Cuando ESX 5 e Hyper-V en Windows Server 2012 se lanzaron y cambiaron las limitaciones que existían anteriormente para los tamaños de las VM, supe casi de inmediato que veríamos que se virtualizarían más cargas de trabajo de SQL Server de gran escala. He trabajado con una cantidad de clientes en el último año que estaban virtualizando 16-32 servidores SQL centrales por varias razones, desde estrategias simplificadas de recuperación ante desastres que coincidían con el resto del negocio, hasta consolidación y menor costo total de propiedad en hardware más nuevo. plataformas Una de las razones del cambio de escalabilidad con ESX 5+ fue la introducción de NUMA virtual (vNUMA) para invitados amplios que superaban el tamaño de un nodo NUMA de hardware individual. Con vNUMA, la VM invitada se optimiza para coincidir con la topología NUMA del hardware, lo que permite que el sistema operativo invitado y cualquier aplicación compatible con NUMA, como SQL Server, que se ejecuta en la VM aproveche las optimizaciones de rendimiento de NUMA, como si fueran ejecutándose en un servidor físico.
Dentro de VMware, una topología vNUMA está disponible en la versión de hardware 8 o superior y se configura de forma predeterminada si la cantidad de CPU virtuales es mayor que ocho para el invitado. También es posible configurar manualmente la topología vNUMA para una VM mediante opciones de configuración avanzadas, lo que puede ser útil para las VM que tienen más memoria asignada que la que puede proporcionar un nodo NUMA físico, pero aún usan ocho vCPU o menos. En su mayor parte, los ajustes de configuración predeterminados funcionan para la mayoría de las máquinas virtuales que he analizado en los últimos años, pero hay ciertos escenarios en los que la topología vNUMA predeterminada no es ideal y la configuración manual puede proporcionar algunos beneficios. Recientemente, estuve trabajando con un cliente con una cantidad de 32 máquinas virtuales de SQL Server vCPU con 512 GB de RAM asignados para realizar algunos ajustes de rendimiento en los que la topología vNUMA no se acercaba a lo que se esperaba.
Los servidores host de VM en este entorno eran procesadores de ocho núcleos E5-4650 de cuatro sockets y 1 TB de RAM, cada uno dedicado a una sola VM de SQL Server en operaciones típicas, pero con capacidad disponible para sostener dos VM en un escenario de falla. Con este diseño de hardware, hay cuatro nodos NUMA, uno por socket, y la configuración de VM esperada también tendría 4 nodos vNUMA presentados para una configuración de 32 vCPU. Sin embargo, lo que encontré al mirar los DMV en SQL Server fue que este no era el caso:
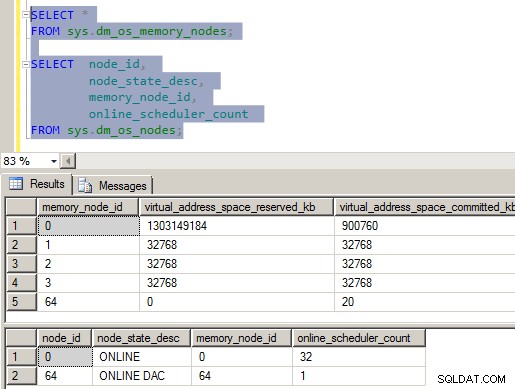
Figura 1:configuración incorrecta de vNUMA
Como probablemente pueda ver en la imagen, algo está realmente mal con la configuración de NUMA en este servidor. Hay cuatro nodos de memoria dentro de SQLOS y solo un único nodo de CPU, con todas las vCPU asignadas en él. Para ser completamente honesto, esto me dejó alucinado cuando lo vi porque iba en contra de todo lo que sabía sobre cómo SQLOS configuraba las estructuras internas al inicio de la instancia. Después de investigar un poco en los archivos ErrorLog, el Monitor de rendimiento y el Administrador de tareas de Windows, descargué una copia de CoreInfo de SysInternals y eché un vistazo al diseño de NUMA que se informa a Windows.
