Una de las muchas mejoras del plan de ejecución en SQL Server 2012 fue la adición de información de reserva y uso de subprocesos para planes de ejecución paralelos. Esta publicación analiza exactamente lo que significan estos números y brinda información adicional para comprender la ejecución en paralelo.
Considere ejecutar la siguiente consulta en una versión ampliada de la base de datos AdventureWorks:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; El optimizador de consultas elige un plan de ejecución paralelo:
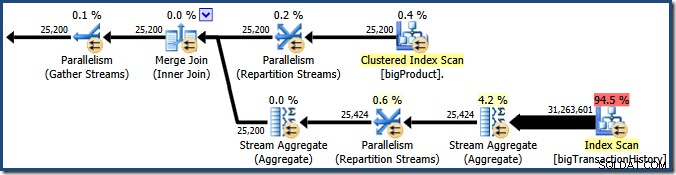
Plan Explorer muestra detalles de uso de subprocesos paralelos en la información sobre herramientas del nodo raíz. Para ver la misma información en SSMS, haga clic en el nodo raíz del plan, abra la ventana Propiedades y expanda ThreadStat nodo. Usando una máquina con ocho procesadores lógicos disponibles para que SQL Server los use, la información de uso de subprocesos de una ejecución típica de esta consulta se muestra a continuación, Explorador de planes a la izquierda, vista de SSMS a la derecha:
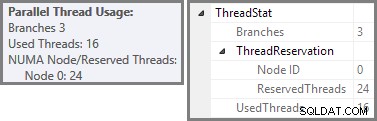
La captura de pantalla muestra que el motor de ejecución reservó 24 hilos para esta consulta y terminó usando 16 de ellos. También muestra que el plan de consulta tiene tres ramas , aunque no dice exactamente qué es una rama. Si ha leído mi artículo de Simple Talk sobre la ejecución de consultas en paralelo, sabrá que las ramas son secciones de un plan de consultas en paralelo delimitadas por operadores de intercambio. El siguiente diagrama dibuja los límites y enumera las ramas (haga clic para ampliar):

Rama dos (naranja)
Veamos primero la rama dos con un poco más de detalle:
Con un grado de paralelismo (DOP) de ocho, hay ocho subprocesos que ejecutan esta rama del plan de consulta. Es importante entender que este es todo el plan de ejecución en lo que respecta a estos ocho hilos, no tienen conocimiento del plan más amplio.
En un plan de ejecución en serie, un único subproceso lee datos de un origen de datos, procesa las filas a través de una serie de operadores del plan y devuelve los resultados al destino (que podría ser una ventana de resultados de consulta de SSMS o una tabla de base de datos, por ejemplo).
En una sucursal de un plan de ejecución en paralelo, la situación es muy similar:cada subproceso lee datos de un origen, procesa las filas a través de una serie de operadores del plan y devuelve los resultados al destino. Las diferencias son que el destino es un operador de intercambio (paralelismo) y la fuente de datos también puede ser un intercambio.
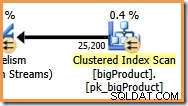
En la rama naranja, la fuente de datos es un escaneo de índice agrupado y el destino es el lado derecho de un intercambio de flujos de partición. El lado derecho de un intercambio se conoce como el lado del productor. , porque se conecta a una sucursal que agrega datos al intercambio.
Los ocho subprocesos en la rama naranja cooperan para escanear la tabla y agregar filas al intercambio. El intercambio ensambla filas en paquetes del tamaño de una página. Una vez que un paquete está lleno, se empuja a través del intercambio hacia el otro lado. Si el intercambio tiene otro paquete vacío disponible para llenar, el proceso continúa hasta que se hayan procesado todas las filas de fuentes de datos (o el intercambio se queda sin paquetes vacíos).
