Introducción
El envío de registros de transacciones es una tecnología muy conocida que se utiliza en SQL Server para mantener una copia de la base de datos activa en el sitio de recuperación ante desastres. La tecnología depende de tres trabajos clave:el trabajo de copia de seguridad, el trabajo de copia y el trabajo de restauración. Mientras que el trabajo de copia de seguridad se ejecuta en el servidor principal, los trabajos de copia y restauración se ejecutan en el servidor secundario. Esencialmente, el proceso implica copias de seguridad periódicas del registro de transacciones en un recurso compartido desde el cual el trabajo de copia se traslada al servidor secundario; posteriormente, el trabajo de restauración aplica las copias de seguridad de registros al servidor secundario. Antes de que todo esto comience, la base de datos secundaria debe inicializarse con una copia de seguridad completa del servidor principal restaurado con la opción NORECOVERY.
Microsoft proporciona un conjunto de procedimientos almacenados que se pueden usar para configurar el envío de registros de un extremo a otro, así como equivalentes de GUI a partir del elemento de propiedades de cada base de datos para la que desee configurar el envío de registros. Cabe señalar que la Base de Datos Secundaria se puede configurar en modo NO RECUPERACIÓN o en modo ESPERA. En el modo NORECOVERY, la base de datos nunca está disponible para consultas, pero en el modo STANDBY, la base de datos secundaria se puede consultar cuando no hay una operación de restauración del registro de transacciones en curso.
Configuración del entorno
Para comenzar, creamos dos instancias de SQL Server en AWS con una imagen idéntica de Amazon EC2. Esta instancia de Amazon EC2 ejecuta SQL Server 2017 RTM-CU5 en Windows Server 2016. Luego, restauramos una copia de la base de datos de WideWorldImporters mediante un conjunto de respaldo adquirido de GitHub en la primera instancia, nuestra instancia principal. Usamos el mismo conjunto de respaldo para crear dos bases de datos idénticas llamadas BranchDB y CorporateDB.
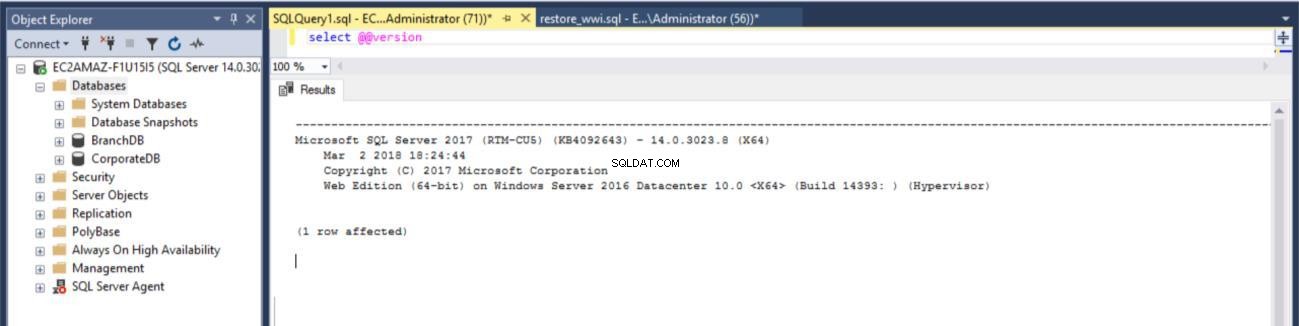
Fig. 1 versión del servidor SQL
Fig. 2 BranchDB y CorporateDB en instancia principal (instancia secundaria en blanco)
Listado 1:Restauración de la base de datos de muestra de WideWorldImporters
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
Ahora tenemos dos instancias, la instancia principal que aloja las dos bases de datos principales (BranchDB y CorporateDB) y la instancia secundaria sin bases de datos de usuarios. primera base de datos. Recuerde que las bases de datos son en realidad idénticas en términos de los datos que contienen. Los siguientes gráficos muestran las opciones clave seleccionadas en la configuración de envío de registros.
