El DBA típico de MySQL puede estar familiarizado con el trabajo y la administración de una base de datos OLTP (Procesamiento de transacciones en línea) como parte de su rutina diaria. Es posible que esté familiarizado con su funcionamiento y con la forma de gestionar operaciones complejas. Si bien el motor de almacenamiento predeterminado que incluye MySQL es lo suficientemente bueno para OLAP (procesamiento analítico en línea), es bastante simple, especialmente para aquellos a quienes les gustaría aprender inteligencia artificial o que se ocupan de la previsión, la extracción de datos y el análisis de datos.
En este blog, vamos a hablar sobre MariaDB ColumnStore. El contenido se adaptará para el beneficio del administrador de bases de datos de MySQL que podría tener menos conocimientos sobre ColumnStore y cómo podría aplicarse a las aplicaciones OLAP (procesamiento analítico en línea).
OLTP frente a OLAP
OLTP
Recursos relacionados Analytics with MariaDB AX:el almacén de datos en columnas de código abierto Una introducción a las bases de datos de series temporales Cargas de trabajo híbridas de OLTP/base de datos de Analytics en el clúster de Galera mediante esclavos asíncronosLa actividad típica de MySQL DBA para manejar este tipo de datos es mediante el uso de OLTP (procesamiento de transacciones en línea). OLTP se caracteriza por grandes transacciones de bases de datos que realizan inserciones, actualizaciones o eliminaciones. Las bases de datos de tipo OLTP están especializadas para el procesamiento rápido de consultas y el mantenimiento de la integridad de los datos mientras se accede a ellos en múltiples entornos. Su eficacia se mide por el número de transacciones por segundo (tps). Es bastante común que las tablas de relación padre-hijo (después de la implementación del formulario de normalización) reduzcan los datos redundantes en una tabla.
Los registros en una tabla comúnmente se procesan y almacenan secuencialmente en una forma orientada a filas y están altamente indexados con claves únicas para optimizar la recuperación o escritura de datos. Esto también es común para MySQL, especialmente cuando se trata de inserciones grandes, escrituras simultáneas o inserciones masivas. La mayoría de los motores de almacenamiento compatibles con MariaDB son aplicables para aplicaciones OLTP:InnoDB (el motor de almacenamiento predeterminado desde 10.2), XtraDB, TokuDB, MyRocks o MyISAM/Aria.
Las aplicaciones como CMS, FinTech, aplicaciones web a menudo se ocupan de escrituras y lecturas pesadas y, a menudo, requieren un alto rendimiento. Para que estas aplicaciones funcionen, a menudo se requiere una gran experiencia en alta disponibilidad, redundancia, resiliencia y recuperación.
OLAP
OLAP se enfrenta a los mismos desafíos que OLTP, pero utiliza un enfoque diferente (especialmente cuando se trata de la recuperación de datos). OLAP se ocupa de conjuntos de datos más grandes y es común para el almacenamiento de datos, a menudo utilizado para el tipo de aplicaciones de inteligencia empresarial. Suele utilizarse para la gestión del rendimiento empresarial, la planificación, la elaboración de presupuestos, la previsión, la elaboración de informes financieros, el análisis, los modelos de simulación, el descubrimiento de conocimientos y la elaboración de informes de almacén de datos.
Los datos que se almacenan en OLAP normalmente no son tan importantes como los que se almacenan en OLTP. Esto se debe a que la mayoría de los datos se pueden simular provenientes de OLTP y luego se pueden alimentar a su base de datos OLAP. Estos datos se utilizan normalmente para la carga masiva, a menudo necesarios para análisis de negocios que eventualmente se representan en gráficos visuales. OLAP también realiza análisis multidimensionales de datos comerciales y brinda resultados que pueden usarse para cálculos complejos, análisis de tendencias o modelado de datos sofisticado.
OLAP generalmente almacena datos de manera persistente utilizando un formato de columnas. Sin embargo, en MariaDB ColumnStore, los registros se desglosan en función de sus columnas y se almacenan por separado en un archivo. De esta manera, la recuperación de datos es muy eficiente, ya que escanea solo la columna relevante a la que se hace referencia en su consulta de declaración SELECT.
