TeamCity es un servidor de integración continua y entrega continua construido en Java. Está disponible como servicio en la nube y en las instalaciones. Como puede imaginar, las herramientas de integración y entrega continuas son cruciales para el desarrollo de software, y su disponibilidad no debe verse afectada. Afortunadamente, TeamCity se puede implementar en un modo de alta disponibilidad.
Esta publicación de blog cubrirá la preparación e implementación de un entorno de alta disponibilidad para TeamCity.
El Medio Ambiente
TeamCity consta de varios elementos. Hay una aplicación Java y una base de datos que la respalda. También utiliza agentes que se comunican con la instancia principal de TeamCity. La implementación de alta disponibilidad consta de varias instancias de TeamCity, donde una actúa como principal y las otras como secundarias. Esas instancias comparten el acceso a la misma base de datos y al directorio de datos. Un esquema útil está disponible en la página de documentación de TeamCity, como se muestra a continuación:

Como podemos ver, hay dos elementos compartidos:el directorio de datos y la base de datos. Debemos asegurarnos de que también estén altamente disponibles. Hay diferentes opciones que puede usar para crear una montura compartida; sin embargo, usaremos GlusterFS. En cuanto a la base de datos, usaremos uno de los sistemas de administración de bases de datos relacionales admitidos:PostgreSQL, y usaremos ClusterControl para crear una pila de alta disponibilidad basada en él.
Cómo configurar GlusterFS
Comencemos con lo básico. Queremos configurar nombres de host y /etc/hosts en nuestros nodos de TeamCity, donde también implementaremos GlusterFS. Para hacer eso, necesitamos configurar el repositorio para los paquetes más recientes de GlusterFS en todos ellos:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateEntonces podemos instalar GlusterFS en todos nuestros nodos de TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS usa el puerto 24007 para la conectividad entre los nodos; debemos asegurarnos de que esté abierto y accesible para todos los nodos.
Una vez que la conectividad esté lista, podemos crear un clúster de GlusterFS ejecutándolo desde un nodo:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Ahora, podemos probar cómo se ve el estado:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Parece que todo está bien y la conectividad está en su lugar.
A continuación, debemos preparar un dispositivo de bloque para que lo utilice GlusterFS. Esto debe ejecutarse en todos los nodos. Primero, crea una partición:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Luego, formatea esa partición:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Finalmente, en todos los nodos, necesitamos crear un directorio que se usará para montar la partición y editar fstab para asegurar que se montará al inicio:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabVeamos ahora que esto funciona:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Ahora podemos usar uno de los nodos para crear e iniciar el volumen GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successTenga en cuenta que usamos el valor '3' para el número de réplicas. Significa que cada volumen existirá en tres copias. En nuestro caso, cada bloque, cada volumen /dev/sdb1 en todos los nodos contendrá todos los datos.
Una vez iniciados los volúmenes, podemos verificar su estado:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksComo puede ver, todo se ve bien. Lo importante es que GlusterFS eligió el puerto 49152 para acceder a ese volumen y debemos asegurarnos de que sea accesible en todos los nodos donde lo montaremos.
El siguiente paso será instalar el paquete del cliente GlusterFS. Para este ejemplo, lo necesitamos instalado en los mismos nodos que el servidor GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.A continuación, debemos crear un directorio en todos los nodos para usarlo como directorio de datos compartidos para TeamCity. Esto tiene que suceder en todos los nodos:
example@sqldat.com:~# sudo mkdir /teamcity-storagePor último, monte el volumen GlusterFS en todos los nodos:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageEsto completa los preparativos de almacenamiento compartido.
Creación de un clúster PostgreSQL de alta disponibilidad
Una vez que se completa la configuración del almacenamiento compartido para TeamCity, ahora podemos construir nuestra infraestructura de base de datos de alta disponibilidad. TeamCity puede usar diferentes bases de datos; sin embargo, usaremos PostgreSQL en este blog. Aprovecharemos ClusterControl para implementar y luego administrar el entorno de la base de datos.
La guía de TeamCity para crear una implementación de múltiples nodos es útil, pero parece dejar de lado la alta disponibilidad de todo lo que no sea TeamCity. La guía de TeamCity sugiere un servidor NFS o SMB para el almacenamiento de datos que, por sí solo, no tiene redundancia y se convertirá en un único punto de falla. Hemos abordado esto mediante el uso de GlusterFS. Mencionan una base de datos compartida, ya que un solo nodo de base de datos obviamente no proporciona alta disponibilidad. Tenemos que construir una pila adecuada:

En nuestro caso. consistirá en tres nodos de PostgreSQL, uno principal y dos réplicas. Usaremos HAProxy como balanceador de carga y usaremos Keepalived para administrar IP virtual para proporcionar un punto final único para que la aplicación se conecte. ClusterControl manejará las fallas al monitorear la topología de replicación y realizar cualquier recuperación requerida según sea necesario, como reiniciar procesos fallidos o conmutar por error a una de las réplicas si el nodo principal deja de funcionar.
Para comenzar, implementaremos los nodos de la base de datos. Tenga en cuenta que ClusterControl requiere conectividad SSH desde el nodo ClusterControl a todos los nodos que administra.

Luego, elegimos un usuario que usaremos para conectarnos al base de datos, su contraseña y la versión de PostgreSQL para implementar:

A continuación, vamos a definir qué nodos usar para implementar PostgreSQL :
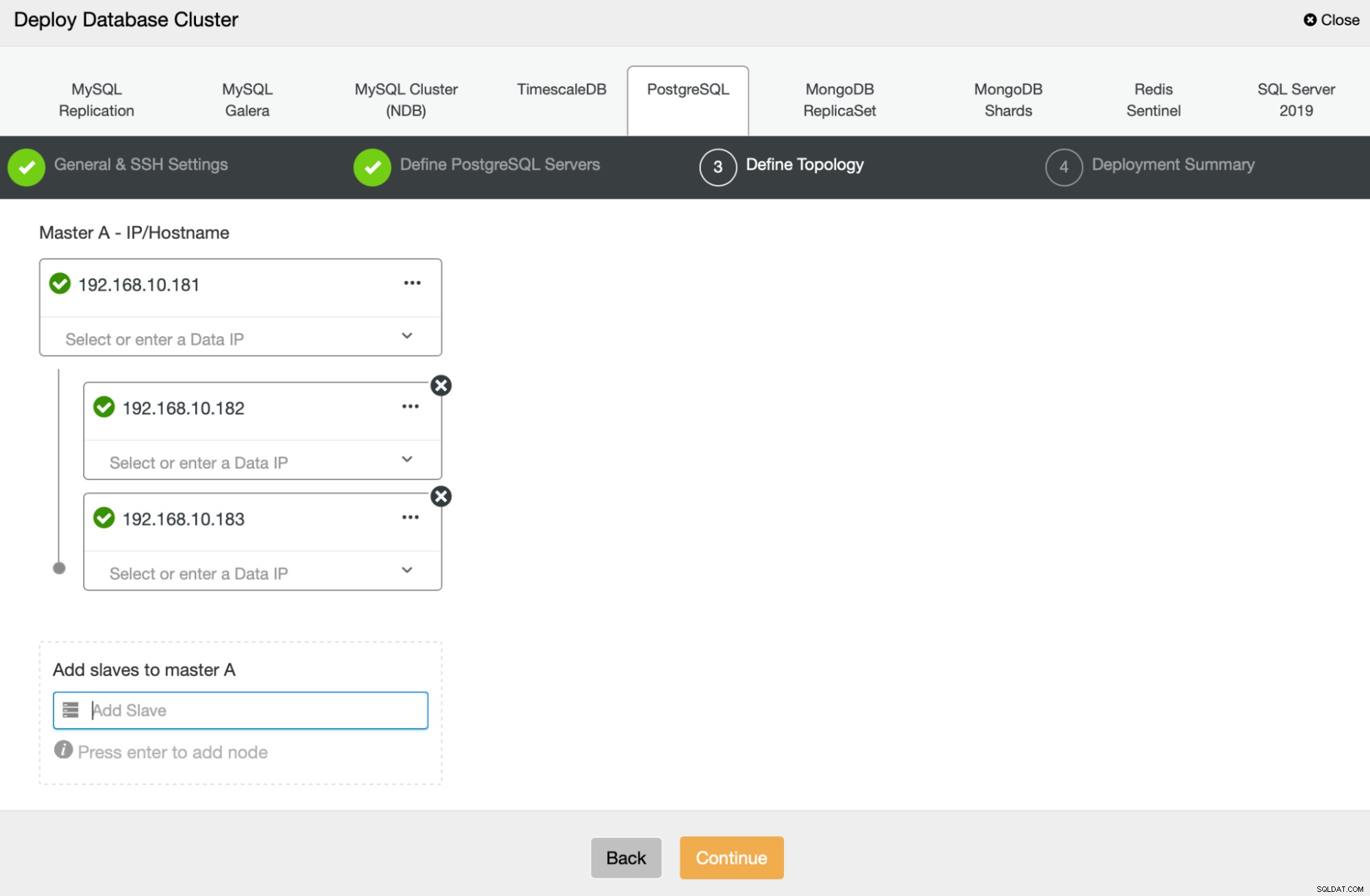
Finalmente, podemos definir si los nodos deben usar replicación asíncrona o síncrona. La principal diferencia entre estos dos es que la replicación síncrona garantiza que cada transacción ejecutada en el nodo principal siempre se replicará en las réplicas. Sin embargo, la replicación síncrona también ralentiza la confirmación. Recomendamos habilitar la replicación síncrona para obtener la mejor durabilidad, pero debe verificar más tarde si el rendimiento es aceptable.