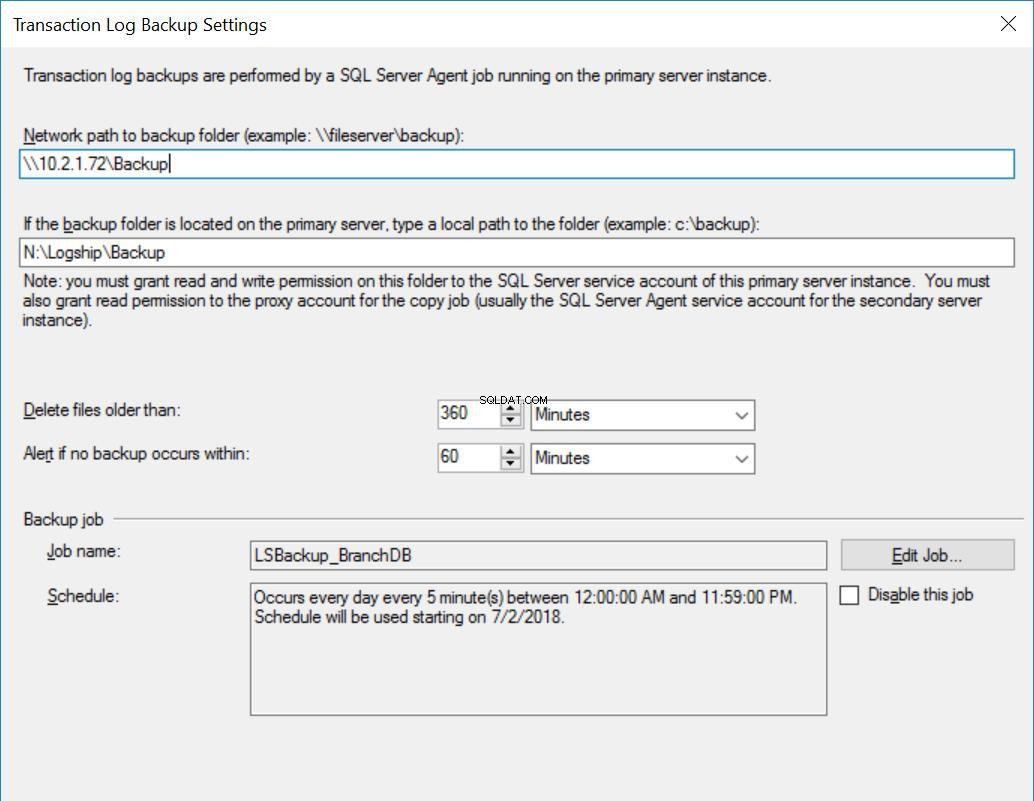
Fig. 3 Configuración de copia de seguridad para BranchDB
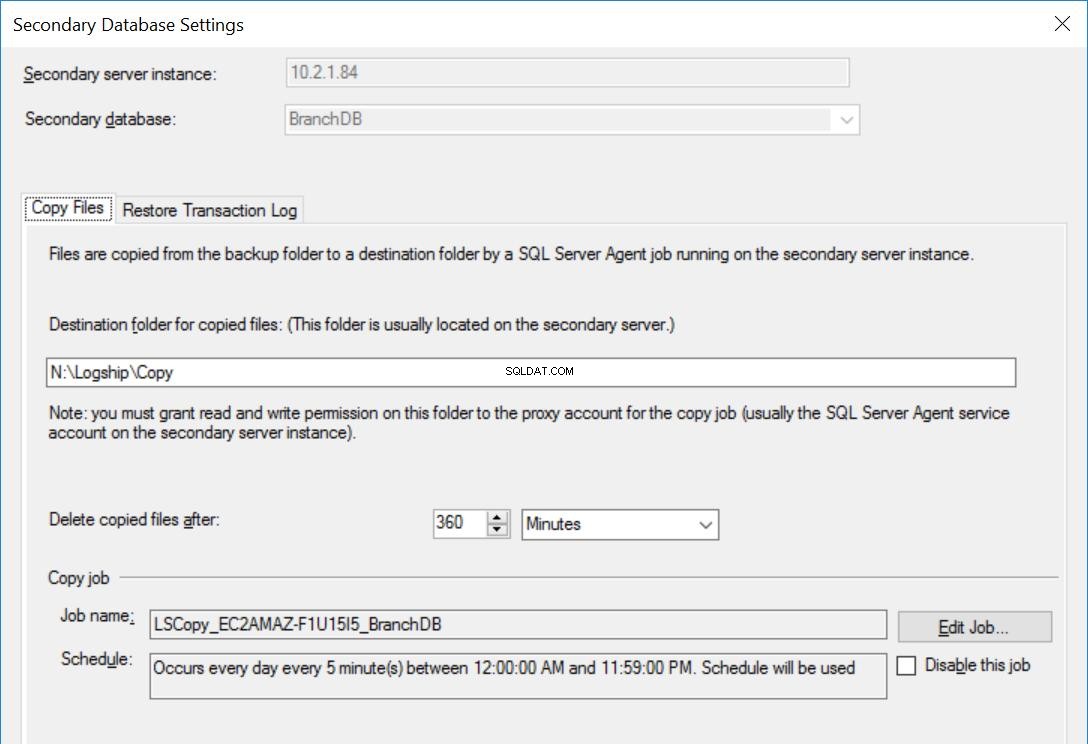
Fig. 4 Configuración de copia para BranchDB
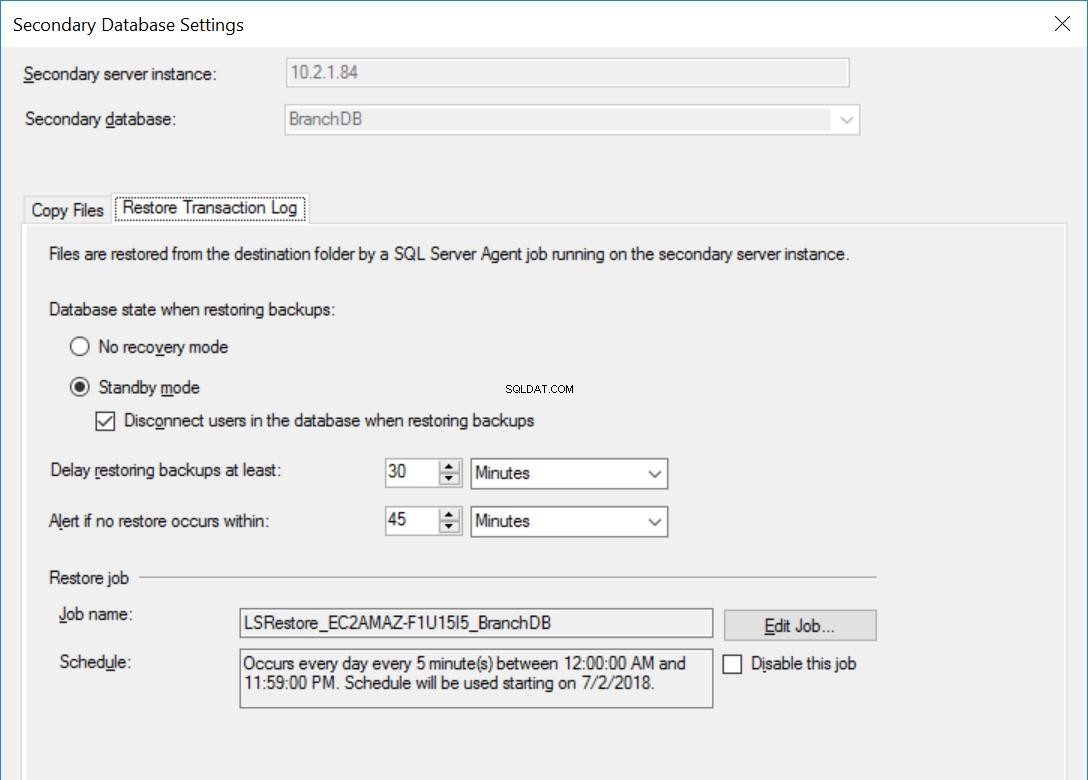
Fig. 5 Restaurar configuración para BranchDB
Cada trabajo de trasvase de registros está configurado para ejecutarse cada cinco minutos. Para procesar “Retrasar la restauración de copias de seguridad”, debemos usar el modo de recuperación en espera en la configuración de envío de registros. Es lógico ya que tiene la Base de Datos Secundaria en modo de espera e indica que podemos consultar la Base de Datos Secundaria siempre que no esté en curso una Restauración del Registro de Transacciones. El valor que especificamos en esta opción (30 minutos en este caso) nos brinda una buena ventana durante la cual podemos ejecutar informes de la base de datos secundaria además del requisito principal de este artículo, que es poder recuperarse del error del usuario.
