El vacío es una de las funciones más importantes para recuperar tuplas eliminadas en tablas e índices. Sin vacío, las tablas y los índices continuarían creciendo en tamaño sin límites. Esta publicación de blog describe la opción PARALLEL para el comando VACUUM, que se introdujo recientemente en PostgreSQL13.
Fases de procesamiento al vacío
Antes de discutir la nueva opción en profundidad, repasemos los detalles de cómo funciona el vacío.
El vacío (sin opción FULL) consta de cinco fases. Por ejemplo, para una tabla con dos índices, funciona de la siguiente manera:
- Fase de exploración del montón
- Explore la tabla desde arriba y recolecte tuplas basura en la memoria.
- Fase de vacío de índice
- Aspire ambos índices uno por uno.
- Fase de vacío del montón
- Aspire el montón (tabla).
- Fase de limpieza del índice
- Limpie ambos índices uno por uno.
- Fase de truncamiento del montón
- Trunca las páginas vacías al final de la tabla.
En la fase de exploración del montón, la aspiradora puede usar el mapa de visibilidad para omitir el procesamiento de páginas que se sabe que no tienen basura, mientras que tanto en la fase de aspiradora del índice como en la de limpieza del índice, dependiendo de los métodos de acceso al índice, una exploración del índice completo es obligatorio.
Por ejemplo, los índices btree, el tipo de índice más popular, requieren un escaneo de índice completo para eliminar las tuplas basura y realizar una limpieza del índice. Dado que el vacío siempre se realiza mediante un solo proceso, los índices se procesan uno por uno. El mayor tiempo de ejecución del vacío, especialmente en una mesa grande, suele molestar a los usuarios.
Opción PARALELO
Para abordar este problema, propuse un parche para paralelizar el vacío en 2016. Después de un largo proceso de revisión y muchas reformas, se introdujo la opción PARALLEL en PostgreSQL 13. Con esta opción, el vacío puede realizar la fase de vacío del índice y la fase de limpieza del índice con trabajadores paralelos. Los trabajadores de vacío en paralelo se lanzan antes de entrar en la fase de vacío de índice o en la fase de limpieza de índice y salen al final de la fase. Un trabajador individual se asigna a un índice. El vacío paralelo siempre está deshabilitado en autovacío.
La opción PARALLEL sin una opción de argumento de número entero calculará automáticamente el grado paralelo en función del número de índices en la tabla.
VACUUM (PARALLEL) tbl;
Dado que el proceso líder siempre procesa un índice, la cantidad máxima de trabajadores paralelos será (la cantidad de índices en la tabla - 1), que se limita aún más a max_parallel_maintenance_workers. El índice de destino debe ser mayor o igual que min_parallel_index_scan_size.
La opción PARALELO nos permite especificar el grado de paralelo pasando un valor entero distinto de cero. El siguiente ejemplo utiliza tres trabajadores, para un total de cuatro procesos en paralelo.
VACUUM (PARALLEL 3) tbl;
La opción PARALELO está activada de forma predeterminada; para deshabilitar el vacío paralelo, establezca max_parallel_maintenance_workers en 0 o especifique PARALLEL 0 .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Mirando la salida VACUUM VERBOSE, podemos ver que un trabajador está procesando el índice.
La información impresa como "por trabajador paralelo" es reportada por el trabajador.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Métodos de acceso a índices versus grado de paralelismo
El vacío no siempre realiza necesariamente la fase de vacío de índice y la fase de limpieza de índice en paralelo. Si el tamaño del índice es pequeño, o si se sabe que el proceso se puede completar rápidamente, el costo de lanzar y administrar trabajadores paralelos para la paralelización genera una sobrecarga. Según los métodos de acceso al índice y su tamaño, es mejor no realizar estas fases mediante un proceso de trabajo de vacío paralelo.
Por ejemplo, al aspirar un índice btree lo suficientemente grande, la fase de vacío del índice la puede realizar un trabajador de vacío paralelo porque siempre requiere un escaneo de índice completo, mientras que la fase de limpieza del índice la realiza un trabajador de vacío paralelo si el índice no se realiza el vacío (es decir, no hay basura en la mesa). Esto se debe a que lo que requieren los índices btree en la fase de limpieza del índice es recopilar las estadísticas del índice, que también se recopilan durante la fase de vacío del índice. Por otro lado, los índices hash no siempre requieren un escaneo en el índice en la fase de limpieza del índice.
Para admitir diferentes tipos de estrategias de vacío de índices, los desarrolladores de métodos de acceso a índices pueden especificar estos comportamientos configurando indicadores en amparallelvacuumoptions campo del IndexAmRoutine estructura. Las banderas disponibles son las siguientes:
- VACUUM_OPTION_NO_PARALLEL (predeterminado)
- el vacío paralelo está deshabilitado en ambas fases.
- VACUUM_OPTION_PARALLEL_BULKDEL
- la fase de vacío de índice se puede realizar en paralelo.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- la fase de limpieza del índice se puede realizar en paralelo si la fase de vacío del índice aún no se ha realizado.
- VACUUM_OPTION_PARALLEL_CLEANUP
- la fase de limpieza del índice se puede realizar en paralelo incluso si la fase de vacío del índice ya ha procesado el índice.
La siguiente tabla muestra cómo PostgreSQL incorporado de índice AM admite el vacío paralelo.
| nbtree | hash | ginebra | esencial | spgist | brin | floración | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Consulte 'src/include/command/vacuum.h' para obtener más detalles.
Verificación de rendimiento
He evaluado el rendimiento del vacío paralelo en mi computadora portátil (Core i7 2.6GHz, 16GB RAM, 512GB SSD). El tamaño de la tabla es de 6 GB y tiene ocho índices de 3 GB. La relación total es de 30 GB, que no se ajusta a la memoria RAM de la máquina. Para cada evaluación, ensucié varios porcentajes de la mesa de manera uniforme después de pasar la aspiradora, luego realicé la aspiración mientras cambiaba el grado paralelo. El siguiente gráfico muestra el tiempo de ejecución de vacío.
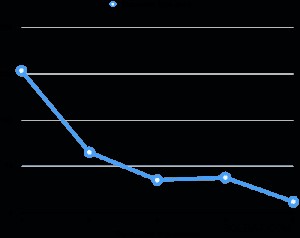
En todas las evaluaciones, el tiempo de ejecución del índice de vacío representó más del 95% del tiempo total de ejecución. Por lo tanto, la paralelización de la fase de vacío de índice ayudó a reducir mucho el tiempo de ejecución de vacío.
Gracias
Un agradecimiento especial a Amit Kapila por revisar, brindar consejos y comprometer esta función en PostgreSQL 13. Agradezco a todos los desarrolladores que participaron en esta función por revisar, probar y debatir.