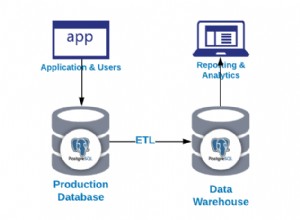
PostgreSQL es una de las bases de datos que se puede implementar a través de ClusterControl, junto con MySQL, MariaDB y MongoDB. ClusterControl no solo simplifica la implementación del clúster de la base de datos, sino que también tiene una función de escalabilidad en caso de que su aplicación crezca y requiera esa funcionalidad.
Al ampliar su base de datos, su aplicación funcionará mucho mejor y sin problemas en caso de que aumente la carga de la aplicación o el tráfico. En esta publicación de blog, revisaremos los pasos sobre cómo realizar la implementación y la ampliación de PostgreSQL v13 con ClusterControl 1.8.2.
Implementación de interfaz de usuario (UI)
Hay dos formas de implementación en ClusterControl, la interfaz de usuario web (UI) y la interfaz de línea de comandos (CLI). El usuario tiene la libertad de elegir cualquiera de las opciones de despliegue en función de su gusto y necesidad. Ambas opciones son fáciles de seguir y están bien documentadas en nuestra documentación. En esta sección, pasaremos por el proceso de implementación utilizando la primera opción:interfaz de usuario web.
