En el mundo de la tecnología de la información, la automatización no es algo nuevo para la mayoría de nosotros. De hecho, la mayoría de las organizaciones lo utilizan para diversos fines según su tipo de trabajo y sus objetivos. Por ejemplo, los analistas de datos usan la automatización para generar informes, los administradores de sistemas usan la automatización para sus tareas repetitivas, como limpiar el espacio del disco, y los desarrolladores usan la automatización para automatizar su proceso de desarrollo.
Hoy en día, hay muchas herramientas de automatización para TI disponibles y se pueden elegir, gracias a la era DevOps. ¿Cuál es la mejor herramienta? La respuesta es un "depende" predecible, ya que depende de lo que estamos tratando de lograr, así como de la configuración de nuestro entorno. Algunas de las herramientas de automatización son Terraform, Bolt, Chef, SaltStack y una muy de moda es Ansible. Ansible es un motor de TI sin agente de código abierto que puede automatizar la implementación de aplicaciones, la administración de la configuración y la orquestación de TI. Ansible se fundó en 2012 y ha sido escrito en el lenguaje más popular, Python. Utiliza un libro de jugadas para implementar toda la automatización, donde todas las configuraciones están escritas en un lenguaje legible por humanos, YAML.
En la publicación de hoy, vamos a aprender cómo usar Ansible para implementar la base de datos de Postgresql.
¿Qué hace que Ansible sea especial?
La razón por la que se usa ansible es principalmente por sus características. Esas características son:
-
Cualquier cosa se puede automatizar mediante el uso de lenguaje simple legible por humanos YAML
-
No se instalará ningún agente en la máquina remota (arquitectura sin agente)
-
La configuración se enviará desde su máquina local al servidor desde su máquina local (modelo push)
-
Desarrollado usando Python (uno de los lenguajes populares que se usan actualmente) y se puede elegir una gran cantidad de bibliotecas
-
Colección de módulos Ansible cuidadosamente seleccionados por el equipo de ingeniería de Red Had
Cómo funciona Ansible
Antes de que Ansible pueda ejecutar tareas operativas en los hosts remotos, debemos instalarlo en un host que se convertirá en el nodo controlador. En este nodo de controlador, organizaremos cualquier tarea que nos gustaría realizar en los hosts remotos, también conocidos como nodos administrados.
El nodo controlador debe tener el inventario de los nodos administrados y el software Ansible para administrarlo. Los datos requeridos para ser utilizados por Ansible, como el nombre de host o la dirección IP del nodo administrado, se colocarán dentro de este inventario. Sin un inventario adecuado, Ansible no podría realizar la automatización correctamente. Consulte aquí para obtener más información sobre el inventario.
Ansible no tiene agente y usa SSH para impulsar los cambios, lo que significa que no tenemos que instalar Ansible en todos los nodos, pero todos los nodos administrados deben tener Python y las bibliotecas de Python necesarias instaladas. Tanto el nodo del controlador como los nodos administrados deben configurarse como sin contraseña. Vale la pena mencionar que la conexión entre todos los nodos del controlador y los nodos administrados es buena y se probó correctamente.
Para esta demostración, aprovisioné 4 máquinas virtuales Centos 8 usando vagrant. Uno actuará como un nodo controlador y las otras 2 VM actuarán como los nodos de la base de datos que se implementarán. No entraremos en detalles sobre cómo instalar Ansible en esta publicación de blog, pero en caso de que desee ver la guía, no dude en visitar este enlace. Tenga en cuenta que estamos usando 3 nodos para configurar una topología de replicación de transmisión, con un nodo principal y 2 en espera. Hoy en día, muchas bases de datos de producción tienen una configuración de alta disponibilidad y una configuración de 3 nodos es común.