Además, debemos mencionar que la restauración de las copias de seguridad del registro de transacciones en realidad se está retrasando. Su marca de tiempo es posterior al valor de retraso. Esto significa que todas las copias de seguridad del registro de transacciones se copiarán en el servidor secundario, que se basa en la programación y se especifica en el trabajo de copia. De hecho, el trabajo de restauración aún se ejecutará según lo programado, pero las copias de seguridad del registro de transacciones (que no tengan hasta 30 minutos de antigüedad) no se restaurarán. En esencia, la base de datos en espera de BranchDB está 30 minutos por detrás de la base de datos principal de BranchDB. Para demostrar este retraso, en la siguiente sección, crearemos una tabla en ambas bases de datos y crearemos un trabajo que inserte un registro cada minuto. Examinaremos esta tabla en las bases de datos secundarias.
Los ajustes para la base de datos CorporateDB son los mismos que en las Figs. 3 a 5, excepto por el trabajo de restauración que NO está configurado para retrasar las copias de seguridad del registro de transacciones.
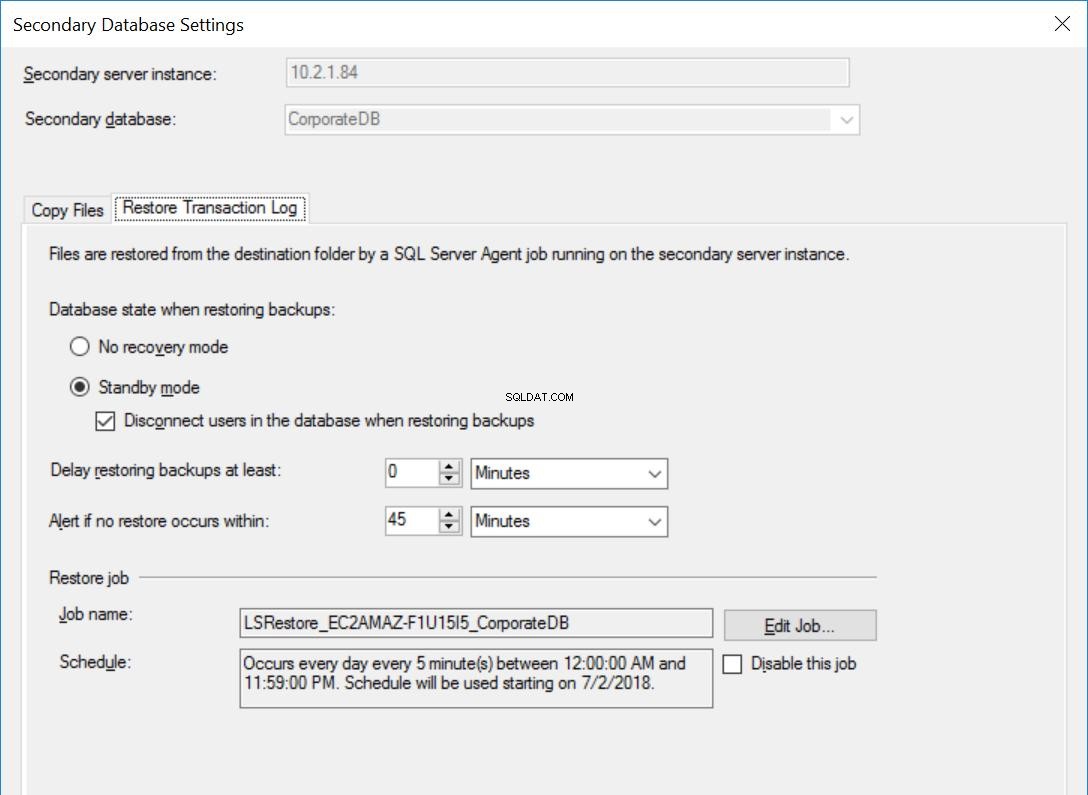
Fig. 6 Restaurar configuración para CorporateDB
Verificación de la configuración
Una vez que se realiza la configuración, podemos verificar que la configuración está bien y comenzar a observar su trabajo. El informe de envío del registro de transacciones nos muestra que la base de datos de la sucursal está rezagada con respecto a la base de datos corporativa en términos de restauraciones:
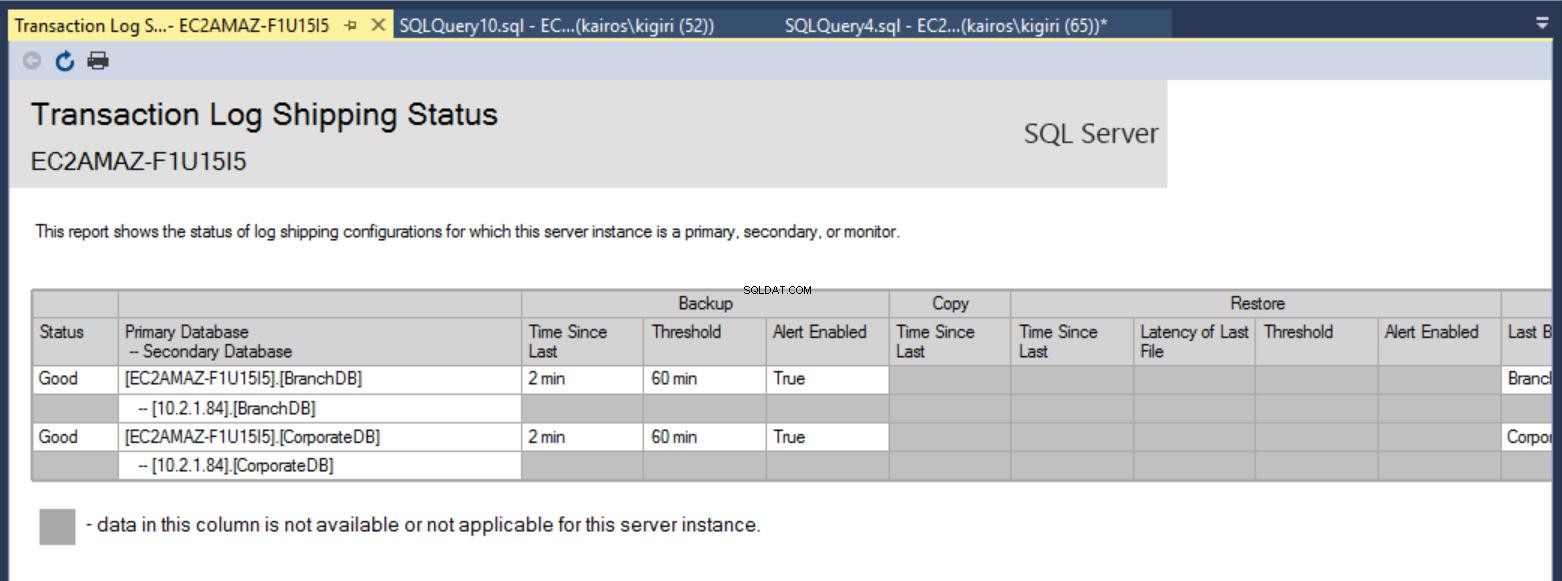
Fig. 7a Informe de envío del registro de transacciones en el servidor principal
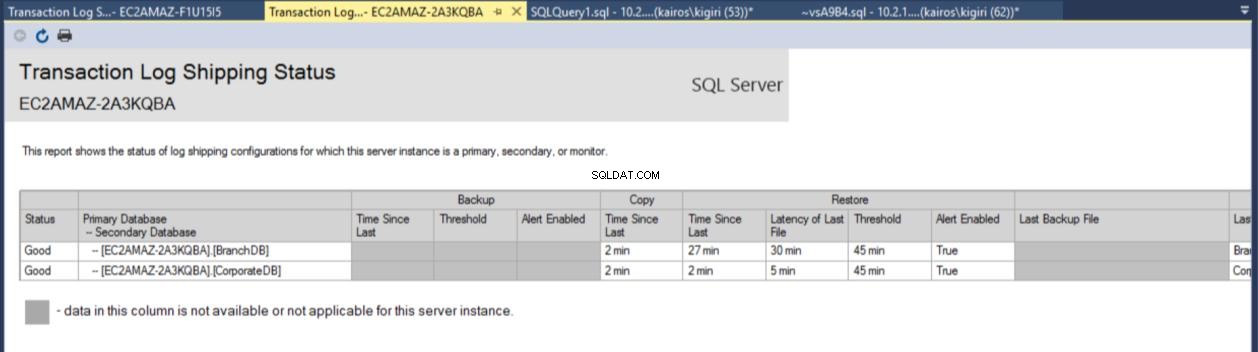
Fig. 7b Informe de envío del registro de transacciones en el servidor secundario
Además, notará el siguiente mensaje en el historial de trabajos de restauración para BranchDB:
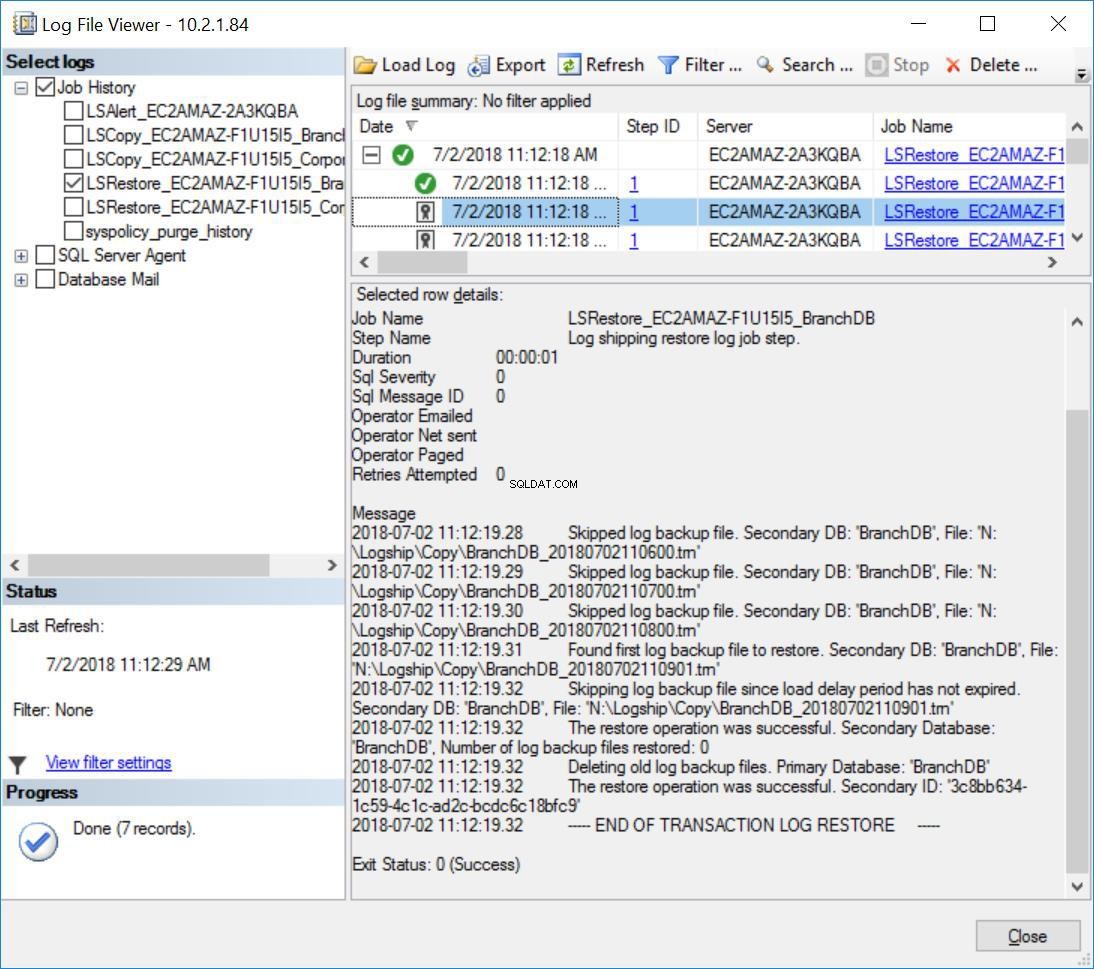
fig. 8 Restauraciones de registros de transacciones omitidas en el servidor secundario
Podemos ir más allá con esta verificación creando una tabla y usando un trabajo para llenar esta tabla con filas cada minuto. El trabajo es una forma sencilla de simular lo que una aplicación podría estar haciendo en una tabla de usuario. Esto puede mostrarnos que este retraso definitivamente se muestra en los datos del usuario.
Listado 2:Crear una tabla de seguimiento de registros
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Listado 3:Crear trabajo para completar la tabla de seguimiento de registros
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @example@sqldat.com, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Cuando consultamos la tabla en las bases de datos primarias respectivamente, podemos confirmar (mediante la columna RecordTime) que las filas coinciden en BranchDB y CorporateDB. Cuando examinamos la tabla en las bases de datos secundarias, de la misma manera, vemos claramente que tenemos una brecha de 30 minutos entre BranchDB y CorporateDB.