Después de hacer clic en "Implementar", se iniciará un trabajo de implementación. Podemos monitorear su progreso en la pestaña Actividad en la interfaz de usuario de ClusterControl. Eventualmente, deberíamos ver que el trabajo se completó y que el clúster se implementó correctamente.

Implemente instancias de HAProxy yendo a Administrar -> Equilibradores de carga. Seleccione HAProxy como equilibrador de carga y rellene el formulario. La elección más importante es dónde desea implementar HAProxy. Usamos un nodo de base de datos en este caso, pero en un entorno de producción, lo más probable es que desee separar los balanceadores de carga de las instancias de la base de datos. A continuación, seleccione qué nodos de PostgreSQL incluir en HAProxy. Los queremos todos.

Ahora comenzará la implementación de HAProxy. Queremos repetirlo al menos una vez más para crear dos instancias de HAProxy para la redundancia. En esta implementación, decidimos optar por tres balanceadores de carga HAProxy. A continuación se muestra una captura de pantalla de la pantalla de configuración al configurar la implementación de un segundo HAProxy:
Cuando todas nuestras instancias de HAProxy están en funcionamiento, podemos implementar Keepalived . La idea aquí es que Keepalived se ubicará junto con HAProxy y monitoreará el proceso de HAProxy. Una de las instancias con HAProxy en funcionamiento tendrá asignada una IP virtual. La aplicación debe utilizar este VIP para conectarse a la base de datos. Keepalived detectará si ese HAProxy deja de estar disponible y pasará a otra instancia de HAProxy disponible.
El asistente de implementación requiere que pasemos las instancias de HAProxy que queremos que Keepalived supervise. También necesitamos pasar la dirección IP y la interfaz de red para VIP.