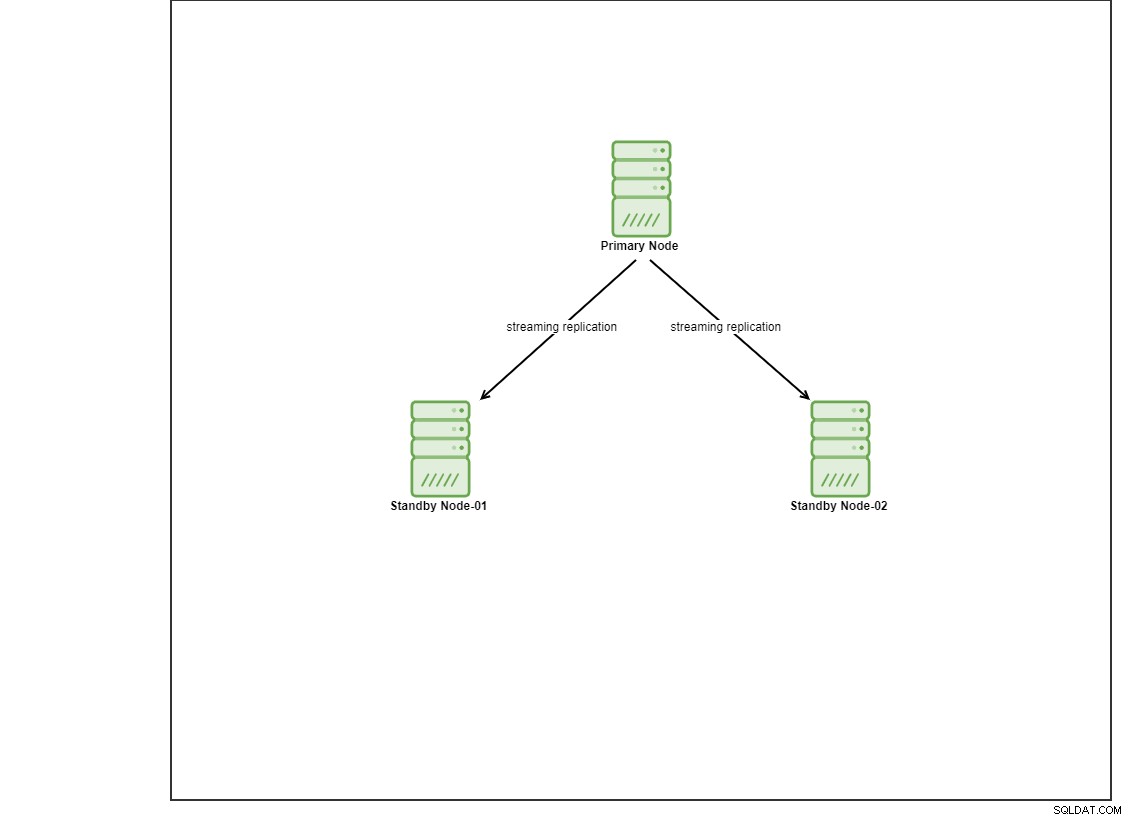
Instalación de PostgreSQL
Hay varias formas de instalar PostgreSQL usando Ansible. Hoy usaré Ansible Roles para lograr este propósito. Ansible Roles en pocas palabras es un conjunto de tareas para configurar un host para cumplir un propósito determinado, como configurar un servicio. Los roles de Ansible se definen mediante archivos YAML con una estructura de directorio predefinida disponible para descargar desde el portal de Ansible Galaxy.
Ansible Galaxy, por otro lado, es un repositorio de Ansible Roles que están disponibles para colocar directamente en sus Playbooks para optimizar sus proyectos de automatización.
Para esta demostración, he elegido los roles que ha mantenido dudefellah. Para que podamos utilizar este rol, debemos descargarlo e instalarlo en el nodo del controlador. La tarea es bastante sencilla y se puede realizar ejecutando el siguiente comando, siempre que se haya instalado Ansible en el nodo de su controlador:
$ ansible-galaxy install dudefellah.postgresqlDebería ver el siguiente resultado una vez que el rol se instaló correctamente en su nodo de controlador:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
Para que podamos instalar PostgreSQL usando esta función, hay algunos pasos que deben realizarse. Aquí viene el libro de jugadas de Ansible. Ansible Playbook es donde podemos escribir código Ansible o una colección de scripts que nos gustaría ejecutar en los nodos administrados. Ansible Playbook usa YAML y consta de una o más jugadas que se ejecutan en un orden particular. Puede definir hosts, así como un conjunto de tareas que le gustaría ejecutar en esos hosts asignados o nodos administrados.
