Introducción
Es de conocimiento común en los círculos de bases de datos que los índices mejoran el rendimiento de las consultas ya sea satisfaciendo el conjunto de resultados requerido por completo (índices de cobertura) o actuando como búsquedas que dirigen fácilmente el motor de consulta a la ubicación exacta del conjunto de datos requerido. Sin embargo, como saben los administradores de bases de datos experimentados, uno no debe entusiasmarse demasiado con la creación de índices en entornos OLTP sin comprender la naturaleza de la carga de trabajo. Usando Query Store en la instancia de SQL Server 2019 (Query Store se introdujo en SQL Server 2016), es bastante fácil mostrar el efecto de un índice en las inserciones.
Insertar sin índice
Comenzamos restaurando la base de datos de muestra de WideWorldImporters y luego creando una copia de Sales. Facturas usando el script en el Listado 1. Tenga en cuenta que la base de datos de muestra ya tiene habilitado el Almacén de consultas en modo de lectura y escritura.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Observe que no hay ningún índice en la tabla que acabamos de crear. Todo lo que tenemos es la estructura de la tabla. Una vez hecho esto, realizamos inserciones en la nueva tabla usando los datos de su padre como se muestra en el Listado 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Durante esta operación, Query Store captura el plan de ejecución de la consulta. La Figura 1 muestra brevemente lo que sucede debajo del capó. Leyendo de izquierda a derecha, vemos que SQL Server ejecuta las inserciones usando Plan ID 563 – un escaneo de índice en la clave principal de la tabla de origen para obtener