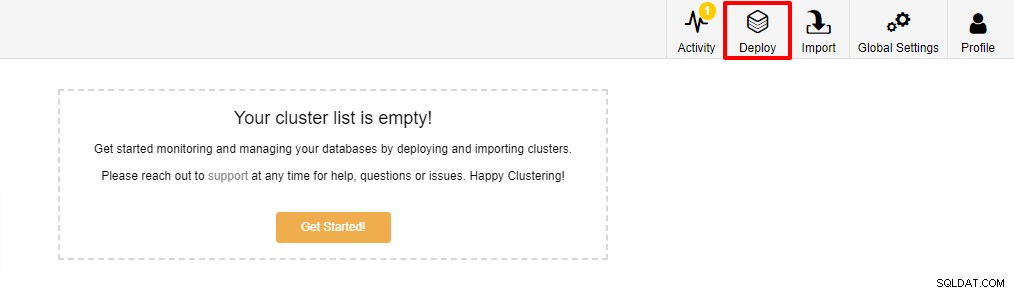
El primer paso es iniciar sesión en su ClusterControl y hacer clic en Implementar:
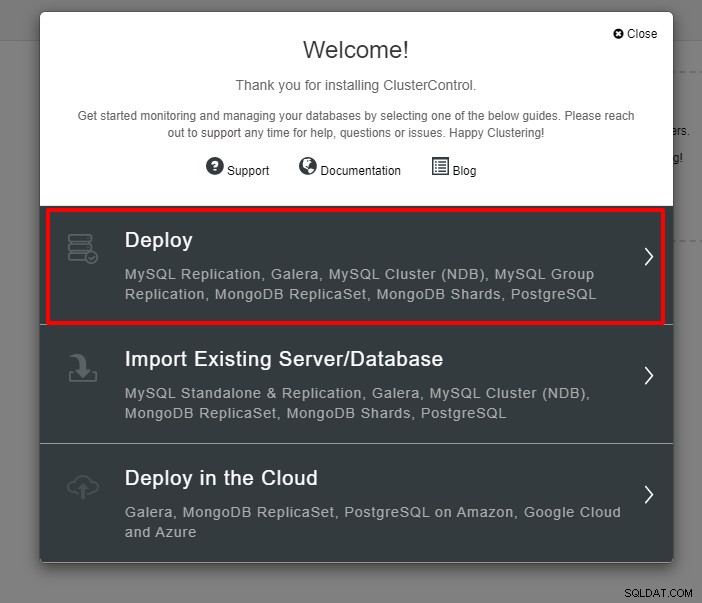
Se le presentará la siguiente captura de pantalla para el siguiente paso de la implementación , elija la pestaña PostgreSQL para continuar:
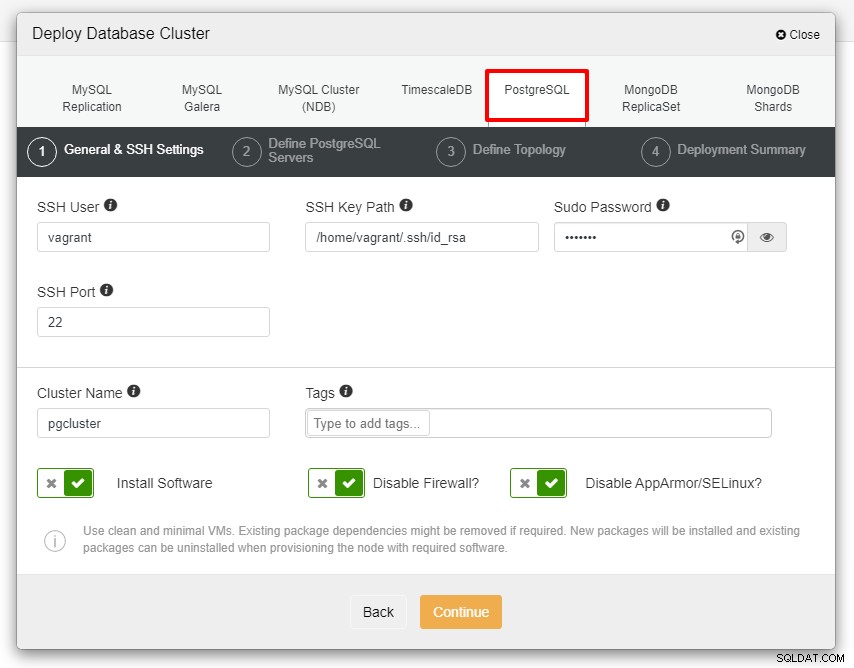
Antes de continuar, quisiera recordarles que la conexión entre el nodo ClusterControl y los nodos de bases de datos no deben tener contraseña. Antes de la implementación, todo lo que debemos hacer es generar el ssh-keygen desde el nodo ClusterControl y luego copiarlo en todos los nodos. Complete la entrada para el usuario de SSH, la contraseña de Sudo y el nombre del clúster según sus requisitos y haga clic en Continuar.
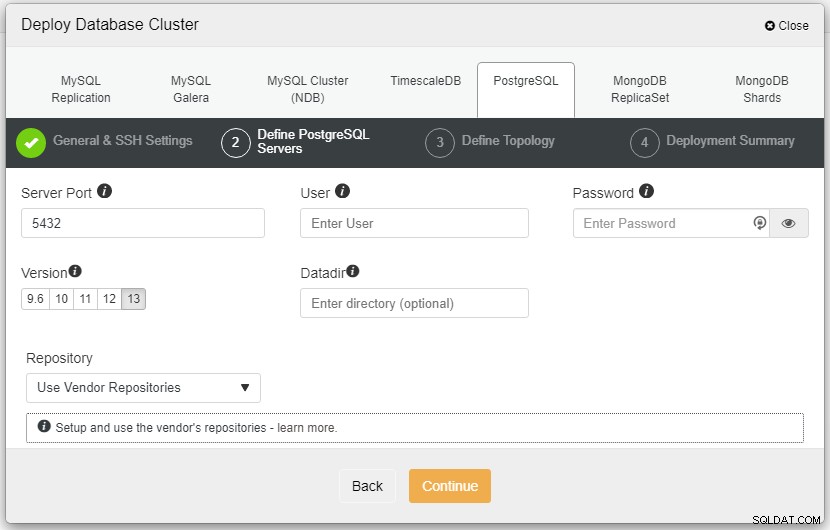
En la captura de pantalla anterior, deberá definir el puerto del servidor (en caso de que quiera usar otros), el usuario que le gustaría, así como la contraseña y asegúrese de elegir la versión 13 que desea instalar.
