Puede pensar que el mantenimiento de la base de datos no es asunto suyo. Pero si diseña sus modelos de manera proactiva, obtiene bases de datos que facilitan la vida de quienes tienen que mantenerlas.
Un buen diseño de base de datos requiere proactividad, una cualidad muy apreciada en cualquier entorno de trabajo. En caso de que no esté familiarizado con el término, la proactividad es la capacidad de anticipar problemas y tener soluciones listas cuando ocurren, o mejor aún, planificar y actuar para que los problemas no ocurran en primer lugar.
Los empleadores entienden que la proactividad de sus empleados o contratistas equivale a ahorro de costos. Por eso lo valoran y por eso animan a la gente a practicarlo.
En su rol como modelador de datos, la mejor manera de demostrar proactividad es diseñar modelos que anticipen y eviten los problemas que afectan de forma rutinaria al mantenimiento de la base de datos. O, al menos, que simplifiquen sustancialmente la solución a esos problemas.
Incluso si no es responsable del mantenimiento de la base de datos, el modelado para facilitar el mantenimiento de la base de datos ofrece muchos beneficios. Por ejemplo, evita que lo llamen en cualquier momento para resolver emergencias de datos que le quitan un tiempo valioso que podría estar dedicando a las tareas de diseño o modelado que tanto disfruta.
Facilitando la vida de los informáticos
Al diseñar nuestras bases de datos, debemos pensar más allá de la entrega de un DER y la generación de scripts de actualización. Una vez que una base de datos entra en producción, los ingenieros de mantenimiento tienen que lidiar con todo tipo de problemas potenciales, y parte de nuestra tarea como modeladores de bases de datos es minimizar las posibilidades de que ocurran esos problemas.
Comencemos analizando lo que significa crear un buen diseño de base de datos y cómo se relaciona esa actividad con las tareas regulares de mantenimiento de la base de datos.
¿Qué es el modelado de datos?
El modelado de datos es la tarea de crear una representación abstracta, generalmente gráfica, de un depósito de información. El objetivo del modelado de datos es exponer los atributos y las relaciones entre las entidades cuyos datos se almacenan en el repositorio.
Los modelos de datos se construyen en torno a las necesidades de un problema empresarial. Las reglas y los requisitos se definen de antemano a través de los aportes de los expertos comerciales para que puedan incorporarse al diseño de un nuevo depósito de datos o adaptarse en la iteración de uno existente.
Idealmente, los modelos de datos son documentos vivos que evolucionan con las cambiantes necesidades comerciales. Desempeñan un papel importante en el apoyo a las decisiones empresariales y en la planificación de la arquitectura y la estrategia de los sistemas. Los modelos de datos deben mantenerse sincronizados con las bases de datos que representan para que sean útiles para las rutinas de mantenimiento de esas bases de datos.
Desafíos comunes de mantenimiento de bases de datos
El mantenimiento de una base de datos requiere un seguimiento constante, automatizado o no, para garantizar que no pierda sus virtudes. Las mejores prácticas de mantenimiento de bases de datos garantizan que las bases de datos siempre mantengan su:
- Integridad y calidad de la información
- Rendimiento
- Disponibilidad
- Escalabilidad
- Adaptabilidad a los cambios
- Trazabilidad
- Seguridad
Hay muchos consejos de modelado de datos disponibles para ayudarlo a crear un buen diseño de base de datos en todo momento. Los que se analizan a continuación tienen como objetivo específico garantizar o facilitar el mantenimiento de las cualidades de la base de datos mencionadas anteriormente.
Integridad y Calidad de la Información
Un objetivo fundamental de las mejores prácticas de mantenimiento de bases de datos es garantizar que la información en la base de datos mantenga su integridad. Esto es fundamental para que los usuarios mantengan su fe en la información.
Hay dos tipos de integridad:integridad física e integridad lógica .
Integridad Física
El mantenimiento de la integridad física de una base de datos se realiza protegiendo la información de factores externos, como fallas de hardware o energía. El enfoque más común y ampliamente aceptado es a través de una estrategia de respaldo adecuada que permita la recuperación de una base de datos en un tiempo razonable si una catástrofe la destruye.
Para los DBA y los administradores de servidores que gestionan el almacenamiento de bases de datos, es útil saber si las bases de datos se pueden particionar en secciones con diferentes frecuencias de actualización. Esto les permite optimizar el uso del almacenamiento y los planes de copia de seguridad.
