En la publicación de blog anterior, hemos cubierto los conceptos básicos del escalado:qué es, cuáles son los tipos, qué es imprescindible si queremos escalar. Esta publicación de blog se centrará en los desafíos y las formas en que podemos escalar.
Desafío del escalamiento horizontal
Escalar bases de datos no es la tarea más fácil por varias razones. Centrémonos un poco en los desafíos relacionados con la ampliación de la infraestructura de su base de datos.
Servicio con estado
Podemos distinguir dos tipos diferentes de servicios:sin estado y con estado. Los servicios sin estado son los que no se basan en ningún tipo de datos existentes. Puede continuar, iniciar dicho servicio y felizmente funcionará. No tienes que preocuparte por el estado de los datos ni del servicio. Si está activo, funcionará correctamente y podrá distribuir fácilmente el tráfico entre múltiples instancias de servicio simplemente agregando más clones o copias de máquinas virtuales existentes, contenedores o similares. Un ejemplo de dicho servicio puede ser una aplicación web:implementada desde el repositorio, con un servidor web configurado correctamente, dicho servicio simplemente se iniciará y funcionará correctamente.
El problema con las bases de datos es que la base de datos es todo menos apátrida. Los datos deben insertarse en la base de datos, deben procesarse y conservarse. La imagen de la base de datos no es más que un par de paquetes instalados sobre la imagen del sistema operativo y, sin datos y sin la configuración adecuada, es bastante inútil. Esto se suma a la complejidad del escalado de la base de datos. Para los servicios sin estado, es solo implementarlos y configurar algunos balanceadores de carga para incluir nuevas instancias en la carga de trabajo. Para las bases de datos que implementan la base de datos, la instancia es solo el punto de partida. Más adelante en el camino está la gestión de datos:debe transferir los datos de su instancia de base de datos existente a la nueva. Esto puede ser una parte importante del problema y del tiempo necesario para que las nuevas instancias comiencen a manejar el tráfico. Solo después de que se hayan transferido los datos, podemos configurar los nuevos nodos para que se conviertan en parte de la topología de replicación existente:los datos deben actualizarse en tiempo real, en función del tráfico que llega a otros nodos.
Tiempo necesario para escalar hacia arriba
El hecho de que las bases de datos sean servicios con estado es una razón directa del segundo desafío al que nos enfrentamos cuando queremos ampliar la infraestructura de la base de datos. Servicios sin estado:simplemente los inicia y eso es todo. Es un proceso bastante rápido. Para las bases de datos, debe transferir los datos. Cuánto tiempo tomará, depende de múltiples factores. ¿Qué tan grande es el conjunto de datos? ¿Qué tan rápido es el almacenamiento? ¿Qué tan rápida es la red? ¿Cuáles son los otros pasos necesarios para aprovisionar el nuevo nodo con los datos nuevos? ¿Se comprimen/descomprimen o se cifran/descifran los datos en el proceso? En el mundo real, puede llevar de minutos a varias horas aprovisionar los datos en un nuevo nodo. Esto limita seriamente los casos en los que puede ampliar su entorno de base de datos. ¿Puntos repentinos y temporales de carga? En realidad no, es posible que hayan pasado mucho tiempo antes de que pueda iniciar nodos de base de datos adicionales. ¿Aumento de carga repentino y constante? Sí, será posible solucionarlo agregando más nodos, pero puede llevar incluso horas abrirlos y dejar que asuman el tráfico de los nodos de base de datos existentes.
