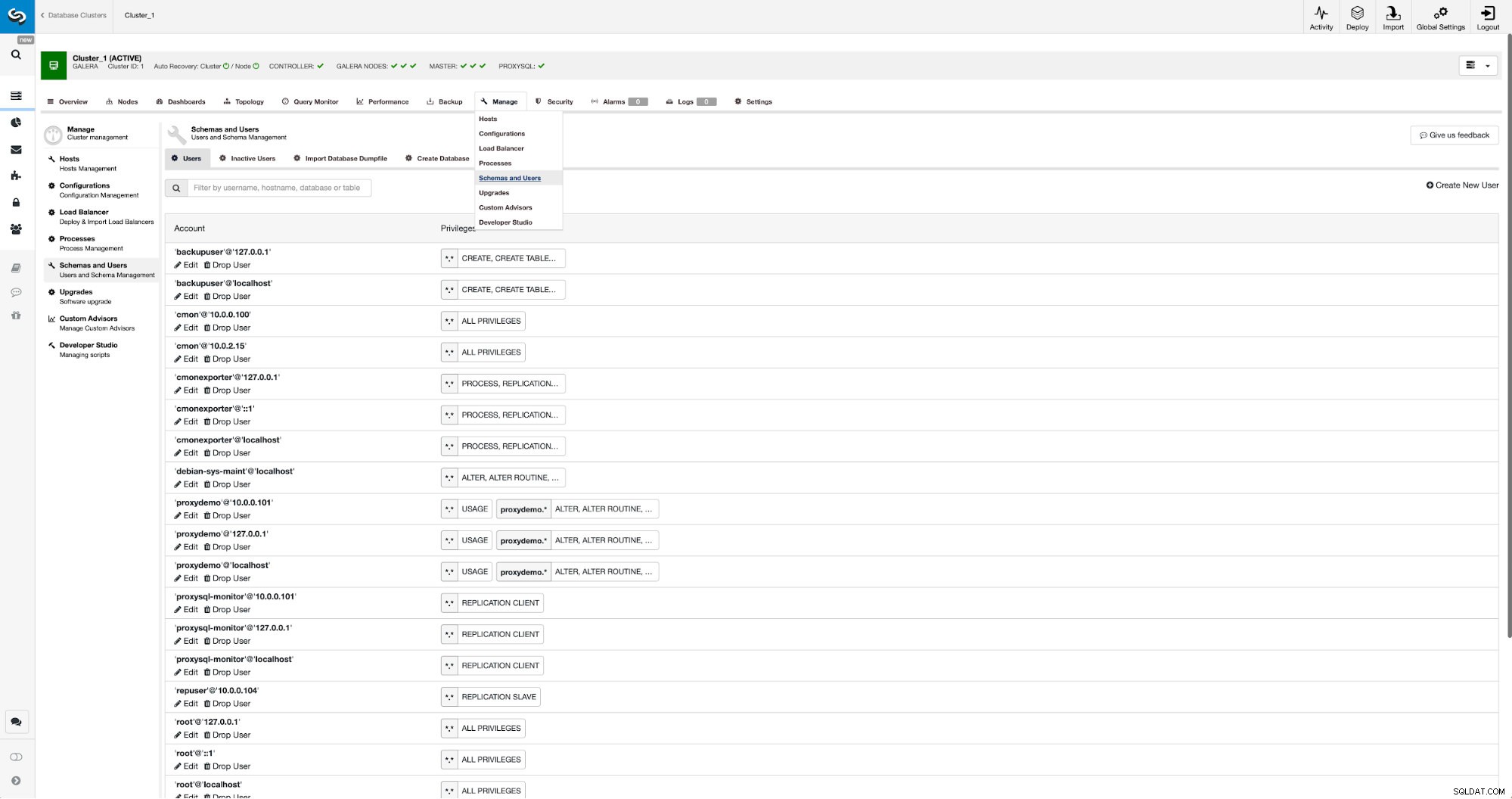
Si aún no tenemos un usuario de replicación creado, tenemos que hacerlo. En el primer clúster tenemos que ir a Administrar -> Esquemas y Usuarios:
En el lado derecho tenemos una opción para crear un nuevo usuario:
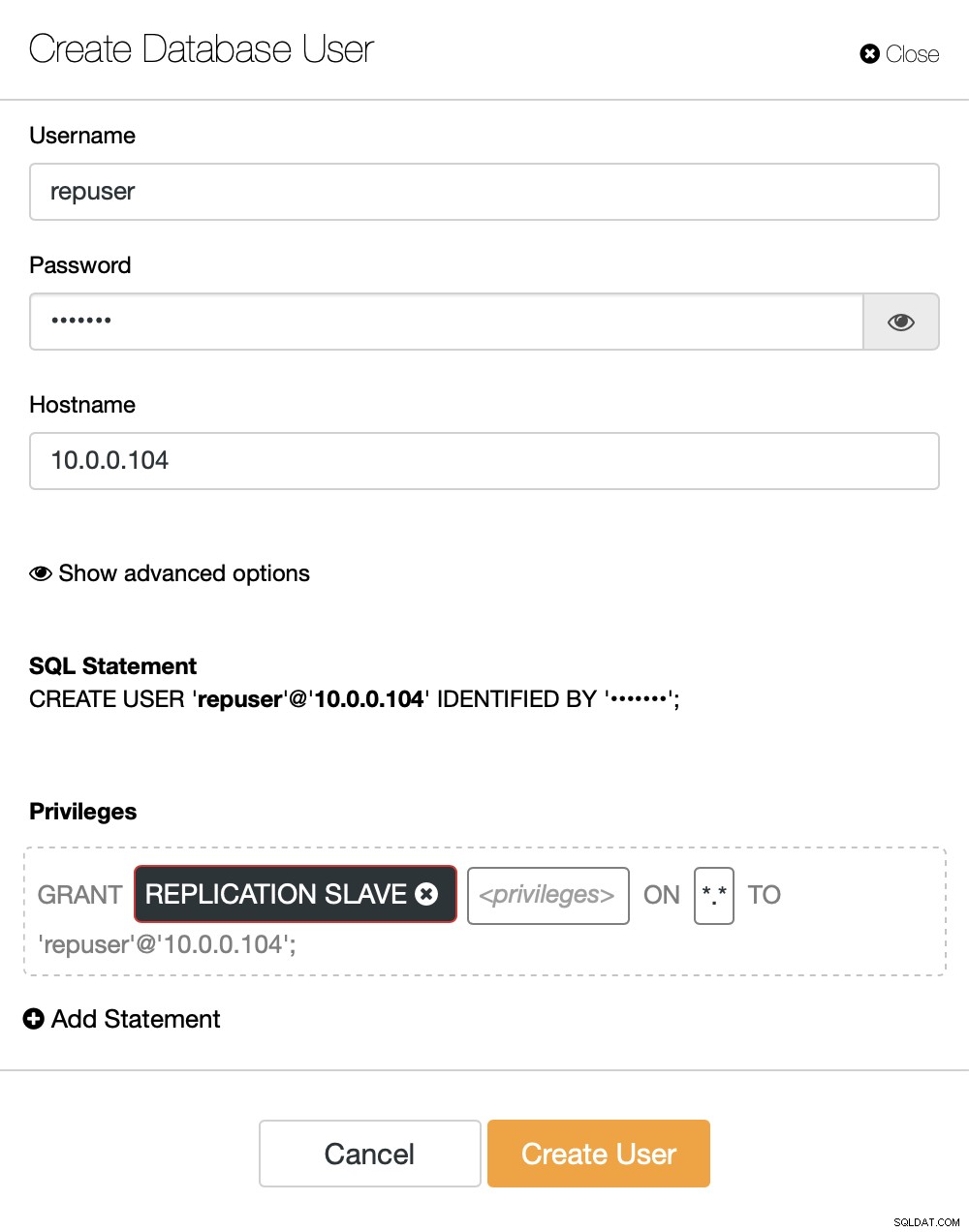
Esto concluye la configuración requerida para configurar la replicación.
Configuración de la replicación entre clústeres mediante ClusterControl
Como dijimos, estamos trabajando en la automatización de esta parte. Actualmente tiene que hacerse manualmente. Como recordará, necesitamos la posición GITD de nuestra copia de seguridad y luego ejecutar un par de comandos usando MySQL CLI. Los datos de GTID están disponibles en la copia de seguridad. ClusterControl crea una copia de seguridad usando xbstream/mbstream y luego la comprime. Nuestra copia de seguridad se almacena en el host ClusterControl donde no tenemos acceso al binario mbstream. Puede intentar instalarlo o puede copiar el archivo de copia de seguridad en la ubicación donde dicho binario está disponible:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Una vez hecho esto, en 10.0.0.104 queremos verificar el contenido del archivo xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Finalmente, configuramos la replicación y la iniciamos:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Eso es todo:acabamos de configurar la replicación asíncrona entre dos clústeres de MariaDB Galera mediante ClusterControl. Como habrás podido ver, ClusterControl pudo automatizar la mayoría de los pasos que tuvimos que realizar para configurar este entorno.