IRI ahora también ofrece funciones de búsqueda difusa, tanto en su base de datos gratuita y herramientas de creación de perfiles de archivos planos, como en bibliotecas de funciones de campo disponibles en IRI CoSort, FieldShield y Voracity para aumentar la calidad de los datos, la seguridad y las capacidades de MDM. Este es el primero de una serie de artículos sobre las soluciones de búsqueda difusa de IRI que cubren su aplicación para mejorar la calidad de los datos.
Introducción
La veracidad o confiabilidad de los datos de una de las grandes palabras con "V" (junto con el volumen, la variedad, la velocidad y el valor) de las que hablan IRI y otros en el contexto de la gestión de datos e información empresarial. Generalmente, IRI define los datos en duda como aquellos que tienen uno o más de estos atributos:
- Baja calidad, porque es inconsistente, inexacta o incompleta
- Ambiguo (piense en MDM), impreciso (no estructurado) o engañoso (redes sociales)
- Sesgada (pregunta de la encuesta), ruidosa (superflua o contaminada) o anormal (valores atípicos)
- No válido por cualquier otro motivo (¿los datos son correctos y precisos para el uso previsto?)
- Inseguro:¿contiene PII o secretos, y está debidamente enmascarado, reversible, etc.?
Este artículo se centra únicamente en las nuevas soluciones de búsqueda difusa para el primer problema, la calidad de los datos. Otros artículos en este blog analizan cómo el software IRI aborda los otros cuatro problemas de veracidad; pide ayuda para encontrarlos si no puedes.
Acerca de la búsqueda difusa
Las búsquedas aproximadas encuentran palabras o frases (valores) que son similares, pero no necesariamente idénticas, a otras palabras o frases (valores). Este tipo de búsqueda tiene muchos usos, como encontrar errores de secuencia, errores de ortografía, caracteres transpuestos y otros que veremos más adelante.
Realizar una búsqueda aproximada de palabras o frases aproximadas puede ayudar a encontrar datos que pueden ser duplicados de datos almacenados previamente. Sin embargo, la entrada del usuario o la corrección automática pueden haber alterado los datos de alguna manera para que los registros parezcan independientes.
El resto del artículo cubrirá cuatro funciones de búsqueda aproximada que ahora admite IRI, cómo usarlas para rastrear sus datos y devolver esos registros que se aproximan al valor de búsqueda.
1. Levenshtein
El algoritmo de Levenshtein funciona tomando dos palabras o frases y contando cuántos pasos de edición serán necesarios para convertir una palabra o frase en otra. Cuantos menos pasos tome, más probable es que la palabra o frase coincida. Los pasos que puede tomar la función de Levenshtein son:
- Inserción de un carácter en la palabra o frase
- Eliminación de un carácter de la palabra o frase
- Reemplazo de un carácter en una palabra o frase con otro
El siguiente es un programa CoSort SortCL (script de trabajo) que demuestra cómo usar la función de búsqueda aproximada de Levenshtein:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Hay dos partes que se deben usar para producir el resultado deseado.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Esta línea llama a la función fs_levenshtein y almacena el resultado en el campo FS_RESULT. La función toma dos parámetros de entrada:
- El campo para ejecutar la búsqueda aproximada (NOMBRE en nuestro ejemplo)
- La cadena con la que se comparará el campo de entrada ("Barney Oakley" en nuestro ejemplo).
/INCLUDE WHERE FS_RESULT GT 50
Esta línea compara el campo FS_RESULT y verifica si es mayor que 50, luego solo se generan los registros con un FS_RESULT de más de 50. A continuación se muestra el resultado de nuestro ejemplo.

Como muestra el resultado, este tipo de búsqueda es útil para encontrar:
- Nombres concatenados
- Ruido
- Errores de ortografía
- Caracteres transpuestos
- Errores de transcripción
- Errores de escritura
La función de Levenshtein también es útil para identificar errores comunes de entrada de datos. Sin embargo, es el que tarda más en ejecutarse de los cuatro algoritmos, ya que compara cada carácter de una cadena con cada carácter de la otra.
El coeficiente de dados, o algoritmo de dados, divide palabras o frases en pares de caracteres, compara esos pares y cuenta las coincidencias. Cuantas más coincidencias tengan las palabras, más probable es que la palabra misma sea una coincidencia.