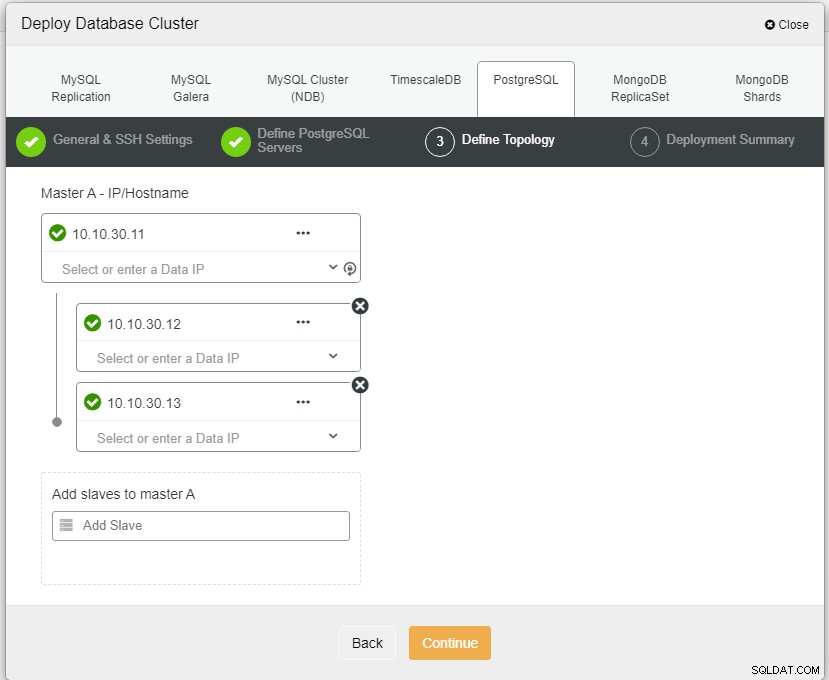 Autor de la fotoDescripción de la foto
Autor de la fotoDescripción de la fotoAquí necesitamos definir los servidores usando el nombre de host o la dirección IP, como en este caso 1 maestro y 2 esclavos. El paso final es elegir el modo de replicación para nuestro clúster.
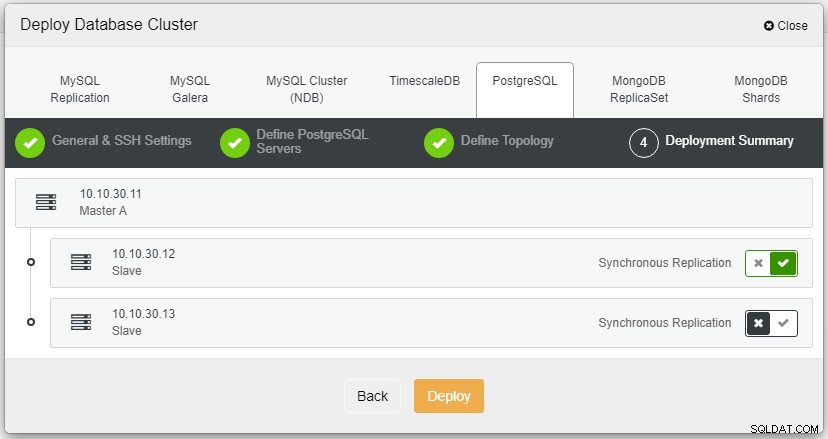
Después de hacer clic en Implementar, se iniciará el proceso de implementación y podremos monitorear el progreso en la pestaña Actividad.
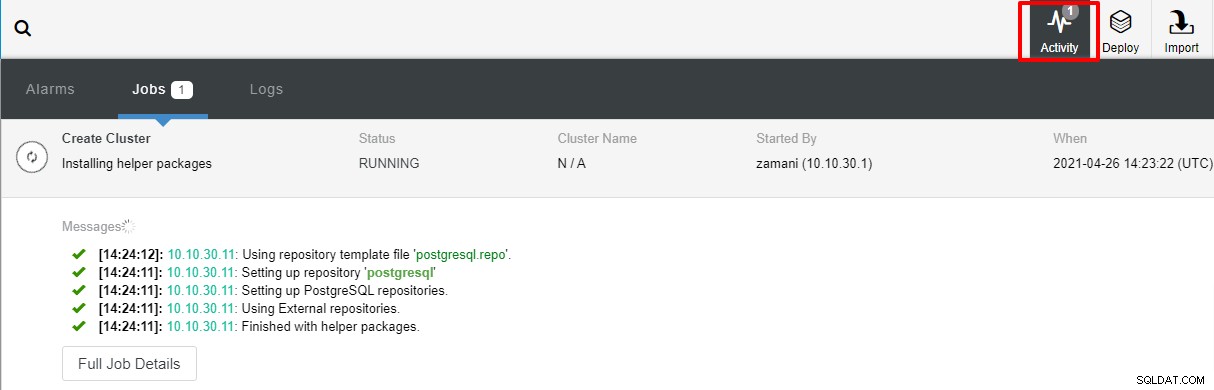
La implementación normalmente demorará un par de minutos, el rendimiento depende principalmente de la red y las especificaciones del servidor.