los datos y luego una inserción de tabla en la tabla de destino. (Lectura de izquierda a derecha). Tenga en cuenta que, en este caso, la mayor parte del costo está en el inserto de la tabla:99 % del costo de la consulta.
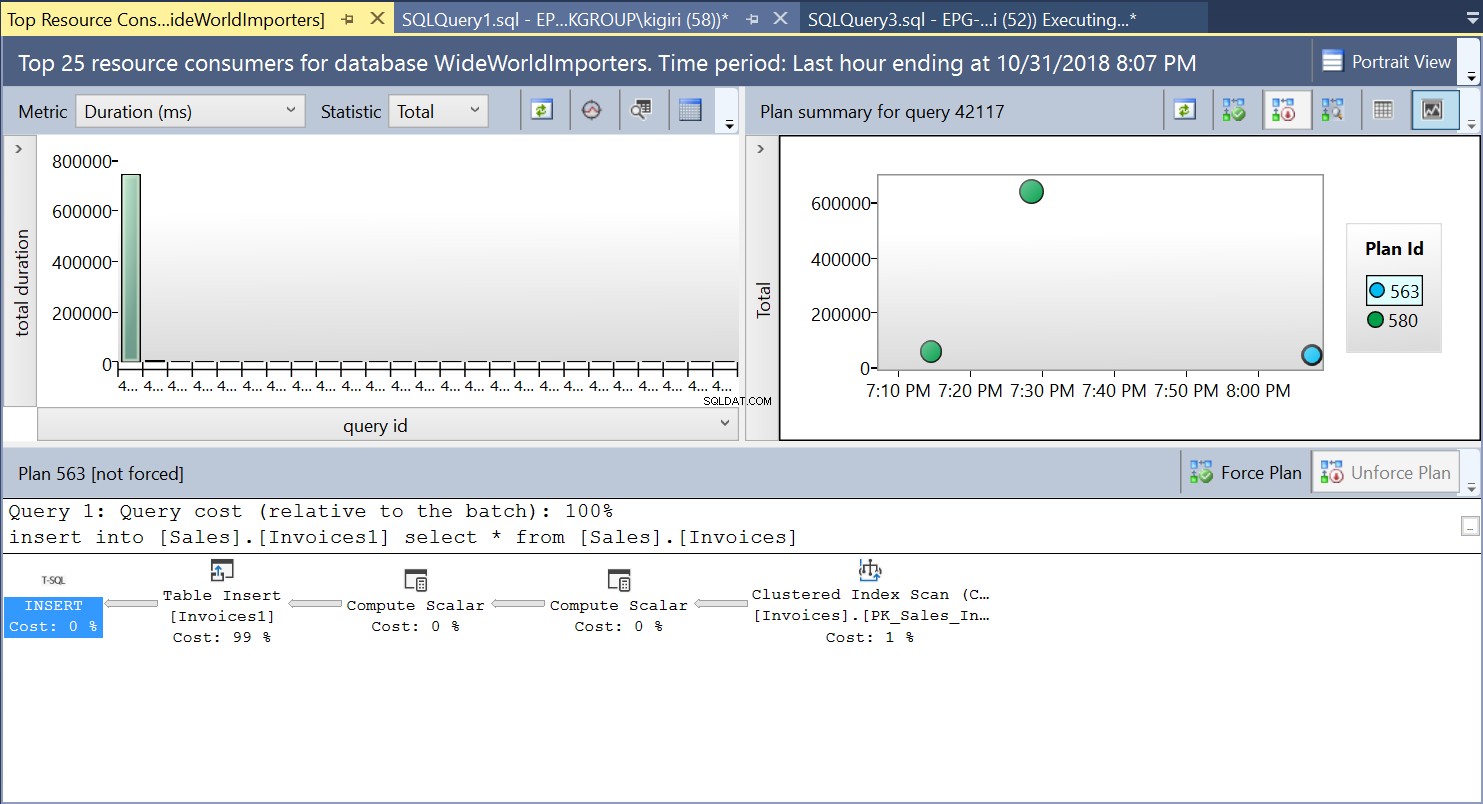
Fig. 1 Plan de Ejecución 563
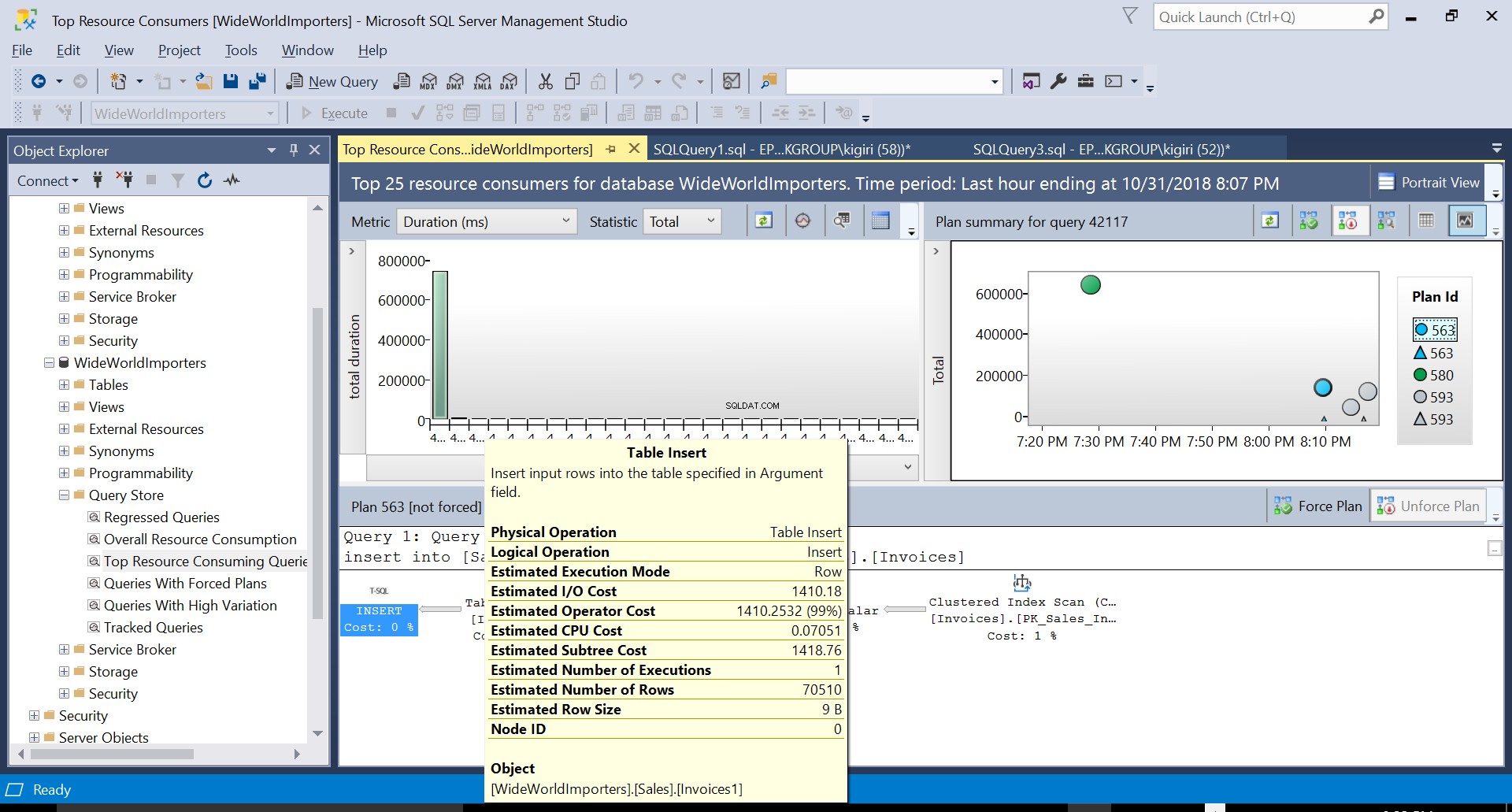
Fig. 2 Insertar tabla en destino
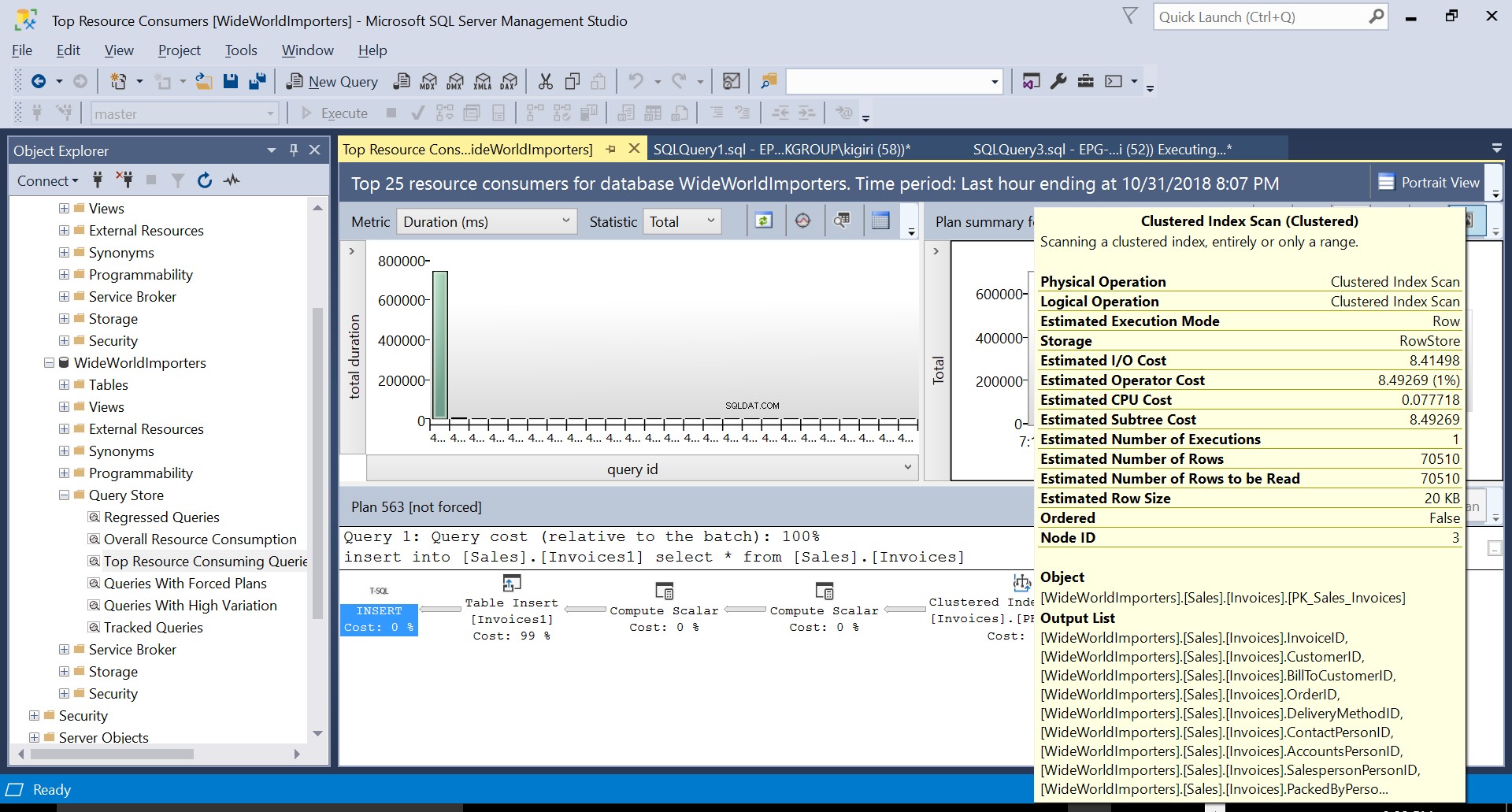
Fig. 3 Escaneo de índice agrupado en la tabla de origen
Insertar con índice
Luego, creamos un índice en la tabla de destino usando el DDL en el Listado 3. Cuando repetimos la declaración en el Listado 2 después de truncar la tabla de destino, vemos un plan de ejecución ligeramente diferente (Plan ID 593 que se muestra en la Fig. 4). Todavía vemos el inserto de tabla, pero contribuye solo al 58 % al costo de la consulta. La dinámica