La siguiente secuencia de comandos de SortCL demuestra la función de búsqueda aproximada de coeficientes de dados.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Hay dos partes que se deben usar para darnos el resultado deseado.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Esta línea llama a la función fs_dice y almacena el resultado en el campo FS_RESULT. La función toma dos parámetros de entrada:
- El campo para ejecutar la búsqueda aproximada (NOMBRE en nuestro ejemplo).
- La cadena con la que se comparará el campo de entrada ("Robert Thomas Smith" en nuestro ejemplo).
/INCLUDE WHERE FS_RESULT GT 50
Esta línea compara el campo FS_RESULT y verifica si es mayor que 50, luego solo se generan los registros con un FS_RESULT de más de 50. A continuación se muestra el resultado de nuestro ejemplo.
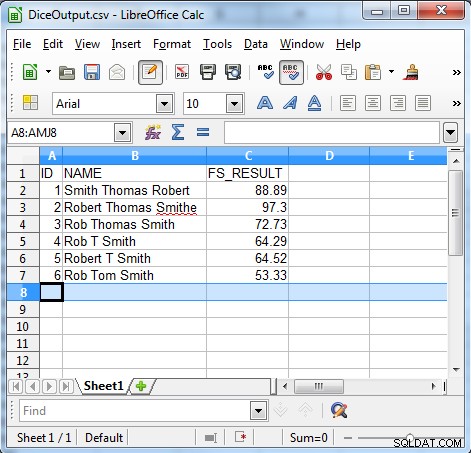
Como muestra el resultado, el algoritmo de coeficiente de dados es útil para encontrar datos inconsistentes como:
- Errores de secuencia
- Correcciones involuntarias
- Apodos
- Iniciales y apodos
- Uso impredecible de iniciales
- Localización
El algoritmo de dados es más rápido que Levenshtein, pero puede volverse menos preciso cuando hay muchos errores simples, como errores tipográficos.
3. Metáfono y 4. Soundex
los algoritmos Metaphone y Soundex comparan palabras o frases en función de sus sonidos fonéticos. Soundex hace esto leyendo la palabra o frase y observando los caracteres individuales, mientras que Metaphone observa tanto los caracteres individuales como los grupos de caracteres. Luego, ambos dan códigos basados en la ortografía y la pronunciación de la palabra.
El siguiente script de SortCL demuestra las funciones de búsqueda de Soundex y Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
En cada caso, hay tres partes que deben usarse para darnos el resultado deseado.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
La línea llama a la función y almacena el resultado en el campo RESULTADO. Ambas funciones toman dos parámetros de entrada:
- El campo para ejecutar la búsqueda aproximada (NOMBRE en nuestro ejemplo)
- La xtring con la que se comparará el campo de entrada ("John" en nuestro ejemplo)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Esta línea compara los campos SE_RESULT y MP_RESULT, y verifica y devuelve la fila si alguno es mayor que 0.
Soundex devuelve 100 para una coincidencia o 0 si no es una coincidencia. Metaphone tiene resultados más específicos y devuelve 100 para una coincidencia fuerte, 66 para una coincidencia normal y 33 para una coincidencia menor.
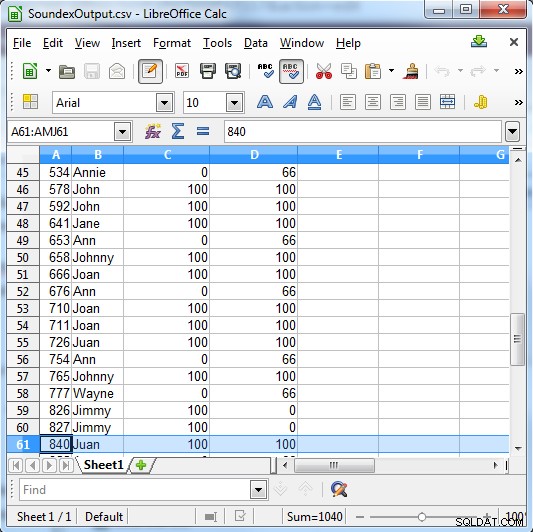
Columna C muestra los resultados de Soundex. COLUMNA D muestra los resultados de Metaphone
Como muestra el resultado, este tipo de búsqueda es útil para encontrar:
- Errores fonéticos
Envíe sus comentarios sobre este artículo a continuación y, si está interesado en usar estas funciones, comuníquese con su representante de IRI. Consulte nuestro próximo artículo sobre el uso de estos algoritmos en el asistente de consolidación (calidad) de datos de IRI Workbench.