¿Importan sus elecciones de tipos de datos del servidor SQL y sus tamaños?
La respuesta está en el resultado que obtuviste. ¿Se hinchó su base de datos en poco tiempo? ¿Tus consultas son lentas? ¿Tuviste los resultados incorrectos? ¿Qué hay de los errores de tiempo de ejecución durante las inserciones y actualizaciones?
No es una tarea tan desalentadora si sabes lo que estás haciendo. Hoy aprenderá las 5 peores elecciones que se pueden hacer con estos tipos de datos. Si se han convertido en un hábito tuyo, esto es lo que debemos corregir por tu propio bien y el de tus usuarios.
Muchos tipos de datos en SQL, mucha confusión
Cuando aprendí por primera vez sobre los tipos de datos de SQL Server, las opciones eran abrumadoras. Todos los tipos están mezclados en mi mente como esta nube de palabras en la Figura 1:

Sin embargo, podemos organizarlo en categorías:
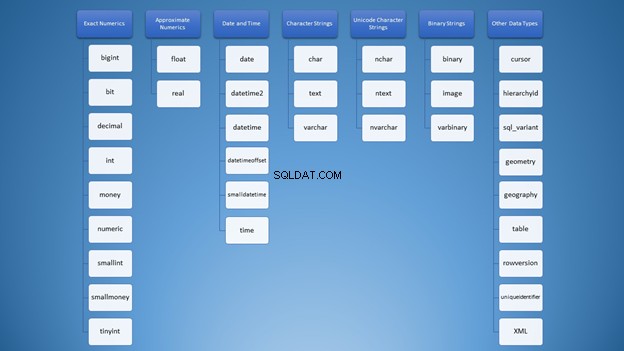
Aún así, para usar cadenas, tiene muchas opciones que pueden conducir a un uso incorrecto. Al principio, pensé que varchar y nvarchar eran iguales. Además, ambos son tipos de cadenas de caracteres. Usar números no es diferente. Como desarrolladores, necesitamos saber qué tipo usar en diferentes situaciones.
Pero quizás te preguntes, ¿qué es lo peor que puede pasar si tomo la decisión equivocada? ¡Déjame decirte!
1. Elegir los tipos de datos SQL incorrectos
Este artículo usará cadenas y números enteros para probar el punto.
Uso del tipo de datos SQL de cadena de caracteres incorrecto
Primero, volvamos a las cuerdas. Existe esta cosa llamada cadenas Unicode y no Unicode. Ambos tienen diferentes tamaños de almacenamiento. A menudo define esto en columnas y declaraciones de variables.
La sintaxis es varchar (n)/carácter (n) o nvarchar (n)/nchar (n) donde n es el tamaño.
Tenga en cuenta que n no es el número de caracteres sino el número de bytes. Es un error común que sucede porque, en varchar , el número de caracteres es el mismo que el tamaño en bytes. Pero no en nvarchar .
Para probar este hecho, creemos 2 tablas y coloquemos algunos datos en ellas.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Ahora, verifiquemos el tamaño de sus filas usando DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
La figura 3 muestra que la diferencia es doble. Compruébalo a continuación.
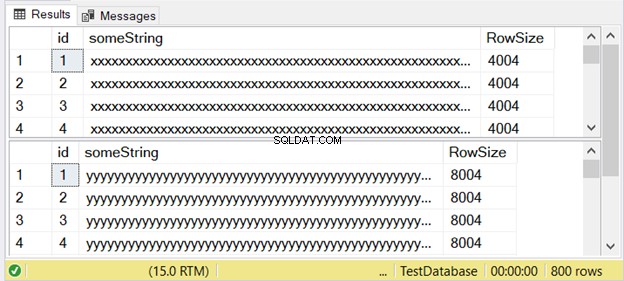
Observe el segundo conjunto de resultados con un tamaño de fila de 8004. Esto usa el nvarchar tipo de datos. También es casi dos veces más grande que el tamaño de fila del primer conjunto de resultados. Y esto usa el varchar tipo de datos.
