Resumen
Este artículo analiza dos enfoques diferentes disponibles para eliminar filas duplicadas de las tablas de SQL, lo que a menudo se vuelve difícil con el tiempo a medida que crecen los datos si no se hace a tiempo.
La presencia de filas duplicadas es un problema común al que se enfrentan los desarrolladores y evaluadores de SQL de vez en cuando; sin embargo, estas filas duplicadas se clasifican en varias categorías diferentes que analizaremos en este artículo.
Este artículo se enfoca en un escenario específico, cuando los datos insertados en una tabla de base de datos conducen a la introducción de registros duplicados y luego analizaremos más de cerca los métodos para eliminar duplicados y finalmente eliminar los duplicados usando estos métodos.
Preparación de datos de muestra
Antes de comenzar a explorar las diferentes opciones disponibles para eliminar duplicados, vale la pena en este punto configurar una base de datos de muestra que nos ayudará a comprender las situaciones en las que los datos duplicados ingresan al sistema y los enfoques que se utilizarán para erradicarlos. .
Configurar base de datos de muestra (UniversityV2)
Comience por crear una base de datos muy simple que consista solo de un Estudiante tabla al principio.
-- (1) Create UniversityV2 sample database
CREATE DATABASE UniversityV2;
GO
USE UniversityV2
CREATE TABLE [dbo].[Student] (
[StudentId] INT IDENTITY (1, 1) NOT NULL,
[Name] VARCHAR (30) NULL,
[Course] VARCHAR (30) NULL,
[Marks] INT NULL,
[ExamDate] DATETIME2 (7) NULL,
CONSTRAINT [PK_Student] PRIMARY KEY CLUSTERED ([StudentId] ASC)
);
Rellenar tabla de estudiantes
Agreguemos solo dos registros a la tabla Student:
-- Adding two records to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Comprobación de datos
Vea la tabla que contiene dos registros distintos en este momento:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
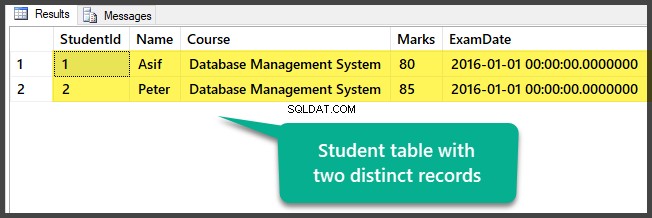
Ha preparado con éxito los datos de muestra configurando una base de datos con una tabla y dos registros distintos (diferentes).
Vamos a discutir ahora algunos escenarios potenciales en los que se introdujeron y eliminaron duplicados, desde situaciones simples hasta situaciones ligeramente complejas.
Caso 01:Adición y eliminación de duplicados
Ahora vamos a introducir filas duplicadas en la tabla Student.
Precondiciones
En este caso, se dice que una tabla tiene registros duplicados si el Nombre de un estudiante , Curso , Marcas y Fecha del examen coincidir en más de un registro aunque el DNI del alumno es diferente.
Por lo tanto, asumimos que dos estudiantes no pueden tener el mismo nombre, curso, calificaciones y fecha de examen.
Agregar datos duplicados para Student Asif
Insertemos deliberadamente un registro duplicado para Estudiante:Asif al Estudiante tabla de la siguiente manera:
-- Adding Student Asif duplicate record to the Student table
SET IDENTITY_INSERT [dbo].[Student] ON
INSERT INTO [dbo].[Student] ([StudentId], [Name], [Course], [Marks], [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')
SET IDENTITY_INSERT [dbo].[Student] OFF
Ver datos de estudiantes duplicados
Ver el Estudiante tabla para ver registros duplicados:
-- View Student table data
SELECT [StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
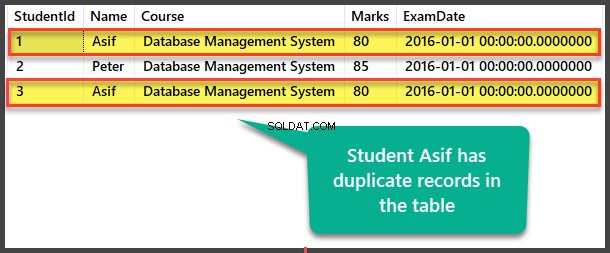
Búsqueda de duplicados por método de autorreferencia
¿Qué sucede si hay miles de registros en esta tabla? Ver la tabla no será de mucha ayuda.