Podemos ver el número de filas procesadas en cada subproceso utilizando la vista de árbol del plan en Plan Explorer:
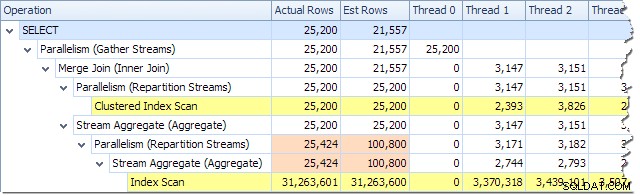
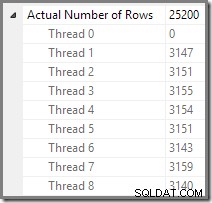
Plan Explorer hace que sea fácil ver cómo se distribuyen las filas en los subprocesos para todos las operaciones físicas en el plan. En SSMS, está limitado a ver la distribución de filas para un solo operador de plan. Para hacer esto, haga clic en un ícono de operador, abra la ventana Propiedades y luego expanda el nodo Número real de filas. El siguiente gráfico muestra la información de SSMS para el nodo Repartition Streams en el borde entre las ramas naranja y violeta:
Rama Tres (Verde)
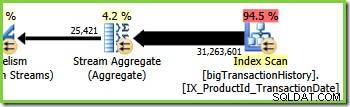
La rama tres es similar a la rama dos, pero contiene un operador Agregado de flujo adicional. La rama verde también tiene ocho hilos, haciendo un total de dieciséis vistos hasta ahora. Los ocho subprocesos de rama verde leen datos de un escaneo de índice no agrupado, realizan algún tipo de agregación y pasan los resultados al lado del productor de otro intercambio de flujos de partición.
La información sobre herramientas de Plan Explorer para Stream Aggregate muestra que está agrupando por ID de producto y calculando una expresión etiquetada partialagg1005 :
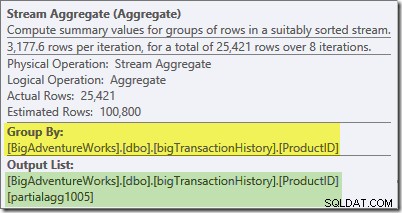
La pestaña Expresiones muestra que la expresión es el resultado de contar las filas en cada grupo:

Stream Aggregate está calculando un parcial (también conocido como agregado 'local'). El calificador parcial (o local) simplemente significa que cada subproceso calcula el agregado en las filas que ve. Las filas de Index Scan se distribuyen entre subprocesos utilizando un esquema basado en la demanda:no hay una distribución fija de filas por adelantado; los subprocesos reciben un rango de filas del escaneo a medida que las solicitan. Qué filas terminan en qué subprocesos es esencialmente aleatorio porque depende de problemas de tiempo y otros factores.
Cada hilo ve diferentes filas del escaneo, pero filas con el mismo ID de producto puede ser visto por más de un hilo. El agregado es 'parcial' porque los subtotales para un grupo de ID de producto en particular pueden aparecer en más de un hilo; es 'local' porque cada subproceso calcula su resultado basándose únicamente en las filas que recibe. Por ejemplo, digamos que hay 1000 filas para el ID de producto n.° 1 en la tabla. Un subproceso podría ver 432 de esas filas, mientras que otro podría ver 568. Ambos subprocesos tendrán un parcial recuento de filas para el ID de producto n.° 1 (432 en un subproceso, 568 en el otro).
La agregación parcial es una optimización del rendimiento porque reduce el número de filas antes de lo que sería posible. En la rama verde, la agregación temprana da como resultado que se ensamblan menos filas en paquetes y se envían a través del intercambio de Repartition Stream.
Rama 1 (Púrpura)

La rama morada tiene ocho hilos más, haciendo veinticuatro hasta ahora. Cada subproceso en esta rama lee filas de los dos intercambios de Repartition Streams y escribe filas en un intercambio de Gather Streams. Esta rama puede parecer complicada y desconocida, pero solo lee filas de una fuente de datos y envía resultados a un destino, como cualquier otro plan de consulta.
El lado derecho del plan muestra los datos que se leen desde el otro lado de los dos intercambios de Repartition Streams que se ven en las ramas naranja y verde. Este lado (lado izquierdo) del intercambio se conoce como el consumidor lado, porque los subprocesos adjuntos aquí están leyendo (consumiendo) filas. Los ocho hilos de la rama morada son consumidores de datos en los dos intercambios de Repartition Streams.
El lado izquierdo de la rama morada muestra las filas que se escriben para el productor lado de un intercambio Gather Streams. Los los mismos ocho hilos (que son consumidores en los intercambios de Repartition Streams) están realizando un productor rol aquí.
Cada subproceso de la rama morada ejecuta todos los operadores de la rama, del mismo modo que un solo subproceso ejecuta todas las operaciones en un plan de ejecución en serie. La principal diferencia es que hay ocho subprocesos que se ejecutan simultáneamente, cada uno trabajando en una fila diferente en un momento dado, usando diferentes instancias de los operadores del plan de consulta.