Puede ver la implicación en el almacenamiento y la E/S. La Figura 4 muestra las lecturas lógicas de las 2 consultas.
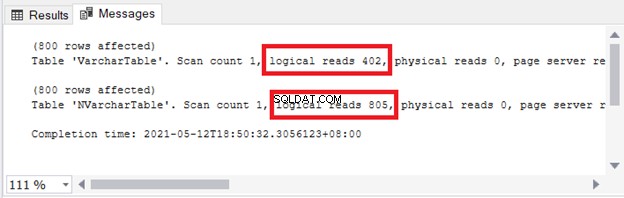
¿Ver? Las lecturas lógicas también son dobles cuando se usa nvarchar en comparación con varchar .
Por lo tanto, no puede simplemente usar indistintamente cada uno. Si necesita almacenar multilingüe caracteres, use nvarchar . De lo contrario, use varchar .
Esto significa que si usa nvarchar solo para caracteres de un solo byte (como el inglés), el tamaño de almacenamiento es mayor . El rendimiento de las consultas también es más lento con lecturas lógicas más altas.
En SQL Server 2019 (y superior), puede almacenar el rango completo de datos de caracteres Unicode usando varchar o char con cualquiera de las opciones de intercalación UTF-8.
Uso del SQL de tipo de datos numérico incorrecto
El mismo concepto se aplica con bigint frente a int – sus tamaños pueden significar noche y día. Me gusta nvarchar y varchar , grande es el doble del tamaño de int (8 bytes para bigint y 4 bytes para int ).
Aún así, otro problema es posible. Si no le importan sus tamaños, pueden ocurrir errores. Si usa un int columna y almacena un número mayor que 2,147,483,647, se producirá un desbordamiento aritmético:
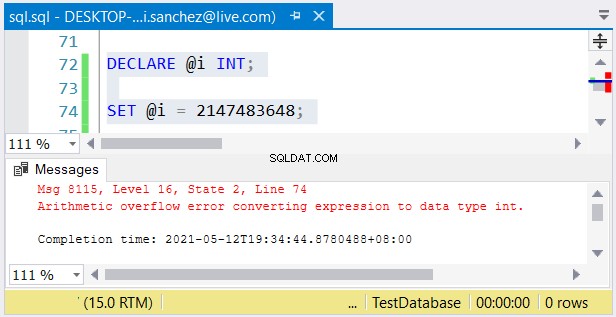
Al elegir tipos de números enteros, asegúrese de que los datos con el valor máximo se ajusten . Por ejemplo, podría estar diseñando una tabla con datos históricos. Tiene previsto utilizar números enteros como valor de clave principal. ¿Crees que no llegará a las 2.147.483.647 filas? Luego usa int en lugar de bigint como el tipo de columna de clave principal.
Lo peor que puede pasar
La elección de tipos de datos incorrectos puede afectar el rendimiento de las consultas o provocar errores de tiempo de ejecución. Por lo tanto, elija el tipo de datos adecuado para los datos.
2. Hacer filas de tablas grandes usando tipos de datos grandes para SQL
Nuestro próximo elemento está relacionado con el primero, pero ampliará el punto aún más con ejemplos. Además, tiene algo que ver con páginas y varchar de gran tamaño o nvarchar columnas.
¿Qué pasa con las páginas y los tamaños de fila?
El concepto de páginas en SQL Server se puede comparar con las páginas de un cuaderno de espiral. Cada página en un cuaderno tiene el mismo tamaño físico. Escribes palabras y haces dibujos sobre ellas. Si una página no es suficiente para un conjunto de párrafos e imágenes, continúe en la página siguiente. A veces, también rompes una página y empiezas de nuevo.
Del mismo modo, los datos de la tabla, las entradas del índice y las imágenes en SQL Server se almacenan en páginas.