Piénselo de esta manera:el procesamiento OLTP maneja sus transacciones de datos cruciales y diarias que ejecutan su aplicación comercial, mientras que OLAP lo ayuda a administrar, predecir, analizar y comercializar mejor su producto:los componentes básicos para tener una aplicación comercial.
¿Qué es MariaDB ColumnStore?
MariaDB ColumnStore es un motor de almacenamiento en columnas conectable que se ejecuta en el servidor MariaDB. Utiliza una arquitectura de datos distribuidos en paralelo mientras mantiene la misma interfaz ANSI SQL que se usa en toda la cartera de servidores MariaDB. Este motor de almacenamiento ha existido por un tiempo, ya que originalmente fue portado desde InfiniDB (un código ahora extinto que todavía está disponible en github). Está diseñado para escalar big data (para procesar petabytes de datos), escalabilidad lineal y real. -Tiempo de respuesta a las consultas de análisis. Aprovecha los beneficios de E/S del almacenamiento en columnas; compresión, proyección justo a tiempo y particionamiento horizontal y vertical para ofrecer un gran rendimiento al analizar grandes conjuntos de datos.
Por último, MariaDB ColumnStore es la columna vertebral de su producto MariaDB AX como el principal motor de almacenamiento utilizado por esta tecnología.
¿En qué se diferencia MariaDB ColumnStore de InnoDB?
InnoDB es aplicable para el procesamiento OLTP que requiere que su aplicación responda de la manera más rápida posible. Es útil si su aplicación trata con esa naturaleza. Por otro lado, MariaDB ColumnStore es una opción adecuada para administrar grandes transacciones de datos o grandes conjuntos de datos que involucran uniones complejas, agregación en diferentes niveles de jerarquía de dimensiones, proyectar un total financiero para una amplia gama de años o usar selecciones de igualdad y rango. . Estos enfoques que usan ColumnStore no requieren que indexe estos campos, ya que puede funcionar lo suficientemente rápido. InnoDB realmente no puede manejar este tipo de rendimiento, aunque no hay nada que le impida intentarlo como se puede hacer con InnoDB, pero a un costo. Esto requiere que agregue índices, lo que agrega grandes cantidades de datos a su almacenamiento en disco. Esto significa que puede llevar más tiempo finalizar la consulta y es posible que no finalice en absoluto si está atrapada en un bucle de tiempo.