Carga adicional causada por el proceso de ampliación
Es muy importante tener en cuenta que el tiempo necesario para escalar es solo una parte del problema. El otro lado es la carga causada por el proceso de escalado. Como mencionamos anteriormente, debe transferir todo el conjunto de datos a los nodos recién agregados. Esto no es algo que pueda ignorar, después de todo, puede ser un proceso de horas para leer los datos del disco, enviarlos a través de la red y almacenarlos en una nueva ubicación. Si el donante, el nodo del que lee los datos, está sobrecargado, debe considerar cómo se comportará si se ve obligado a realizar una actividad de E/S adicional. ¿Podrá su clúster asumir una carga de trabajo adicional si ya está bajo una gran presión y está muy disperso? La respuesta puede no ser fácil de obtener ya que la carga en los nodos puede presentarse de diferentes formas. La carga vinculada a la CPU será el mejor de los casos, ya que la actividad de E/S debe ser baja y las operaciones de disco adicionales serán manejables. La carga vinculada a E/S, por otro lado, puede ralentizar significativamente la transferencia de datos, lo que afecta gravemente la capacidad de escalar del clúster.
Escritura de escala
El proceso de escalamiento horizontal que mencionamos anteriormente se limita bastante a escalar lecturas. Es fundamental entender que escalar escrituras es una historia completamente diferente. Puede escalar las lecturas simplemente agregando más nodos y distribuyendo las lecturas entre más nodos de back-end. Las escrituras no son tan fáciles de escalar. Para empezar, no puede escalar las escrituras así como así. Cada nodo que contiene el conjunto de datos completo es, obviamente, necesario para manejar todas las escrituras realizadas en algún lugar del clúster porque solo aplicando todas las modificaciones al conjunto de datos puede mantener la coherencia. Entonces, cuando lo piensa, no importa cómo diseñe su clúster y qué tecnología use, cada miembro del clúster tiene que ejecutar cada escritura. Ya sea una réplica, replicando todas las escrituras desde su maestro o nodo en un clúster multimaestro como Galera o InnoDB Cluster ejecutando todos los cambios en el conjunto de datos realizados en todos los demás nodos del clúster, el resultado es el mismo. Las escrituras no escalan horizontalmente simplemente agregando más nodos al clúster.
¿Cómo podemos escalar horizontalmente la base de datos?
Entonces, sabemos a qué tipo de desafíos nos enfrentamos. ¿Cuáles son las opciones que tenemos? ¿Cómo podemos escalar la base de datos?
Añadiendo réplicas
En primer lugar, escalaremos horizontalmente simplemente agregando más nodos. Claro, tomará tiempo y seguro, no es un proceso que pueda esperar que suceda de inmediato. Claro, no podrá escalar escrituras como esa. Por otro lado, el problema más típico al que se enfrentará es la carga de la CPU provocada por las consultas SELECT y, como comentamos, las lecturas se pueden escalar simplemente agregando más nodos al clúster. Más nodos para leer significa que la carga en cada uno de ellos se reducirá. Cuando esté al comienzo de su viaje hacia el ciclo de vida de su aplicación, suponga que esto es con lo que se enfrentará. Carga de CPU, consultas no eficientes. Es muy poco probable que necesite escalar las escrituras hasta mucho más adelante en el ciclo de vida, cuando su aplicación ya haya madurado y tenga que lidiar con la cantidad de clientes.
Por fragmentación
Agregar nodos no resolverá el problema de escritura, eso es lo que establecimos. En su lugar, lo que debe hacer es fragmentar:dividir el conjunto de datos en todo el clúster. En este caso, cada nodo contiene solo una parte de los datos, no todo. Esto nos permite finalmente comenzar a escalar las escrituras. Digamos que tenemos cuatro nodos, cada uno de los cuales contiene la mitad del conjunto de datos.
