Al ejecutar una consulta, el optimizador de SQL Server intenta encontrar el mejor plan de consulta en función de los índices existentes y las últimas estadísticas disponibles durante un tiempo razonable, por supuesto, si este plan aún no está almacenado en la memoria caché del servidor. Si no, la consulta se ejecuta de acuerdo con este plan y el plan se almacena en la memoria caché del servidor. Si el plan ya se ha creado para esta consulta, la consulta se ejecuta de acuerdo con el plan existente.
Estamos interesados en el siguiente problema:
Durante la compilación de un plan de consulta, al clasificar los posibles índices, si el servidor no encuentra el mejor índice, el índice faltante se marca en el plan de consulta y el servidor mantiene estadísticas sobre dichos índices:cuántas veces el servidor usaría este índice y cuánto costaría esta consulta.
En este artículo, vamos a analizar estos índices faltantes:cómo lidiar con ellos.
Consideremos esto en un ejemplo particular. Cree un par de tablas en nuestra base de datos en un servidor local y de prueba:
[expandir título =”Código”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expandir]
La estructura es sencilla y consta de dos mesas. La primera tabla se llama pedidos con campos como identificador, fecha de venta y vendedor. El segundo son los detalles del pedido, donde se especifican algunos productos con precio y cantidad.
Mire una consulta simple y su plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
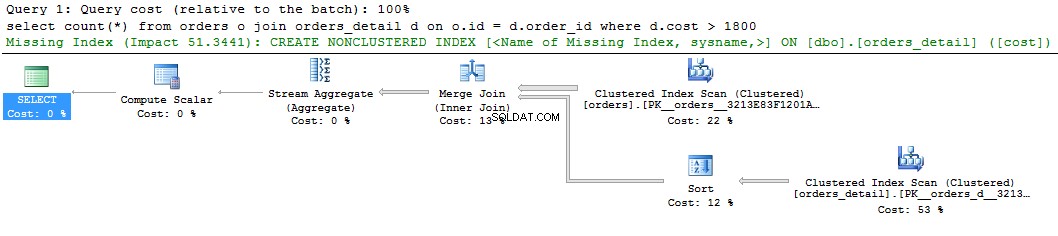
Podemos ver una pista verde sobre el índice faltante en la pantalla gráfica del plan de consulta. Si hace clic con el botón derecho y selecciona "Faltan detalles del índice...", aparecerá el texto del índice sugerido. Lo único que hay que hacer es eliminar los comentarios del texto y dar un nombre al índice. El script está listo para ser ejecutado.
No crearemos el índice que recibimos de la sugerencia proporcionada por SSMS. En su lugar, veremos si este índice será recomendado por vistas dinámicas vinculadas a índices faltantes. Las vistas son las siguientes:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
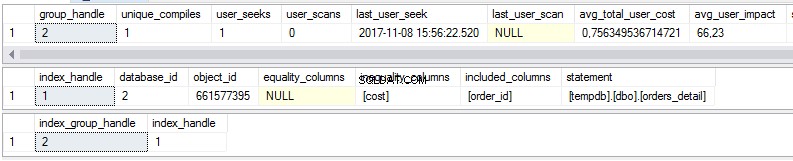
Como podemos ver, hay algunas estadísticas sobre índices que faltan en la primera vista:
- ¿Cuántas veces se realizaría una búsqueda si existiera el índice sugerido?
- ¿Cuántas veces se realizaría un escaneo si existiera el índice sugerido?
- Última fecha y hora en que usamos el índice
- El costo real actual del plan de consulta sin el índice sugerido.
La segunda vista es el cuerpo del índice:
- Base de datos
- Objeto/mesa
- Columnas ordenadas
- Columnas añadidas para aumentar la cobertura del índice
La tercera vista es la combinación de la primera y la segunda vista.
En consecuencia, no es difícil obtener una secuencia de comandos que genere una secuencia de comandos para crear índices faltantes a partir de estas vistas dinámicas. El guión es el siguiente:
[expandir título=”Código”]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expandir]
Para la eficiencia del índice, se generan los índices que faltan. La solución perfecta es cuando este conjunto de resultados no devuelve nada. En nuestro ejemplo, el conjunto de resultados devolverá al menos un índice:

Cuando no hay tiempo y no tiene ganas de lidiar con los errores del cliente, ejecuté la consulta, copié la primera columna y la ejecuté en el servidor. Después de esto, todo funcionó bien.
Recomiendo tratar la información de estos índices de forma consciente. Por ejemplo, si el sistema recomienda los siguientes índices:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
Y estos índices se utilizan para la búsqueda, es bastante obvio que es más lógico reemplazar estos índices con uno que cubra los tres sugeridos:
create index ix_1 on tbl1 (a,b) include (c,d)
Por lo tanto, hacemos una revisión de los índices que faltan antes de implementarlos en el servidor de producción. Aunque…. Nuevamente, por ejemplo, implementé los índices perdidos en el servidor TFS, aumentando así el rendimiento general. Llevó un tiempo mínimo realizar esta optimización. Sin embargo, al cambiar de TFS 2015 a TFS 2017, me encontré con el problema de que no había ninguna actualización debido a estos nuevos índices. Sin embargo, pueden ser fácilmente encontrados por la máscara
select * from sys.indexes where name like 'ix[_]2017%'
Herramienta útil:
dbForge Index Manager:útil complemento de SSMS para analizar el estado de los índices SQL y solucionar problemas con la fragmentación de índices.