Listado 4:consulta de la tabla Log Tracker
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
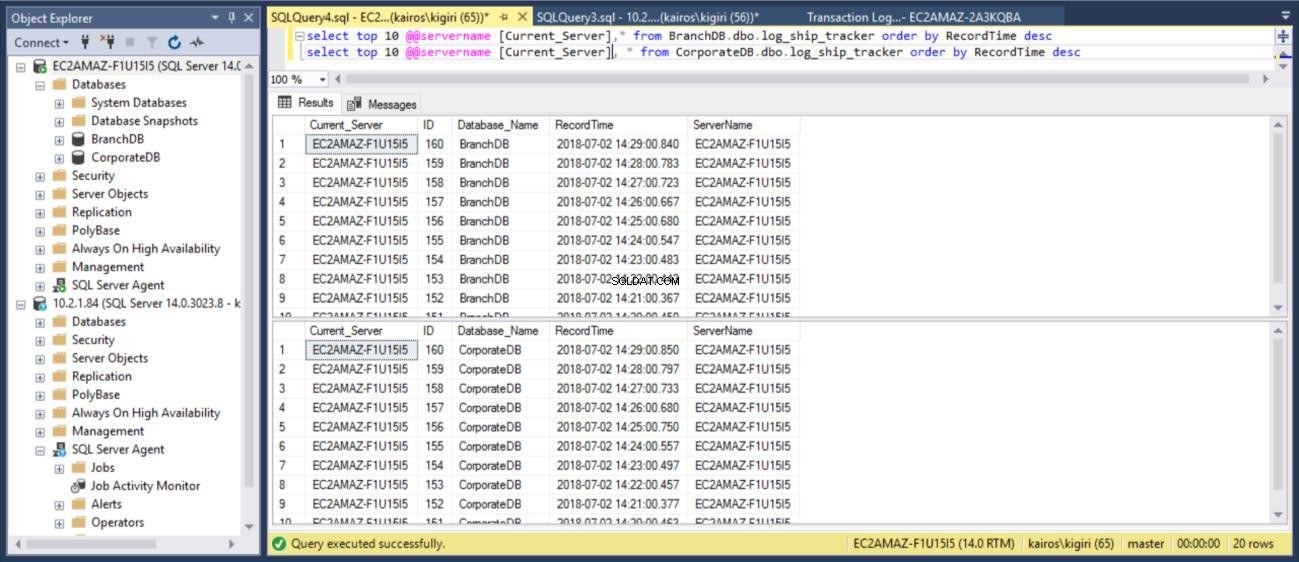
Fig. 9 Coincidencia de tablas de Log Tracker en bases de datos primarias
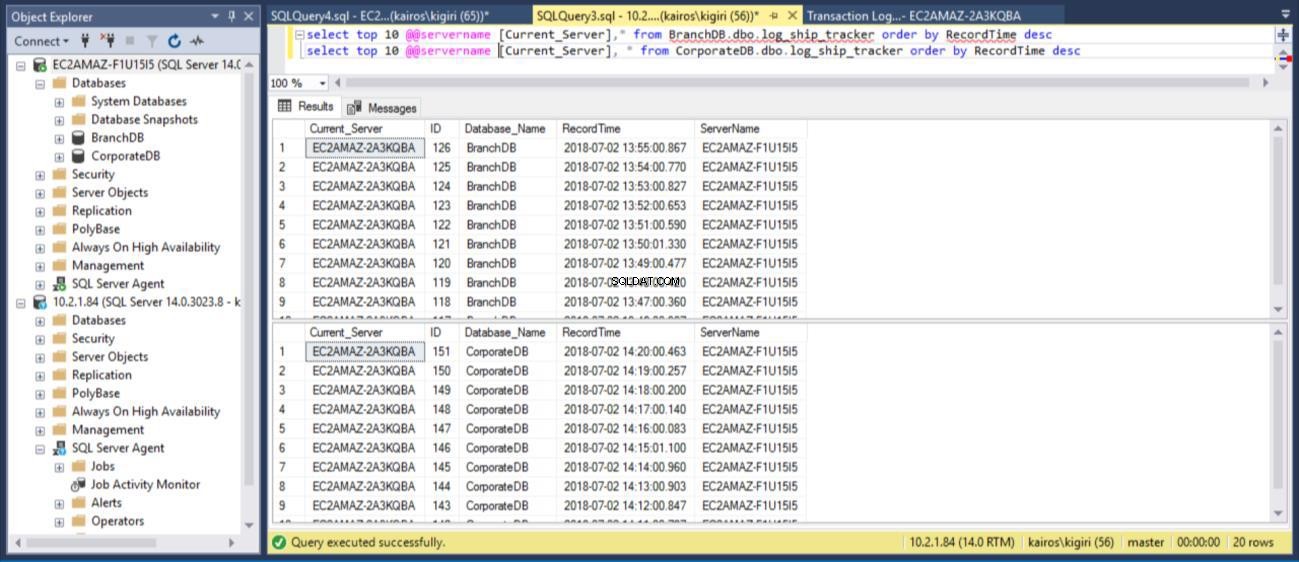
fig. 10 tablas de Log Tracker tienen una brecha de ~30 minutos en las bases de datos secundarias
Recuperación de un error de usuario
Ahora hablemos del beneficio clave de este retraso. En el escenario, donde un usuario suelta una tabla sin darse cuenta, podemos recuperar los datos rápidamente de la base de datos secundaria siempre que no haya transcurrido el período de retraso. En este ejemplo, soltamos la tabla Sales.Orderlines en AMBAS bases de datos y verificamos que la tabla ya no existe en AMBAS bases de datos.