Todas las tareas se ejecutarán como el usuario de ansible que inició sesión. Para que podamos ejecutar las tareas con un usuario diferente, incluido el "root", podemos hacer uso de Become. Echemos un vistazo a pg-play.yml a continuación:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Como puede ver, he definido los hosts como pgcluster y hago uso de Become para que Ansible ejecute las tareas con el privilegio sudo. El usuario vagabundo ya está en el grupo sudoer. También he definido el rol que instalé dudefellah.postgresql. pgcluster se ha definido en el archivo de hosts que creé. En caso de que se pregunte cómo se ve, puede echar un vistazo a continuación:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleAdemás de eso, he creado otro archivo personalizado (custom_var.yml) en el que incluí toda la configuración y configuración de PostgreSQL que me gustaría implementar. Los detalles del archivo personalizado son los siguientes:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }Para ejecutar la instalación, todo lo que tenemos que hacer es ejecutar el siguiente comando. No podrá ejecutar el comando ansible-playbook sin crear el archivo de playbook (en mi caso es pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostDespués de ejecutar este comando, ejecutará algunas tareas definidas por el rol y mostrará este mensaje si el comando se ejecutó correctamente:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12Una vez que ansible completó las tareas, inicié sesión en el esclavo (n2), detuve el servicio PostgreSQL, eliminé el contenido del directorio de datos (/var/lib/pgsql/13/data/) y ejecute el siguiente comando para iniciar la tarea de copia de seguridad:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |También podemos verificar el estado de la replicación en modo de espera usando el siguiente comando después de reiniciar el servicio de PostgreSQL:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyComo puede ver, hay mucho trabajo por hacer para que podamos configurar la replicación para PostgreSQL a pesar de que hemos automatizado algunas de las tareas. Veamos cómo se puede lograr esto con ClusterControl.
Implementación de PostgreSQL usando la GUI de ClusterControl
Ahora que sabemos cómo implementar PostgreSQL mediante Ansible, veamos cómo podemos implementar mediante ClusterControl. ClusterControl es un software de gestión y automatización para clústeres de bases de datos, incluidos MySQL, MariaDB, MongoDB y TimescaleDB. Ayuda a implementar, monitorear, administrar y escalar su clúster de base de datos. Hay dos formas de implementar la base de datos, en esta publicación de blog le mostraremos cómo implementarla mediante la interfaz gráfica de usuario (GUI), suponiendo que ya tiene instalado ClusterControl en su entorno.
El primer paso es iniciar sesión en su ClusterControl y hacer clic en Implementar:
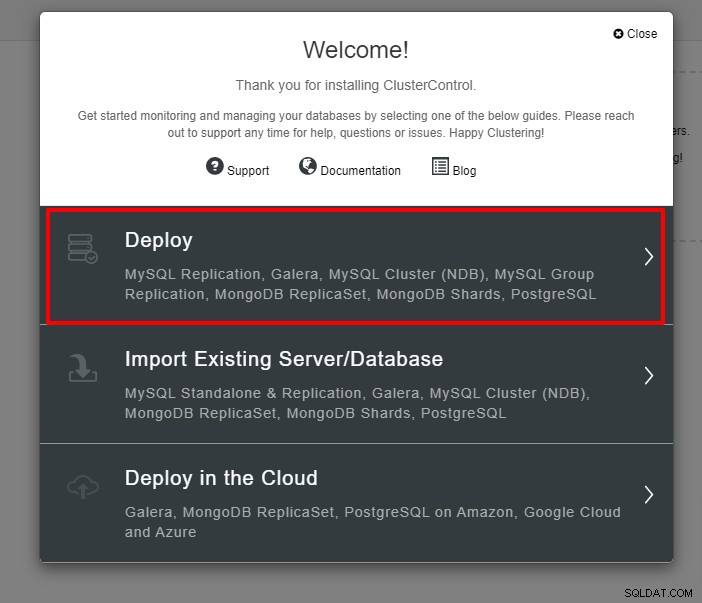
Se le presentará la siguiente captura de pantalla para el siguiente paso de la implementación , elija la pestaña PostgreSQL para continuar:
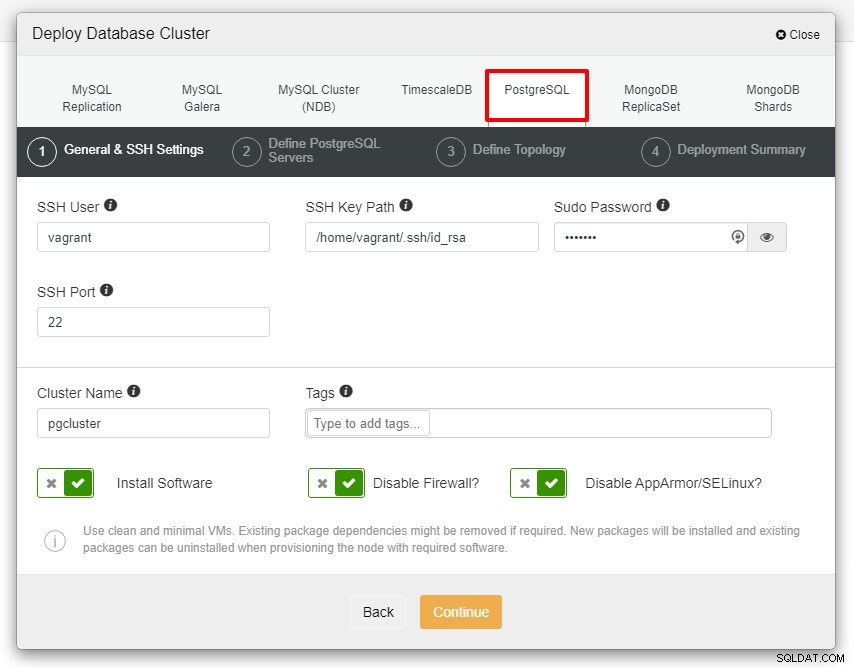
Antes de continuar, me gustaría recordarle que la conexión entre el nodo ClusterControl y los nodos de las bases de datos debe ser sin contraseña. Antes de la implementación, todo lo que debemos hacer es generar el ssh-keygen desde el nodo ClusterControl y luego copiarlo en todos los nodos. Complete la entrada para el usuario de SSH, la contraseña de Sudo y el nombre del clúster según sus requisitos y haga clic en Continuar.