El último y último paso será crear una base de datos para TeamCity:

Con esto, hemos concluido la implementación del clúster PostgreSQL de alta disponibilidad.
Implementación de TeamCity como multinodo
El siguiente paso es implementar TeamCity en un entorno de múltiples nodos. Usaremos tres nodos de TeamCity. Primero, tenemos que instalar Java JRE y JDK que coincidan con los requisitos de TeamCity.
apt install default-jre default-jdkAhora, en todos los nodos, tenemos que descargar TeamCity. Lo instalaremos en un directorio local, no compartido.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzEntonces podemos iniciar TeamCity en uno de los nodos:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logUna vez que se haya iniciado TeamCity, podemos acceder a la interfaz de usuario y comenzar la implementación. Inicialmente, tenemos que pasar la ubicación del directorio de datos. Este es el volumen compartido que creamos en GlusterFS.

A continuación, seleccione la base de datos. Vamos a utilizar un clúster de PostgreSQL que ya hemos creado.

Descargue e instale el controlador JDBC:

A continuación, complete los detalles de acceso. Usaremos la IP virtual proporcionada por Keepalived. Tenga en cuenta que usamos el puerto 5433. Este es el puerto que se usa para el backend de lectura/escritura de HAProxy; siempre apuntará hacia el nodo principal activo. A continuación, elija un usuario y la base de datos para usar con TeamCity.

Una vez hecho esto, TeamCity comenzará a inicializar la estructura de la base de datos.

Acepto el acuerdo de licencia:

Finalmente, cree un usuario para TeamCity:

¡Eso es! Ahora deberíamos poder ver la GUI de TeamCity:

Ahora, tenemos que configurar TeamCity en modo multinodo. Primero, tenemos que editar los scripts de inicio en todos los nodos:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shDebemos asegurarnos de exportar las siguientes dos variables. Verifique que utiliza el nombre de host, la IP y los directorios correctos para el almacenamiento local y compartido:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Una vez hecho esto, puede iniciar los nodos restantes:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startDebería ver el siguiente resultado en Administración -> Configuración de nodos:un nodo principal y dos nodos en espera.

Tenga en cuenta que la conmutación por error en TeamCity no está automatizada. Si el nodo principal deja de funcionar, debe conectarse a uno de los nodos secundarios. Para hacer esto, vaya a "Configuración de nodos" y ascienda al nodo "Principal". Desde la pantalla de inicio de sesión, verá una indicación clara de que se trata de un nodo secundario:

En la "Configuración de nodos", verá que el nodo tiene eliminado del clúster:

Recibirá un mensaje que indica que no puede escribir en este nodo. No te preocupes; la escritura requerida para promover este nodo al estado "principal" funcionará bien:

Haga clic en "Habilitar" y hemos promovido con éxito un nodo secundario de TimeCity:

Cuando el nodo 1 esté disponible y TeamCity se inicie nuevamente en ese nodo, verlo volver a unirse al clúster:

Si desea mejorar aún más el rendimiento, puede implementar HAProxy + Keepalived frente a la IU de TeamCity para proporcionar un único punto de entrada a la GUI. Puede encontrar detalles sobre la configuración de HAProxy para TeamCity en la documentación.
Conclusión
Como puede ver, la implementación de TeamCity para alta disponibilidad no es tan difícil; la mayor parte se ha cubierto a fondo en la documentación. Si está buscando formas de automatizar algo de esto y agregar un backend de base de datos de alta disponibilidad, considere evaluar ClusterControl gratis durante 30 días. ClusterControl puede implementar y monitorear rápidamente el back-end, proporcionando conmutación por error automatizada, recuperación, monitoreo, administración de copias de seguridad y más.
Para obtener más consejos sobre herramientas de desarrollo de software y prácticas recomendadas, consulte cómo ayudar a su equipo de DevOps con sus necesidades de base de datos.
Para obtener las últimas noticias y las mejores prácticas para administrar su infraestructura de base de datos basada en código abierto, no olvide seguirnos en Twitter o LinkedIn y suscríbase a nuestro boletín. ¡Hasta pronto!