FILESTREAM fue presentado por Microsoft en 2008. El propósito era almacenar y administrar archivos no estructurados de manera más efectiva. Antes de que se introdujera FILESTREAM, se usaban los siguientes enfoques para almacenar los datos en el servidor SQL:
- Los archivos no estructurados se pueden almacenar en la columna VARBINARY o IMAGE de una tabla de SQL Server. Este enfoque es eficaz para mantener la coherencia transaccional y reduce la complejidad de la gestión de archivos, pero cuando la aplicación cliente lee datos de la tabla SQL, utiliza la memoria SQL, lo que genera un rendimiento deficiente.
- En lugar de almacenar todo el archivo en la tabla SQL, almacene la ubicación física del archivo no estructurado en la tabla SQL. Este enfoque brinda una gran mejora en el rendimiento, pero no garantiza la consistencia transaccional; además, la administración de archivos también fue difícil.
La función FILESTREAM es muy efectiva porque permite almacenar archivos BLOB en el sistema de archivos NT y mantiene la consistencia transaccional. Cuando una aplicación cliente lee datos del contenedor FILESTREAM, en lugar de usar la memoria del búfer de SQL Server, usa la memoria caché del sistema T, lo que mejora el rendimiento.
FILESTREAM no es un tipo de datos. Es un atributo que se puede asignar a la columna VARBINARY(MAX). Cuando la columna VARBINARY(MAX) se asigna al atributo FILESTREAM, se denomina columna FILESTREAM. Los datos almacenados en la columna FILESTREAM se almacenarán en el sistema NT como un archivo de disco y el puntero del archivo se almacenará en la tabla. La columna VARBINARY(max) con el atributo FILESTREAM asignado no tiene límite de almacenamiento de 2 GB en la tabla. Por lo tanto, también podemos almacenar archivos de gran tamaño.
En este artículo, voy a demostrar lo siguiente:
- Cómo habilitar la función FILESTREAM.
- Cómo crear y configurar grupos de archivos FILESTREAM y contenedores de datos FILESTREAM.
- Cómo almacenar y acceder a los datos de las tablas habilitadas para FILESTREAM.
Demostración:
En esta demostración, voy a usar:
- Servidor de base de datos :Servidor SQL 2017
- Software :SQL Server Management Studio
- Base de datos :FileStream_Demo
Configurar el acceso a FILESTREAM en la base de datos de SQL Server