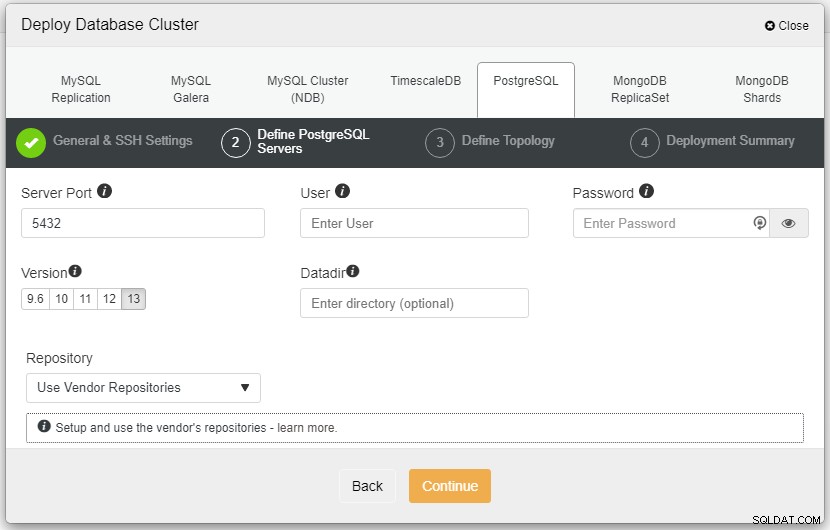
En la captura de pantalla anterior, deberá definir el puerto del servidor (en caso de que desee utilizar otros), el usuario que desea, así como la contraseña y la versión que desea para instalar.
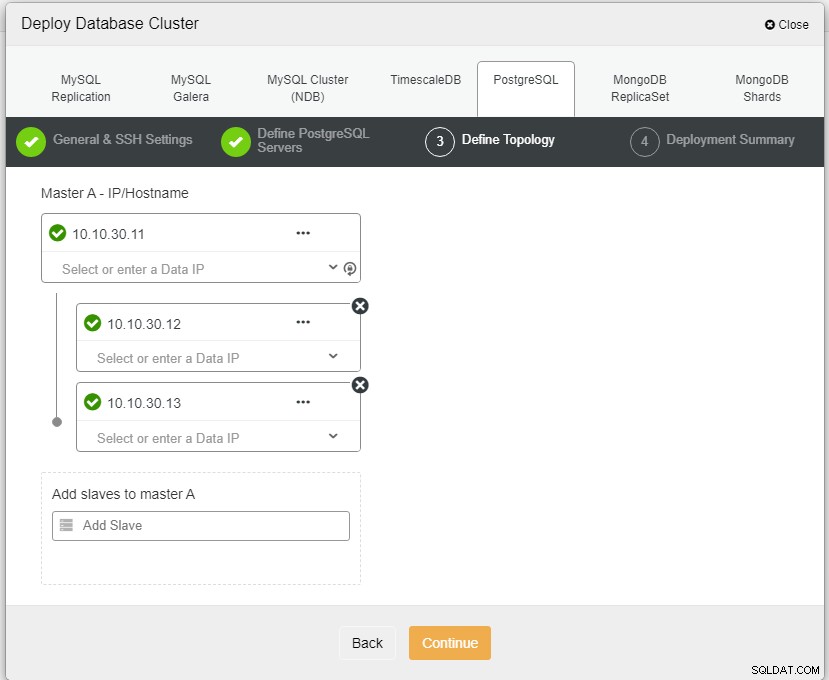
Aquí necesitamos definir los servidores usando el nombre de host o la dirección IP, como en este caso 1 maestro y 2 esclavos. El paso final es elegir el modo de replicación para nuestro clúster.
