TimescaleDB es una base de datos de código abierto inventada para hacer que SQL sea escalable para datos de series temporales. Es un sistema de base de datos relativamente nuevo. TimescaleDB se introdujo en el mercado hace dos años y alcanzó la versión 1.0 en septiembre de 2018. Sin embargo, está diseñado sobre un sistema RDBMS maduro.
TimescaleDB está empaquetado como una extensión de PostgreSQL. Todo el código tiene licencia de código abierto Apache-2, con la excepción de algunos códigos fuente relacionados con las funciones empresariales de series temporales con licencia de escala de tiempo (TSL).
Como base de datos de series temporales, proporciona particiones automáticas a través de fechas y valores clave. La compatibilidad con SQL nativo de TimescaleDB lo convierte en una buena opción para aquellos que planean almacenar datos de series temporales y ya tienen un conocimiento sólido del lenguaje SQL.
Si está buscando una base de datos de serie temporal que pueda usar SQL enriquecido, alta disponibilidad, una solución de copia de seguridad sólida, replicación y otras características empresariales, este blog puede ponerlo en el camino correcto.
Cuándo usar TimescaleDB
Antes de comenzar con las características de TimescaleDB, veamos dónde puede encajar. TimescaleDB fue diseñado para ofrecer lo mejor de NoSQL y relacional, con el enfoque de series de tiempo. Pero, ¿qué son los datos de series temporales?
Los datos de series temporales son el núcleo del Internet de las cosas, los sistemas de monitoreo y muchas otras soluciones centradas en datos que cambian con frecuencia. Como sugiere el nombre de "series de tiempo", estamos hablando de datos que cambian con el tiempo. Las posibilidades para este tipo de DBMS son infinitas. Puede usarlo en varios casos de uso de IoT industrial en los sectores de fabricación, minería, petróleo y gas, comercio minorista, atención médica, monitoreo de operaciones de desarrollo o información financiera. También puede encajar en gran medida en las canalizaciones de aprendizaje automático o como fuente de inteligencia y operaciones comerciales.
No hay duda de que la demanda de IoT y soluciones similares crecerá. Dicho esto, también podemos esperar la necesidad de analizar y procesar datos de muchas maneras diferentes. Los datos de series temporales generalmente solo se agregan; es muy poco probable que actualice datos antiguos. Por lo general, no elimina filas particulares; por otro lado, es posible que desee algún tipo de agregación de datos a lo largo del tiempo. No solo queremos almacenar cómo cambian nuestros datos con el tiempo, sino también analizarlos y aprender de ellos.
El problema con los nuevos tipos de sistemas de bases de datos es que suelen utilizar su propio lenguaje de consulta. Se necesita tiempo para que los usuarios aprendan un nuevo idioma. La mayor diferencia entre TimescaleDB y otras bases de datos de series temporales populares es la compatibilidad con SQL. TimescaleDB es compatible con la gama completa de funciones de SQL, incluidos los agregados basados en el tiempo, las uniones, las subconsultas, las funciones de ventana y los índices secundarios. Además, si su aplicación ya usa PostgreSQL, no se necesitan cambios en el código del cliente.
Conceptos básicos de arquitectura
TimescaleDB se implementa como una extensión en PostgreSQL, lo que significa que una base de datos de escala de tiempo se ejecuta dentro de una instancia general de PostgreSQL. El modelo de extensión permite que la base de datos aproveche muchos de los atributos de PostgreSQL, como la confiabilidad, la seguridad y la conectividad con una amplia gama de herramientas de terceros. Al mismo tiempo, TimescaleDB aprovecha el alto grado de personalización disponible para las extensiones al agregar enlaces profundos en el planificador de consultas, el modelo de datos y el motor de ejecución de PostgreSQL.
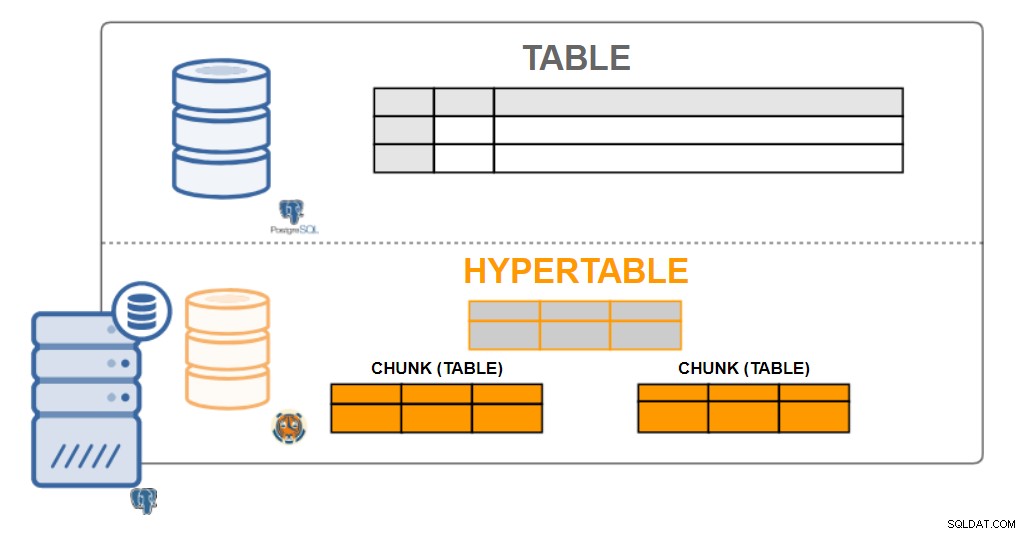 Arquitectura TimescaleDB
Arquitectura TimescaleDB Hipermesas
Desde la perspectiva del usuario, los datos de TimescaleDB parecen tablas singulares, llamadas hipertablas. Las hipertablas son un concepto o una vista implícita de muchas tablas individuales que contienen los datos llamados fragmentos. Los datos de la hipertabla pueden ser de una o dos dimensiones. Se puede agregar por un intervalo de tiempo y por un valor de "clave de partición" (opcional).