Para configurar FileStream en SQL Server, realice los siguientes cambios en SQL Server.
- Habilite la función FILESTREAM desde el Administrador de configuración de SQL Server.
- Habilite el nivel de acceso de FILESTREAM en la instancia de SQL Server.
- Cree un grupo de archivos FILESTREAM y un contenedor FileStream para almacenar datos BLOB.
Habilitar la función FILESTREAM
Para habilitar FileStream en cualquier base de datos, primero habilite la función FileStream en la instancia de SQL Server. Para ello, abra el administrador de configuración de SQL Server, haga clic con el botón derecho en Instancia de SQL y seleccione Propiedades. , como se muestra en la siguiente imagen:
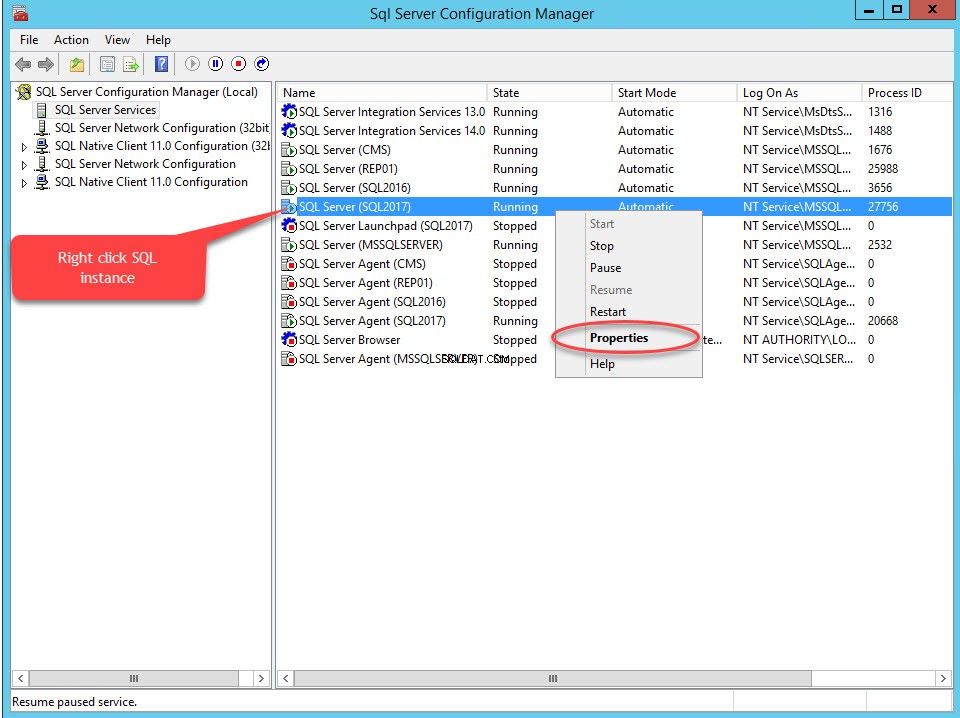
Se abre un cuadro de diálogo para configurar las propiedades del servidor. Cambiar a FILESTREAM pestaña. Seleccione Habilitar FILESTREAM para acceso T-SQL . Seleccione Habilitar FILESTREAM para acceso de E/S y luego seleccione Permitir acceso de cliente remoto a los datos de FILESTREAM . En el nombre del recurso compartido de Windows cuadro de texto, proporcione un nombre del directorio para almacenar los archivos. Ver la siguiente imagen:
Haga clic en Aceptar y reinicie el servicio SQL.
Habilitar el nivel de acceso de FILESTREAM en la instancia de SQL Server
Una vez que la función FILESTREAM esté habilitada, cambie el nivel de acceso de FILESTREAM. Para cambiar el nivel de acceso de FileStream, ejecute la siguiente consulta:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
En la consulta anterior, los siguientes parámetros son valores válidos:
0 significa el soporte de FILESTREAM para la instancia de SQL está deshabilitado.
1 significa el soporte de FILESTREAM para T-SQL está habilitado.
2 medios la compatibilidad con FILESTREAM para T-SQL y el acceso de transmisión Win32 está habilitada.
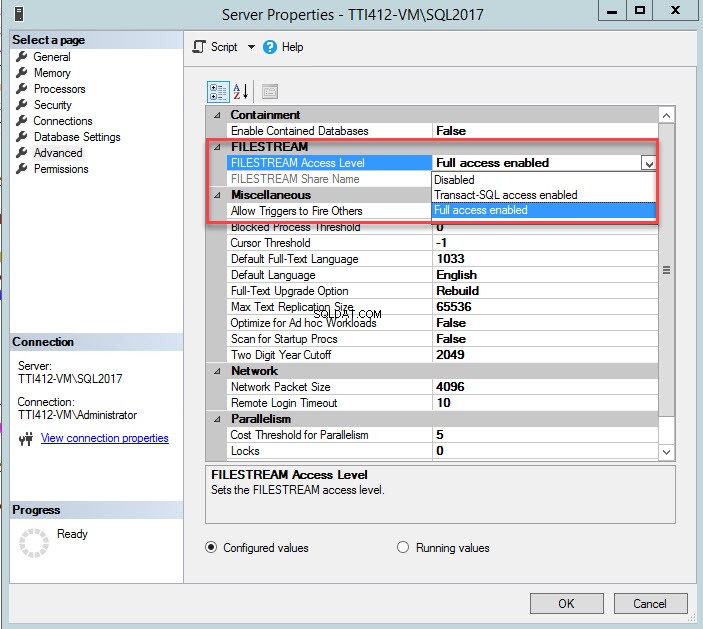
Puede cambiar el nivel de acceso de FILESTREAM mediante SQL Server Management Studio. Para ello, haga clic con el botón derecho en una conexión de SQL Server>> seleccione Propiedades>> En el cuadro de diálogo de propiedades del servidor, seleccione Nivel de acceso de FileStream en el cuadro desplegable y seleccione Acceso completo habilitado , como se muestra en la siguiente imagen:
Una vez que se cambia el parámetro, reinicie los servicios de SQL Server.