Una página tiene el mismo tamaño de 8 KB. Si una fila de datos es muy grande, no cabrá en la página de 8 KB. Una o más columnas se escribirán en otra página bajo la unidad de asignación ROW_OVERFLOW_DATA. Contiene un puntero a la fila original en la página bajo la unidad de asignación IN_ROW_DATA.
En base a esto, no puede ajustar muchas columnas en una tabla durante el diseño de la base de datos. Habrá consecuencias en I/O. Además, si consulta mucho estos datos de desbordamiento de filas, el tiempo de ejecución es más lento . Esto puede ser una pesadilla.
Surge un problema cuando maximiza todas las columnas de diferentes tamaños. Luego, los datos pasarán a la siguiente página bajo ROW_OVERFLOW_DATA. actualice las columnas con datos de menor tamaño, y debe eliminarse en esa página. La nueva fila de datos más pequeña se escribirá en la página bajo IN_ROW_DATA junto con las otras columnas. Imagina la E/S involucrada aquí.
Ejemplo de fila grande
Primero preparemos nuestros datos. Usaremos tipos de datos de cadena de caracteres con tamaños grandes.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Obtención del tamaño de fila
A partir de los datos generados, inspeccionemos sus tamaños de fila en función de DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
Los primeros 300 registros se ajustarán a las páginas IN_ROW_DATA porque cada fila tiene menos de 8060 bytes u 8 KB. Pero las últimas 100 filas son demasiado grandes. Consulte el conjunto de resultados en la Figura 6.
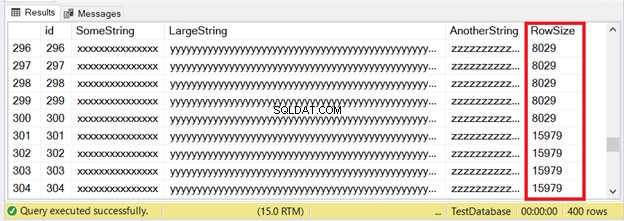
Ves parte de las primeras 300 filas. Los siguientes 100 superan el límite de tamaño de página. ¿Cómo sabemos que las últimas 100 filas están en la unidad de asignación ROW_OVERFLOW_DATA?
Inspección de ROW_OVERFLOW_DATA
Usaremos sys.dm_db_index_physical_stats . Devuelve información de la página sobre las entradas de la tabla y el índice.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
El conjunto de resultados se muestra en la Figura 7.

Ahí está. La figura 7 muestra 100 filas en ROW_OVERFLOW_DATA. Esto es consistente con la Figura 6 cuando existen filas grandes que comienzan con las filas 301 a 400.
La siguiente pregunta es cuántas lecturas lógicas obtenemos cuando consultamos estas 100 filas. Intentémoslo.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vemos 102 lecturas lógicas y 100 lecturas lógicas de lob de LargeTable . Deje estos números por ahora, los compararemos más tarde.
Ahora, veamos qué sucede si actualizamos las 100 filas con datos más pequeños.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Esta declaración de actualización usó las mismas lecturas lógicas y lecturas lógicas de lob que en la Figura 8. A partir de esto, sabemos que sucedió algo más grande debido a las lecturas lógicas de lob de 100 páginas.
Pero para estar seguros, comprobémoslo con sys.dm_db_index_physical_stats como hicimos antes. La figura 9 muestra el resultado:

¡Ido! Las páginas y filas de ROW_OVERFLOW_DATA se convirtieron en cero después de actualizar 100 filas con datos más pequeños. Ahora sabemos que el movimiento de datos de ROW_OVERFLOW_DATA a IN_ROW_DATA ocurre cuando se reducen las filas grandes. Imagínese si esto sucede mucho para miles o incluso millones de registros. Loco, ¿no?
En la Figura 8, vimos 100 lecturas lógicas de lob. Ahora, vea la Figura 10 después de volver a ejecutar la consulta:

¡Se convirtió en cero!