Los modelos de datos pueden reflejar esa partición identificando áreas de diferente "temperatura" de datos y agrupando entidades en esas áreas. “Temperatura” se refiere a la frecuencia con la que las tablas reciben nueva información. Las tablas que se actualizan con mucha frecuencia son las "más populares"; aquellos que nunca o rara vez se actualizan son los "más fríos".

Modelo de datos de un sistema de comercio electrónico que diferencia datos calientes, tibios y fríos.
Un DBA o administrador del sistema puede usar esta agrupación lógica para particionar los archivos de la base de datos y crear diferentes planes de copia de seguridad para cada partición.
Integridad lógica
Mantener la integridad lógica de una base de datos es esencial para la confiabilidad y utilidad de la información que entrega. Si una base de datos carece de integridad lógica, las aplicaciones que la utilizan tarde o temprano revelan inconsistencias en los datos. Ante estas inconsistencias, los usuarios desconfían de la información y simplemente buscan fuentes de datos más confiables.
Entre las tareas de mantenimiento de la base de datos, mantener la integridad lógica de la información es una extensión de la tarea de modelado de la base de datos, solo que comienza después de que la base de datos se pone en producción y continúa a lo largo de su vida útil. La parte más crítica de esta área de mantenimiento es adaptarse a los cambios.
Gestión de cambios
Los cambios en las reglas o requisitos comerciales son una amenaza constante para la integridad lógica de las bases de datos. Puede sentirse satisfecho con el modelo de datos que ha construido, sabiendo que está perfectamente adaptado al negocio, que responde con la información correcta a cualquier consulta y que deja fuera cualquier anomalía de inserción, actualización o eliminación. ¡Disfruta de este momento de satisfacción, porque dura poco!
El mantenimiento de una base de datos implica enfrentarse a la necesidad de realizar cambios en el modelo a diario. Te obliga a agregar nuevos objetos o alterar los existentes, modificar la cardinalidad de las relaciones, redefinir las claves primarias, cambiar los tipos de datos y hacer otras cosas que nos hacen temblar a los modeladores.
Los cambios suceden todo el tiempo. Puede ser que algún requisito se haya explicado mal desde el principio, que hayan surgido nuevos requisitos o que haya introducido involuntariamente alguna falla en su modelo (después de todo, los modeladores de datos somos humanos).
Sus modelos deben ser fáciles de modificar cuando surja la necesidad de cambios. Es fundamental utilizar una herramienta de diseño de bases de datos para el modelado que le permita crear versiones de sus modelos, generar scripts para migrar una base de datos de una versión a otra y documentar adecuadamente cada decisión de diseño.
Sin estas herramientas, cada cambio que realice en su diseño crea riesgos de integridad que salen a la luz en los momentos más inoportunos. Vertabelo te brinda toda esta funcionalidad y se encarga de mantener el historial de versiones de un modelo sin que tengas que pensarlo.