Ahora que tenemos PostgreSQL v13 instalado usando la GUI de ClusterControl, que es bastante sencillo .
Implementación de PostgreSQL de interfaz de línea de comandos (CLI)
De lo anterior, podemos ver que la implementación es bastante sencilla usando la interfaz de usuario web. La nota importante es que todos los nodos deben tener conexiones SSH sin contraseña antes de la implementación. En esta sección, veremos cómo realizar la implementación mediante la CLI de ClusterControl o la línea de comandos de las herramientas “s9s”.
Asumimos que ClusterControl se instaló antes de esto, comencemos generando el ssh-keygen. En el nodo ClusterControl, ejecute los siguientes comandos:
$ whoami
root
$ ssh-keygen -t rsa # generate the SSH key for the user
$ ssh-copy-id 10.10.40.11 # pg node1
$ ssh-copy-id 10.10.40.12 # pg node2
$ ssh-copy-id 10.10.40.13 # pg node3Una vez que todos los comandos anteriores se ejecutaron con éxito, podemos verificar la conexión sin contraseña usando el siguiente comando:
$ ssh 10.10.40.11 "whoami" # make sure can ssh without passwordSi el comando anterior se ejecuta con éxito, la implementación del clúster se puede iniciar desde el servidor ClusterControl usando la siguiente línea de comando:
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.40.11?master;10.10.40.12?slave;10.10.40.13?slave" --provider-version='13' --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logInmediatamente después de ejecutar el comando anterior, verá algo como esto, lo que significa que la tarea ha comenzado a ejecutarse:
El clúster se creará en 3 nodos de datos.
Verificando los parámetros del trabajo.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.12: Checking ssh/sudo with credentials ssh_cred_job_6656.
10.10.40.13: Checking ssh/sudo with credentials ssh_cred_job_6656.
…
…
This will take a few moments and the following message will be displayed once the cluster is deployed:
…
…
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.
También puede verificarlo iniciando sesión en la consola web, utilizando el nombre de usuario que ha creado. Ahora tenemos un clúster de PostgreSQL implementado con 3 nodos. Si desea obtener más información sobre el comando de implementación anterior, esta es la mejor referencia para usted.
Ampliar PostgreSQL con la interfaz de usuario de ClusterControl