Mapa de procesador lógico a socket:********———————— Socket 0
——–********—————- Socket 1
—————-********——– Enchufe 2
————————******** Enchufe 3
Asignación de procesador lógico a nodo NUMA:
******************************** Nodo NUMA 0
El resultado de CoreInfo confirmó que la VM presenta las 32 vCPU como 4 sockets diferentes, pero luego agrupó las 32 vCPU en el nodo NUMA 0. Mirando los contadores de rendimiento de Windows Server 2012 en la VM, pude ver en el grupo de contadores de memoria del nodo NUMA que Se presentaron 4 nodos de memoria NUMA al sistema operativo con la memoria distribuida uniformemente entre los nodos. Todo esto se alineó con lo que estaba viendo en SQLOS, y también pude ver por las entradas de ERRORLOG de inicio que la máscara de CPU para el nodo estaba enmascarando todas las CPU disponibles en el Nodo de CPU 0, pero se estaban creando cuatro asignadores de páginas grandes, uno para cada nodo de memoria.
22/09/2013 05:03:37, Servidor, Desconocido, Configuración de nodo:nodo 0:Máscara de CPU:0x00000000ffffffff:0 Máscara de CPU activa:0x00000000ffffffff:0. Este mensaje proporciona una descripción de la configuración NUMA para esta computadora. este es solo un mensaje informativo. No se requiere ninguna acción del usuario.22/09/2013 05:03:37,Servidor,Desconocido,Esta instancia de SQL Server notificada por última vez con un ID de proceso de 1596 el 22/09/2013 5:00:25 a.m. (local) 22/09/2013 10:00:25 (UTC). Este es solo un mensaje informativo; no se requiere ninguna acción del usuario.
22/09/2013 05:03:35, Servidor, Desconocido, Grande Página asignada:32 MB
22/09/2013 05:03:35, Servidor, Desconocido, Grande Página asignada:32 MB
22/09/2013 05:03:35, Servidor, Desconocido, Página grande asignada:32 MB
22/09/2013 05:03:35, Servidor, Desconocido, Página grande asignada :32 MB
22/09/2013 05:03:35, Servidor, Desconocido, Uso de páginas bloqueadas en el administrador de memoria.
22/09/2013 05:03:35, Servidor, Desconocido, Detectado 524287 MB de RAM. Este es un mensaje informativo; no se requiere ninguna acción del usuario.
22/09/2013 05:03:35,Servidor,Desconocido,SQL Server se está iniciando en la base de prioridad normal (=7). este es solo un mensaje informativo. No se requiere ninguna acción del usuario.
22/09/2013 05:03:35,Servidor,Desconocido,SQL Server detectó 4 sockets con 8 núcleos por socket y 8 procesadores lógicos por socket 32 procesadores lógicos en total; utilizando 32 procesadores lógicos basados en licencias de SQL Server. Este es un mensaje informativo; no se requiere ninguna acción del usuario.
En este punto, estaba seguro de que se trataba de algo relacionado con la configuración de la VM, pero no pude identificar cuál era específicamente el problema, ya que nunca había visto este comportamiento en otras VM de SQL Server amplias en las que había asistido a clientes en VMware ESX 5+. en el pasado. Después de realizar un par de cambios de configuración en un servidor de VM de prueba que estaba disponible, ninguno de ellos corrigió la configuración de vNUMA que se presentaba dentro de la VM. Después de llamar al soporte de VMware, se nos pidió que deshabilitáramos la función de conexión en caliente de vCPU para la VM de prueba y ver si eso solucionaba el problema. Con hotplug deshabilitado en la VM, la salida de CoreInfo confirmó que la asignación vNUMA de los procesadores para la VM ahora era correcta:
Mapa de procesador lógico a socket:********———————— Socket 0
——–********—————- Socket 1
—————-********——– Enchufe 2
————————******** Enchufe 3
Asignación de procesador lógico a nodo NUMA:
********———————— Nodo NUMA 0
——–********————— - Nodo NUMA 1
—————-********——– Nodo NUMA 2
————————******** Nodo NUMA 3
Este comportamiento en realidad está documentado en el artículo de VMware KB (vNUMA está deshabilitado si la conexión en caliente de VCPU está habilitada), de octubre de 2013. Esta resultó ser la primera máquina virtual amplia para SQL Server con la que trabajé donde la conexión en caliente de vCPU estaba habilitada, y es no es una configuración típica que esperaría para una VM de 32 vCPU, pero era parte de la plantilla estándar que se usaba en el cliente y afectó a su SQL Server.