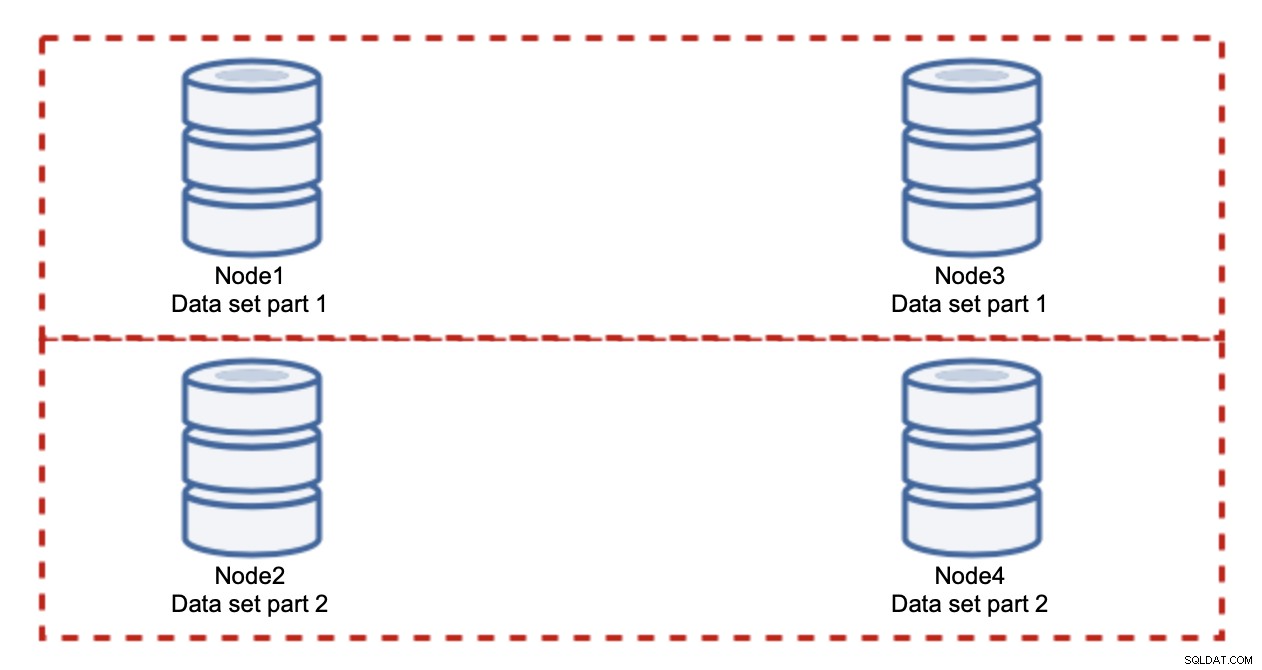
Como puede ver, la idea es simple. Si la escritura está relacionada con la parte 1 del conjunto de datos, se ejecutará en el nodo1 y el nodo3. Si está relacionado con la parte 2 del conjunto de datos, se ejecutará en el nodo2 y el nodo4. Puede pensar en los nodos de la base de datos como discos en un RAID. Aquí tenemos un ejemplo de RAID10, dos pares de espejos, para redundancia. En la implementación real, puede ser más complejo, puede tener más de una réplica de los datos para mejorar la alta disponibilidad. La esencia es que, asumiendo una división perfectamente justa de los datos, la mitad de las escrituras llegarán al nodo 1 y al nodo 3 y la otra mitad a los nodos 2 y 4. Si desea dividir la carga aún más, puede introducir el tercer par de nodos:
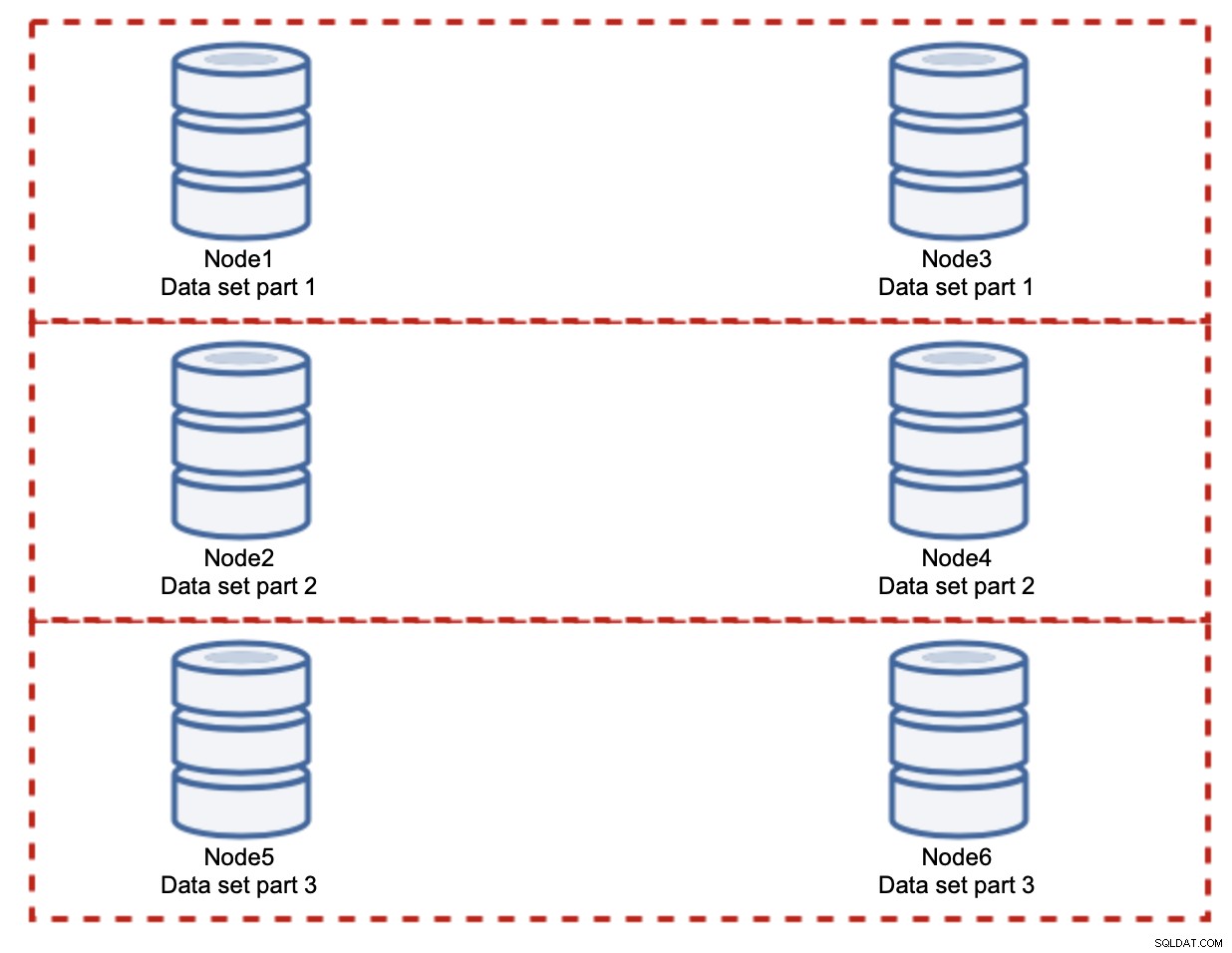
En este caso, nuevamente, suponiendo una división perfectamente justa, cada par ser responsable del 33 % de todas las escrituras en el clúster.
Esto resume bastante bien la idea de la fragmentación. En nuestro ejemplo, al agregar más fragmentos, podemos reducir la actividad de escritura en los nodos de la base de datos al 33 % de la carga de E/S original. Como puedes imaginar, esto no viene sin inconvenientes.
¿Cómo encontraré en qué fragmento se encuentran mis datos? Los detalles están fuera del alcance de esta llamada pero, en resumen, puede implementar algún tipo de función en una columna determinada (módulo o hash en la columna 'id') o puede crear una metadatabase separada donde almacenará los detalles de cómo se distribuyen los datos.
Esperamos que esta breve serie de blogs le haya resultado informativa y que comprenda mejor los diferentes desafíos a los que nos enfrentamos cuando queremos ampliar el entorno de la base de datos. Si tiene algún comentario o sugerencia sobre este tema, no dude en comentar debajo de esta publicación y compartir su experiencia