Agregar grupo de archivos FILESTREAM y archivos de datos
Una vez que FILESTREAM esté habilitado, agregue el grupo de archivos FILESTREAM y el contenedor FILESTREAM.
Para ello, haga clic con el botón derecho en FileStream-Demo base de datos>> seleccione Propiedades>> En un panel izquierdo de las Propiedades de la base de datos cuadro de diálogo, seleccione Grupos de archivos>> En la cuadrícula de FILESTREAM, haga clic en Agregar grupo de archivos botón>> Nombre el grupo de archivos como Dummy Document . Ver la siguiente imagen:
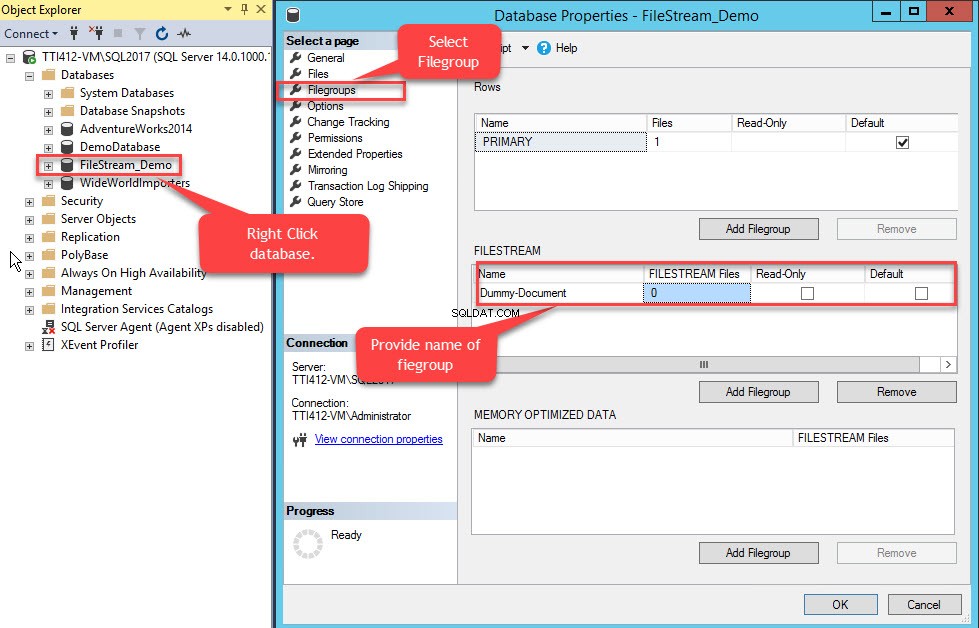
Una vez que se crea el grupo de archivos, en el cuadro de diálogo Propiedades de la base de datos, seleccione archivos y haga clic en el botón Agregar. La cuadrícula de archivos de la base de datos se habilita. En la columna Nombre lógico, proporcione el nombre:Dummy-Document . Seleccione Datos de FILESTREAM en Tipo de archivo caja desplegable. Seleccione Documento ficticio en el grupo de archivos columna. En el Camino columna, proporcione la ubicación del directorio donde se almacenarán los archivos (E:\Dummy-Documents). Ver la siguiente imagen:
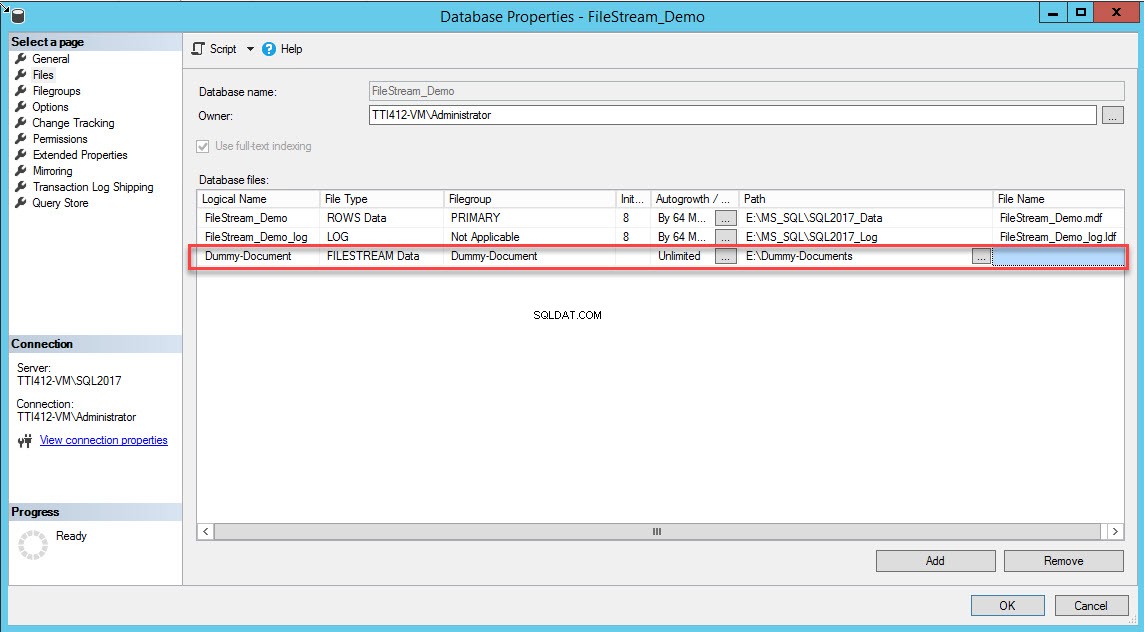
Como alternativa, puede agregar el grupo de archivos y los contenedores FILESTREAM ejecutando la siguiente consulta T-SQL:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Para verificar que se haya creado el contenedor FileStream, abra el Explorador de Windows y navegue hasta el directorio "E:\Dummy-Document".