PostgreSQL es una base de datos relacional y sabemos que escalar este tipo de base de datos no es fácil en comparación con una base de datos no relacional. Actualmente, la mayoría de las aplicaciones necesitan escalabilidad para brindar un mejor rendimiento y velocidad. Hay muchas formas de implementar esto dependiendo de su infraestructura y entorno.
La escalabilidad es una de las características que puede facilitar ClusterControl y se puede lograr tanto con la interfaz de usuario como con la CLI. En esta sección, veremos cómo podemos escalar horizontalmente PostgreSQL utilizando la interfaz de usuario de ClusterControl. El primer paso es iniciar sesión en su interfaz de usuario y elegir el clúster, una vez que se elige el clúster, puede hacer clic en la opción como se muestra en la siguiente captura de pantalla:
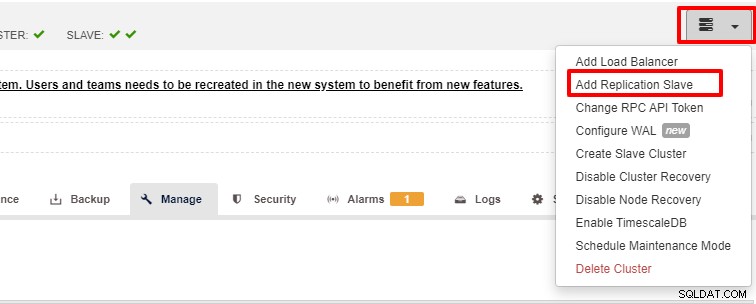
Una vez que se hizo clic en "Agregar esclavo de replicación", verá la siguiente página . Puede elegir "Agregar nuevo..." o "Importar..." dependiendo de su situación. En este ejemplo elegiremos la primera opción:
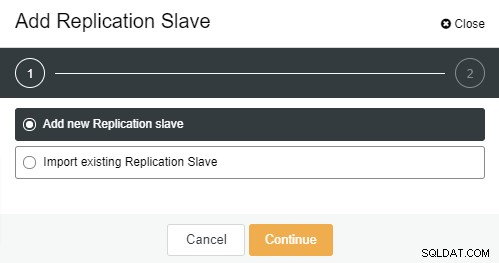
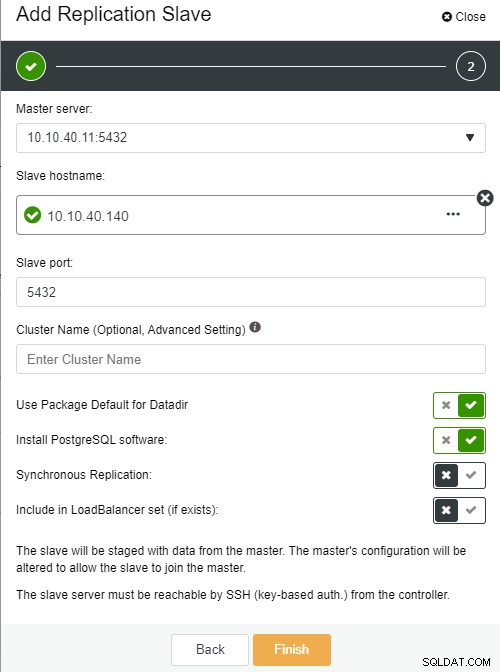
La siguiente pantalla aparecerá una vez que haga clic en ella:
 Autor de la fotoDescripción de la foto
Autor de la fotoDescripción de la foto-
Nombre de host esclavo:el nombre de host/dirección IP del nuevo esclavo o nodo
-
Puerto esclavo:el puerto PostgreSQL del esclavo, el predeterminado es 5432
-
Nombre del clúster:el nombre del clúster, puede agregarlo o dejarlo en blanco
-
Usar paquete predeterminado para Datadir:puede marcar esta opción si desea tener una ubicación diferente para Datadir
-
Instalar el software PostgreSQL:puede dejar esta opción marcada
-
Replicación síncrona:puedes elegir qué tipo de replicación quieres en esta
-
Incluir en el conjunto LoadBalancer (si existe):esta opción debe verificarse si tiene LoadBalancer configurado para el clúster
La nota clave importante aquí es que debe configurar el nuevo host esclavo para que no tenga contraseña antes de poder ejecutar esta configuración. Una vez que todo esté confirmado, podemos hacer clic en el botón "Finalizar" para completar la configuración. En este ejemplo, agregué la IP "10.10.40.140".
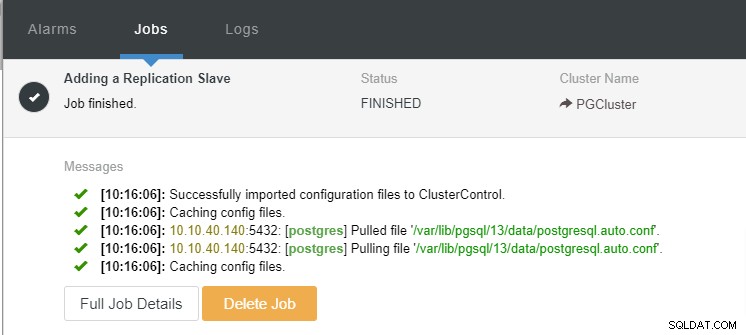
Ahora podemos monitorear la actividad del trabajo y dejar que se complete la configuración. Para confirmar la configuración, podemos ir a la pestaña "Topología" para ver el nuevo esclavo:
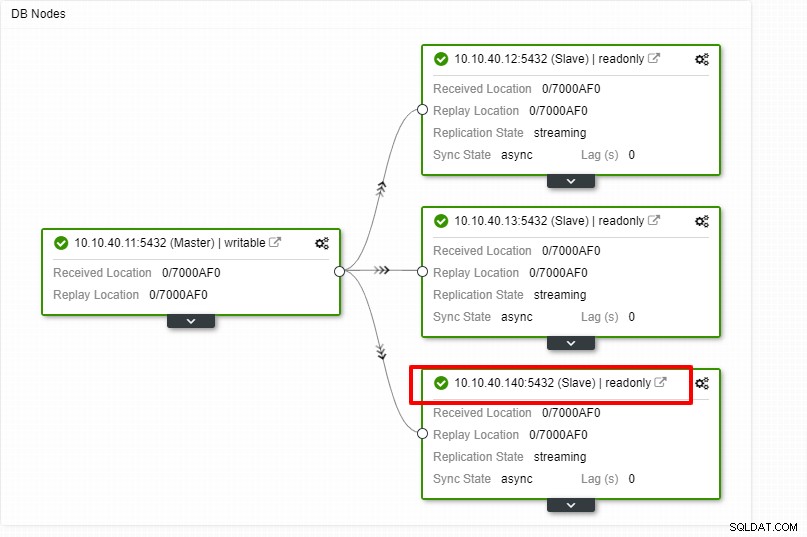
Escalamiento horizontal de PostgreSQL con CLI de ClusterControl