Arquitectura de almacén de columnas de MariaDB
Veamos la arquitectura de MariaDB ColumStore a continuación:
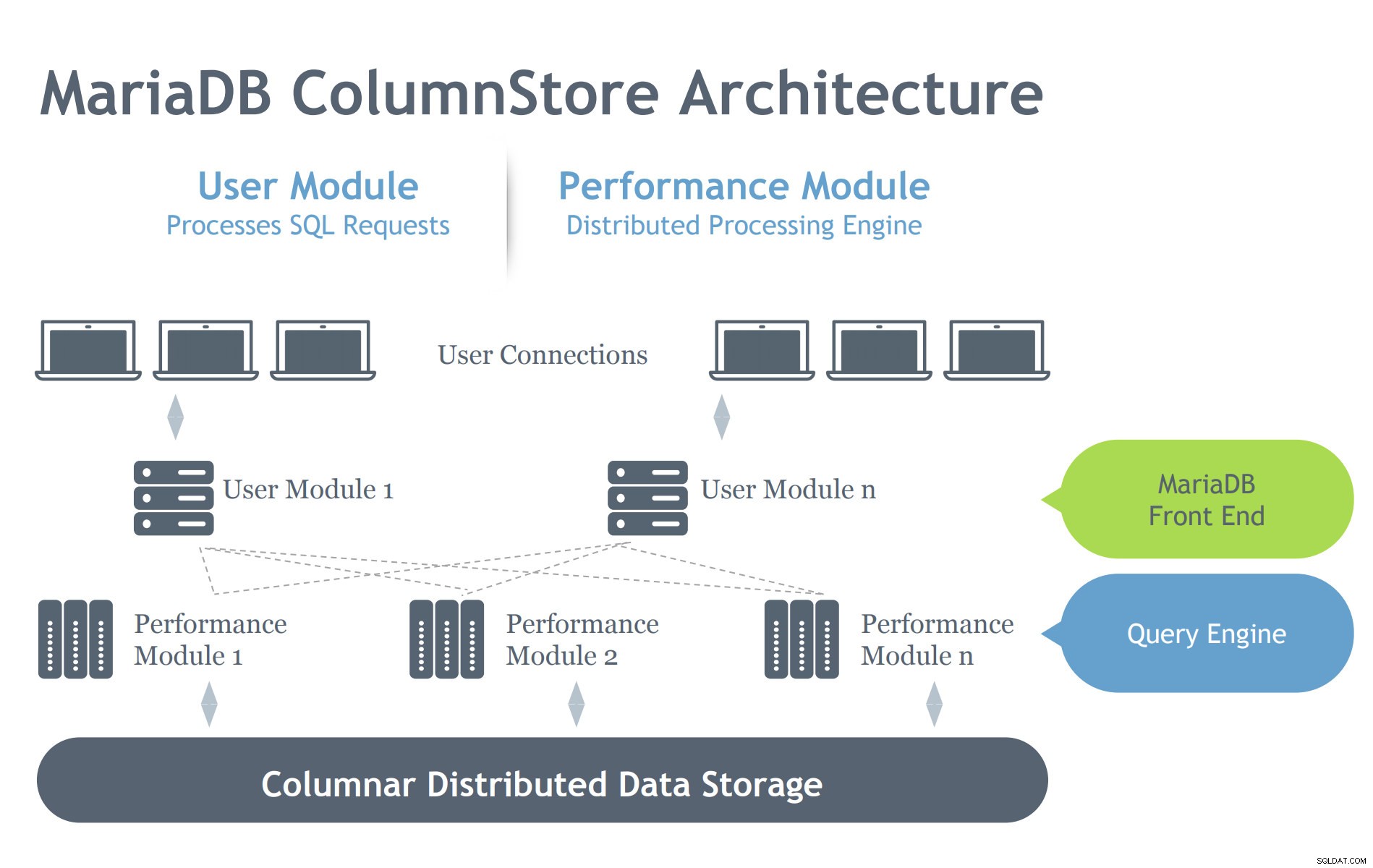 Imagen cortesía de la presentación de MariaDB ColumnStore
Imagen cortesía de la presentación de MariaDB ColumnStore En contraste con la arquitectura InnoDB, ColumnStore contiene dos módulos que denotan que su intención es trabajar de manera eficiente en un entorno arquitectónico distribuido. InnoDB está diseñado para escalar en un servidor, pero se extiende en múltiples nodos interconectados según la configuración del clúster. Por lo tanto, ColumnStore tiene varios niveles de componentes que se encargan de los procesos solicitados al servidor MariaDB. Profundicemos en estos componentes a continuación:
- Módulo de usuario (UM):el UM es responsable de analizar las solicitudes de SQL en un conjunto optimizado de pasos de trabajo primitivos ejecutados por uno o más servidores PM. Por lo tanto, la mensajería unificada es responsable de la optimización de consultas y la organización de la ejecución de consultas por parte de los servidores PM. Si bien se pueden implementar varias instancias de mensajería unificada en una implementación de varios servidores, una sola mensajería unificada es responsable de cada consulta individual. Se puede implementar un equilibrador de carga de base de datos, como MariaDB MaxScale, para equilibrar adecuadamente las solicitudes externas con los servidores de mensajería unificada individuales.
- Módulo de rendimiento (PM):el PM ejecuta pasos de trabajo granulares recibidos de un UM de manera multiproceso. ColumnStore permite la distribución del trabajo entre muchos módulos de rendimiento. La mensajería unificada está compuesta por el proceso mysqld de MariaDB y el proceso ExeMgr.