Efectos de la desactivación de vNUMA
Hay una serie de efectos que la desactivación de vNUMA podría tener en una carga de trabajo, pero hay dos problemas específicos que podrían afectar a SQL Server específicamente en este tipo de configuración. La primera es que el servidor podría tener problemas con las acumulaciones de espera de CMEMTHREAD, ya que hay 32 vCPU asignadas a un solo nodo NUMA y la partición predeterminada para los objetos de memoria en SQLOS es por nodo NUMA. Este problema específico fue documentado por Bob Dorr en el grupo CSS de Microsoft en su publicación de blog SQL Server 2008/2008 R2 en máquinas más nuevas con más de 8 CPU presentadas por nodo NUMA puede necesitar el indicador de seguimiento 8048. Como parte de la revisión de las estadísticas de espera en la máquina virtual con el cliente, noté que CMEMTHREAD era su segundo tipo de espera más alto, lo cual es anormal según mi experiencia y me hizo mirar la configuración de SQLOS NUMA que se muestra en la Figura 1 anterior. En este caso, la marca de rastreo no es la solución, la eliminación del hotplug de vCPU de la configuración de la VM resuelve el problema.
El segundo problema que afectaría específicamente a SQL Server si está en una versión sin parches está asociado con la administración de memoria NUMA en SQLOS y la forma en que SQLOS rastrea y administra las páginas Ausentes durante la fase inicial de aumento de la memoria después del inicio de la instancia. Bob Dorr documentó este comportamiento en la publicación de blog de CSS, Cómo funciona:SQL Server (bloques de memoria local, externa y ausente de NUMA). Esencialmente, cuando SQLOS intenta una asignación de memoria de nodo local durante el arranque inicial, si la dirección de memoria devuelta es de un nodo de memoria diferente, la página se agrega a la lista Ausente y ocurre otro intento de asignación de memoria local, y el proceso se repite hasta que una asignación de memoria local tiene éxito o se alcanza el objetivo de memoria del servidor. Dado que tres cuartas partes de la memoria de nuestras instancias existen en nodos NUMA sin programadores, esto crea una condición de rendimiento degradado durante el aumento inicial de la memoria para la instancia. Las actualizaciones recientes han cambiado el comportamiento de la asignación de memoria durante el aumento inicial para intentar solo la asignación de memoria local una cantidad fija de veces (la cantidad específica no está documentada) antes de usar la memoria externa para continuar con el procesamiento. Esas actualizaciones están documentadas en KB #2819662, REVISIÓN:problemas de rendimiento de SQL Server en entornos NUMA.
Resumen
Para máquinas virtuales amplias, definidas como aquellas que tienen más de 8 vCPU, es deseable que el hipervisor pase vNUMA a la máquina virtual para permitir que Windows y SQL Server aprovechen las optimizaciones de NUMA dentro de su base de código. Como resultado, estas máquinas virtuales más amplias no deberían tener habilitada la configuración de conexión en caliente de vCPU, ya que esto es incompatible con vNUMA y puede resultar en un rendimiento degradado para SQL Server cuando se virtualiza.