En el método de autorreferencia, tomamos dos referencias a la misma tabla y las unimos usando el mapeo columna por columna con la excepción del ID que se hace menor o mayor que el otro.
Veamos el método de autorreferencia para encontrar duplicados que se ve así:
USE UniversityV2
-- Self-Referencing method to finding duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1,[dbo].[Student] S2
WHERE S1.StudentId<S2.StudentId AND
S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
El resultado del script anterior nos muestra solo los registros duplicados:

Búsqueda de duplicados mediante el método de autorreferencia-2
Otra forma de encontrar duplicados usando autorreferencias es usar INNER JOIN de la siguiente manera:
-- Self-Referencing method 2 to find duplicate students having same name, course, marks, exam date
SELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID
,S1.Name AS S1_Name, S2.Name as S2_Name
,S1.Course AS S1_Course, S2.Course as S2_Course
,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
INNER JOIN
[dbo].[Student] S2
ON S1.Name=S2.Name
AND
S1.Course=S2.Course
AND
S1.Marks=S2.Marks
AND
S1.ExamDate=S2.ExamDate
WHERE S1.StudentId<S2.StudentId

Eliminación de duplicados por método de autorreferencia
Podemos eliminar los duplicados usando el mismo método que usamos para encontrar duplicados con la excepción de usar DELETE en línea con su sintaxis de la siguiente manera:
USE UniversityV2
-- Removing duplicates by using Self-Referencing method
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
Comprobación de datos después de la eliminación de duplicados
Revisemos rápidamente los registros después de que hayamos eliminado los duplicados:
USE UniversityV2
-- View Student data after duplicates have been removed
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
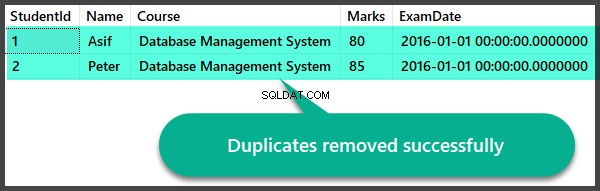
Creación de vista de duplicados y procedimiento almacenado de eliminación de duplicados
Ahora que sabemos que nuestras secuencias de comandos pueden encontrar y eliminar con éxito filas duplicadas en SQL, es mejor convertirlas en vista y procedimiento almacenado para facilitar su uso:
USE UniversityV2;
GO
-- Creating view find duplicate students having same name, course, marks, exam date using Self-Referencing method
CREATE VIEW dbo.Duplicates
AS
SELECT
S1.[StudentId] AS S1_StudentId
,S2.StudentId AS S2_StudentID
,S1.Name AS S1_Name
,S2.Name AS S2_Name
,S1.Course AS S1_Course
,S2.Course AS S2_Course
,S1.ExamDate AS S1_ExamDate
,S2.ExamDate AS S2_ExamDate
FROM [dbo].[Student] S1
,[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
GO
-- Creating stored procedure to removing duplicates by using Self-Referencing method
CREATE PROCEDURE UspRemoveDuplicates
AS
BEGIN
DELETE S2
FROM [dbo].[Student] S1,
[dbo].[Student] S2
WHERE S1.StudentId < S2.StudentId
AND S1.Name = S2.Name
AND S1.Course = S2.Course
AND S1.Marks = S2.Marks
AND S1.ExamDate = S2.ExamDate
END
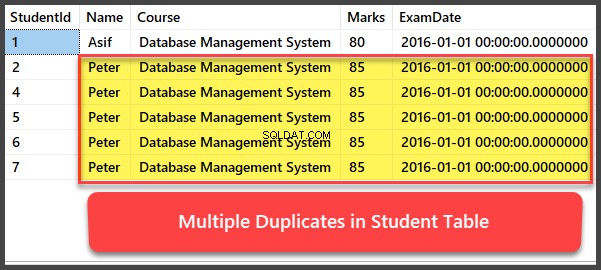
Agregar y ver varios registros duplicados
Agreguemos ahora cuatro registros más al Estudiante tabla y todos los registros se duplican de tal manera que tienen el mismo nombre, curso, notas y fecha de examen:
--Adding multiple duplicates to Student table
INSERT INTO Student (Name,
Course,
Marks,
ExamDate)
VALUES ('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01'),
('Peter', 'Database Management System', 85, '2016-01-01');
-- Viewing Student table after multiple records have been added to Student table
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Eliminación de duplicados mediante el procedimiento UspRemoveDuplicates
USE UniversityV2
-- Removing multiple duplicates
EXEC UspRemoveDuplicates
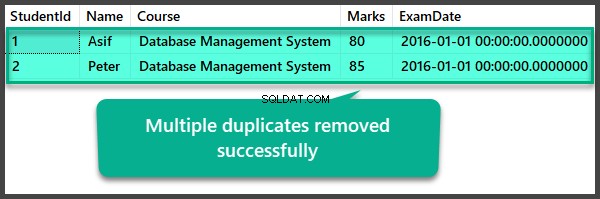
Comprobación de datos después de la eliminación de varios duplicados
USE UniversityV2
--View Student table after multiple duplicates removal
SELECT
[StudentId]
,[Name]
,[Course]
,[Marks]
,[ExamDate]
FROM [UniversityV2].[dbo].[Student]
Caso 02:Adición y eliminación de duplicados con los mismos ID
Hasta ahora, hemos identificado registros duplicados con identificaciones distintas, pero ¿y si las identificaciones son las mismas?
Por ejemplo, piense en el escenario en el que una tabla se ha importado recientemente desde un archivo de texto o de Excel que no tiene clave principal.
Precondiciones
En este caso, se dice que una tabla tiene registros duplicados si todos los valores de las columnas son exactamente iguales, incluida alguna columna de ID, y falta la clave principal, lo que facilitó el ingreso de registros duplicados.
Crear tabla de cursos sin clave principal
Para reproducir el escenario en el que los registros duplicados en ausencia de una clave principal caen en una tabla, primero creemos un nuevo Curso tabla sin ninguna clave principal en la base de datos de University2 de la siguiente manera:
USE UniversityV2
-- Creating Course table without primary key
CREATE TABLE [dbo].[Course] (
[CourseId] INT NOT NULL,
[Name] VARCHAR (30) NOT NULL,
[Detail] VARCHAR (200) NULL,
);
Poblar tabla de cursos
-- Populating Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (2, N'Tabular Data Modeling', N'This is about Tabular Data Modeling')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail]) VALUES (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')
Comprobación de datos
Ver el Curso tabla:
USE UniversityV2
-- Viewing Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course
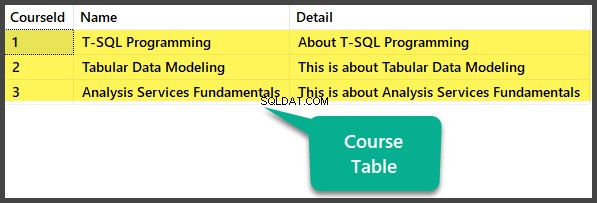
Adición de datos duplicados en la tabla del curso
Ahora inserte duplicados en el Curso tabla:
USE UniversityV2
-- Inserting duplicate records in Course table
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detail])
VALUES (1, N'T-SQL Programming', N'About T-SQL Programming')
Ver datos de cursos duplicados
Seleccione todas las columnas para ver la tabla:
USE UniversityV2
-- Viewing duplicate data in Course table
SELECT CourseId
,Name
,Detail FROM dbo.Course

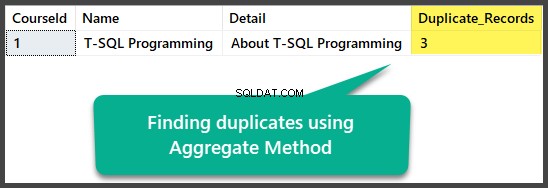
Búsqueda de duplicados por método agregado
Podemos encontrar duplicados exactos usando el método agregado al agrupar todas las columnas con un total de más de una después de seleccionar todas las columnas y contar todas las filas usando la función de conteo agregado (*):
-- Finding duplicates using Aggregate method
SELECT <column1>,<column2>,<column3>…
,COUNT(*) AS Total_Records