Listado 5:Tabla de caída de líneas de pedido
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
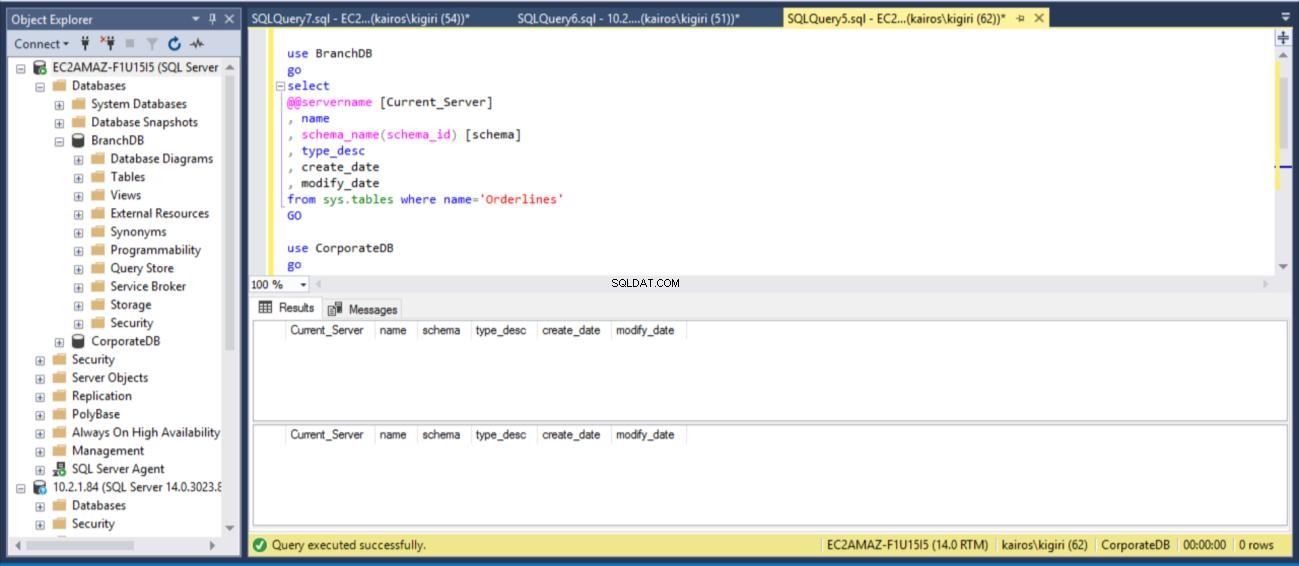
Fig. 11 Tabla de caída de ventas.Líneas de pedido
Cuando buscamos la tabla en el servidor secundario, encontramos que la tabla todavía está disponible en AMBAS bases de datos. Así, para CorporateDB tenemos menos de cinco minutos para recuperar los datos. (Figura 12). Pero una vez que se ejecuta el siguiente ciclo de restauración, perdemos la tabla en la base de datos de la base de datos corporativa. Para recuperar esta tabla, debemos realizar una recuperación puntual utilizando una copia de seguridad completa en un entorno separado y luego extraer esta tabla específica. Estarás de acuerdo en que llevará algún tiempo. Para la tabla Orderlines de BranchDB, tenemos un poco más de tiempo y podemos recuperar la tabla con una sola instrucción SQL sobre un servidor vinculado (consulte el Listado 6).
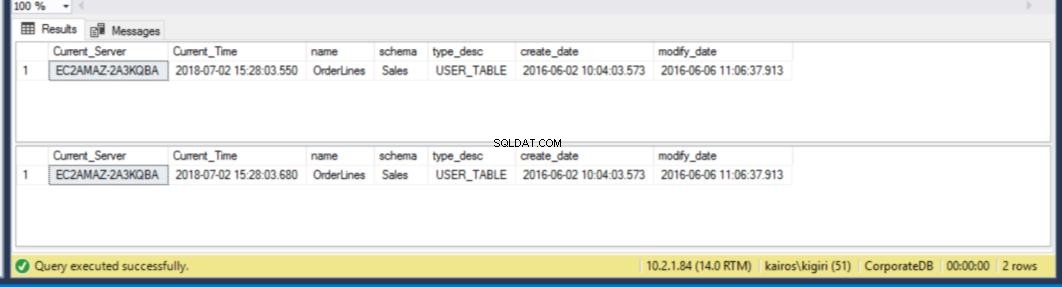
Fig. 12 Cuenta regresiva de cinco minutos:la tabla existe en ambas bases de datos secundarias
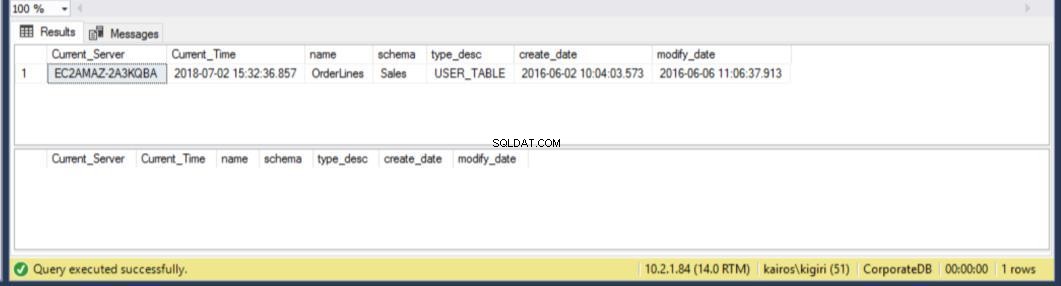