Prácticamente todas las interacciones de los usuarios con TimescaleDB son con hipertablas. La creación de tablas, los índices, la modificación de tablas, la selección de datos, la inserción de datos... todo debe ejecutarse en la hipertabla.
TimescaleDB realiza este particionamiento extenso tanto en implementaciones de un solo nodo como en implementaciones en clúster (en desarrollo). Si bien el particionamiento solo se usa tradicionalmente para escalar horizontalmente en varias máquinas, también nos permite escalar a altas tasas de escritura (y consultas en paralelo mejoradas) incluso en máquinas individuales.
Soporte de datos relacionales
Como base de datos relacional, tiene soporte completo para SQL. TimescaleDB admite modelos de datos flexibles que se pueden optimizar para diferentes casos de uso. Esto hace que Timescale sea algo diferente de la mayoría de las otras bases de datos de series temporales. El DBMS está optimizado para una ingesta rápida y consultas complejas, basado en PostgreSQL y, cuando es necesario, tenemos acceso a un sólido procesamiento de series temporales.
Instalación
TimescaleDB, de manera similar a PostgreSQL, admite muchas formas diferentes de instalación, incluida la instalación en Ubuntu, Debian, RHEL/Centos, Windows o plataformas en la nube.
Una de las formas más convenientes de jugar con TimescaleDB es una imagen acoplable.
El siguiente comando extraerá una imagen de Docker de Docker Hub si aún no se ha instalado y luego la ejecutará.
docker run -d --name timescaledb -p 5432:5432 -e POSTGRES_PASSWORD=severalnines timescale/timescaledbPrimer uso
Dado que nuestra instancia está en funcionamiento, es hora de crear nuestra primera base de datos timescaledb. Como puede ver a continuación, nos conectamos a través de la consola estándar de PostgreSQL, por lo que si tiene herramientas de cliente de PostgreSQL (por ejemplo, psql) instaladas localmente, puede usarlas para acceder a la instancia de la ventana acoplable TimescaleDB.
psql -U postgres -h localhost
CREATE DATABASE severalnines;
\c severalnines
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;Operaciones diarias
Desde la perspectiva del uso y la administración, TimescaleDB se ve y se siente como PostgreSQL, y se puede administrar y consultar como tal.
Los puntos principales de las operaciones diarias son:
- Coexiste con otras bases de datos de TimescaleDB y PostgreSQL en un servidor PostgreSQL.
- Utiliza SQL como lenguaje de interfaz.
- Utiliza conectores PostgreSQL comunes para herramientas de terceros para copias de seguridad, consola, etc.
Configuración de base de datos de escala de tiempo
La configuración lista para usar de PostgreSQL suele ser demasiado conservadora para los servidores modernos y TimescaleDB. Debe asegurarse de que la configuración de postgresql.conf esté ajustada, ya sea usando timescaledb-tune o haciéndolo manualmente.
$ timescaledb-tuneEl script le pedirá que confirme los cambios. Estos cambios luego se escriben en su postgresql.conf y tendrán efecto en el reinicio.
Ahora, echemos un vistazo a algunas operaciones básicas del tutorial de TimescaleDB que pueden darle una idea de cómo trabajar con el nuevo sistema de base de datos.
Para crear una hipertabla, comienza con una tabla SQL normal y luego la convierte en una hipertabla a través de la función create_hypertable.
-- Create extension timescaledb
CREATE EXTENSION timescaledb;
Create a regular table
CREATE TABLE conditions (
time TIMESTAMPTZ NOT NULL,
location TEXT NOT NULL,
temperature DOUBLE PRECISION NULL,
humidity DOUBLE PRECISION NULL
);Convertirlo a hipertable es tan simple como:
SELECT create_hypertable('conditions', 'time');La inserción de datos en la hipertabla se realiza mediante comandos SQL normales:
INSERT INTO conditions(time, location, temperature, humidity)
VALUES (NOW(), 'office', 70.0, 50.0);Seleccionar datos es un buen SQL antiguo.
SELECT * FROM conditions ORDER BY time DESC LIMIT 10;Como podemos ver a continuación, podemos hacer un grupo por, ordenar por y funciones. Además, TimescaleDB incluye funciones para el análisis de series de tiempo que no están presentes en PostgreSQL estándar.
SELECT time_bucket('15 minutes', time) AS fifteen_min,
location, COUNT(*),
MAX(temperature) AS max_temp,
MAX(humidity) AS max_hum
FROM conditions
WHERE time > NOW() - interval '3 hours'
GROUP BY fifteen_min, location
ORDER BY fifteen_min DESC, max_temp DESC;