- Mapas de extensión:ColumnStore mantiene metadatos sobre cada columna en un objeto distribuido compartido conocido como Mapa de extensión. El servidor de mensajería unificada hace referencia al Mapa de extensión para ayudar a generar los pasos de trabajo primitivos correctos. El servidor PM hace referencia al mapa de extensión para identificar los bloques de disco correctos para leer. Cada columna se compone de uno o más archivos y cada archivo puede contener múltiples extensiones. En la medida de lo posible, el sistema intenta asignar almacenamiento físico contiguo para mejorar el rendimiento de lectura.
- Almacenamiento:ColumnStore puede usar almacenamiento local o almacenamiento compartido (por ejemplo, SAN o EBS) para almacenar datos. El uso de almacenamiento compartido permite que el procesamiento de datos se traslade automáticamente a otro nodo en caso de que falle un servidor PM.
A continuación se muestra cómo MariaDB ColumnStore procesa la consulta,
- Los clientes envían una consulta al servidor MariaDB que se ejecuta en el módulo de usuario. El servidor realiza una operación de tabla para todas las tablas necesarias para cumplir con la solicitud y obtiene el plan de ejecución de consulta inicial.
- Usando la interfaz del motor de almacenamiento de MariaDB, ColumnStore convierte el objeto de la tabla del servidor en objetos de ColumnStore. Estos objetos luego se envían a los procesos del módulo de usuario.
- El módulo de usuario convierte el plan de ejecución de MariaDB y optimiza los objetos dados en un plan de ejecución de ColumnStore. Luego determina los pasos necesarios para ejecutar la consulta y el orden en que deben ejecutarse.
- El módulo de usuario luego consulta el mapa de extensión para determinar qué módulos de rendimiento consultar para obtener los datos que necesita, luego realiza la eliminación de extensión, eliminando cualquier módulo de rendimiento de la lista que solo contenga datos fuera del rango de lo que requiere la consulta.
- El módulo de usuario luego envía comandos a uno o más módulos de rendimiento para realizar operaciones de E/S de bloque.
- El módulo o módulos de rendimiento llevan a cabo el filtrado de predicados, el procesamiento de unión, la agregación inicial de datos del almacenamiento local o externo y luego envían los datos de vuelta al módulo de usuario.
- El módulo de usuario realiza la agregación final del conjunto de resultados y compone el conjunto de resultados para la consulta.
- El módulo de usuario/ExeMgr implementa cualquier cálculo de función de ventana, así como cualquier clasificación necesaria en el conjunto de resultados. Luego devuelve el conjunto de resultados al servidor.
- El servidor MariaDB realiza cualquier función de lista de selección, operaciones ORDENAR POR y LÍMITE en el conjunto de resultados.
- El servidor MariaDB devuelve el conjunto de resultados al cliente.
Paradigmas de ejecución de consultas
Analicemos un poco más cómo ColumnStore ejecuta la consulta y cuándo impacta.
ColumnStore se diferencia de los motores de almacenamiento MySQL/MariaDB estándar, como InnoDB, ya que ColumnStore mejora el rendimiento al escanear solo las columnas necesarias, utilizar la partición mantenida por el sistema y utilizar varios subprocesos y servidores para escalar el tiempo de respuesta de las consultas. El rendimiento se ve beneficiado cuando solo incluye columnas que son necesarias para la recuperación de datos. Esto significa que el asterisco codicioso (*) en su consulta de selección tiene un impacto significativo en comparación con SELECT
Al igual que con InnoDB y otros motores de almacenamiento, el tipo de datos también tiene importancia en el rendimiento de lo que utilizó. Si dice que tiene una columna que solo puede tener valores de 0 a 100, declare esto como tinyint, ya que se representará con 1 byte en lugar de 4 bytes para int. Esto reducirá el costo de E/S en 4 veces. Para los tipos de cadena, un umbral importante es char(9) y varchar(8) o superior. Cada archivo de almacenamiento de columna utiliza un número fijo de bytes por valor. Esto permite una búsqueda posicional rápida de otras columnas para formar la fila. Actualmente, el límite superior para el almacenamiento de datos en columnas es de 8 bytes. Entonces, para cadenas más largas que esta, el sistema mantiene una extensión de 'diccionario' adicional donde se almacenan los valores. El archivo de extensión de columnas luego almacena un puntero en el diccionario. Por lo tanto, es más costoso leer y procesar una columna varchar(8) que una columna char(8), por ejemplo. Entonces, donde sea posible, obtendrá un mejor rendimiento si puede utilizar cadenas más cortas, especialmente si evita la búsqueda en el diccionario. Todos los tipos de datos de TEXTO/BLOB de 1.1 en adelante utilizan un diccionario y realizan una búsqueda de bloques múltiples de 8 KB para recuperar esos datos si es necesario, cuanto más largos sean los datos, más bloques se recuperan y mayor es el impacto potencial en el rendimiento.