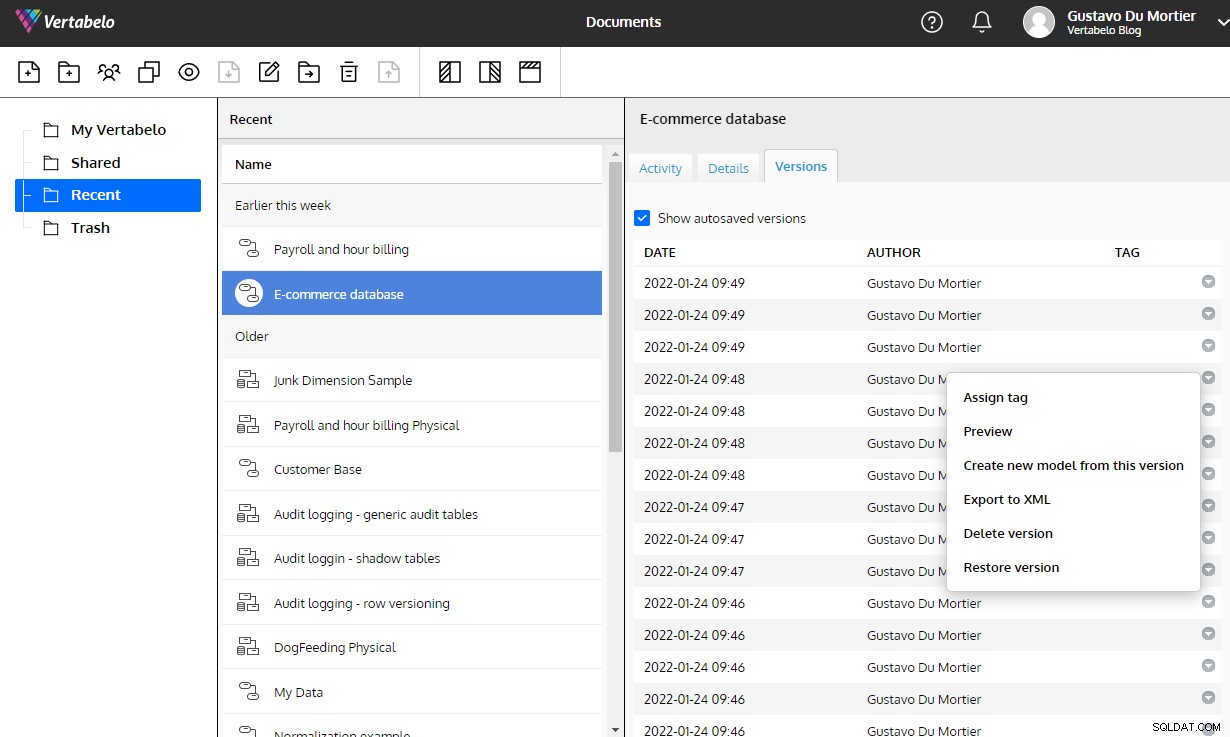
El control de versiones automático integrado en Vertabelo es de gran ayuda para mantener los cambios en un modelo de datos.
La gestión de cambios y el control de versiones también son factores cruciales para incorporar actividades de modelado de datos en el ciclo de vida del desarrollo de software.
Refactorización
Cuando aplica cambios a una base de datos en uso, debe estar 100% seguro de que no se pierde información y que su integridad no se ve afectada como consecuencia de los cambios. Para hacer esto, puede usar técnicas de refactorización. Normalmente se aplican cuando se quiere mejorar un diseño sin afectar su semántica, pero también se pueden utilizar para corregir errores de diseño o adaptar un modelo a nuevos requisitos.
Hay un gran número de técnicas de refactorización. Por lo general, se emplean para dar nueva vida a las bases de datos heredadas, y existen procedimientos de libros de texto que garantizan que los cambios no dañen la información existente. Se han escrito libros enteros al respecto; Te recomiendo que los leas.
Pero para resumir, podemos agrupar las técnicas de refactorización en las siguientes categorías:
- Calidad de los datos: Hacer cambios que aseguren la consistencia y coherencia de los datos. Los ejemplos incluyen agregar una tabla de búsqueda y migrar a ella datos repetidos en otra tabla y agregar una restricción en una columna.
- Estructurales: Realizar cambios en las estructuras de las tablas que no alteren la semántica del modelo. Los ejemplos incluyen combinar dos columnas en una, agregar una clave sustituta y dividir una columna en dos.
- Integridad referencial: Aplicar cambios para garantizar que exista una fila a la que se hace referencia dentro de una tabla relacionada o que se pueda eliminar una fila sin referencia. Los ejemplos incluyen agregar una restricción de clave externa en una columna y agregar una restricción de valor no nulo a una tabla.
- Arquitectónico: Realización de cambios destinados a mejorar la interacción de las aplicaciones con la base de datos. Los ejemplos incluyen la creación de un índice, hacer que una tabla sea de solo lectura y encapsular una o más tablas en una vista.
No se consideran técnicas de refactorización las técnicas que modifican la semántica del modelo, así como aquellas que no alteran en modo alguno el modelo de datos. Estos incluyen insertar filas en una tabla, agregar una nueva columna, crear una nueva tabla o vista y actualizar los datos en una tabla.
Mantener la calidad de la información
La calidad de la información en una base de datos es el grado en que los datos cumplen con las expectativas de precisión, validez, integridad y consistencia de la organización. Mantener la calidad de los datos a lo largo del ciclo de vida de una base de datos es vital para que sus usuarios tomen decisiones correctas e informadas utilizando los datos que contiene.