Agregar los nuevos nodos al clúster existente es muy simple usando la CLI. Desde el nodo del controlador, ejecuta el siguiente comando. El primer comando es identificar el clúster al que nos gustaría agregar el nuevo nodo:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED postgresql_single admin admins PGCluster All nodes are operational.En este ejemplo, podemos ver que el ID de nodo es "1" para el nombre de clúster "PGCluster". Veamos la primera opción de comando sobre cómo agregar un nuevo nodo al clúster de PostgreSQL existente:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.141?slave" --logLa abreviatura "--log" al final de la línea nos permitirá ver cuál es la tarea actual que se ejecuta después de ejecutar el comando como se indica a continuación:
Using SSH credentials from cluster.
Cluster ID is 1.
The username is 'root'.
Verifying job parameters.
Found a master candidate: 10.10.40.11:5432, adding 10.10.40.141:5432 as a slave.
Verifying job parameters.
10.10.40.11: Checking ssh/sudo with credentials ssh_cred_cluster_1_6245.
10.10.40.11:5432: Loading configuration file '/var/lib/pgsql/13/data/postgresql.conf'.
10.10.40.11:5432: wal_keep_segments is set to 0, increase this for safer replication.
…
…El siguiente comando disponible que puede usar es como el siguiente:
$ s9s cluster --add-node --cluster-id=1 --nodes="postgresql://10.10.40.142?slave" --waitAgregar nodo al clúster
\ Job 9 RUNNING [▋ ] 5% Installing packagesObserve que hay una abreviatura “--wait” en la línea y el resultado que verá se mostrará como arriba. Una vez que se completa el proceso, podemos confirmar los nuevos nodos en la pestaña "Descripción general" del clúster desde la interfaz de usuario:
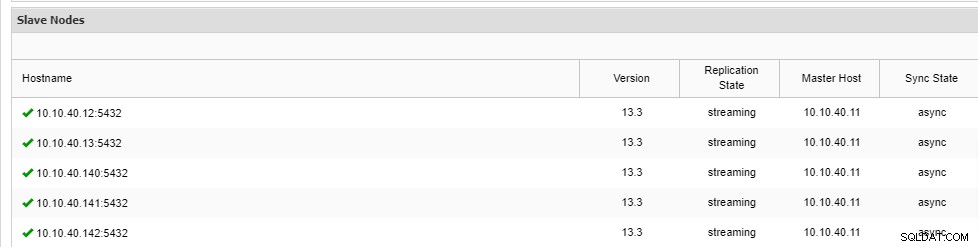
Conclusión
En esta publicación de blog, hemos revisado dos opciones para escalar PostgreSQL en ClusterControl. Como puede notar, escalar PostgreSQL es fácil con ClusterControl. ClusterControl no solo puede hacer la escalabilidad, sino que también puede lograr una configuración de alta disponibilidad para su clúster de base de datos. Funciones como HAProxy, PgBouncer y Keepalived están disponibles y listas para implementarse en su clúster siempre que sienta la necesidad de esas opciones. Con ClusterControl, su clúster de base de datos es fácil de administrar y monitorear al mismo tiempo.
Esperamos que esta publicación de blog lo guíe para escalar su configuración de PostgreSQL.