El Stream Aggregate en esta rama es un global agregar. Combina los agregados parciales (locales) calculados en la rama verde (recuerde el ejemplo de un recuento de 432 en un subproceso y 568 en el otro) para producir un total combinado para cada ID de producto. La información sobre herramientas del Explorador de planes muestra la expresión de resultado global, etiquetada Expr1004:
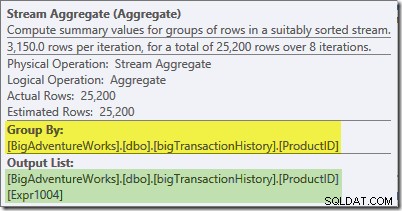
El resultado global correcto por ID de producto se calcula sumando los agregados parciales, como se ilustra en la pestaña Expresiones:
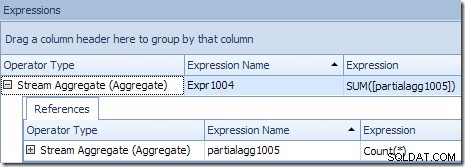
Para continuar con nuestro ejemplo (imaginario), el resultado correcto de 1000 filas para el ID de producto n.º 1 se obtiene sumando los dos subtotales de 432 y 568.
Cada uno de los ocho subprocesos de la rama púrpura lee datos del lado del consumidor de los dos intercambios de Gather Streams, calcula los agregados globales, realiza Merge Join en el ID del producto y agrega filas al intercambio de Gather Streams en el extremo izquierdo de la rama púrpura. El proceso central no es muy diferente de un plan en serie ordinario; las diferencias están en dónde se leen las filas, a dónde se envían y cómo se distribuyen las filas entre los subprocesos...
Distribución de filas de intercambio
El lector alerta se preguntará acerca de un par de detalles en este punto. ¿Cómo logra la rama morada calcular los resultados correctos por ID de producto? pero la rama verde no pudo (los resultados para el mismo ID de producto se distribuyeron en muchos subprocesos)? Además, si hay ocho uniones de combinación separadas (una por subproceso), ¿cómo garantiza SQL Server que las filas que se unirán terminen en la misma instancia? de la unión?
Ambas preguntas se pueden responder observando la forma en que los dos intercambios de Repartition Streams enrutan las filas desde el lado del productor (en las ramas verde y naranja) hasta el lado del consumidor (en la rama morada). Primero veremos el intercambio de Repartition Streams que bordea las ramas naranja y púrpura:
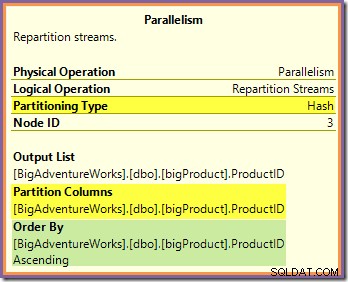
Este intercambio enruta las filas entrantes (desde la rama naranja) mediante una función hash aplicada a la columna de ID del producto. El efecto es que todas las filas de un ID de producto en particular están garantizadas para enrutarse al mismo subproceso de rama púrpura. Los hilos naranja y morado no saben nada de este enrutamiento; todo esto es manejado internamente por el intercambio.
Todo lo que saben los subprocesos naranjas es que están devolviendo filas al iterador principal que las solicitó (el lado del productor del intercambio). Del mismo modo, todos los subprocesos morados "saben" que están leyendo filas de una fuente de datos. El intercambio determina en qué paquete irá una fila de hilo naranja entrante, y podría ser cualquiera de los ocho paquetes candidatos. De manera similar, el intercambio determina de qué paquete leer una fila para satisfacer una solicitud de lectura de un subproceso púrpura.
Tenga cuidado de no adquirir una imagen mental de un hilo naranja particular (productor) que está vinculado directamente a un hilo violeta particular (consumidor). No es así como funciona este plan de consulta. Un productor de naranjas puede termina enviando filas a todos los consumidores morados:el enrutamiento depende completamente del valor de la columna de ID del producto en cada fila que procesa.
También tenga en cuenta que un paquete de filas en el intercambio solo se transfiere cuando está lleno (o cuando el lado del productor se queda sin datos). Imagine el intercambio llenando paquetes una fila a la vez, donde las filas para un paquete en particular pueden provenir de cualquiera de los subprocesos (naranja) del lado del productor. Una vez que un paquete está lleno, se pasa al lado del consumidor, donde un subproceso de consumidor particular (púrpura) puede comenzar a leerlo.