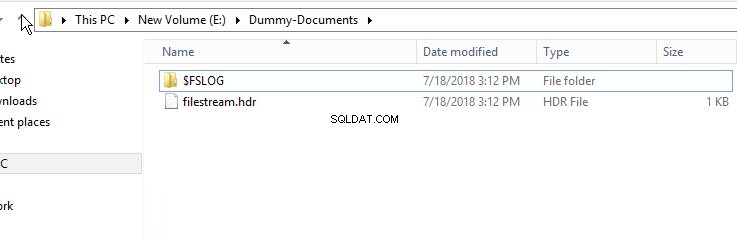
Como se muestra en la imagen de arriba, el directorio $FSLOG y el filestream.hdr se ha creado el archivo. $FSLOG es como el servidor SQL T-Log y filestream.hdr contiene metadatos de FILESTREAM. Asegúrese de no cambiar ni editar esos archivos.
Almacenar archivos en tabla SQL
En esta demostración, crearemos una tabla para almacenar varios archivos de la computadora. La tabla tiene las siguientes columnas:
- El “Directorio Raíz ” columna para almacenar la ubicación del archivo.
- El “Nombre de archivo ” columna para almacenar el nombre del archivo.
- El “FileAttribute ” columna para almacenar el atributo de archivo (Raw/Directory.
- La "Fecha de creación del archivo ” columna para almacenar el tiempo de creación del archivo.
- El "Tamaño de archivo ” columna para almacenar el Tamaño del archivo.
- El “FileStreamCol ” para almacenar el contenido del archivo en formato binario.
Cree una tabla SQL con una columna FILESTREAM
Una vez que se configure FILESTREAM, cree una tabla SQL con las columnas de FILESTREAM para almacenar varios archivos en la tabla del servidor SQL. Como mencioné anteriormente, FILESTREAM no es un tipo de datos. Es un atributo que agregamos a la columna varbinary(max) en la tabla habilitada para FILESTREAM. Cuando cree una tabla habilitada para FILESTREAM, asegúrese de agregar un IDENTIFICADOR ÚNICO columna que tiene el ROWGUIDCOL y ÚNICO atributos.