de ejecución está un poco sesgada con la introducción de una ordenación y una inserción de índice. Básicamente, lo que sucede es que SQL Server debe introducir filas correspondientes en el índice a medida que se introducen nuevos registros en la tabla.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
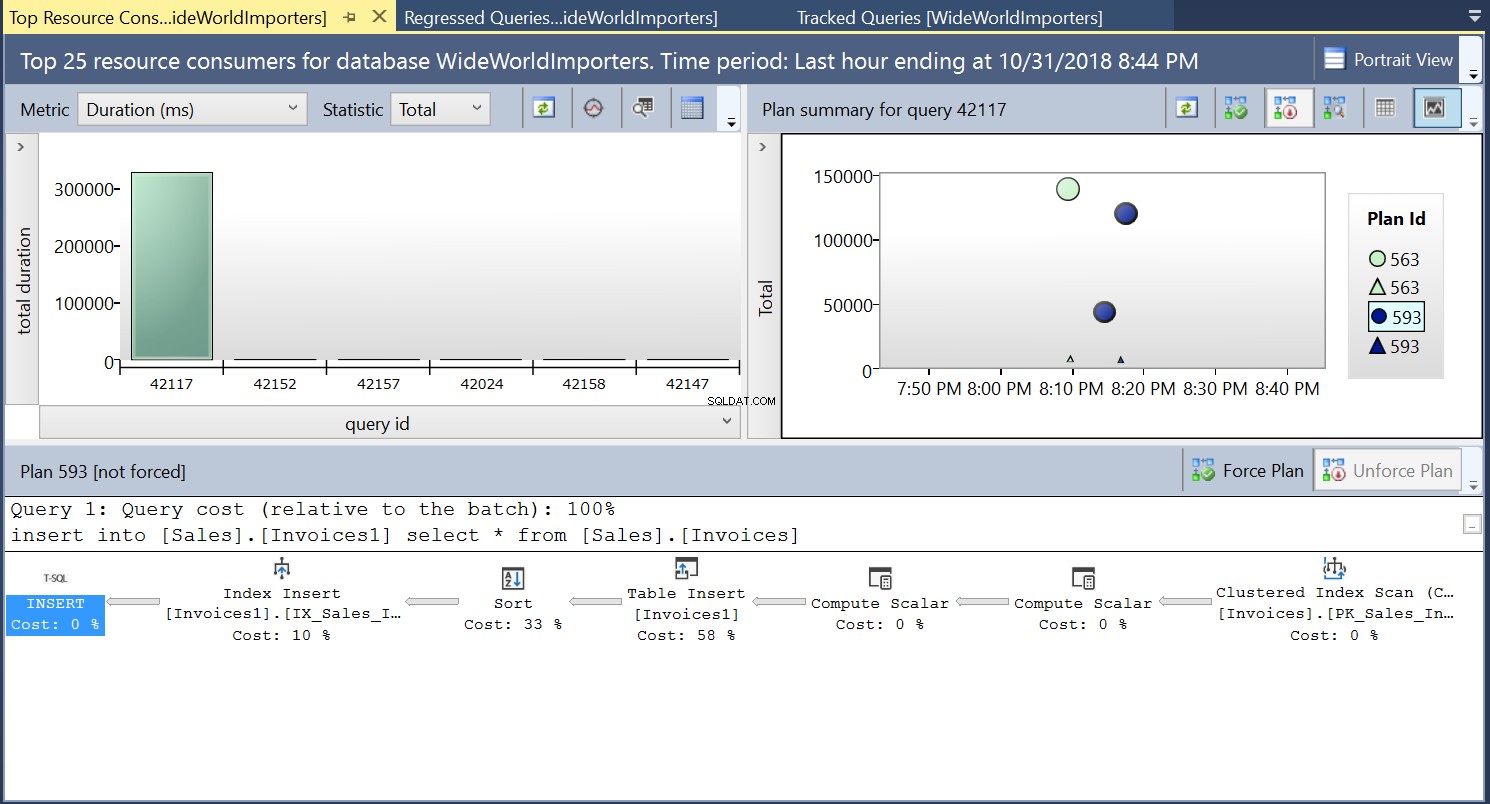
Fig. 4 Plan de Ejecución 593
Mirando más profundo
Podemos examinar los detalles de ambos planes y ver cómo estos nuevos factores aumentan el tiempo de ejecución de la declaración. El plan 593 agrega aproximadamente 300 ms adicionales a la duración promedio de la declaración. Bajo una gran carga de trabajo en un entorno de producción, esta diferencia podría ser significativa.
