En la publicación de blog anterior, expliqué brevemente cómo publicamos los números de rendimiento en el anuncio de pglogical. En esta publicación de blog, me gustaría analizar los límites de rendimiento de las soluciones de replicación lógica en general, y también cómo se aplican a pglogical.
replicación física
En primer lugar, veamos cómo funciona la replicación física (integrada en PostgreSQL desde la versión 9.0). Una figura un tanto simplificada de con dos solo dos nodos se ve así:
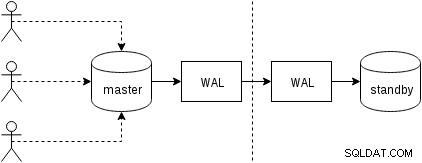
Los clientes ejecutan consultas en el nodo maestro, los cambios se escriben en un registro de transacciones (WAL) y se copian a través de la red a WAL en el nodo en espera. El proceso de recuperación en espera en espera luego lee los cambios de WAL y los aplica a los archivos de datos al igual que durante la recuperación. Si el modo de espera está en modo "hot_standby", los clientes pueden emitir consultas de solo lectura en el nodo mientras esto sucede.
Esto es muy eficiente porque hay muy poco procesamiento adicional:los cambios se transfieren y se escriben en el modo de espera como un blob binario opaco. Por supuesto, la recuperación no es gratuita (tanto en términos de CPU como de E/S), pero es difícil ser más eficiente que esto.
Los cuellos de botella potenciales obvios con la replicación física son el ancho de banda de la red (transferencia de la WAL del maestro al modo de espera) y también la E/S en el modo de espera, que puede estar saturada por el proceso de recuperación que a menudo emite una gran cantidad de solicitudes de E/S aleatorias ( en algunos casos más que el maestro, pero no entremos en eso).
replicación lógica
La replicación lógica es un poco más complicada, ya que no se trata de un flujo WAL binario opaco, sino de un flujo de cambios "lógicos" (imagínese las declaraciones INSERT, UPDATE o DELETE, aunque eso no es perfectamente correcto ya que estamos tratando con una representación estructurada de los datos). Tener los cambios lógicos permite hacer cosas interesantes como la resolución de conflictos, replicar solo tablas seleccionadas, en un esquema diferente o entre diferentes versiones (o incluso diferentes bases de datos).
Hay diferentes formas de obtener los cambios:el enfoque tradicional es mediante el uso de disparadores que registran los cambios en una tabla y permiten que un proceso personalizado lea continuamente esos cambios y los aplique en espera mediante la ejecución de consultas SQL. Y todo esto es impulsado por un proceso daemon externo (o posiblemente múltiples procesos, ejecutándose en ambos nodos), como se ilustra en la siguiente figura

Eso es lo que hacen slony o londiste, y si bien funcionó bastante bien, significa una gran sobrecarga; por ejemplo, requiere capturar los cambios de datos y escribir los datos varias veces (en la tabla original y en una tabla de "registro", y también a WAL para ambas tablas). Discutiremos otras fuentes de gastos generales más adelante. Si bien pglogical necesita lograr los mismos objetivos, los logra de manera diferente, gracias a varias funciones agregadas a las versiones recientes de PostgreSQL (por lo tanto, no estaban disponibles cuando se implementaron las otras herramientas):

Es decir, en lugar de mantener un registro de cambios separado, pglogical se basa en WAL; esto es posible gracias a una decodificación lógica disponible en PostgreSQL 9.4, que permite extraer cambios lógicos del registro WAL. Gracias a esto, pglogical no necesita disparadores costosos y, por lo general, puede evitar escribir los datos dos veces en el maestro (excepto en el caso de transacciones grandes que pueden derramarse en el disco).
Después de decodificar cada transacción, se transfiere a la base de datos en espera y el proceso de aplicación aplica sus cambios a la base de datos en espera. pglogical no aplica los cambios mediante la ejecución de consultas SQL regulares, sino a un nivel inferior, evitando la sobrecarga asociada con el análisis y la planificación de consultas SQL. Esto le da a pglogical una ventaja significativa sobre las soluciones existentes que pasan por la capa de SQL (pagando así el análisis y la planificación).
cuellos de botella potenciales
Claramente, la replicación lógica es susceptible a los mismos cuellos de botella que la replicación física, es decir, es posible saturar la red al transferir los cambios y E/S en el modo de espera al aplicarlos en el modo de espera. También hay una buena cantidad de gastos generales debido a los pasos adicionales que no están presentes en una replicación física.
Necesitamos recopilar de alguna manera los cambios lógicos, mientras que la replicación física simplemente reenvía el WAL como un flujo de bytes. Como ya se mencionó, las soluciones existentes generalmente se basan en activadores que escriben los cambios en una tabla de "registro". pglogical, en cambio, se basa en el registro de escritura anticipada (WAL) y la decodificación lógica para lograr lo mismo, que es más económico que los disparadores y tampoco necesita escribir los datos dos veces en la mayoría de los casos (con la ventaja adicional de que aplicamos los cambios automáticamente en orden de confirmación).
Eso no quiere decir que no haya oportunidades para mejoras adicionales; por ejemplo, la decodificación actualmente solo ocurre una vez que se confirma la transacción, por lo que con transacciones grandes esto puede aumentar el retraso de la replicación. La replicación física simplemente transmite los cambios de WAL al otro nodo y, por lo tanto, no tiene esta limitación. Las transacciones grandes también se pueden derramar en el disco, lo que provoca escrituras duplicadas, porque el flujo ascendente tiene que almacenarlas hasta que se confirmen y se puedan enviar al flujo descendente.
El trabajo futuro está planificado para permitir que pglogical comience a transmitir grandes transacciones mientras aún están en progreso en el flujo ascendente, lo que reduce la latencia entre la confirmación ascendente y descendente y reduce la amplificación de escritura ascendente.
Una vez que los cambios se transfieren al modo de espera, el proceso de aplicación debe aplicarlos de alguna manera. Como se mencionó en la sección anterior, las soluciones existentes hicieron eso mediante la construcción y ejecución de comandos SQL, mientras que pglogical pasa por alto la capa SQL y la sobrecarga asociada por completo.
Aún así, eso no hace que la aplicación sea completamente gratuita, ya que todavía necesita realizar cosas como búsquedas de clave principal, actualizar índices, ejecutar activadores y realizar otras comprobaciones. Pero es significativamente más barato que el enfoque basado en SQL. En cierto sentido, funciona de forma muy parecida a COPY y es especialmente rápido en tablas simples sin activadores, claves foráneas, etc.
En todas las soluciones de replicación lógica, cada uno de esos pasos (descodificación y aplicación) ocurren en un solo proceso, por lo que hay una cantidad bastante limitada de tiempo de CPU. Este es probablemente el cuello de botella más apremiante en todas las soluciones existentes, porque puede tener una máquina bastante robusta con decenas o incluso cientos de clientes que ejecutan consultas en paralelo, pero todo eso debe pasar por un solo proceso de decodificación de esos cambios (en el maestro) y un proceso que aplica esos cambios (en espera).
La limitación del "proceso único" se puede relajar un poco al usar bases de datos separadas, ya que cada base de datos es manejada por un proceso separado. Cuando se trata de una sola base de datos, el trabajo futuro está planificado para aplicar en paralelo a través de un grupo de trabajadores en segundo plano para aliviar este cuello de botella.