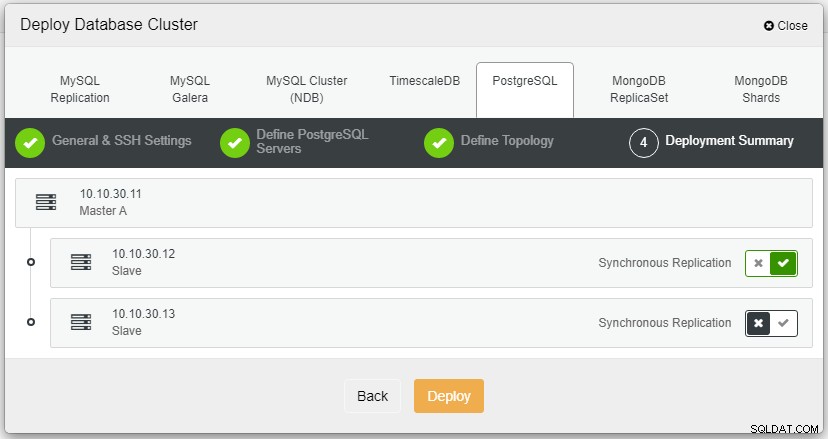
Después de hacer clic en Implementar, el proceso de implementación comenzará y podremos monitorear el progreso en la pestaña Actividad.
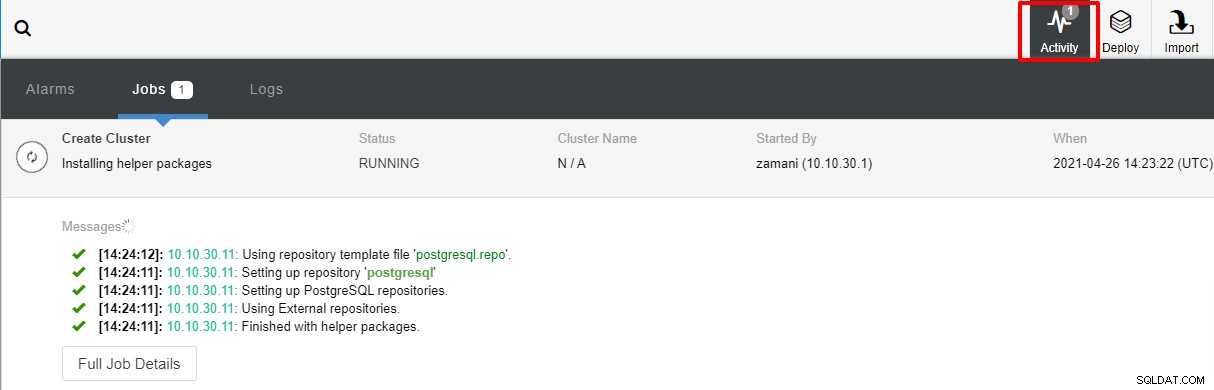
La implementación normalmente demorará un par de minutos, el rendimiento depende principalmente de la red y las especificaciones del servidor.

Ahora que tenemos PostgreSQL instalado usando ClusterControl.
Implementación de PostgreSQL mediante CLI de ClusterControl
La otra forma alternativa de implementar PostgreSQL es mediante la CLI. siempre que ya hayamos configurado la conexión sin contraseña, podemos simplemente ejecutar el siguiente comando y dejar que termine.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logDebería ver el siguiente mensaje una vez que el proceso se haya completado correctamente y pueda iniciar sesión en la web de ClusterControl para verificar:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Conclusión
Como puede ver, hay algunas formas de implementar PostgreSQL. En esta publicación de blog, hemos aprendido cómo implementarlo usando Ansible y también usando nuestro ClusterControl. Ambas formas son fáciles de seguir y se pueden lograr con una curva de aprendizaje mínima. Con ClusterControl, la configuración de replicación de transmisión se puede complementar con HAProxy, VIP y PGBouncer para agregar conmutación por error de conexión, IP virtual y agrupación de conexiones a la configuración.
Tenga en cuenta que la implementación es solo un aspecto de un entorno de base de datos de producción. Mantenerlo en funcionamiento, automatizar las conmutaciones por error, recuperar los nodos dañados y otros aspectos como la supervisión, las alertas y las copias de seguridad son esenciales.
Con suerte, esta publicación de blog beneficiará a algunos de ustedes y les dará una idea sobre cómo automatizar las implementaciones de PostgreSQL.