Ejecute el siguiente script para crear una tabla habilitada para FILESTREAM:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Insertar datos en la tabla
Tengo el WorldWide_Importors.xls documento almacenado en la computadora en la ubicación "E:\Documentos". Usar OPENROWSET(Bulk) para cargar su contenido desde el disco al VARBINARY(max) variable. Luego almacene la variable en FileStreamCol (VARBINARY(max)) columna del DummyDocumen mesa Para ello, ejecute el siguiente script:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Acceder a los datos de FILESTREAM
Se puede acceder a los datos de FILESTREAM mediante T-SQL y API administrada. Cuando se accede a la columna FILESTREAM mediante la consulta T-SQL, utiliza la memoria SQL para leer el contenido del archivo de datos y enviar los datos a la aplicación cliente. Cuando se accede a la columna FILESTREAM mediante la API administrada de Win32, no utiliza la memoria de SQL Server. Utiliza la capacidad de transmisión del sistema de archivos NT que brinda beneficios de rendimiento.
Acceda a datos de FILESTREAM mediante T-SQL
Como mencioné al principio del artículo, FILESTREAM es un atributo asignado a una columna de la tabla que tiene tipo de datos varbinary(max), por lo tanto, se puede acceder a él como a cualquier otra columna de la tabla. Para recuperar datos de FILESTREAM junto con toda la información de la tabla, ejecute la siguiente consulta
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
A continuación se muestra el resultado de la consulta:

Como se muestra en la imagen de arriba, el documento "WorldWide_Importors.xls" se ha convertido en un BLOB que se almacena en la columna "FileStreamCol".
Acceda a los datos de FILESTREAM mediante la API administrada
Aunque el acceso a FILESTREAM mediante la API de Win32 brinda rendimiento y otros beneficios, tiene sintaxis diferentes y difíciles que las sintaxis de T-SQL, lo que dificulta el acceso a los datos. En primer lugar, para ubicar el archivo en el almacén de datos de FILESTREAM, debemos identificar la ruta lógica para identificar el archivo en el almacén de datos de FILESTREAM de manera única. Podemos hacerlo usando Pathname() método de la columna FILESTREAM. Se distingue entre mayúsculas y minúsculas.
Después de recuperar la ruta del Archivo, para acceder, debemos obtener el contexto de la transacción usando Comenzar transacción método. Una vez que se ha obtenido el contexto de la transacción, podemos acceder a él usando el SQLFileStream clase.
El siguiente código obtiene la ruta local a WorldWide_Importors.xls documento en el almacén de datos de FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Resultado de la consulta:

Eliminar archivos del contenedor FILESTREAM
Eliminar archivos es sencillo. Debe ejecutar la consulta de eliminación para eliminar el archivo de la tabla SQL habilitada para FILESTREAM. Aunque el registro se haya eliminado de las tablas, el archivo estará disponible físicamente en el almacén de datos de FILSTREAM. Será eliminado por Garbage Collector. El proceso del recolector de elementos no utilizados se ejecuta cuando se produce el evento de punto de control. Al proporcionar un punto de control explícito, puede eliminarlo inmediatamente después de eliminarlo de la tabla.
Consulta para eliminar archivos de la tabla SQL:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Resumen
En este artículo, he cubierto:
- Introducción de FILESTREAM y cuáles son los beneficios.
- Cómo habilitar la función FILESTREAM en la instancia del servidor SQL.
- Cree y configure el almacén de datos de FILESTREAM y los grupos de archivos.
- Realice la inserción y eliminación de archivos del almacén de datos de FILESTREAM.
En futuros artículos, voy a explicar:
- Cómo hacer una copia de seguridad y restaurar una base de datos habilitada para FILESTREAM.
- Configuración de la replicación y división de tablas en tablas de FILESTREAM.
¡Estén atentos!