Su responsabilidad como modelador de datos es garantizar que sus modelos mantengan la calidad de la información en el nivel más alto posible. Para hacer esto:
- El diseño debe seguir al menos la tercera forma normal para que no se produzcan anomalías de inserción, actualización o eliminación. Esta consideración se aplica principalmente a las bases de datos para uso transaccional, donde los datos se agregan, actualizan y eliminan periódicamente. No se aplica estrictamente en las bases de datos para uso analítico (es decir, almacenes de datos), ya que la actualización y eliminación de datos rara vez se realizan, si es que se realizan alguna vez.
- Los tipos de datos de cada campo en cada tabla deben ser apropiados para el atributo que representan en el modelo lógico. Esto va más allá de definir correctamente si un campo es de tipo de datos numérico, de fecha o alfanumérico. También es importante definir correctamente el rango y la precisión de los valores que admite cada campo. Un ejemplo:un atributo de tipo Fecha implementado en una base de datos como un campo de Fecha/Hora puede causar problemas en las consultas, ya que un valor almacenado con su parte de tiempo distinta de cero puede quedar fuera del alcance de una consulta que utiliza un rango de fechas.
- Las dimensiones y los hechos que definen la estructura de un almacén de datos deben alinearse con las necesidades del negocio. Al diseñar un almacén de datos, las dimensiones y los hechos del modelo deben definirse correctamente desde el principio. Hacer modificaciones una vez que la base de datos está operativa tiene un costo de mantenimiento muy alto.
Gestión del crecimiento
Otro desafío importante en el mantenimiento de una base de datos es evitar que su crecimiento alcance el límite de capacidad de almacenamiento de forma inesperada. Para ayudar con la administración del espacio de almacenamiento, puede aplicar el mismo principio que se usa en los procedimientos de copia de seguridad:agrupe las tablas en su modelo de acuerdo con la velocidad a la que crecen.
Una división en dos áreas suele ser suficiente. Coloque las tablas con frecuentes adiciones de filas en un área, aquellas en las que rara vez se insertan filas en otra. Tener el modelo sectorizado de esta manera permite a los administradores de almacenamiento particionar los archivos de la base de datos de acuerdo con la tasa de crecimiento de cada área. Pueden distribuir las particiones entre diferentes soportes de almacenamiento con distintas capacidades o posibilidades de crecimiento.
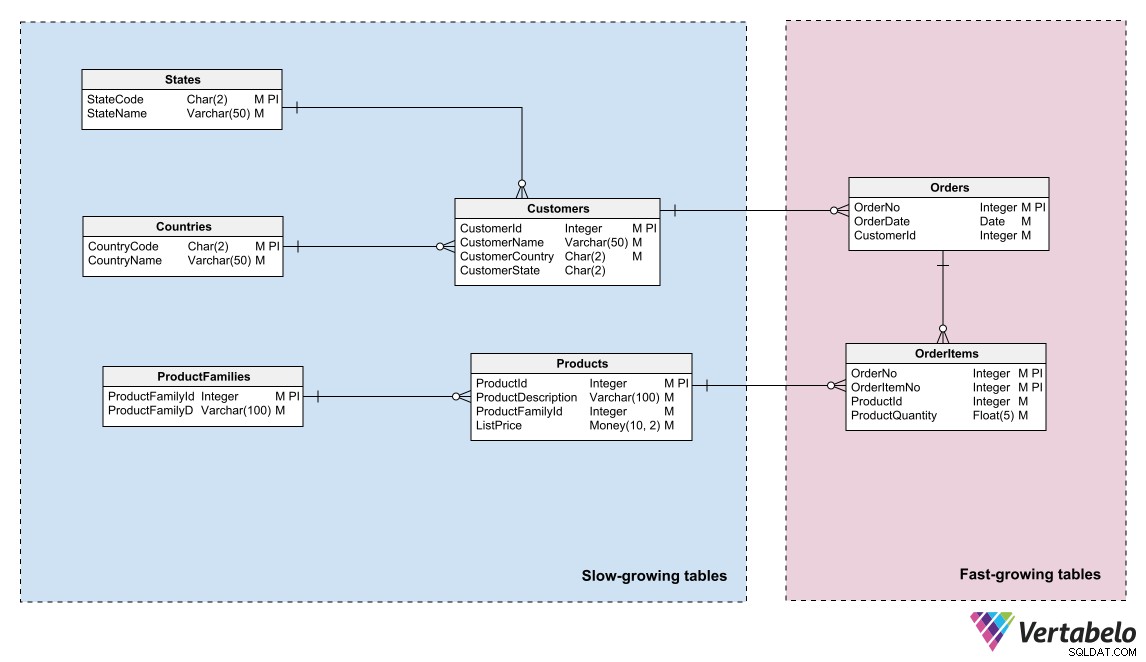
Una agrupación de tablas por su tasa de crecimiento ayuda a determinar los requisitos de almacenamiento y administrar su crecimiento.