El intercambio Repartition Streams que bordea las ramas verde y morada funciona de manera muy similar:
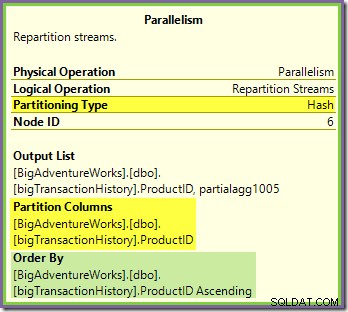
Las filas se enrutan a paquetes en este intercambio utilizando la misma función hash en la misma columna de partición en cuanto al intercambio naranja-púrpura visto anteriormente. Esto significa que ambos Repartition Streams intercambia filas de rutas con el mismo ID de producto en el mismo subproceso de rama púrpura.
Esto explica cómo Stream Aggregate en la rama púrpura puede calcular agregados globales:si se ve una fila con una ID de producto particular en un subproceso de rama púrpura particular, se garantiza que ese subproceso verá todas las filas para esa ID de producto (y no otro hilo lo hará).
La columna de particionamiento de intercambio común también es la clave de combinación para la combinación de fusión, por lo que se garantiza que todas las filas que posiblemente puedan unirse serán procesadas por el mismo subproceso (púrpura).
Una última cosa a tener en cuenta es que ambos intercambios preservan el orden (también conocido como 'fusión'), como se muestra en el atributo Ordenar por en la información sobre herramientas. Esto cumple con el requisito de combinación de combinación de que las filas de entrada se ordenen en las claves de combinación. Tenga en cuenta que los intercambios nunca ordenan las filas por sí mismos, solo se pueden configurar para preservar orden existente.
Hilo Cero
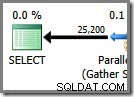
La parte final del plan de ejecución se encuentra a la izquierda del intercambio Gather Streams. Siempre se ejecuta en un solo subproceso, el mismo que se usa para ejecutar todo un plan en serie regular. Este subproceso siempre está etiquetado como 'Subproceso 0' en los planes de ejecución y, a veces, se denomina subproceso 'coordinador' (una designación que no encuentro particularmente útil).
El subproceso cero lee las filas del lado del consumidor (izquierda) del intercambio Gather Streams y las devuelve al cliente. No hay iteradores de subproceso cero aparte del intercambio en este ejemplo, pero si los hubiera, todos se ejecutarían en el mismo subproceso único. Tenga en cuenta que Gather Streams también es un intercambio de fusión (tiene un atributo Ordenar por):

Los planes paralelos más complejos pueden incluir zonas de ejecución en serie distintas de la que se encuentra a la izquierda del intercambio final de Gather Streams. Estas zonas seriales no se ejecutan en el subproceso cero, pero ese es un detalle para explorar en otro momento.
Hilos reservados y usados revisados
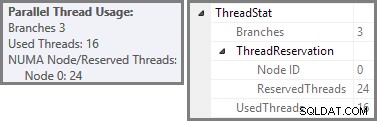
Hemos visto que este plan paralelo contiene tres ramas. Esto explica por qué SQL Server reservado 24 hilos (tres ramas en DOP 8). La pregunta es por qué solo 16 subprocesos se informan como 'usados' en la captura de pantalla anterior.
Hay dos partes en la respuesta. La primera parte no se aplica a este plan, pero es importante conocerla de todos modos. El número de sucursales notificadas es el número máximo que se puede ejecutar simultáneamente .
Como sabrá, ciertos operadores de plan están 'bloqueando', lo que significa que tienen que consumir todas sus filas de entrada antes de que puedan producir la primera fila de salida. El ejemplo más claro de un operador de bloqueo (también conocido como stop-and-go) es Sort. Una ordenación no puede devolver la primera fila en secuencia ordenada antes de haber visto todas las filas de entrada porque la última fila de entrada podría ordenarse primero.
Los operadores con múltiples entradas (joins y uniones, por ejemplo) pueden bloquear con respecto a una entrada, pero no bloquear ('canalizar') con respecto a la otra. Un ejemplo de esto es la unión hash:la entrada de compilación está bloqueando, pero la entrada de la sonda está canalizada. La entrada de compilación está bloqueando porque crea la tabla hash contra la cual se prueban las filas de la sonda.
La presencia de operadores de bloqueo significa que una o más ramas paralelas podrían se garantiza que se complete antes de que otros puedan comenzar. Cuando esto ocurre, SQL Server puede reutilizar los subprocesos utilizados para procesar una rama completa para una rama posterior en la secuencia. SQL Server es muy conservador con respecto a la reserva de subprocesos, por lo que solo las ramas que están garantizadas para completar antes de que comience otro, utilice esta optimización de reserva de subprocesos. Nuestro plan de consulta no contiene ningún operador de bloqueo, por lo que el recuento de sucursales informado es solo el número total de sucursales.