Activar STATISTICS IO cuando se ejecuta la declaración de inserción solo una vez en ambos casos, con índice en la tabla de destino y sin índice en la tabla de destino, también muestra que se trabaja más en términos de E/S lógica al insertar filas en una tabla con índices.
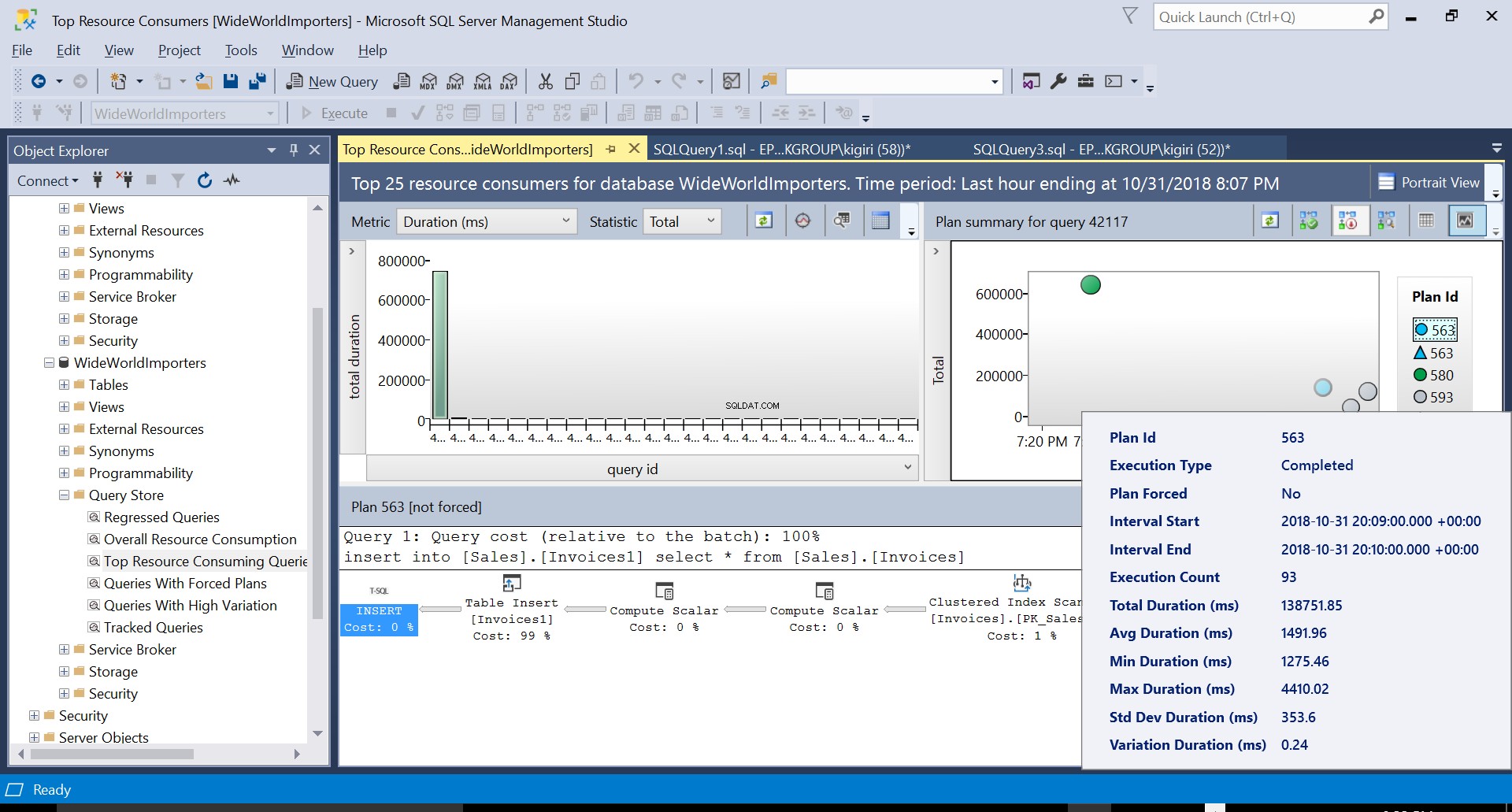
Fig. 5 Detalles del Plan de Ejecución 563
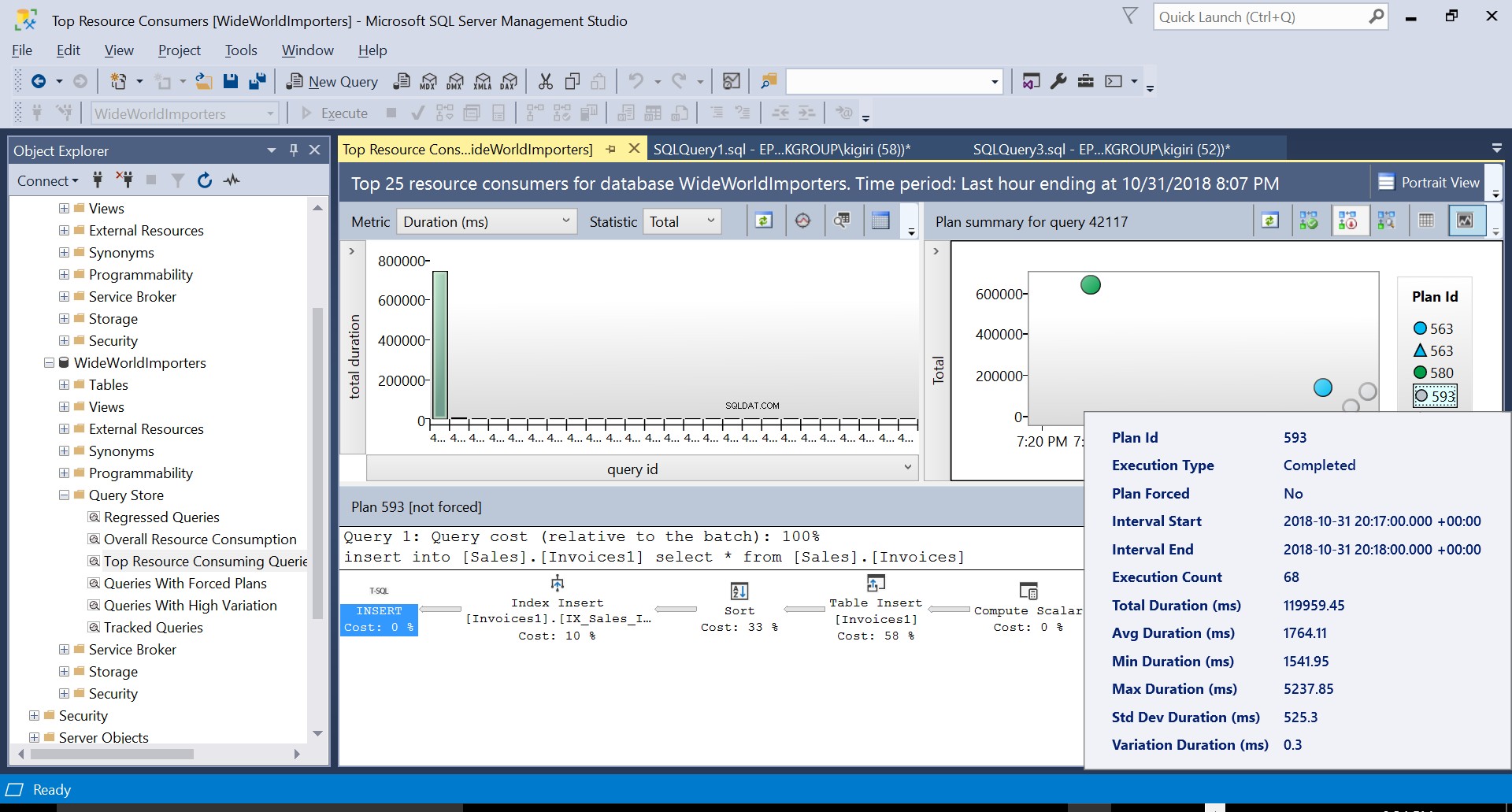
Fig. 4 Detalles del Plan de Ejecución 593
Sin índice:salida con STATISTICS IO activado:
Tabla 'Facturas1'. Recuento de escaneos 0, lecturas lógicas 78372 , lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Facturas'. Recuento de escaneos 1, lecturas lógicas 11400, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
(70510 filas afectadas)
Índice:Salida con STATISTICS IO activado:
Tabla 'Facturas1'. Recuento de escaneos 0, lecturas lógicas 81119 , lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Mesa ‘Mesa de trabajo’. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Facturas'. Recuento de escaneos 1, lecturas lógicas 11400 , lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
(70510 filas afectadas)
Información adicional
Microsoft y otras fuentes proporcionan scripts para examinar el entorno de producción de índices e identificar situaciones como:
- Índices redundantes – Índices que están duplicados
- Índices que faltan – Índices que podrían mejorar el rendimiento según la carga de trabajo
- Montones – Tablas sin índices agrupados
- Tablas sobreindexadas – Tablas con más índices que columnas
- Uso del índice – Recuento de búsquedas, escaneos y búsquedas en índices
Los elementos 2, 3 y 5 están más relacionados con el impacto en el rendimiento con respecto a las lecturas, mientras que los elementos 1 y 4 están relacionados con el impacto en el rendimiento con respecto a las escrituras. Los listados 4 y 5 son dos ejemplos de estas consultas disponibles públicamente.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Conclusión
Hemos demostrado, usando Query Store, que la carga de trabajo adicional con un índice puede introducirse en el plan de ejecución de una declaración de inserción de muestra. En producción, los índices excesivos y redundantes pueden tener un impacto negativo en el rendimiento, especialmente en bases de datos destinadas a cargas de trabajo OLTP. Es importante utilizar las secuencias de comandos y las herramientas disponibles para examinar los índices y determinar si realmente ayudan o perjudican el rendimiento.
Herramienta útil:
dbForge Index Manager:práctico complemento de SSMS para analizar el estado de los índices SQL y solucionar problemas con la fragmentación de índices.