Registro
Creamos un modelo de datos esperando que proporcione la información tal como está en el momento de la consulta. Sin embargo, tendemos a pasar por alto la necesidad de una base de datos para recordar todo lo que sucedió en el pasado a menos que los usuarios lo requieran específicamente.
Parte del mantenimiento de una base de datos es saber cómo, cuándo, por qué y quién modificó un dato en particular. Esto puede ser para cosas como averiguar cuándo cambió el precio de un producto o revisar los cambios en el registro médico de un paciente en un hospital. El registro se puede utilizar incluso para corregir errores de usuario o de aplicaciones, ya que le permite revertir el estado de la información a un punto en el pasado sin necesidad de recurrir a complicados procedimientos de restauración de copias de seguridad.
Nuevamente, incluso si los usuarios no lo necesitan explícitamente, considerar la necesidad de un registro proactivo es un medio muy valioso para facilitar el mantenimiento de la base de datos y demostrar su capacidad para anticipar problemas. Tener datos de registro permite respuestas inmediatas cuando alguien necesita revisar información histórica.
Existen diferentes estrategias para que un modelo de base de datos admita el registro, todas las cuales agregan complejidad al modelo. Un enfoque se denomina registro en el lugar, que agrega columnas a cada tabla para registrar la información de la versión. Esta es una opción simple que no implica la creación de esquemas separados o tablas específicas de registro. Sin embargo, afecta el diseño del modelo porque las claves primarias originales de las tablas ya no son válidas como claves primarias:sus valores se repiten en filas que representan diferentes versiones de los mismos datos.
Otra opción para mantener la información de registro es usar tablas de sombra. Las tablas de sombra son réplicas de las tablas del modelo con la adición de columnas para registrar datos de registro. Esta estrategia no requiere modificar las tablas en el modelo original, pero debe recordar actualizar las tablas sombra correspondientes cuando cambie su modelo de datos.
Otra estrategia más es emplear un subesquema de tablas genéricas que registren cada inserción, eliminación o modificación de cualquier otra tabla.
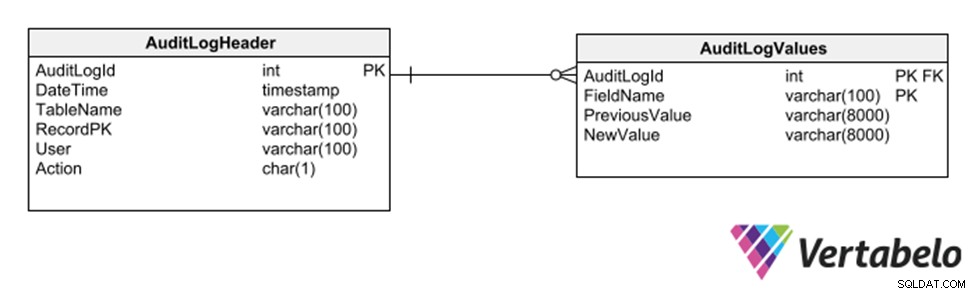
Tablas genéricas para mantener un registro de auditoría de una base de datos.
Esta estrategia tiene la ventaja de que no requiere modificaciones al modelo para registrar una pista de auditoría. Sin embargo, dado que utiliza columnas genéricas del tipo varchar, limita los tipos de datos que se pueden registrar en el registro de seguimiento.
Mantenimiento del rendimiento y creación de índices
Prácticamente cualquier base de datos tiene un buen rendimiento cuando recién se está comenzando a utilizar y sus tablas contienen solo unas pocas filas. Pero tan pronto como las aplicaciones comienzan a llenarlo con datos, el rendimiento puede degradarse muy rápidamente si no se toman precauciones al diseñar el modelo. Cuando esto sucede, los DBA y los administradores de sistemas lo llaman para que los ayude a resolver los problemas de rendimiento.