FROM <Table>
GROUP BY <column1>,<column2>,<column3>…
HAVING COUNT(*)>1
Esto se puede aplicar de la siguiente manera:
USE UniversityV2
-- Finding duplicates using Aggregate method
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
Eliminación de duplicados por método agregado
Eliminemos los duplicados usando el método agregado de la siguiente manera:
USE UniversityV2
-- Removing duplicates using Aggregate method
-- (1) Finding duplicates and put them into a new table (CourseNew) as a single row
SELECT
c.CourseId
,c.Name
,c.Detail
,COUNT(*) AS Duplicate_Records INTO CourseNew
FROM dbo.Course c
GROUP BY c.CourseId
,c.Name
,c.Detail
HAVING COUNT(*) > 1
-- (2) Rename Course (which contains duplicates) as Course_OLD
EXEC sys.sp_rename @objname = N'Course'
,@newname = N'Course_OLD'
-- (3) Rename CourseNew (which contains no duplicates) as Course
EXEC sys.sp_rename @objname = N'CourseNew'
,@newname = N'Course'
-- (4) Insert original distinct records into Course table from Course_OLD table
INSERT INTO Course (CourseId, Name, Detail)
SELECT
co.CourseId
,co.Name
,co.Detail
FROM Course_OLD co
WHERE co.CourseId <> (SELECT
c.CourseId
FROM Course c)
ORDER BY CO.CourseId
-- (4) Data check
SELECT
cn.CourseId
,cn.Name
,cn.Detail
FROM Course cn
-- Clean up
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
Comprobación de datos
USE Universidad V2
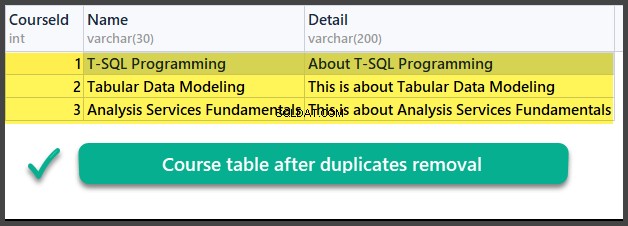
Entonces, hemos aprendido con éxito cómo eliminar duplicados de una tabla de base de datos usando dos métodos diferentes basados en dos escenarios diferentes.
Cosas que hacer
Ahora puede identificar y liberar fácilmente una tabla de base de datos del valor duplicado.
1. Intente crear el UspRemoveDuplicatesByAggregate procedimiento almacenado basado en el método mencionado anteriormente y elimine los duplicados llamando al procedimiento almacenado
2. Intente modificar el procedimiento almacenado creado anteriormente (UspRemoveDuplicatesByAggregates) e implemente las sugerencias de limpieza mencionadas en este artículo.
DROP TABLE CourseNew
-- (5) You can drop the Course_OLD table afterwards
-- (6) You can remove Duplicate_Records column from Course table afterwards
3. ¿Puede estar seguro de que UspRemoveDuplicatesByAggregate procedimiento almacenado se puede ejecutar tantas veces como sea posible, incluso después de eliminar los duplicados, para demostrar que el procedimiento sigue siendo coherente en primer lugar?
4. Consulte mi artículo anterior Saltar para comenzar el desarrollo de bases de datos basadas en pruebas (TDDD):parte 1 e intente insertar duplicados en las tablas de la base de datos SQLDevBlog, luego intente eliminar los duplicados utilizando los dos métodos mencionados en este consejo.
5. Intente crear otra base de datos de muestra EmployeesSample haciendo referencia a mi artículo anterior El arte de aislar dependencias y datos en pruebas unitarias de bases de datos e inserte duplicados en las tablas e intente eliminarlos usando los dos métodos que aprendió de este consejo.
Herramienta útil:
Comparación de datos de dbForge para SQL Server:una poderosa herramienta de comparación de SQL capaz de trabajar con grandes datos.