Lo peor que puede pasar
El rendimiento lento de las consultas es el subproducto de los datos de desbordamiento de filas. Considere mover las columnas de gran tamaño a otra tabla para evitarlo. O, si corresponde, reduzca el tamaño del varchar o nvarchar columna.
3. Usando ciegamente la conversión implícita
SQL no nos permite usar datos sin especificar el tipo. Pero es indulgente si tomamos una decisión equivocada. Intenta convertir el valor al tipo que espera, pero con una penalización. Esto puede suceder en una cláusula WHERE o JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
El Número de tarjeta columna no es un tipo numérico. Es nvarchar . Entonces, el primer SELECT causará una conversión implícita. Sin embargo, ambos funcionarán bien y producirán el mismo conjunto de resultados.
Veamos el plan de ejecución en la Figura 11.
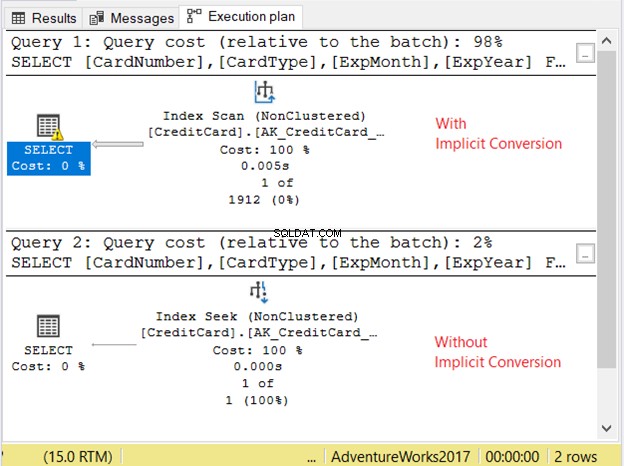
Las 2 consultas se ejecutaron muy rápido. En la Figura 11, son cero segundos. Pero mira los 2 planes. El que tenía conversión implícita tenía un escaneo de índice. También hay un ícono de advertencia y una flecha gruesa que apunta al operador SELECCIONAR. Nos dice que es malo.
Pero no termina ahí. Si pasa el mouse sobre el operador SELECCIONAR, verá algo más:

El ícono de advertencia en el operador SELECT se trata de la conversión implícita. Pero, ¿qué tan grande es el impacto? Revisemos las lecturas lógicas.
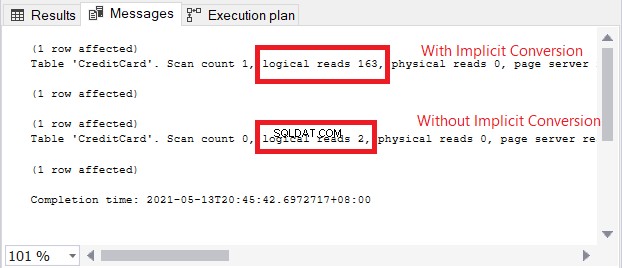
La comparación de lecturas lógicas en la Figura 13 es como el cielo y la tierra. En la consulta de información de la tarjeta de crédito, la conversión implícita provocó más de cien veces las lecturas lógicas. ¡Muy mal!
Lo peor que puede pasar
Si una conversión implícita provocó muchas lecturas lógicas y un mal plan, espere un rendimiento de consulta lento en conjuntos de resultados grandes. Para evitar esto, use el tipo de datos exacto en la cláusula WHERE y ÚNASE para hacer coincidir las columnas que compara.
4. Usar valores numéricos aproximados y redondearlos
Mira la figura 2 de nuevo. Los tipos de datos del servidor SQL que pertenecen a valores numéricos aproximados son float y reales . Las columnas y variables hechas de ellas almacenan una aproximación cercana de un valor numérico. Si planea redondear estos números hacia arriba o hacia abajo, es posible que se lleve una gran sorpresa. Tengo un artículo que discute esto en detalle aquí. Vea cómo 1 + 1 da como resultado 3 y cómo puede lidiar con el redondeo de números.