La creación/sugerencia automática de índices en bases de datos de producción es una herramienta útil para resolver problemas de rendimiento “en el calor del momento”. Los motores de base de datos pueden analizar las actividades de la base de datos para ver qué operaciones toman más tiempo y dónde hay oportunidades para acelerar mediante la creación de índices.
Sin embargo, es mucho mejor ser proactivo y anticiparse a la situación definiendo índices como parte del modelo de datos. Esto reduce en gran medida los esfuerzos de mantenimiento para mejorar el rendimiento de la base de datos. Si no está familiarizado con los beneficios de los índices de bases de datos, le sugiero que lea todo sobre los índices, comenzando con los conceptos básicos.
Hay reglas prácticas que brindan suficiente orientación para crear los índices más importantes para consultas eficientes. El primero es generar índices para la clave principal de cada tabla. Prácticamente todos los RDBMS generan un índice para cada clave principal automáticamente, por lo que puede olvidarse de esta regla.
Otra regla es generar índices para claves alternativas de una tabla, particularmente en tablas para las que se crea una clave sustituta. Si una tabla tiene una clave natural que no se usa como clave principal, es muy probable que las consultas para unir esa tabla con otras lo hagan con la clave natural, no con la sustituta. Esas consultas no funcionan bien a menos que cree un índice en la clave natural.
La siguiente regla general para los índices es generarlos para todos los campos que son claves externas. Estos campos son excelentes candidatos para establecer uniones con otras tablas. Si se incluyen en los índices, los analizadores de consultas los utilizan para acelerar la ejecución y mejorar el rendimiento de la base de datos.
Por último, es una buena idea utilizar una herramienta de creación de perfiles en una base de datos provisional o de control de calidad durante las pruebas de rendimiento para detectar cualquier oportunidad de creación de índices que no sea obvia. La incorporación de los índices sugeridos por las herramientas de creación de perfiles en el modelo de datos es extremadamente útil para lograr y mantener el rendimiento de la base de datos una vez que está en producción.
Seguridad
En su papel como modelador de datos, puede ayudar a mantener la seguridad de la base de datos proporcionando una base sólida y segura en la que almacenar datos para la autenticación de usuarios. Tenga en cuenta que esta información es muy confidencial y no debe estar expuesta a ciberataques.
Para que su diseño simplifique el mantenimiento de la seguridad de la base de datos, siga las mejores prácticas para almacenar datos de autenticación, la principal de las cuales es no almacenar contraseñas en la base de datos, incluso en forma cifrada. Almacenar solo su hash en lugar de la contraseña para cada usuario permite que una aplicación autentique el inicio de sesión de un usuario sin crear ningún riesgo de exposición de la contraseña.
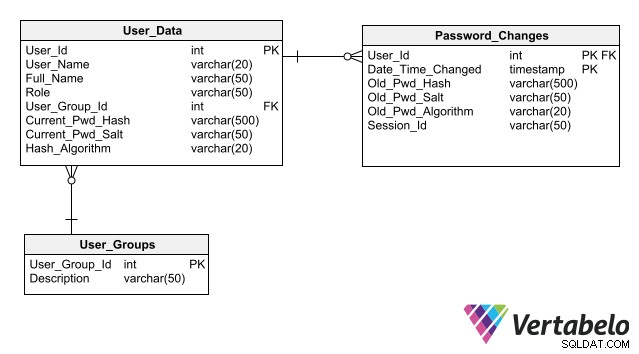
Un esquema completo para la autenticación de usuarios que incluye columnas para almacenar hashes de contraseñas.
Visión para el futuro
Por lo tanto, cree sus modelos para facilitar el mantenimiento de la base de datos con buenos diseños de base de datos teniendo en cuenta los consejos anteriores. Con más modelos de datos mantenibles, su trabajo se ve mejor y gana la apreciación de los DBA, ingenieros de mantenimiento y administradores de sistemas.
También inviertes en tranquilidad. La creación de bases de datos fáciles de mantener significa que puede pasar sus horas de trabajo diseñando nuevos modelos de datos, en lugar de correr parcheando bases de datos que no entregan la información correcta a tiempo.