En un sistema basado en filas, la adición de columnas redundantes aumenta el costo general de la consulta, pero en un sistema en columnas, solo se produce un costo si se hace referencia a la columna. Por lo tanto, se deben crear columnas adicionales para admitir diferentes rutas de acceso. Por ejemplo, almacene una parte inicial de un campo en una columna para permitir búsquedas más rápidas, pero además almacene el valor de forma larga como otra columna. Los escaneos en un código más corto o en una columna de la parte inicial serán más rápidos.
Las uniones de consultas están optimizadas y listas para uniones a gran escala y evitan la necesidad de índices y la sobrecarga del procesamiento de bucles anidados. ColumnStore mantiene estadísticas de tablas para determinar el orden de combinación óptimo. Enfoques similares se comparten con InnoDB, por ejemplo, si la combinación es demasiado grande para la memoria de mensajería unificada, utiliza una combinación basada en disco para completar la consulta.
Para agregaciones, ColumnStore distribuye la evaluación agregada tanto como sea posible. Esto significa que comparte a través de UM y PM para manejar consultas especialmente o una gran cantidad de valores en las columnas agregadas. Select count (*) está optimizado internamente para elegir la menor cantidad de bytes de almacenamiento en una tabla. Esto significa que elegiría la columna CHAR (1) (usa 1 byte) sobre la columna INT que toma 4 bytes. La implementación aún respeta la semántica ANSI en la que el conteo seleccionado (*) incluirá valores nulos en el conteo total en lugar de una selección explícita (COL-N) que excluye los valores nulos en el conteo.
El orden por y el límite se implementan actualmente al final del proceso del servidor mariadb en la tabla de conjunto de resultados temporales. Esto se mencionó en el paso 9 sobre cómo ColumnStore procesa la consulta. Entonces, técnicamente, los resultados se pasan al servidor MariaDB para ordenar los datos.
Para consultas complejas que usan subconsultas, es básicamente el mismo enfoque donde se ejecutan en secuencia y es administrado por UM, al igual que con las funciones de Windows que son manejadas por UM pero usa un proceso de clasificación dedicado más rápido, por lo que es básicamente más rápido.
La partición de sus datos la proporciona ColumnStore, que utiliza mapas de extensión que mantienen los valores mínimos/máximos de los datos de columna y proporcionan un rango lógico para la partición y eliminan la necesidad de indexación. Extent Maps también proporciona partición manual de tablas, vistas materializadas, tablas de resumen y otras estructuras y objetos que las bases de datos basadas en filas deben implementar para el rendimiento de las consultas. Hay ciertos beneficios para los valores en columnas cuando están en orden o semiordenado, ya que esto permite una partición de datos muy efectiva. Con valores mínimos y máximos, se eliminarán los mapas de extensión completos después del filtro y la exclusión. Consulte esta página en su manual sobre Eliminación de extensión. Por lo general, esto funciona particularmente bien para datos de series temporales o valores similares que aumentan con el tiempo.