Fig. 13 25 minutos adicionales para recuperar la tabla BranchDB
Listado 6:Recuperar tabla de líneas de pedido
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
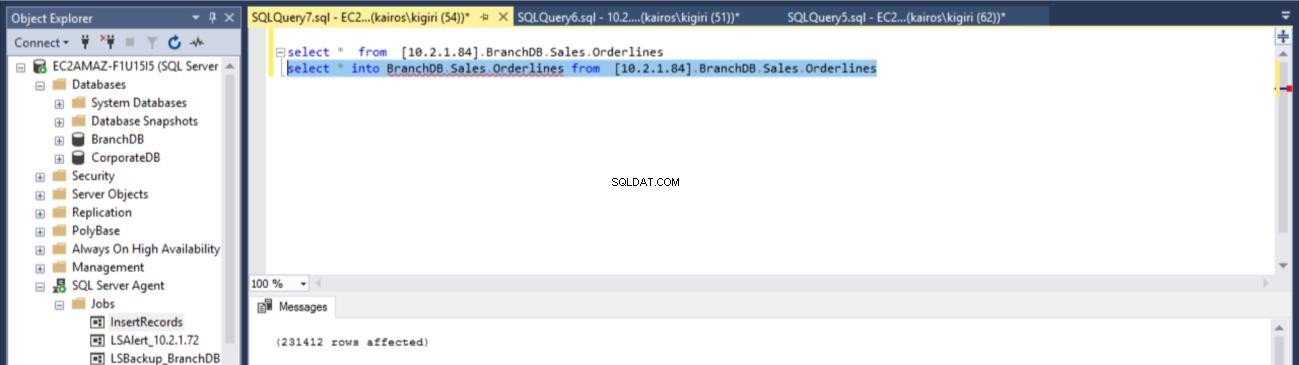
Fig. 14 Recuperar la tabla BranchDB Sales.Orderlines
Luego verificamos el Servidor Primario (Base de datos de BranchDB) que la tabla está restaurada.
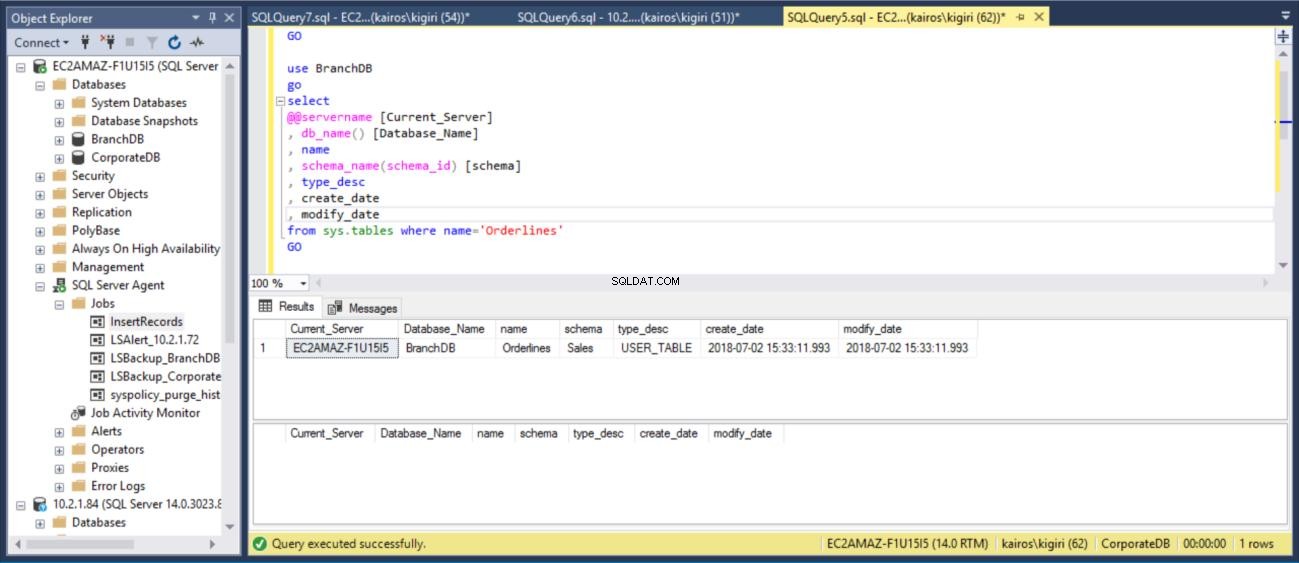
Fig. 15 Recuperar la tabla BranchDB Sales.Orderlines
Conclusión
SQL Server proporciona varias formas de recuperarse de la pérdida de datos por una variedad de causas raíz:falla del disco, corrupción, error del usuario, etc. La recuperación en un momento dado de las copias de seguridad es probablemente el más conocido de estos métodos. Para ciertos casos simples de error del usuario o casos similares, donde uno o dos objetos se pierden, el uso de Transaction Log Shipping with Delayed Recovery es un buen enfoque a considerar. Sin embargo, se debe tener en cuenta que se debe seleccionar una base de datos secundaria, que está configurada estrictamente para las necesidades de recuperación ante desastres, para RPO más bajos.