La segunda parte de la respuesta es que los subprocesos aún se pueden reutilizar si suceden para completar antes de que se inicie un subproceso en otra rama. El número total de subprocesos todavía está reservado en este caso, pero el uso real puede ser menor. La cantidad de subprocesos que usa realmente un plan paralelo depende de los problemas de sincronización, entre otras cosas, y puede variar entre ejecuciones.
Los subprocesos paralelos no comienzan a ejecutarse todos al mismo tiempo, pero nuevamente, los detalles tendrán que esperar para otra ocasión. Veamos el plan de consulta nuevamente para ver cómo se pueden reutilizar los subprocesos, a pesar de la falta de operadores de bloqueo:
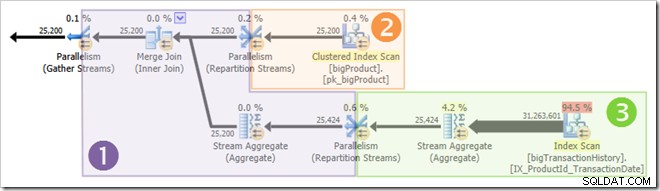
Está claro que los subprocesos en la rama uno no pueden completarse antes de que se inicien los subprocesos en las ramas dos o tres, por lo que no hay posibilidad de reutilización de subprocesos allí. La rama tres también es poco probable para completar antes de que se inicie la rama uno o la rama dos porque tiene mucho trabajo por hacer (casi 32 millones de filas para agregar).
La rama dos es un asunto diferente. El tamaño relativamente pequeño de la tabla de productos significa que existe una posibilidad decente de que la sucursal pueda completar su trabajo antes rama tres se pone en marcha. Si la lectura de la tabla de productos no da como resultado ninguna E/S física, ocho subprocesos no tardarán mucho en leer las 25 200 filas y enviarlas al intercambio de flujos de partición de límite naranja-púrpura.
Esto es exactamente lo que sucedió en las ejecuciones de prueba utilizadas para las capturas de pantalla vistas hasta ahora en esta publicación:los ocho hilos de la rama naranja se completaron lo suficientemente rápido como para que pudieran reutilizarse para la rama verde. En total, se usaron dieciséis subprocesos únicos, así que eso es lo que informa el plan de ejecución.
Si la consulta se vuelve a ejecutar con una caché fría, el retraso introducido por la E/S física es suficiente para garantizar que los subprocesos de la rama verde se inicien antes de que se completen los subprocesos de la rama naranja. No se reutiliza ningún subproceso, por lo que el plan de ejecución informa que los 24 subprocesos reservados se utilizaron de hecho:
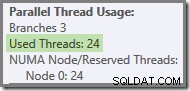
En términos más generales, es posible cualquier número de 'subprocesos usados' entre los dos extremos (16 y 24 para este plan de consulta):
Finalmente, tenga en cuenta que el subproceso que ejecuta la parte serial del plan a la izquierda de Gather Streams final no se cuenta. en los totales de hilos paralelos. No es un subproceso adicional agregado para acomodar la ejecución en paralelo.
Reflexiones finales
La belleza del modelo de intercambio utilizado por SQL Server para implementar la ejecución paralela es que toda la complejidad del almacenamiento en búfer y el movimiento de filas entre subprocesos está oculta dentro de los operadores de intercambio (paralelismo). El resto del plan se divide en ordenadas "ramas", delimitadas por intercambios. Dentro de una sucursal, cada operador se comporta de la misma manera que en un plan en serie:en casi todos los casos, los operadores de la sucursal no tienen conocimiento de que el plan más amplio utiliza la ejecución en paralelo.
La clave para comprender la ejecución paralela es (mentalmente) dividir el plan paralelo en los límites del intercambio e imaginar cada rama como serial separado del DOP. planes, todos ejecutando concurrencia en un subconjunto distinto de filas. Recuerde en particular que cada uno de estos planes seriales ejecuta todos los operadores en esa rama; SQL Server no. ¡ejecuta cada operador en su propio hilo!
Comprender el comportamiento más detallado requiere un poco de reflexión, especialmente en cuanto a cómo se enrutan las filas dentro de los intercambios y cómo el motor garantiza resultados correctos, pero la mayoría de las cosas que vale la pena saber requieren un poco de reflexión, ¿no es así?