Instalación de MariaDB ColumnStore
La instalación de MariaDB ColumnStore puede ser simple y directa. MariaDB tiene una serie de notas aquí a las que puede consultar. Para este blog, nuestro entorno de destino de instalación es CentOS 7. Puede ir a este enlace https://downloads.mariadb.com/ColumnStore/1.2.4/ y consultar los paquetes según el entorno de su sistema operativo. Consulte los pasos detallados a continuación para ayudarlo a acelerar:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
Una vez hecho esto, debe ejecutar postConfigure comando para finalmente instalar y configurar su MariaDB ColumnStore. En esta instalación de muestra, hay dos nodos que configuré ejecutándose en la máquina vagabunda:
csnode1:192.168.2.10
csnode2:192.168.2.20
Ambos nodos están definidos en sus respectivos /etc/hosts y ambos nodos están destinados a tener sus módulos de usuario y rendimiento combinados en ambos hosts. La instalación es un poco trivial al principio. De ahí que te compartimos cómo puedes configurarlo para que puedas tener una base. Consulte los detalles a continuación para ver el proceso de instalación de muestra:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#Una vez finalizada la instalación y la configuración, MariaDB creará una configuración maestro/esclavo para esto, de modo que lo que hayamos cargado desde csnode1, se replicará en csnode2.
Volcando su Big Data
Después de su instalación, es posible que no tenga datos de muestra para probar. IMDB ha compartido datos de muestra que puede descargar en su sitio https://www.imdb.com/interfaces/. Para este blog, creé un script que hace todo por ti. Compruébalo aquí https://github.com/paulnamuag/columnstore-imdb-data-load. Simplemente hágalo ejecutable, luego ejecute el script. Hará todo por usted al descargar los archivos, crear el esquema y luego cargar los datos en la base de datos. Así de simple.
Ejecutar sus consultas de muestra
Ahora, intentemos ejecutar algunas consultas de muestra.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)Básicamente, es más rápido y rápido. Hay consultas que no puede procesar de la misma manera que ejecuta con otros motores de almacenamiento, como InnoDB. Por ejemplo, traté de jugar y hacer algunas consultas tontas y ver cómo reacciona y da como resultado:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Por lo tanto, encontré MCOL-1620 y MCOL-131 y apunta a configurar la variable infinidb_vtable_mode. Ver a continuación:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Pero establecer infinidb_vtable_mode=0 , lo que significa que trata la consulta como un modo de procesamiento fila por fila genérico y altamente compatible. Algunos componentes de la cláusula WHERE pueden ser procesados por ColumnStore, pero las uniones son procesadas completamente por mysqld utilizando un mecanismo de unión de bucle anidado. Ver a continuación:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Sin embargo, tomó algún tiempo, ya que explica que mysqld lo procesó completamente. Aún así, optimizar y escribir buenas consultas sigue siendo el mejor enfoque y no delegar todo a ColumnStore.
Además, tiene ayuda para analizar sus consultas ejecutando comandos como SELECT calSetTrace(1); o SELECCIONE calGetStats(); . Puede usar este conjunto de comandos, por ejemplo, optimizar las consultas bajas y malas o ver su plan de consulta. Compruébelo aquí para obtener más detalles sobre el análisis de las consultas.
Administración de ColumnStore
Una vez que haya configurado completamente MariaDB ColumnStore, se envía con su herramienta llamada mcsadmin que puede usar para realizar algunas tareas administrativas. También puede usar esta herramienta para agregar otro módulo, asignar o pasar a DBroots de PM a PM, etc. Consulte su manual sobre esta herramienta.
Básicamente, puede hacer lo siguiente, por ejemplo, verificar la información del sistema:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Conclusión
MariaDB ColumnStore es un motor de almacenamiento muy poderoso para su OLAP y procesamiento de big data. Esto es completamente de código abierto, lo cual es muy ventajoso de usar que usar bases de datos OLAP propietarias y costosas disponibles en el mercado. Sin embargo, existen otras alternativas para probar, como ClickHouse, Apache HBase o cstore_fdw de Citus Data. Sin embargo, ninguno de estos usa MySQL/MariaDB, por lo que podría no ser su opción viable si elige quedarse con las variantes de MySQL/MariaDB.