Lo peor que puede pasar
Redondeo de un flotante o real puede tener resultados locos. Si desea valores exactos después del redondeo, use decimal o numérico en su lugar.
5. Establecer tipos de datos de cadena de tamaño fijo en NULL
Dirijamos nuestra atención a tipos de datos de tamaño fijo como char y nchar . Además de los espacios acolchados, establecerlos en NULL aún tendrá un tamaño de almacenamiento igual al tamaño del char columna. Entonces, establecer un char (500) columna a NULL tendrá un tamaño de 500, no cero o 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
En el código anterior, los datos se maximizan según el tamaño de char y varchar columnas Verificar el tamaño de fila usando DATALENGTH también mostrará la suma de los tamaños de cada columna. Ahora establezcamos las columnas en NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
A continuación, consultamos las filas usando DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
¿Cuáles crees que serán los tamaños de datos de cada columna? Mira la Figura 14.
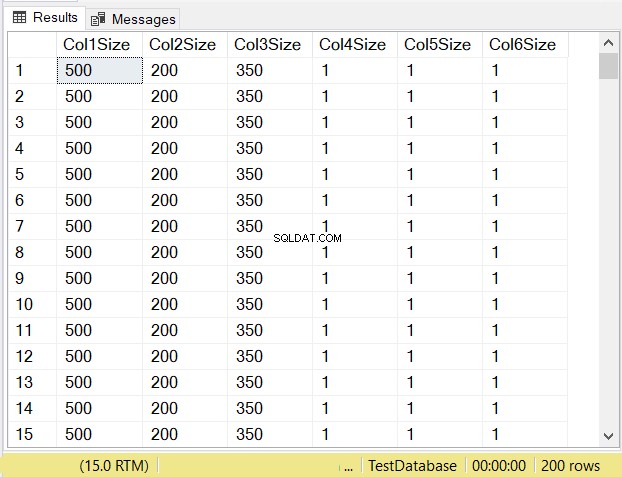
Mire los tamaños de columna de las primeras 3 columnas. Luego compárelos con el código anterior cuando se creó la tabla. El tamaño de datos de las columnas NULL es igual al tamaño de la columna. Mientras tanto, el varchar columnas cuando NULL tiene un tamaño de datos de 1.
Lo peor que puede pasar
Durante las tablas de diseño, char anulable las columnas, cuando se establecen en NULL, seguirán teniendo el mismo tamaño de almacenamiento. También consumirán las mismas páginas y RAM. Si no llena toda la columna con caracteres, considere usar varchar en su lugar.
¿Qué sigue?
Entonces, ¿importan sus elecciones en los tipos de datos del servidor SQL y sus tamaños? Los puntos presentados aquí deberían ser suficientes para hacer un punto. Entonces, ¿qué puedes hacer ahora?
- Tómese el tiempo para revisar la base de datos que admite. Comience con el más fácil si tiene varios en su plato. Y sí, hacer tiempo, no encontrar el tiempo. En nuestra línea de trabajo, es casi imposible encontrar el tiempo.
- Revise las tablas, los procedimientos almacenados y todo lo relacionado con tipos de datos. Tenga en cuenta el impacto positivo al identificar problemas. Lo necesitará cuando su jefe le pregunte por qué tiene que trabajar en esto.
- Planifique atacar cada una de las áreas problemáticas. Siga las metodologías o políticas que tenga su empresa para abordar los problemas.
- Una vez que los problemas hayan desaparecido, celebre.
Suena fácil, pero todos sabemos que no lo es. También sabemos que hay un lado positivo al final del viaje. Por eso se llaman problemas – porque hay una solución. Así que anímate.
¿Tienes algo más que añadir sobre este tema? Infórmenos en la sección para comentarios. Y si esta publicación te dio una idea brillante, compártela en tus plataformas de redes sociales favoritas.